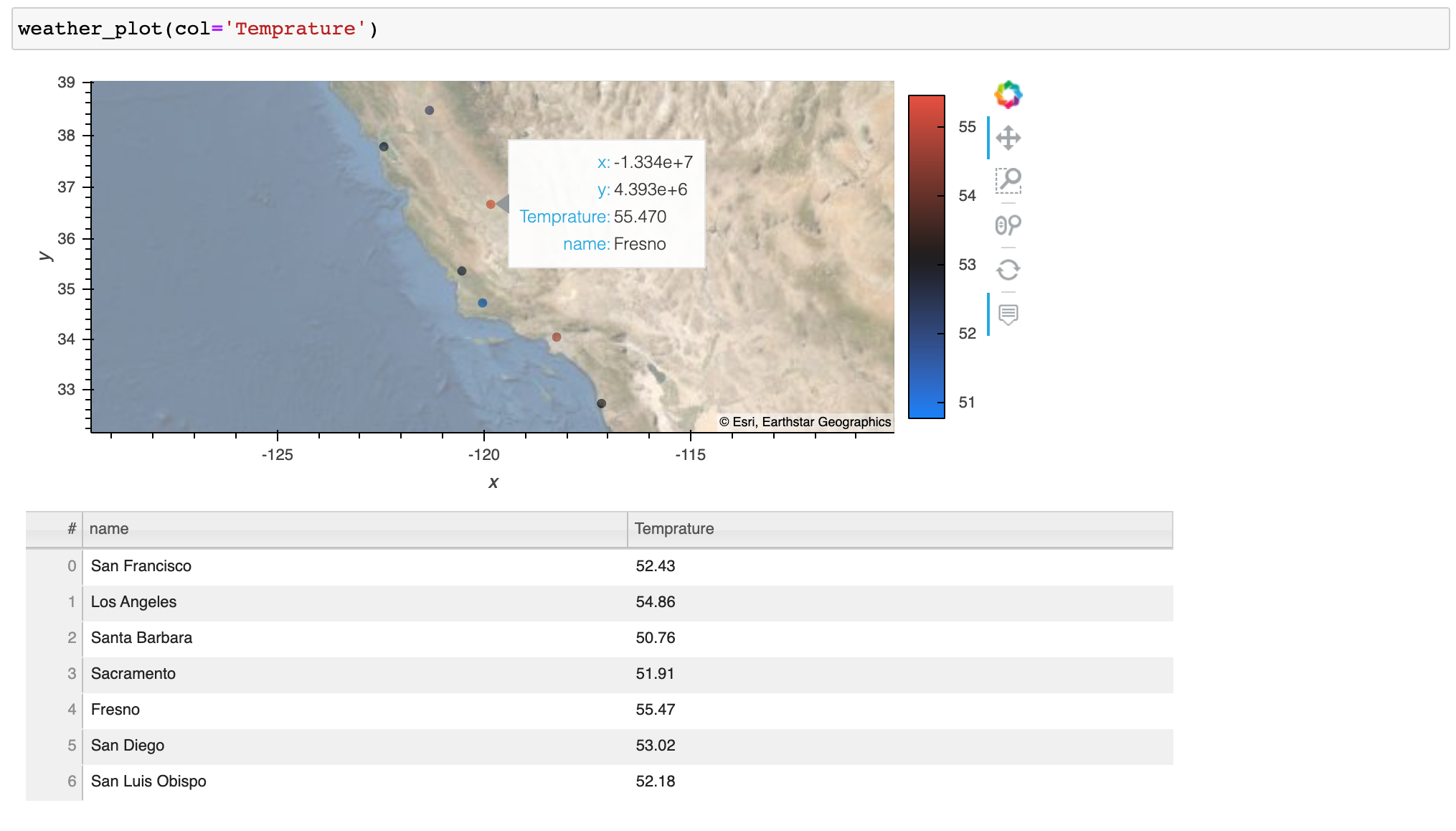
Price Impact of Order Book Imbalance in Cryptocurrency Markets
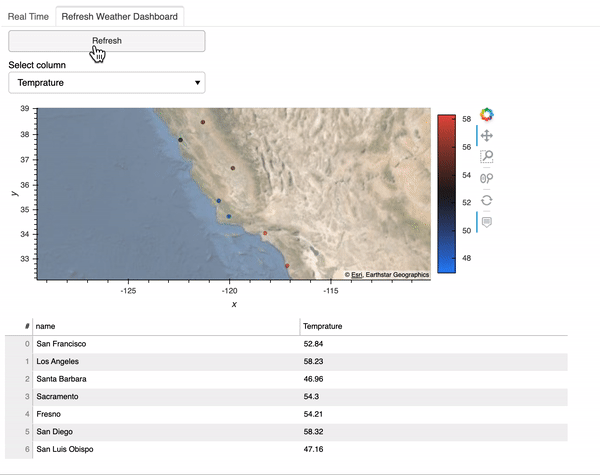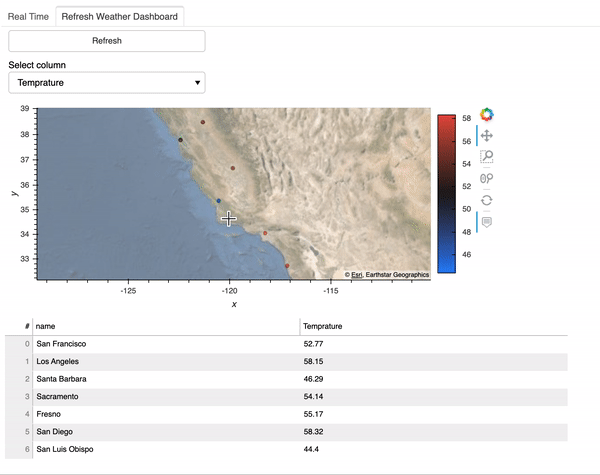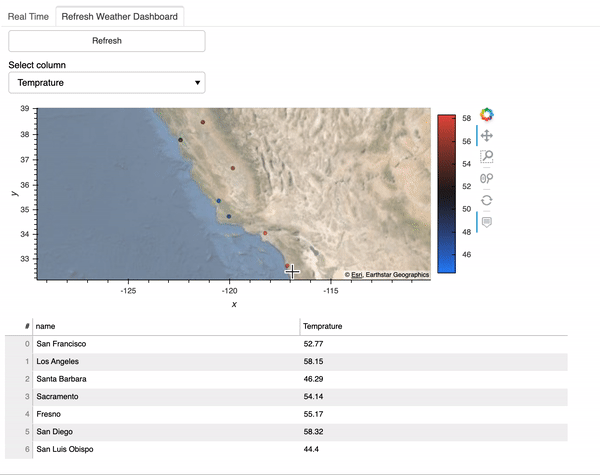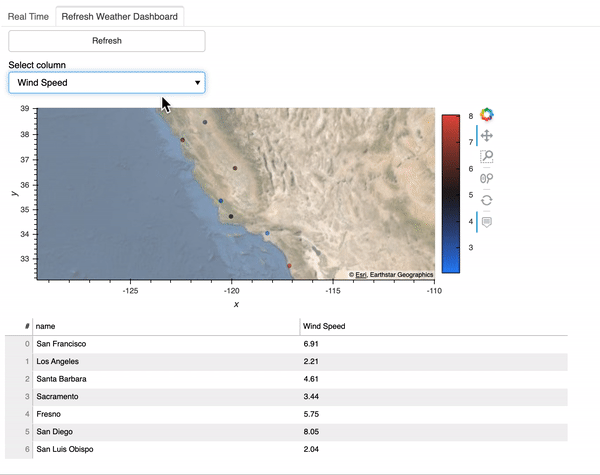
What can we learn from 1.9 million order book observations?
We investigate whether imbalanced order books lead to price changes towards the thinner side of the book. That is, by this hypothesis prices decrease when limit order books have large volumes posted at the ask side relative to the bid side, and if order books are more heavy on the bid side then prices increase. We test this hypothesis and assess whether order book imbalance information can be exploited to profitably predict price movements in the ETHUSD market.
Order book imbalance
We follow the literature, e.g., Cartea et al. (2015), and define the order book imbalance as
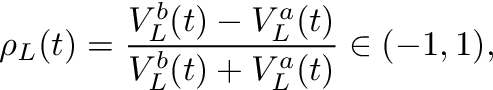
where t indexes the time, V stands for volume at either the bid (superscript b) or ask (superscript a), and L is the depth level of the order book considered to calculate ρ. Figure 1 shows an example how to calculate the imbalance ρ for a given order book.
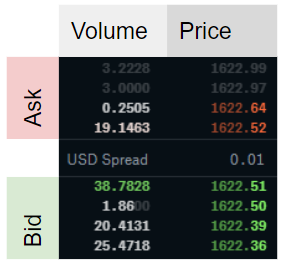
A ρ-value close to -1 is obtained when market makers post a large volume at the ask relative to the bid volume. A ρ-value close to 1 means there is a large volume at the bid side of the order book relative to the ask side. With an imbalance of zero the order book is perfectly balanced at the given level L. The hypothesis suggests that low imbalance numbers (<0) imply negative returns, high imbalance numbers (>0) imply positive returns, i.e., the price moves into the direction of the imbalance ρ.
What do researchers conclude from stock market data?
Cont et al. (2014) use US stock data to show that there is a price impact of order flow imbalance and a linear relationship between “order flow imbalance” and price changes. The authors define order flow imbalance as the imbalance between supply and demand, measured by aggregating incoming orders over a given period. Their linear model has an R² of around 70%. The study considers the past order flows (that result in an imbalance measure) and compares it to the price change over the same period. Hence, the conclusion is not that order flow imbalances predict future prices, but rather that the order flow imbalances computed over a historic period explains the price change over the same period. So this study reveals no direct insights on current order flow imbalances on future prices. Silantyev (2018) confirms the finding of this study using BTC-USD order book data in his Medium article.
Lipton et al. (2013), us the imbalance measure ρ with L=1 and find that the price change until the next tick can be well approximated by a linear function of the order book imbalance but note that
(1) the change is well below the bid-ask spread, and
(2) the method “does not by itself offer an opportunity for a straightforward statistical arbitrage”.
Cartea et al. (2018) find that a higher order book imbalance measured by ρ is followed by an increased amount of market orders and that the imbalance helps to predict price changes immediately after the arrival of a market order.
In their book, Cartea et al. (2015) present for one particular stock that correlations of past imbalances and price changes are decent (about 25% for a 10-second interval).
Stoikov (2017) defines a mid-price adjustment that incorporates
order book imbalances and bid-ask spreads. He finds that the resulting
price (mid-price plus adjustment) is a better predictor for short-term movements of mid-prices than mid-prices and volume-weighted mid-prices. In this study, the order book imbalance slightly differs from ours, specifically Equation (1) would be adjusted by removing the ask volume from the nominator and fixing the level L to 1. The method estimates the expectation of the future mid-price conditional on current information and is horizon independent. Empirically horizons for which the forecasts are most accurate range from 3 to 10 seconds for the stocks assessed. The adjusted mid-price lives between the bid and the ask for the data presented which indicates that the method by itself does not present a method for statistical arbitrage, but as the author notes can be used to improve upon algorithms.
These studies consider tick-level data at the best bid-ask price (L=1),
we look at longer horizons and delve into a depth of 5 to calculate the order
imbalance. The data in these studies uses stock market data, with the
notable exception of Silantyev (2018), whereas we look into cryptocurrency order books.
Data
Order book data can be queried via public API from crypto-exchanges. Historical data other than candle data is not generally available. Hence I collected order book data for ETHUSD from Coinbase in 10 second intervals up to a depth of 5 levels from May to December 2019 (2019–05–21 01:46:37 to 2019–12–18 18:40:59). This amounts to 1,920,617 observations. There are some gaps in the data, e.g., due to system downtimes, which we account for in our analysis. We count 592 gaps where the timestamp difference between two subsequent order book observations is larger than 11 seconds. The timestamp between two order books is not exactly 10 seconds in the data since I collected the data using repeated REST requests, rather than, e.g., a continuous Websocket stream.
Distribution of order book imbalance
Before looking at the relationship between price changes and the order book imbalance, we look at the distribution of the imbalance for different order book levels.
We calculate the order book imbalance ρ for all observations and the 5 different levels according to Equation 1 and find the following properties.
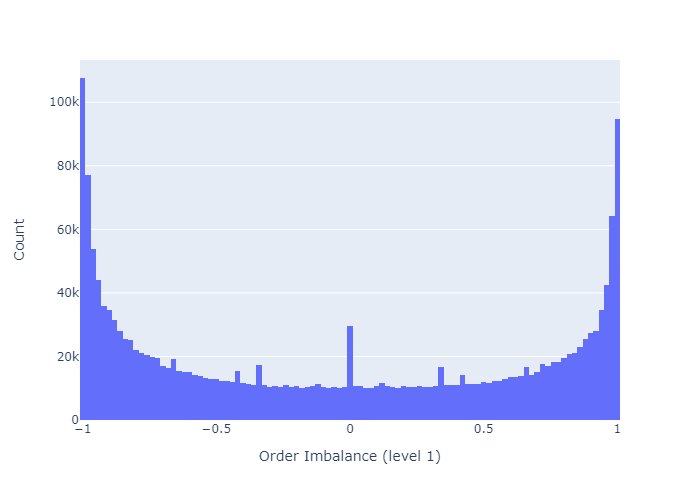
- At L=1 the imbalances are often very pronounced or not existent at all. The higher L, the more frequent are balanced order books (i.e., more observations for ρ≈0).
- The imbalance is autocorrelated. The deeper the level L, the higher the autocorrelation
We present the first finding in Figures 2 and 3 and the second in Figure 4.
Figure 2 shows a histogram of order book imbalances for level 1. We observe that at this level, the order book is mostly balanced (close to 0), or highly imbalanced (close to -1 or 1).
As we increase the order book depth to calculate the imbalance, the order books become more balanced, as we see in Figure 3.
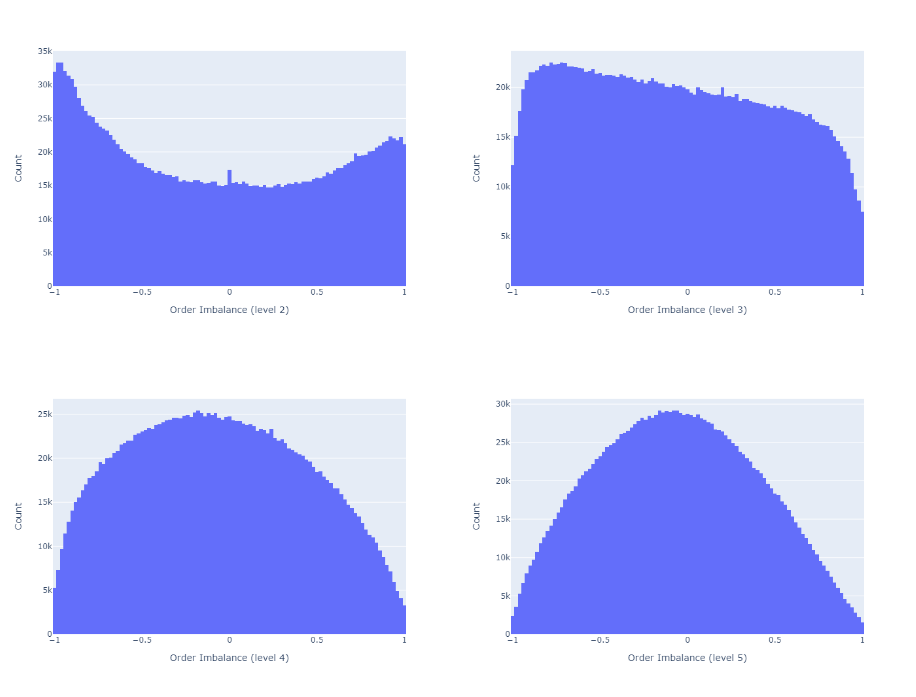
Figure 4 shows the autocorrelation function (ACF). Consistent with Cuartea et al. (2015) we find that imbalances are highly autocorrelated. The correlation for a given lag tends to be higher, the larger the order book depth L for the calculation of the imbalance.
Do order book imbalances help to predict price movements?
We now investigate the correlation of ρ and future mid-prices. Mid-prices are defined as the average of highest bid price and the lowest ask price.
We first calculate the p-period ahead log-return of the mid-price for each observation of order book imbalance. We then calculate the correlation between these returns and the order imbalances observed at the beginning of the period. We remove observations where the p-periods are on average longer than 11 seconds (1 period ≈ 10 seconds).
Figure 5 and 6 show the correlations of future returns and imbalances as a function of the period over which the return is measured. We conclude as follows.
- The correlations are low.
E.g., Cont et al. (2014) report an R² of about 70% between the price-impact and their measure of order flow imbalance over the same period. For a linear univariate regression model this R² implies a correlation of sqrt(0.70)=0.84. However, the authors measure the price increase over the same period as the order flow imbalance, hence this method does not offer price forecasts - The imbalance measure ρ is more predictive for prices closer to the imbalance observation (the correlation decreases as p increases)
- The higher the depth level L of the order book considered to calculate the imbalance, the more the imbalance measure correlates with future price movements
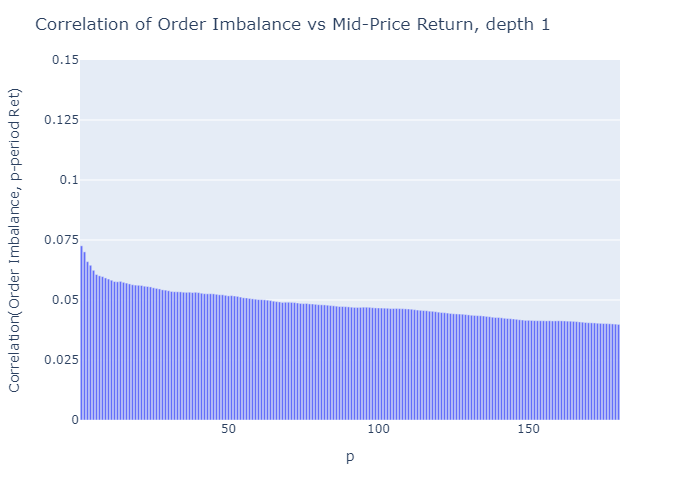
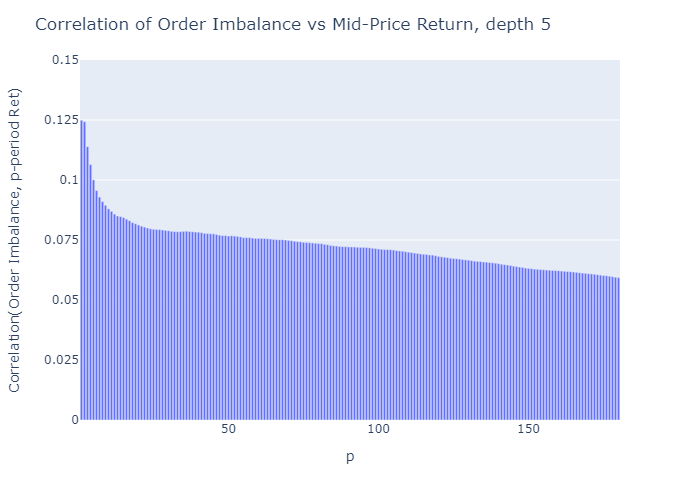
The corresponding plots for depths L=2 to 4 which I don’t show for brevity are consistent with these findings. For Python code for these plots see Appendix A2.
Price uncertainty
The correlations presented above showed that imbalances calculated with higher L correlates better with price increases than imbalances calculated with lower L. More near-term prices have a higher correlation with ρ. Based on this we continue the analysis with only one-period ahead forecasts (≈10s).
Correlation is an average measure, what about the uncertainty of the mid-price moves?
Figure 7 and 8 plot the 1-period log-return against the imbalance observed at the beginning of the period for L=1 and L=5 respectively. The level 1 imbalance plot (Figure 7) looks as if there was a higher variation of log-returns when the imbalance is large (close to -1 or close to 1) or 0, which we don’t observe for level 5 imbalances (Figure 8). However, this seemingly larger variation in the plot stems from the fact that we have more observations for L=1 at the boundaries and at zero (seen in the histograms in Figures 2 and 3) — calculating the standard deviation of returns does not confirm higher variances at the extremes as we see in the next paragraph.
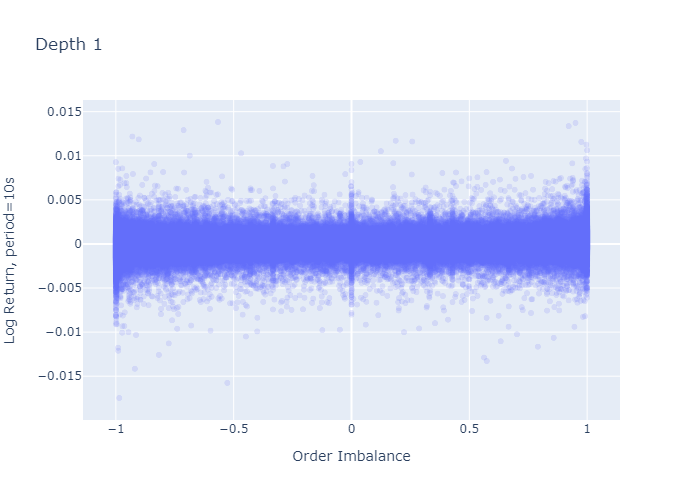
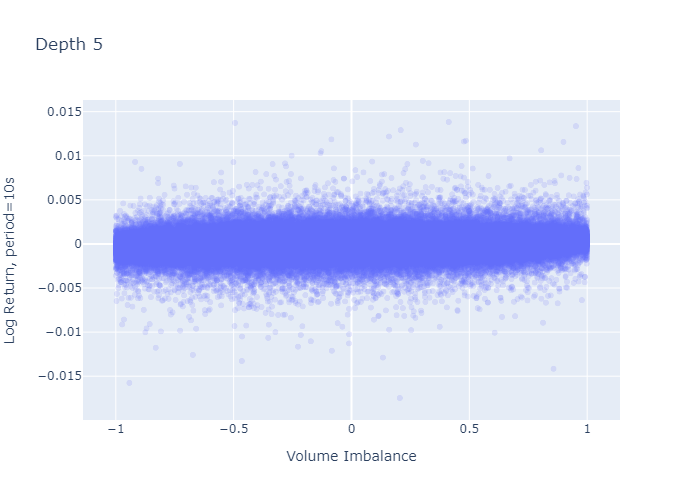
Imbalance regimes
We follow Cartea et al. (2018) and bucket our imbalance measure into five regimes chosen to be equally spaced along the points
θ = {-1, -0.6, -0.2, 0.2, 0.6, 1}.
That is, regime 0 has price imbalances between -1 and -0.6, regime 1 from -0.6 to -0.2 and so on. Table 1 shows the standard deviation of 1-period ahead price returns for all 5 regimes.
Table 1 addresses the question from the previous paragraph: the mid-price variance at extreme imbalances (regime 0 and regime 4) is not higher for order book depth level L=1 than for level 5.
Now we take this analysis further and estimate probabilistic bounds for the expected mid-price return in a given regime by constructing confidence intervals. I provide details on this calculation in Appendix A1.
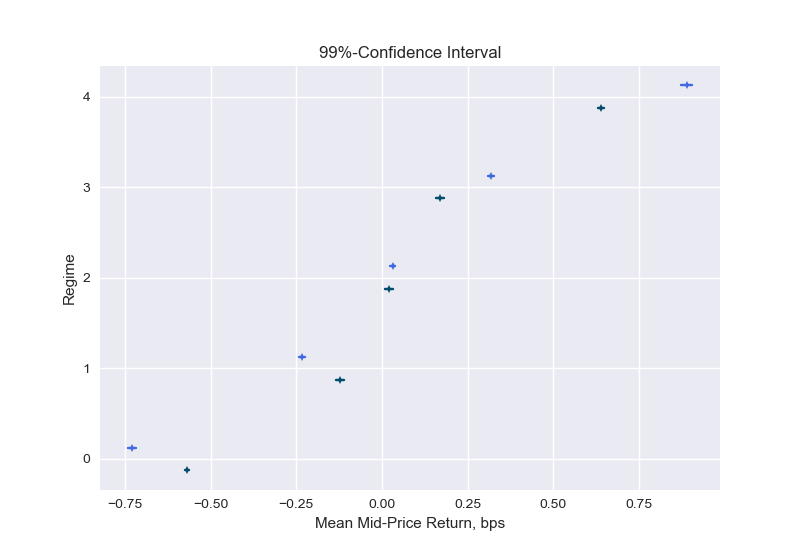
Figure 9 presents confidence intervals for the expected mid-price return in a given regime. We can see that indeed the returns are on average negative for low imbalance numbers (regime 0 and 1) and positive for high imbalance numbers (regime 3 and 4). The means move more into the order imbalance direction when the imbalance is constructed with a higher level, e.g., in regime 4 the mean of the 1-period ahead return when the imbalance is calculated with L=1 (dark line) is smaller than when performing the calculations at a depth of level L=5 (bright line). Note that the confidence intervals shown reflect the uncertainty in the expected value. The standard deviations of Table 1 inform us about the uncertainty of the returns around this expected value.
This analysis confirms the findings from the correlation analysis: there is positive but weak correlation between imbalances and 1-period ahead returns, and the deeper level (L) results in a slightly more predictive imbalance measure.
Empirical probabilities
What is the probability that the next period mid-price will go up, stay flat, or go down knowing in which imbalance regime we are?
To see this, we bucket every order imbalance into a regime 0-4 and then count the number of negative returns, zero returns, and positive 1-period returns and divide the count by the number of observation to have an estimate for the probabilities of mid-price moves.
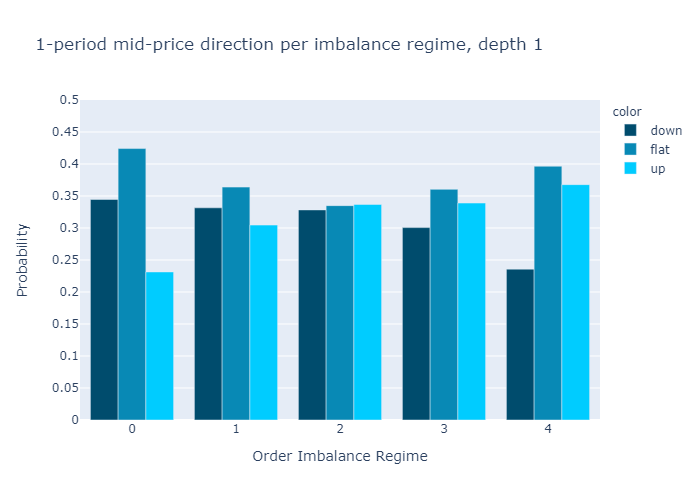
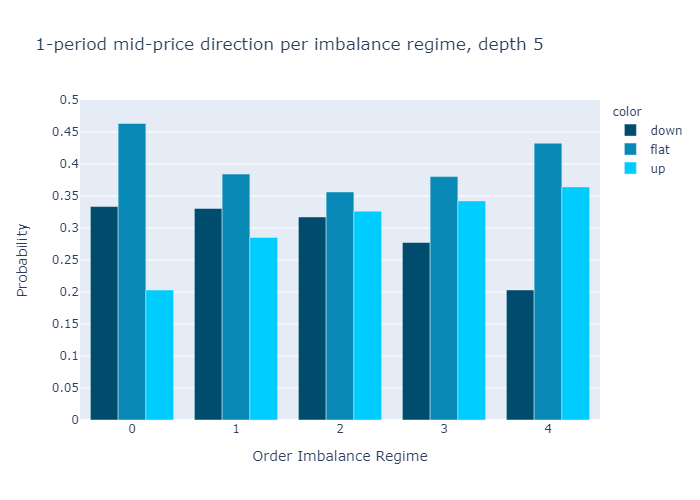
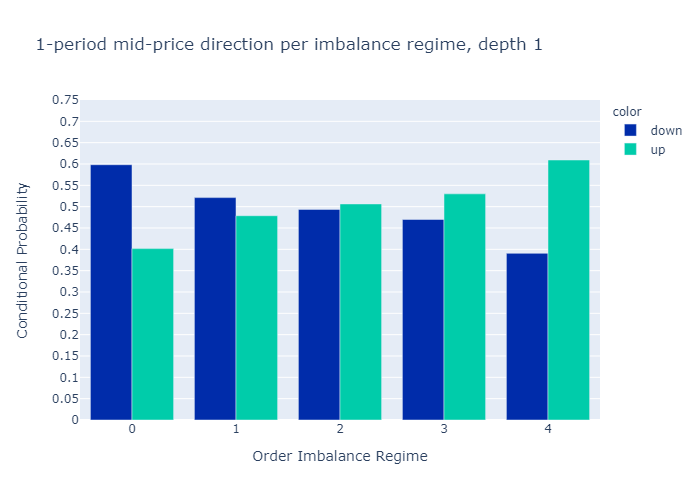
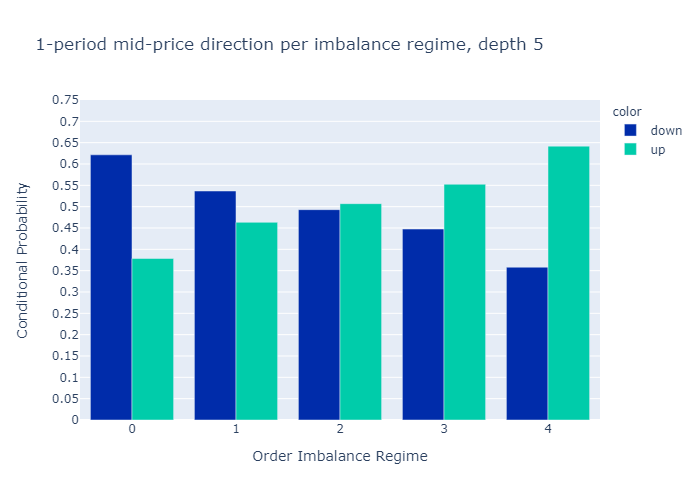
Figures 10 and 11 present the empirical probabilities for imbalances computed for L=1 and L=5 respectively. The figures confirm our initial hypothesis:
There is a higher probability of mid-price decreases in regimes with low values of order book imbalance, and vice versa.
We see qualitatively no difference in the empirical probabilities when calculating the imbalances with only 1 level (Figure 10) or 5 levels (Figure 11). We observe that the probabilities for higher levels L=5 are more discriminatory than for L=1, which is a desired property.
In Appendix A3 we also show the probabilities conditional on observing a non-zero price move. We find that if the price moves, the level 5 imbalance is a slightly better predictor than the level 1 imbalance.
Profitability

Many crypto exchanges have trading fees in the order of 10bps (and we would execute 2 trades). We see from the confidence intervals (Figure 9) that mid-price returns are below 10 basis points for the 10 second periods considered. So from judging by the expected return without considering variances, we can conclude that order imbalances do not directly imply a profitable strategy on its own without even investigating the bid-ask spreads.
To affirm this finding, we look at profitability from another angle and calculate the empirical probabilities of price moves larger than 10 basis points, similar to figures 10 and 11. That is, we count all movements that are in absolute terms below 10 basis points as flat. Table 3 shows that for imbalance calculations with order book levels of both 1 and 5, most trades would end up below an absolute return of 10 basis points in all regimes. This confirms the strategy does not allow for statistical arbitrage on its own.
Conclusion
Our analysis for ETHUSD order books and mid-price movements is consistent with the findings in the literature on order book imbalances for stock markets:
- When the imbalance is close to -1 there is a selling pressure and the mid-price is more likely to go down in the near term, when the imbalance is close to 1 there is a buying pressure and the mid-price is more likely to move up.
- The price impact of the imbalance measure is short-lived and quickly deteriorates with the time horizon.
- The imbalance measure itself cannot directly be used for statistical arbitrage, however, it can be used to improve upon algorithms.
In addition to what the literature cited on order book imbalances, I have also analyzed the order book imbalance calculated using up to 5 levels and found that the correlation of the imbalance measure with future price moves increases with the level (for the 5 levels assessed). From the expected values and its confidence intervals in Figure 9, however, we see that higher levels do only marginally improve the return direction and we observed that empirical probabilities are only slightly more discriminatory when working with higher levels of order book depths. Therefore, the added value from deeper levels (L>1) does probably not justify the higher complexity (handling deeper levels is typically more time consuming for high frequency algorithms).
Finally, we found the strongest relationship between imbalance and price movements to be within the shortest period (10 seconds) available in the data. Therefore, I conclude that looking into tick data could reveal more insights, as opposed to the 10 second period length examined in this article.
References
Cartea, A., R. Donnelly, and S. Jaimungal (2018). Enhancing trading strategies with order book signals. Applied Mathematical Finance 25 (1), 1-35.
Cartea, A., S. Jaimungal, and J. Penalva (2015). Algorithmic and high-frequency trading. Cambridge University Press.
Cont, R., A. Kukanov, and S. Stoikov (2014). The price impact of order book events. Journal of financial econometrics 12 (1), 47-88.
Lipton, A., U. Pesavento, and M. G. Sotiropoulos (2013). Trade arrival dynamics and quote imbalance in a limit order book. arXiv preprint arXiv:1312.0514 .
Paolella, M. S. (2007). Intermediate probability: A computational approach. John Wiley & Sons.
Silantyev, E. (2018). Order-flow-analysis-of-cryptocurrency-markets. Medium.
Stoikov, S. (2017). The micro-price: A high frequency estimator of future prices. Available at SSRN 2970694 .
Appendix
A1. Confidence intervals
We are interested in the mean of the log-returns conditional on being in a given regime. We construct confidence intervals that allow us to estimate probabilistic bounds for the expected mid-price return in a given regime. The method we present here is standard, see e.g., Paollela 2017.
By the central limit theorem, the sample mean
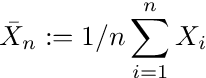
of i.i.d. random variables Xi are normal:
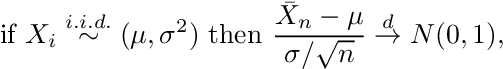
where Xi represent the i=1,…,n observations drawn from a distribution with mean μ and standard deviation σ, the arrow with superscript d denotes convergence in distribution and N(0,1) represents the standard normal distribution. We can express Equation A.2. informally as
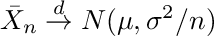
that leads to the estimates of mean and variance
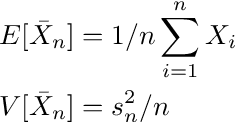
where s is the sample standard deviation. Now, the confidence interval for a level (1-α) is given by
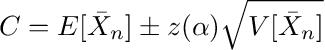
z(α) represents the point on the x -axis of the standard normal density curve such that the probability of observing a value greater than z(α) or smaller than –z(α) is equal to α.
To apply this form of the central limit theorem, the mid-price returns have to be i.i.d.. The autocorrelation of mid-price returns are below 1% (see also A2) and there is no indication that they should stem from different distributions or have another dependency that is not reflected in the correlation, so we can assume the i.i.d. property holds and use Equation A.4.
import scipy.stats as st
import numpy as npdef estimate_confidence(shifted_return,
vol_binned,
volume_regime_num,
alpha=0.1):
"""
Estimate confidence interval for given alpha
:param shifted_return: array of returns for which we calculate
the confidence interval
of its mean, can contain NaN
:type shifted_return: float array of length n
:param vol_binned: volume regimes. Entry i corresponds to the
volume regime associated with
shifted_return[i]
:type vol_binned: float array of length n
:param volume_regime_num: equals np.max(vol_binned)+1
:type volume_regime_num: int
:return: confidence intervals for mean of the returns per regime
:rtype: float array of size volume_regime_num x 2
"""
confidence_interval = np.zeros((volume_regime_num, 2))
z = st.norm.ppf(1-alpha)
for regime_num in range(0, volume_regime_num):
m = np.nanmean(shifted_return[vol_binned == regime_num])
s = np.nanstd(shifted_return[vol_binned == regime_num])
sqrt_n = np.sqrt(np.sum(vol_binned == regime_num))
confidence_interval[regime_num, :] = [m - z * s/sqrt_n,
m + z * s/sqrt_n]
return confidence_interval
A2. Plot the autocorrelation function
The Python code-snippet below calculates autocorrelations and plots. The calculation accounts for (hard-coded) gaps in the time-series that are greater than 11 seconds.
import numpy as np
from datetime import datetime
import plotly.express as pxdef shift_array(v, num_shift):
'''
Shift array left (num_shift<0) or right num_shift>0
:param v: float array to be shifted
:type v: array 1d
:param num_shift: number of shifts
:type num_shift: int
:return: float array of same length as original array,
shifted by num_shifts elements, np.nan
entries at boundaries
:rtype: array
'''
v_shift = np.roll(v, num_shift)
if num_shift > 0:
v_shift[:num_shift] = np.nan
else:
v_shift[num_shift:] = np.nan
return v_shiftdef plot_acf(v, max_lag, timestamp):
'''
Create figure to plot autocorrelation function
:param max_lag: when to stop the autocorrelation
calculations (up to max_lag lags)
:param timestamp: timestamp array of length n
with entry i corresponding to timestamp of
entry i in v, used to remove time-jumps
v: array with n observation
:return: plotly-figure
'''
corr_vec = np.zeros(max_lag, dtype=float)
for k in range(max_lag):
v_lag = shift_array(v, -k-1)
timestamp_lag = shift_array(timestamp, -k-1)
dT = (timestamp - timestamp_lag) / (k+1)
msk_time_gap = dT > 11000.0
mask = ~np.isnan(v) & ~np.isnan(v_lag) & ~msk_time_gap
corr_vec[k] = np.corrcoef(v[mask], v_lag[mask])[0, 1]
fig_acf = px.bar(x=range(1, max_lag+1), y=corr_vec)
fig_acf.update_layout(yaxis_range=[0, 1])
fig_acf.update_xaxes(title="Lag")
fig_acf.update_yaxes(title="ACF")
return fig_acf
A3. Conditional Empirical Probabilities
Figures A1 and A2 show the empirical probabilities of a mid-price up move/down move conditional on observing a non-zero return. Level 5 imbalances show a better discriminatory power, that is, in regimes 0 and 5 the probabilities are more extreme than at level 1.
If the mid-price moves, the imbalance with L=5 is a better indicator of the price direction than the imbalance of L=1.
Note from Towards Data Science’s editors: While we allow independent authors to publish articles in accordance with our rules and guidelines, we do not endorse each author’s contribution. You should not rely on an author’s works without seeking professional advice. See our Reader Terms for details.