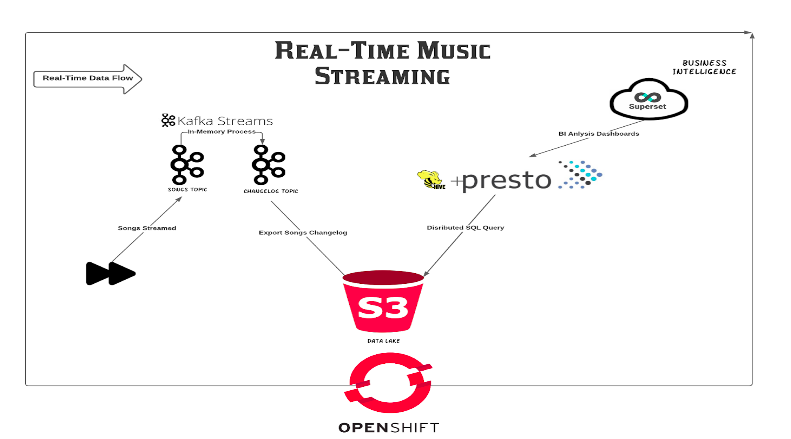
Please find below the transcript:
Jeremie (00:00:00):
Hey, everyone, Jeremie here. Welcome back to the Towards Data Science Podcast. I’m really excited about today’s episode because we’re going to be taking on a lot of long-termist, reformed looking, and semi futuristic topics related to AI. And the way AI technology is going to shape the future of governance. Are human beings going to just become economically irrelevant? How many of our day-to-day decisions are going to be offloaded to machines? And maybe most importantly, what does the emergence of highly capable and highly general AI systems mean for the future of democracy and governance itself? Those questions are impossible to answer with any kind of certainty, but it might be possible to get some hints by taking a long view at the history of human technological development.
Jeremie (00:00:41):
And that’s exactly the strategy that my guest Ben Garfinkel is applying in his research on the future of AI. Now, Ben is a multidisciplinary researcher who’s working on forecasting risks from advanced technologies, including AI at Oxford’s Future of Humanity Institute. Ben’s also spent a lot of time exploring some classical arguments for AI risk, many of which you’ll have encountered on the podcast. We’ve had a lot of guests on to discuss and explore those in detail and many of which he disagrees with. And we’ll be exploring his disagreements, why he has them, and where he thinks the arguments for AI risk are a little bit shaky. I really enjoyed the conversation. I hope you do too. Ben, thanks so much for joining me for the podcast.
Ben (00:01:19):
Yeah. Thanks so much for having me.
Jeremie (00:01:21):
I’m really happy to have you here. Your focus is on a whole bunch of long-termist issues, a lot of them around AI. Before we dive into the meat and potatoes of that though, I’d love to have a better understanding of what brought you to this space. So what was your background coming in and how did you discover long-termism in AI?
Ben (00:01:38):
Yeah, so it’s actually I guess, fairly roundabout. So in college I studied physics and philosophy and was quite interested in actually the philosophy of physics and was even considering going to grad school for that, which fortunately I did not do. And yeah, I guess through philosophy, I started to learn more about ethics and encountered certain ideas around population ethics. The idea that there’s different questions around how we should value future generations in the decisions we make and what our obligations are to future generations. Or how strong the obligation is to do something that has at least some use to other people. And then through that, I became increasingly interested in long-termism, and also trying to figure out something that seemed useful. And I came to think that maybe philosophy and physics was not that.
Ben (00:02:28):
And I got actually very lucky not just around this time, as I was trying to look more into long-termist or futuristic topics, I happened to meet a professor, Allan Dafoe, who was at Yale at the time. He was just himself pivoting to work on AI governance issues. And I think he put up a call for research assistants when I was still a senior there. And I was interested in the topic, I’d read a little bit about AI risk. I started to read for example, the book Superintelligence and I hadn’t really engaged in that area, but seemed like there may be some important issues there. And an opportunity jumped up and I started working with Allan. And now several years later, I’m actually still working with Allan, and I’ve just become fairly convinced that working on risks from emerging technology is at least a pretty good thing to do from a long-termist perspective.
Jeremie (00:03:14):
And this is actually a beautiful segue into, I think one of the main topics I really wanted to talk about. And that is this idea that you spent a lot of time thinking about existential risk from AI and the arguments for it. Many of which I know that you’re not actually fully sold on. Maybe we can start there, what’s the nature of the existential risk that people generally in particular, Allan and you are worried about when it comes to AI? And then we can maybe get into the counter-arguments to those arguments as well, but just for starters, what is that risk?
Ben (00:03:44):
Yeah, so I don’t think that there’s really a single risk that’s, at least really predominant in the community of people thinking about the long-term impacts of AI. So I’d say there’s a few main, very broad, and somewhat nebulous categories. So one class of risks very quickly is I’d say are risks from instability. So a lot of people, especially in the international security domain are worried about for example, lethal autonomous weapons systems, maybe increasing the risk of conflict between states. Maybe accidental, flash conflicts or potentially certain applications of AI, let’s say moving second strike capabilities and increasing the risk of nuclear war. Or they’re worried about great power competition. And the main vector of concern they have is maybe something about AI will destabilize politics either domestically or internationally, and then maybe there’ll be war which will have lasting damage or just some other negative, long conflict.
Ben (00:04:43):
There’s another class of concerns that is less focused on there being, let’s say some specific conflict or collapse or war. And is more focused on the idea that maybe there’s some level of possible contingency in how AI reshapes society. So you might think that certain decisions people make about how the government and AI will have lasting effects that carry forward and affect future generations. And in fact, for example, things like how prevalent democracy is or what the distribution of power is, or just various other things that people care about that maybe for example, bad values being in some sense entrenched.
Jeremie (00:05:23):
Because on that side, I imagine that’s a very, obviously it’s complicated area. But what are some of the ways in which people imagine AI transforming the extent to which let’s say democracy is a attractable mode of governance in the future?
Ben (00:05:36):
So just on democracy there’s obviously some speculative edge to this, but one argument for being worried about democracy is that democracy is not really normal. If you look across broad, sweeping view in history, back to the first civilizations, it’s not that uncommon for there to be, let’s say very weekly democratic elements. So it’s not completely autocracy, there’s some sort of body, say, Roman Senate or something, but in the case of Roman which is a well-known one. But it’s very far from what we have right now, which is like almost universal suffrage in a large number of countries with very responsive governments and consistent transfer for more. That’s extremely rare from a historical perspective. And even if things were not fully autocracy or somewhat coming before, this is a very different thing the past couple 100 years. And there’s different theories about why this modern form of democracy has become more common. And there’s a lot of debate about this because it’s hard to run RCTs. But a lot of people do point to at least certain economic changes that happen around the industrial revolution as relevant.
Ben (00:06:43):
So one class of change that people sometimes bring up is Androform, was a really serious concern before the industrial revolution. Some of the concern was that if you give a lot of common people power of the government, or leverage the [inaudible 00:06:56] that redistribute land, which is the primary form of wealth from wealthy actors more broadly should be very disruptive. And that’s as countries industrialized and land became less relevant as a form of wealth, maybe these land reform concerns became less of a blocker. You no longer had this land aristocracy, had this very blunt policy fear.
Ben (00:07:18):
And other concerns as well, is that the value of labor went up as well, just as productive increased. And this gave people in some nebulous sense, more bargaining power because you have the typical worker just what they did and more value. And they could create a larger threat by threatening to basically just remove their labor. Or organizations also thought to maybe have been relevant, like maybe people being packed in the cities would be easier to organize and actually have successful revolutions. And there’s lot of different factors that people basically point to as being economic changes that maybe helped democracy along its way or helps at least partly explain why it’s more prevalent today.
Ben (00:07:52):
So one concern you could have quite broadly is if the prevalence of democracy is in some way contingent on certain material or economic factors. Then that have only really held for the past couple 100 years. Maybe this isn’t normal, maybe if you just change a lot of economic and technological variables, it’s not going to hold. And there’s some more specific arguments here. So one pretty specific argument is just if the value of human labor goes very low, even goes to zero in most cases, because you can just substitute capital for labor. Because AI systems can do anything that people can do, maybe when we reduce the power of workers, if you can automate law enforcement or putting down the uprisings because military technologies can be automated as well.
Ben (00:08:33):
Maybe that makes authoritarian governments more stable. It means that they don’t even make concessions out of fear of uprisings. Maybe as well if the value of labor goes to zero, then at that point might become very heavily based on just who owns capital or who owns machines basically. And maybe it creates a system, a situation that’s very analogous to the little concerns about land reform. Where wealth wasn’t really based on these more nebulous things would divide people’s labor, didn’t really play a role, which is largely, there’s a thing that you own that you basically collect rents on. If you returned to that system, then maybe that’s also not good for the stability of democracy as well.
Ben (00:09:09):
So there’s an outside view perspective, which is just, this is a rare thing. Maybe we shouldn’t expect it to last, we change a lot. And then there’s some more inside view arguments that maybe will make authoritarian governments more stable, and make people were more worried about giving power to [inaudible 00:09:24].
Jeremie (00:09:24):
It’s really interesting how entangled all these issues are and how difficult it is to articulate a coherent vision of what the future might look like when all these transformational changes happen. One of the things that keeps coming to mind for me when we start talking about what’s going to happen with democracy, what’s going to happen with the economies. And then the power of labor to negotiate and so on, is the underlying assumption that we have any kind of market structure whatsoever, to the extent that you have all labor being done by machines.
Jeremie (00:09:57):
One of the, I guess almost silly questions that I would have is what is the value of money in that context? What is the value of price discovery? How does price discovery happen in that context? And what even does redistribution mean if… It’s not that we’re necessarily in a post scarcity situation, you would expect gradients of scarcity. But anyway, I’m not even sure what thought I’m trying to articulate here, but it looks like you have something to throw in there.
Ben (00:10:23):
So I think this is a really serious issue. I think we should not expect ourselves to actually be able to imagine a future with very advanced AI in any level of detail and actually be right. So an analogy I’ve sometimes used is I think there are certain aspects of a world where AI systems can at least do all the things that people can do. We can reason about to some extent, abstractly. We do have these economic models, we have labor and you have capital, and you can ask about what happens if you can substitute capital for labor. And even project is very abstract point of view. And there’s maybe some reason to hope that these theories are sufficiently abstract, that even if we don’t know the details. There’s still some reason to think that there’s sufficient general abstract that we can still use them to reason about the future. But there’s definitely a concern, like anything that becomes specific on how the governments work. We’re probably going to be imagining just the functionality of government’s quite wrong.
Ben (00:11:19):
So one analogy I’ve sometimes used is let’s imagine that you’re in say 1500 and someone describes the internet to you in very abstract terms of it’s like communication will be much faster. Retrieving information and learning things would be much quicker. And it gives you some of the abstract properties of it. There are some stuff you can probably reason about.
Ben (00:11:40):
So you might think, for example, “Oh, you can probably have less autonomy because people can communicate with them more quickly as opposed to them being overseas and out of contact. Or businesses can probably be larger because these coordination costs will probably go down.” And some stuff you can probably say about that would actually be true, or you could say, “Oh, maybe people work remotely,” and you probably don’t even know a lot about the details. But if you try to get really specific about what’s going on with that you’re probably going to be imagining it just completely, completely wrong. Because you have no familiarity whatsoever of what a computer actually is like, or how people interact with them.
Ben (00:12:15):
You’re not going to get details at the level of like, there’ll be this thing called Reddit and GameStop stock. There’s all these issues, which there’s no chance you’re ever going to foresee in any level of detail. And there’s lots of issues you might imagine that just won’t really apply because you’re using abstractions that somehow don’t fit very well. So this is a bit of a long-winded way of saying, I do think we have some theories and methods of reasoning that are sufficiently abstract and I expect them to hold at least a little bit. But I think there’s lots of stuff that we just can’t foresee. Lots of issues that we just can’t really talk about. And lots of stuff we say today they’ll probably end up being silly from the perspective of the future.
Jeremie (00:12:51):
Yeah, I would imagine so, “This time it’s going to be different,” is a dangerous thing to say at any given time. But when it comes to the next stage of the AI revolution, if you want to call it that. I know that’s the language you’ve tended to use as well and it seems apt in this case. One of the things that I do wonder about is a kind of almost like abstraction leakage where the abstractions that we rely on to define things like markets. This is one of the very fundamental elements of our reasoning when we’re talking about predicting the future. Markets implicitly revolve around people, because ultimately prices are just what individual human beings are willing to pay for a thing. To the extent that we broaden our definition of what a market participant could be.
Jeremie (00:13:38):
And here we get into questions of like, how do we consider an AI agent? At what point is it a participatory member of society? And at what point does price discovery really revolve around the needs and wants of non-human systems and things like that? I guess that’s where I start to wonder, this is a non-constructive perspective by default. So it’s not helpful for me to say like, “Markets are a bad abstraction,” but is that an issue that you think is serious or?
Ben (00:14:06):
Yeah, so yes, I do certainly think that there’s an issue and I think you point out a good, specific problem of, we have this very firm distinction between… People are very different than machines and software at the moment. It’s a very [crosstalk 00:14:19] like economic actors versus stuff about the economic [inaudible 00:14:23]. And there’s some degree of blurring of a corporation, for certain purposes has [inaudible 00:14:29] which are in some ways similar to a person. But the distinction is fairly, fairly strong. Even just between capital and labor, there aren’t any ambiguities around this at the moment.
Ben (00:14:41):
But if you think that very broadly capable, gentle, AI systems will exist in the future. We think that maybe people have interesting relationships with the AI systems where they create assessments, which are meant to pursue their values. I think a lot of distinctions that we draw might actually become a lot more ambiguous than they are today. And the way in which they become ambiguous in the future might make it so that any reason we do that relies on really crisp distinctions, might just fail in ways which are difficult to foresee at the moment.
Jeremie (00:15:12):
Yeah. It’s an interesting risk to predict because it really is unpredictable and fundamentally challenging. It seems like one of the issues there too, and you explore this in some of your work actually on the history of technology is which metric you’re even going to look at to tell the story of the evolution of this technology. Can you speak a little bit to that, your historical outlook and which metrics you find interesting and why they may or may not be relevant in the future?
Ben (00:15:36):
Yeah. So I think one metric that I think people very frequently reach to is global world product or GDP. And GDP is interesting as a metric because the thing it’s meant to measure is basically to some extent productive capacity, like how much stuff can you produce or stuff that people value can you produce. And-
Jeremie (00:16:01):
I have a stupid question. So what is GDP? What is the actual definition of GDP?
Ben (00:16:08):
So at least nominal GDP, you add up the total price of all of what are called final products that are sold within an economy. So a final product is basically something that is something like an end result. If you sell someone screws, and then they sell the screw to someone who uses the screw to make like a ceiling fan or something. The screw isn’t meant to be counted because you’re double counting. If someone buys a ceiling fan and they buy the screw when they buy the ceiling fan, they’re also buying the screw as well. So it’s meant to be basically adding up the total essentially sell price of all the stuff that’s bought or sold within an economy excluding the intermediate products.
Ben (00:16:48):
But then people also often want to talk about real GDP, which is different than nominal GDP. So nominal GDP is just, you add up basically all the prices. And one issue of nominal GDP is if you have inflation, then you can have nominal GDP increase for reasons that have nothing to do whatsoever with the actual underlying stock. So government decides to print more money, suddenly the price of everything goes up by a factor of 1,000, but you still have the same stuff. It doesn’t really feel like GDP growth has been extremely rapid in a nominal sense, but it’s not really telling you that actually you’re producing more stuff.
Jeremie (00:17:25):
Yeah. Venezuela is doing great.
Ben (00:17:27):
Yeah, exactly. So real GDP, it’s meant to be adjusting for this. And at least very roughly speaking the way it works is you try to define everything relative to the prices that existed a certain point in time in the past. So let’s say you have an economy that exists, the only product sold is butter and the price of butter goes up by a factor of 1,000 for some reason because of inflation. But you only double the amount of butter that you sell in the economy. Real GDP will just say, “Oh, because the amount of butter you sold increased by a factor of two. The size of your economy has only increased by a factor of two.” And the size of the economy is defined as take the price of butter in the past, multiply it by how many units exist today and that’s real GDP. And it gets pretty complicated because people keep introducing new products over time. So how do you compare the real GDP of the economy in 2020 versus the economy in the 1700s, given that most of the stuff that people buy in 2020 didn’t exist in 1700? How do you actually do that comparison? And there’s various wonky methods people use, they don’t really understand properly.
Ben (00:18:36):
But in asking that question, you’ve also gotten to one of the main issues with GDP. It’s meant to be tracking the productive capacity of society, like how much stuff we make basically. And if you use real GDP, over short periods of time, it seems fairly unproblematic because you’re not typically introducing that many new products. But over a long period of time, it becomes increasingly nebulous how these comparisons actually work. So very blunt comparisons still are pretty much fine. So you can still say like GDP per capita in 10,000 BC versus today. Even if I don’t know exactly how to define GDP per capita for like 100 other societies, I’m still quite confident it was lower.
Ben (00:19:21):
So it’s in some sense like a blunt instrument, I think its usefulness really depends on how precise you want to make your discussions or predictions. So let’s say someone makes a very bold prediction that the rate of GDP per capita growth will increase by a factor of 10 due to automation. If someone makes a bold prediction like that, it is a little bit ambiguous what real GDP means in some crazy futuristic economy. But even if you look a little bit fuzzy on it, the difference between GDP, the rate of growth, didn’t change, the rate of growth increased by a factor of 10 is still blunt enough. It’s a useful way of expressing a claim.
Ben (00:19:57):
So that’s a long-winded way of saying, I think GDP or GDP per capita is often pretty good as a proxy of just how quickly is productive capacity increasing. It’s useful for things like the industrial revolution, really clearly shows up in GDP per capita. Or when a country seems really stagnant, like undeveloped country isn’t developing, GDP per capita is typically pretty flat. And then when China, for example, started to take off in a really obvious qualitative sense GDP per capita tracked that pretty well. So it’s useful for that, but it also has various issues. And then there are also issues beyond that of like, often people want to use it as a proxy for how good people’s lives are, like GDP per capita.
Ben (00:20:38):
But there’s various things that don’t typically get factored into it, like the quality of medical care, isn’t very directly factored into it, air pollution isn’t factored into it. If everyone was just very depressed or anesthesia, the value of anesthesia being developed just really does not show up. There’s a classic paper by William Nordhaus that shows that quality improvements in lights, the fact that light bulbs are just way better than candles, more than 100 years ago doesn’t really show up. So it’s a long-winded way of saying same fiscal lots of issues, at least as a crude measure, pretty good. But doesn’t necessarily correlate that actually as well as you might help with wellbeing and other things of interest.
Jeremie (00:21:15):
It is interesting that when you tagged on that last piece, it doesn’t correlate well with wellbeing. I can’t think of a better encapsulation of a kind of alignment problem. Basically the problem of coming up with a metric that says, here’s what we want. Humans are really bad, or it’s not that we’re bad. It may just be a genuinely difficult problem to specify metrics that even make sense. And you see what the stock market, we decide to fixate on this one metric. And for a while, the stock market was a great measure of in general, how’s the economy doing, how’s the average person doing? But then there’s a decoupling and we end up with very divergent stock markets versus the lives of the average person. Anyway, sorry. It didn’t mean to butt in but you were mentioning the-
Ben (00:22:00):
Yeah. So I should just say as a little caveat, I think at the moment, GDP actually is pretty good as a metric. Where if you often define the things you care about, like life expectancy or life satisfaction. It does actually currently, there’s often like a pretty strong correlation. And I think you’re just like, didn’t know anything, you’re behind [inaudible 00:22:17] or something, you need to pick a country to live in. And the only thing you get is the GDP per capita. This is often going to be useful information for you. I guess my thought is more in line with the alignment concerns, I wouldn’t be surprised if it becomes more decoupled in the future.
Ben (00:22:30):
Especially if let’s say, imagine we eventually just totally replaced labor with capital and machines and people no longer are really working for wages. And economic growth is mostly machines building other machines and workers aren’t really involved. I would not be shocked if the economy increases by a factor of 10, but a person’s life does not increase by a factor of 10.
Jeremie (00:22:47):
Yeah. That’s interesting as well and raises the question of what, and this is back to price discovery, which is a big aspect of GDP. There are so many areas where things get complicated. But what’s also interesting is looking at some of the work that you put together on this historical exploration of technology. A lot of these metrics really are correlated. To some degree, it just doesn’t matter what you’re measuring, something dramatic has happened over the last 2000 years or the last 20,000 years. However, you want to measure it, either cultural revolution, neolithic revolution, industrial revolution. And it’s almost as if the human super-organism, all the human beings on planet earth are an optimization algorithm that’s just lashed onto some kind of optimum or local optimum or whatever. And we’re now climbing that gradient really steeply.
Jeremie (00:23:44):
Do you see AI as like a continuum limit of that? Is that just like the natural next step? Or should we think of it as a quantum leap, like a step function, things are just qualitatively different?
Ben (00:23:56):
Yeah. I think that’s a really good question. And I do think that this is a debate that exists in terms of how exactly to interpret the history of economic growth or increased social capacity. Or whatever kind of nebulous term you want to use to describe people’s ability to make stuff or change stuff or get stuff done in the world. And there’s actually a debate that exists for example, between different interpretations of the industrial revolution. So one interpretation of the industry revolution which occurred between roughly 1750 to 1850, in the UK and some surrounding countries is that up until the industrial revolution, growth was very stagnant. And then there was some change, some interesting pivot that happened that maybe took place over, maybe also another century on the other end of the industrial revolution. Where for some reason the pace of technological progress went up.
Ben (00:24:55):
And people switched away from an agriculturally based economy to industrial economy. And people started using non-organic sources of energy. So it’s no longer wood and animal fertilizer. It’s now fossil fuels and energy transmitted by electricity and stuff like this. And R&D is now playing a role in economic growth, which previously it didn’t really. And there’s some interesting phase transition or something that happened over a couple 100 years. We just transitioned from one economy to almost like a qualitatively different economy that could just grow and change faster.
Ben (00:25:29):
There’s another interpretation now that basically says that there’s actually this long run trend across at least the history of human civilization of the rate of growth getting faster and faster. And this interpretation says that as the overall scale of the economy increases, for that reason, the growth rate itself, just growth keeps going up and up. And this interesting feedback loop where the scale of the economy kept getting bigger and growth rate kept getting larger and larger and really visibly exploded in the industrial revolution. Just because this is where the pace finally became fast enough for people to notice this, but there was actually like a pretty consistent trend. It wasn’t really a phase transition.
Ben (00:26:12):
And there’s some recent work by for example, David Roodman, who’s an economist who does work for the Open Philanthropy Project. There’s a recent report he wrote I think, modeling the human trajectory, which argues or explores this continuous perspective. And there’s a debate in economic history as well. So there’s an economist, Michael Kramer has argued for this smooth acceleration perspective and lots of economic historians who have argued. Actually, there’s some weird thing where you switch from one economy to another.
Ben (00:26:42):
I’ll just say that there’s competing interpretations. So one just says every once in a while, it’s a bit weird, it’s a bit idiosyncratic. Something happens, some change that’s a bit discontinuous. And we switched to a new economy that can grow faster. And another interpretation says, no, actually this is a pretty consistent forest. Just things keep getting faster and faster, and it’s not phase transitions and it’s not discontinuity, it’s just there’s a smooth, really long run trend of just the world keeps accelerating more and more
Jeremie (00:27:11):
It’s interesting how that entangles almost like two different sub-problems. One of them is do humans learn almost continuously? In other words, is it the case that cave people were gradually generation on generation actually picking up more and more skills as they went, that it only become obvious when you look over like 10,000 years. Or is it the case that no, they’re basically stagnant, everything is truly flat and then you get some takeoff. It almost feels like this could be viewed as part of an even deeper question where if you keep zooming out and keeps zooming out. It no longer becomes a story of humanity iterating towards some future economy with AI is taking over. But rather moving from completely a biotic matter and the big bang, purely no value creation whatsoever to…
Jeremie (00:28:01):
I guess that has to be a step function, that first moment where life evolves. This is where I’m curious about, that perspective would seem to argue for more the quantum leap angle or the step function approach, unless I’m mistaken.
Ben (00:28:15):
Yeah. So I think that’s right. Definitely at least intuitively there’s certain transitions in history where it really seems like just something different happening. So the first self-replicating thing that can qualify as a life form, it seems like that has to be like a fairly discrete boundary in some sense. Or those things like, I really don’t know evolutionary history, but I think first you carry out something like mitochondria became part of the cell. This is a fairly discrete event, I believe where one of the organisms were smaller than the other, [inaudible 00:28:48] in it and the whole eukaryotic branch of life evolved from that. And various interesting things like people falling from that, where that also seems like something that intuitively is a discontinuous change that I don’t exactly know.
Ben (00:29:06):
So it does seem like intuitively there are certain things. And then another one as well is even in the industrial revolution where people were starting to do agriculture in a big way. I think the general thinking is that this was actually fairly rapid in a historical sense or things that could qualify as humans have existed for 10s of 1,000s of years. And then maybe over the course of a few 1,000 years people in like Western Asia and later other continents, transitioned to sedentary agricultural civilizations.
Ben (00:29:35):
And I think the thought is you had like a massive ice age for 100,000 years roughly, and then the ice age ended. And the climate changed and it became in some ways more favorable for people actually transitioning to sedentary agriculture, and then it just happened very, fairly quickly. So yeah, I do think that you’re right that there are some historical cases where it really does feel like at least without me personally knowing a lot about them, it feels like a discontinuous change. And I do also think that will probably be the case to some extent for AI. I don’t think it’s going to be a, you wake up tomorrow thing. But I do think that if we eventually reach full automation or if the growth rate again increases due to AI. People probably won’t look at it just as a stable continuation of economic trends that have existed since 1950. That right now we have this very steady rate of economic growth and we have this pretty steady filling rate of automation. And if the growth rate ever goes nuts, I think that people will feel like there was some inflection point or pivot point or some tipping point involved there.
Jeremie (00:30:36):
That’s actually as good a transition point as any of that could imagine to the second area you’ve been looking at that I really want to discuss, which is your views on AI safety… Not AI safety necessarily, let’s say AI risk and this idea of a smooth transition to an AI powered world, or let’s say a very abrupt transition to a kind of dystopic or existentially deadly scenario. So do you have some views on this? Maybe I’m just going to kick things off with that. So can you lay your thoughts are on where you think the AI risk argument is strong and maybe where it fails?
Ben (00:31:14):
Yeah. So I think I might just initially say a little bit about the continuity question or at least the relevance to the continuity question. So as you alluded to, this is also the debate people have about AI is how abrupt will the… Let’s assume we eventually get to a world where AI systems can basically make human labor obsolete and do all sorts of other crazy things. How abrupt transition will that be? Will it be the sort of thing, like an analogy to the industry revolution, where it’s a period of many decades and it’s this gradual thing that spreads across the world in a gradual way?
Ben (00:31:48):
I think even things like, steam power, people transitioning from not using fossil fuels to using them, that was an extremely long transition. Will it be more like those cases or will it be something that feels a lot more abrupt? Will there, for example be a point like a two-year period, where we went from stuff being basically normal to now everything is AI or even less than two years. And this is the debate that sometimes happens in the long-termist or futuristic [inaudible 00:32:15]. And it seems relevant in some ways where one of, and some ways should be something that increases risk or eventually reduces it.
Ben (00:32:24):
So in terms of increasing risk, one thing that a sudden, or really rapid change implies is it can come a little bit out of nowhere. So it’s very continuous, you see a lot of stuff that’s happening coming well ahead of time. Whereas if it’s really sudden, if it’s a process that would take two years, and that means that in principle two years from now, we could be living in a very different world if it just happens to happens. And there’s less time to get prepared and less time to get used to different intermediate levels of difference and do trial and error learning and get a sense of what the risks are. What the risks aren’t. If we talk this out and realize opportunity to see how to find and get used to the problems and come up with intermediate solutions and learn from your mistakes. And I think the largest risk with this is probably relevant to risks related to misaligned AI which is, I guess, the last major category of risk. And these are also a little bit diverse and I believe you’ve had some previous people on the podcast talk about them.
Ben (00:33:21):
But a lot of the concerns is basically boiled down to lots of AI systems we develop in the future will probably to some extent behave as though they’re pursuing certain objectives. Or trying to maximize certain things about the world. In the sense that like [inaudible 00:33:35] and the system makes predictions about offense rates in a criminal justice perspective is in a sense, trying to increase predictive accuracy or that sort of thing. And the concern is that the goal is that AI systems have will in some sense diverge and [inaudible 00:33:58] people tend to have, and that this will lead to disastrous outcome. We have AI systems which are quite clever and quite good at achieving whatever goals they have just doing things that differ from what people want.
Ben (00:34:12):
So speed is really relevant to this because if you think that this is going to be this pervasive issue of someone creates an AI system and deploys it. And then there’s some sort of divergence between it’s goals and goals that people have, and this causes harm. It seems like if there’s a really continuous transition to AI systems playing larger and larger roles in the world, that there’s probably quite a lot of time to know this less catastrophic versions of this concern or learn what works or doesn’t work. Not everyone is fully convinced that just gradualness and trial and error is enough to completely resolve the issue. But it seems like surely it’s helpful to actually be able to see more minor versions of the concern and come up with solutions that work in minor cases. Always this stuff is very sudden then, and let’s say we wake up tomorrow and we have AI systems that in principle can just completely replace human labor, could run governments, could do whatever.
Ben (00:34:59):
If we, for whatever reason, decide to use them. And they had goals which were different than ours in some important way, then this is probably a lot more concerning and we might not see issues coming. Yeah. So I guess to your question, what are the reasons why this might not be a major concern or just what’s the set of arguments for it being a concern one way or the other?
Jeremie (00:35:21):
Well, actually I think there’s an even more specific concern that you’ve taken a lot of time to unpack. And it’s this concern around the argument that Nick Bostrom makes in his book, Superintelligence. Just to briefly summarize, to tee it up here, the idea is, and I’m going to butcher this and please feel free to highlight the various ways in which I butcher this. But the idea is something like, if we assume that AI teams, let’s say OpenAI and DeepMind and whatever else are gradually iterating and iterating and iterating. One day, one of them has an insight or purchases, a whole bunch of compute, or gets access to a whole bunch of data. That’s just the one thing that’s needed to bump a system from like pathetic, little GPT-3 to now all of a sudden human level or above.
Jeremie (00:36:06):
That system because it’s human level or above, it may know how to improve itself because humans know how to improve the AI systems. So maybe it figures out how to improve itself and you get some recursive loop because loops very tight, the AI can improve itself. And eventually it’s so smart that it can overpower, let’s say its captors with its intelligence and take over the world and lead to a completely disastrous outcome. Is that at least roughly right?
Ben (00:36:30):
Yeah. So I think that’s basically roughly right. Yeah. So one way to think about is I think there’s a spectrum of these alignment concerns. And some of them are in the more, maybe the future nebulous perspective where we create lots of AI systems gradually over time and their goals are different from ours and there’s a gradual loss of control of the future and that sort of thing. And there’s so much more extreme where it’s like there’s a single AI system and arrives quite suddenly. And it’s in some sense broadly superintelligence and it doesn’t really have major precedents. And that system individually quite rapidly causes havoc in world, like there’s some major jump to this one single very disruptive system which is definitely the version of concern. It’s emphasized in things like Nick’s book Superintelligence and then the narrative, I guess you just described.
Ben (00:37:18):
So a lot of my own thinking about AI risk has been a lot about this more extreme end of the spectrum so that concern appears in places like superintelligence for a couple of reasons. One I think it’s the version of I first encountered and that made me especially interested in it which I guess is a partial just personal reason for interest.
Ben (00:37:39):
And the other others I think that this is just, even if lots of AI alignment researchers, don’t primarily have this version of concern in mind. I think it’s still quite influential and pretty well-known. And often if someone knows anything about AI risk, this is the version of concern that comes to mind. So that sounds I think it’s maybe a special worth paying attention. So some of my thinking has been just about the question of like it plausible that you actually have this very sudden jump from you don’t really have major AI systems of interest what is a bit like it is today. And then suddenly some researcher somewhere has this major breakthrough and you end up with this single system. And I guess I’m fairly skeptical of this for maybe boring reasons.
Ben (00:38:15):
So one initial boring reason is just that’s not the way technology tends to work. If you start from the perspective of like, let’s look at how technology normally transforms the world. It’s normally the case that it’s this a protractive process that takes decades where someone develops something and then it’s a long process of improvement. And then it’s the point in some sectors before other sectors and it’s useful in some areas before other areas. And then people need to develop complimentary inventions to take advantage of it. And people need to figure out how to actually use it appropriately. And there’s lots of tweaking and issues you don’t foresee that make it a slow process. So like electricity it’s, I think the electric motor sometime in the early 19th century, I believe it’s invented. But then electric motors don’t predominant in American factories until something the 1930s.
Ben (00:39:02):
Or the first digital computers middle of the 20th century but from like ’90s, that they really show up in productivity statistics in a big way. And even then, not really and still loads of countries, not like that pervasively used in different important contexts. And even not in a sense like that larger portion of the economy. So it becomes a start from there and it’s like you don’t look too specifically at the details of AI and say like, “What would I expect if it’s like any other technology we’ve ever had?” Probably it’s economic transformation, it’s going to be a gradual thing, lots of annoying stuff that happens.
Jeremie (00:39:35):
To just to probe at that a little bit. So one of the things that I would imagine has made the progress and distribution of technology accelerate in the last 100 years for whatever period we choose is precisely communication. We talked about that quite a few times, the role the internet played and so on. And communication in particular, in terms of tightening feedback loops between the teams of people who design product, the teams of people who deploy it, the teams of people who sell it and so on. To the extent that integration that coherence is driven by communication. Would that undermine this argument in a sense of saying, “Well, if you have a single AI system that’s internally coherent and that’s able to essentially tighten that feedback loop, not infinitely but to machine time.” Do you find that that position interesting, I guess, is what I’m trying to ask?
Ben (00:40:28):
So I guess I find it interesting, but not persuasive. So I’d say there’s the idea of like if we jump to imagine that there’s a sudden jump to some extremely broadly capable AI system that just can serve you all of the economically relevant production tasks. It can do mining for chips, it can run ballot polling centers, it can do AI research, it can build more compute resources, it can manage without military strategic. If we imagine that there’s a single system that just abruptly comes into existence, that’s just itself doing all of this without interacting with outside factors or pulling on external resources. It does seem like there’s some intuition of like, stuff can happen faster because the communication efficiency costs have just gone down a lot. But there’s the questions like, should we imagine that this is the way development will work? That there’ll be like one single system that just abruptly gets all these capabilities. And I guess that’s something that I’m probably skeptical of in the case of AI and also again for somewhat boring reasons.
Ben (00:41:32):
So we do know that you can have progress in different areas at the same time. So something like the… I imagine probably a lot of your listeners are familiar with this, language models or this recent system GPT-3 developed by OpenAI. This is an example of a system that got pretty good at lots of different tasks through a single training process roughly the same time. So I was trained on a large corpus of basically webpages. And I was trained to basically try and predict what’s the least surprising, next word I could encounter on the basis of the words I’ve already encountered in a document I’m exposed to.
Ben (00:42:08):
So you can use it to do stuff like write a headline for a news article, and then I’ll try and think what’s the least surprising text for an article given this headline. And one thing people find is you can actually use it to do a lot of different stuff. So you can use it to do translation, for example, we can write a sentence in Spanish and say the English translation, the sentence is blank is calling. And the system will go out at least surprising thing to find next would basically be like the English translation of it and use it to write poetry. What’s the least surprising ending to this Emily Dickinson poem and that sort of thing.
Ben (00:42:42):
But even in these cases where lots of different capabilities in some sense, come online at once. You do still definitely see AI variation in terms of how good it is at different stuff. So it’s pretty bad for the most part at writing, like usable computer code. You can do a little bit of this, but basically can’t do it in a useful way at the moment. It’s pretty good at writing like Jabberwocky style poems, one of these came before the other. And there’s reason to think that can even be the case that’s going to be like an expanding thing where some capabilities come before others. There’s also some capabilities that you can’t really produce just purely through this GPT-3 style, train it on this large corpus of online things.
Ben (00:43:23):
If you want to translate the Department of Defense internal memos, it needs to be trained on something else. If you want it to write like healthcare legislation, probably [inaudible 00:43:30] is not going to do it for you. If you want it to set supermarket prices, at price inventory thing, or you personalize emails where it knows actually when to schedule meetings for you. You’re going to need a different training method. Or if you want to perform better than humans, you’re going to need a different training method as well, because you need to give it like… What it basically does is to try to say what would be the least surprising thing for person to have written on the internet. But if you want to do better than a person you’re going to need to use something else, some sort of feedback mechanism.
Ben (00:43:55):
So basically the reason I think different capabilities will come online at different times. There’ll also probably be lots of annoying stuff that comes up in different specific domains that doesn’t really show up to researchers. But tends to come up when you want to apply stuff like a law of going from [inaudible 00:44:07] to people actually using electric motors in factories, it’s like, you need to redesign your factory floor. Because it’s no longer based around the central steam engine. You need to redesign the things that’s using the hardware, you need redesign the processes that your workers use is actually leverage this thing. You have regulations that need to happen, et cetera, et cetera. And probably these things would need to be dealt with to some extent, at least initially by different teams. And some of them will be harder than others or require different resources than others. And I would basically be surprised if, this has been like a long way of saying I expect stuff to come online, that’d actually be really useful in the world at pretty different points for different tasks.
Jeremie (00:44:40):
Interesting. Yeah, that makes perfect sense. And what’s interesting to me is it’s exactly the kind of error that a theorist would make, imagining a system that… And not that it is an error, this scenario could easily come to pass. But these are interesting objections that seem to map onto the psychology of somebody who’s focused on theoretical optimization rather than optimization of systems and economies in practice. Interesting. So none of this though, seems to suggest that it would not be possible at some point in the future for an AI system with the ability to self-improve iteratively and [crosstalk 00:45:21] to be developed.
Jeremie (00:45:23):
So there’s two parts to this question. First off, A, do you think that that’s the case, or do you think that it will be possible to build such a system? And B, do you think such a system will be built or is likely to be built? Is there a series of incentives that stacks up to get us to a recursively self-improving AI that just goes [foom 00:45:47], eventually and does whatever? Is that a plausible story?
Ben (00:45:51):
Yeah. So I have a couple of bits here. So first bit is it’s unclear to me that recursive self-improvement will really be the thing. So clearly there are feedback loops and will be feedback loops in the future. So we see lots of technologies in a more limited way. So the existence software is useful for developing software. Software developers use software and computers are useful for designing computers. If people like Nvidia or any sort of hardware manufacturer didn’t have computers to use, they would probably find their jobs quite a bit harder. So there’s loads of cases where technologies where the aided design development or a technology aided development for another technology. It’s typically not recursive, or it’s not typically exactly the same artifact that’s improving itself.
Ben (00:46:44):
And in the case of AI, I don’t necessarily see a good reason to expect it to be recursive. I definitely expect AI to be applied more and more in the context of AI development searching for the right architecture. Or learning, figuring out what’s the most optimal way to basically develop another system or make it work well. But I don’t necessarily see a strong reason to think that’s the individual system doing it to itself, as opposed to a system that’s developed to help train other systems. The same way like software doesn’t tend to improve itself. I don’t really see a great benefit to it being recursive. It could be the case if that’s done, but I don’t see why it would be recursive, why that’s inherently more attractive. In some ways it seems maybe less attractive. It seems like somehow messier or it seems nice if this is a bit of a modular thing.
Jeremie (00:47:33):
Yeah, I guess, to some degree, just to bolster this argument a little bit from an engineering standpoint, I would imagine that… So there’s this abstraction of different systems, this term that we use to say there’s system A, there’s system, B. System A’s either improving itself or system B’s improving it, and then maybe system A… All that stuff. I guess what I’d thinking of in this case is an abstraction that covers something like a closed system that crucially operates on machine time. So the key distinction to my mind that would define like a takeoff of this form would be the fact that this either self-optimization or system A improves system B happens on the order of like microseconds. Or what have you such that humans do not intercede in the process and are ultimately surprised by the results where the results would deviate significantly from our expectations.
Ben (00:48:33):
Yeah. So I think maybe one of the key distinctions is labor basically involved in the improvement process. So one general counter to this AI feedback loop being really important to really increasing the rate of change that much. I guess we do already do have these feedback loops where loads of tasks that researchers or engineers would have been doing at the beginning of the 20th century, they just don’t do anymore. They’ve just been completely automated. So just actually doing calculations by hand is like a huge time sink. It’s like research effort for engineering. So there’s been massive, massive automation, in terms of the time that people spent doing, a huge portion of it’s been automated either way. So in that sense, there’s been this really strong feedback loop where technological progress has helped technological progress.
Ben (00:49:25):
But at least since the middle of the 20th century, we haven’t seen an increase in the rate of productivity growth, like technological progress, at least in leading countries. It seems to have actually gone slower, if anything. And the rate now is comparable to the beginning of the 20th century in the U.S.. So clearly this feedback loop isn’t enough on its own and there’s an offsetting thing and probably to mean the same thing as like this idea is getting hard to find phenomenon. Where technology helps you make new stuff, but also each new thing you want to make is a bit harder to make from the previous thing. Because if it was easy, you would’ve already done it. So that’s one general counter argument.
Ben (00:50:01):
And then the counter, counter argument to that is like, well this whole time that we’ve been automating lots of the tasks involved in research and then creating machines to do them and then improving the machines. Human labor has always been a part of it. And if you have this story where human labor stuffed on by capital basically is complementary. I think we have labor bottlenecks story where we keep making cooler machines and we keep making more machines. But there’s diminishing returns on the coolness of your machines or the quantity of your machines for fixed amount of research effort. So research effort’s really the bottleneck. It creates this diminishing returns phenomenon where it really limits the marginal value of the additional cool tech stuff that’s involved, done by researchers or owned by researchers. And then the number of researchers grows at this pretty constant exponential rate that can’t really be changed that easily because it’s linked to the population and things like that.
Ben (00:50:57):
So then I was talking, if you actually remove just human labor completely from the picture, just people are just not involved in R&D anymore or manufacturing. Then maybe in that case you no longer have this diminishing returns effect, you no longer have this bottleneck that you get diminishing returns on capital for like a fixed amount of labor. Maybe it just feeds back directly to itself, diminishing returns go away in some important sense. And then the feedback loop really takes off once you just completely remove humans from the loop, would be the story you could tell to say why the feedback loop will be different in the future than the non-explicit feedback loop we’ve had for the past century.
Jeremie (00:51:29):
And I guess there is a feedback of human self-improvement. I think clock time is the distinguishing characteristic here, but I do strive to improve myself in my productivity and I do strive to nail that myself. I try to improve the way I improve myself. In principle, I think I do that to an infinite number of derivatives or as close to that as matter. So there is an exponential quality to it, but clearly I’m not Elon Musk yet. I haven’t achieved hard take-off so there’s a difference there somewhere.
Ben (00:52:05):
Yeah. So I guess the thing I’d say there is probably that, I think you’re definitely right, that that’s a real phenomenon. I think though that the kind of orders of magnitude involved, how much you would have to self-improve is just smaller than it is for technology. So let’s imagine a researcher unit is a person in your laptop. And that’s the thing that produces the research. The person can actually make themselves better at coding and they can make themselves better at learning how to do things quickly, they can learn how to learn. But maybe the actual difference in productivity, maybe you can help to increase by like a factor of 10 in terms of human capital relative to what the average researcher in 2020 is. Whereas your laptop, it seems to get maybe has more [inaudible 00:52:44] to climb up in terms of how much better it can get than it is right now.
Jeremie (00:52:49):
That does unfortunately seem to be the case, but I just need to keep working at it. I think that’s what it needs.
Ben (00:52:56):
Yeah. I wish you best of luck in your race against your laptop’s rate of improvement.
Jeremie (00:52:59):
Yeah. Thanks. I’ll let you know if I hit take off. So that’s really interesting that you have done so much thinking on this and I can see in myself some shifts in terms of the way that you’re thinking about this, certainly there are aspects of it that I hadn’t considered before. That do come from this economics perspective that come from the systems perspective. Is this a way of thinking that you think is especially uncommon among technical AI safety people? Or are you starting to see that become adopted where… I’m still trying to piece together what the landscape looks like and how views have been shifting on this topic over time. Because just by way of example, I remember 2009, it was [inaudible 00:53:45]. Basically everybody was talking about this idea of a brain in a box or some fast takeoff thing where a machine self improves and so on.
Jeremie (00:53:54):
Whereas now it really does seem like between OpenAI, Paul Christiano, and a lot of the work being done at Future of Humanity Institute, things are shifting. And I’d love to get your perspective on that shift, that timeline and where the community now stands with respect to all these theses.
Ben (00:54:11):
Yeah. So I do definitely think there’s been a shift in the way, let’s say the median person in these communities is thinking about it. It’s a little bit ambiguous to me how much of it is a shift in terms of people who used to think one way shifting to another way of thinking. Versus more people entering the community with a preexisting different way of thinking. I do think that there is some element of people thinking about things in a bit more of a concrete way. What you think a lot of the older analysis, it’s very abstract. It’s very much relying on… It’s not exactly like mathematical, it’s like people doing an abstract algebra or something. But it’s definitely maybe like a more mathematical mindset.
Ben (00:54:58):
And it’s shifted over time. And I think one reason for that, which is very justifiable, it’s just when people are talking about this in the mid 2000s. Machine learning, wasn’t really a huge thing. People thought it would be more maybe logic oriented systems would be what maybe AGI would look like. Anything that really looked at all AGI-ish to really use as a model to think about. And I think as machine learning from took off and people started to have these systems, something like GPT-3 where obviously this is not AGI and probably AGI will be very different than that. It’s like a little bit of a stepping stone in the path to AGI. It’s like a little bit maybe AGI-ish or something.
Ben (00:55:41):
I think having these concrete examples just leads you to start thinking in a slightly different way. Where start to realize that they’re actually a little bit hard to describe in the context of maybe these abstract frameworks that you had before. So GPT-3 does it have a goal or if you want to predict this behavior, how useful. I guess it’s goal is to produce whatever next word would be unsurprising, but it’s somewhat doesn’t exactly feel right to think that way. It’s not clear how useful it is for predicting this behavior. It doesn’t really seem like there’s a risk of it doing something crazy like killing people to prevent them from stopping it from outputting. Somehow it just feels like it doesn’t really fit very well. And also just seeing more concrete applications and thinking… So I think just saying like Paul Christiano said, for example, to some extent being optimistic about, “Oh, I think you could actually probably do that thing with machine learning, not that far in the future without major breakthroughs.” Lends people to also think in a more continuous sense where it’s not all or nothing. It’s like you can see the stepping stones of intermediate transformations.
Ben (00:56:41):
So I think it’s seeing intermediate applications, having a bit more concreteness. And feeling a little bit like more skeptical of the abstract constituting, just because it’s hard to fit them onto the thing you’re seeing, or maybe some forces that have had an effect. Typically, I do definitely think that there are plenty of people who think that the more mathematical and classical way of approaching things is still quite useful or that may be the predominant way they approach things.
Jeremie (00:57:09):
Yeah. I actually have heard arguments… Not necessarily arguments that a system like GPT-3 would become pathological in the way you’ve described. But at least stories that can be told that sound internally consistent that describe worlds in which a system like that could go really badly wrong. In that case, it’s something like, imagine GPT-10, whatever the year would have to be for that to happen. And you had the system that necessarily, it is doing this like glorified auto-complete task. But in order to perform that task, one thing that seems clear is that it’s developing a fairly sophisticated model of the world. There’s some debate over the extent to which this is memorization versus actual generalizable learning. But let’s give GPT-3 the benefit of the doubt and assume it is generalizable learning. To the extent that that’s the case, the system continues to develop a more and more sophisticated model of the world, a larger and larger context window.
Jeremie (00:58:06):
Eventually that model of the world includes the fact that GPT-3 itself exists and is part of the world. Eventually this realization, as it tries to optimize its gradients makes it realize, “Oh I could develop direct control over my gradients through some kind of wire-heading,” is usually how it’s framed in the [crosstalk 00:58:25] community and so on. I think the problems that you described apply to this way of thinking. But it’s interesting how GPT-3 really has led to this concrete thinking about some of those abstracts.
Ben (00:58:39):
Yeah. I think it’s also very useful to have these concrete systems because I also think they force differences in intuition. Or force differences in comeback and assumptions to the surface. So just as one example, there’s definitely the cases that some people have expressed concern about these GPT systems or if you have GPT-10 then maybe this would be very dangerous. And I actually wouldn’t have guessed this. Or I guess I wouldn’t have guessed that other people had this intuition just because I didn’t have it. Because my baseline intuition is just basically too rough approximation the way the system works. It’s a model of some parameters and then it’s exposed to like a corpus of text. And it just basically outputs an X word and then the next word is actually right or it’s not. Or basically there’s a gradient that pushes the outputs to be less and less surprising relative to whatever the actual words in a data set are.
Ben (00:59:35):
It’s just basically being optimized for outputting words, which would be unsurprising to find as an X word in a piece of text, which is online somewhere. And when I think of GPT-10, I think, “Wow, I guess it just outputs words, which would be very unsurprising to find on webpages online.” It’s just like the thing that it does. And suppose, let’s say it does stuff like outputs words which lead people to destroy the world or something. It seems like it would only do that if those would be words that would be the most unsurprising to find online. If the words that lead it to destroy the world are not, would it be surprising to find online because people don’t normally write that sort of thing online. Then it seems like something weird has happened with the gradient descent process.
Jeremie (01:00:15):
So I think that’s a really great way to frame it. I believe the counter-argument to that might sound something like, we might look at human beings 200,000 years ago as sex optimizers or something like that. And then we find that we’re not that as our evolution has unfolded. I think the case here is that well, first off there’s a deep question as to what it is that a neural network actually is optimizing. It’s not actually clear that it’s optimizing its loss function or it feels a kick every time its gradients get updated. It goes like, “Oh, you’re wrong. Update all your rates by this.”
Jeremie (01:00:58):
Does that kick hurt? And if it does then, is that the true thing that’s being optimized by these systems? And then if that’s the case, then there’s this whole area obviously inner alignment that we’re skirting around here, but it’s a deep rabbit hole, I guess.
Ben (01:01:15):
So I sort of agree that there’s a distinction between the loss function that’s used when training the system and what this system acts like it’s trying to do. And there’s one really simple way of saying that is if you start with like a chess playing reinforcement learning system. And you have a reward function, that loss function associated with it, and you just haven’t trained it yet. It’s just not going to act like it’s trying to win at chess because that’s like one of the bluntest examples of like, it just doesn’t add up.
Ben (01:01:40):
And then obviously, you have these transplanting cases where you train a system in let’s say a video game where it gets points every time it opens a green box that’s on the left and on the right there’s like a red box. And you put it in a new environment where there’s a red box in the left and a green box on the right. And the training data you’ve given it so far, isn’t actually sufficient to distinguish, sounds like what is actually the thing that’s being rewarded. Is it for opening the red boxes or is it for opening the box on the left? And you shouldn’t be surprised if the system, for example, opens the box on the left, even though actually the thing that isn’t a loss function is the red box or vice versa. It wouldn’t be surprising if it’s generalized in the wrong way.
Ben (01:02:21):
So I certainly agree that there can generalization errors. I struggle to see why you would end up with, like in the case of something like GPT-3, I just don’t understand mechanistically what would be happening, where it would be… So let’s say that the concern is because it’s the text generation system that puts out some text where if it’s read by someone, it’s an engineering blueprint for something that kills everyone, let’s say. Which I don’t know if there’s like a non-sci-fi version of this where it leads to existential risk, but let’s say it’s the thing it does. I sometimes feel like I’m almost being… To answer or something or I’m missing something. But I just don’t understand mechanistically why would this grading design process lead it to have a policy that does that. Why would it in any way be optimized in that direction?
Jeremie (01:03:06):
The answer I would give, I’m sure not having put sufficient thought into this, I should preface. But is in principle, if we imagine, let’s say unlimited amount of compute, unlimited scale of data, and so on. This model would, let’s say it starts to think, and it thinks more and more and more and develops like a larger and larger and more complete picture of the world. Again, depending on what it’s trying to optimize, assuming it’s trying to optimize for minimizing its gradients. Here this is very course, I assume I’m wrong somehow, but somehow it feels like right to imagine that a neural network feels bad every time it gets kicked around. I don’t know.
Ben (01:03:47):
I don’t think it actually makes any sense, as much as it feels bad. I think it’s just, it has certain parameters and then it outputs something and it compares to the training set. And then based on the discrepancy, it’s [inaudible 01:04:02] kicked in a different direction. But I don’t think that there’s actually any internal… I don’t think there’s actually a meaningful sense which it feels bad. It has parameters that get nudged around by like a stick. It’s this guy with a stick, pushing the parameters in different directions on the basis of the discrepancy or lack of discrepancy, and then they eventually end up somewhere.
Jeremie (01:04:23):
Yeah. So this in and of itself is like, I think one of the coolest aspects. I’m about to get distracted by the inner alignment excitement here. But it’s one of the coolest aspects to me of the alignment debate, because it really gets you to the point of wondering about subjective experience and consciousness. Because there’s no way to have the conversation without saying, like, “This is some kind of learning process.” And learning process tends to produce an artifact like in humans, it’s a brain that seems to have some subjective experience, basically all life. You can look at an amoeba, move it around under a microscope. It really seems like it experiences pain and joy in different moments in different ways.
Jeremie (01:05:02):
So anyways, seeing these systems that behave in ways that could be interpreted similarly inspires at least in me questions about what is the link between the actual Mesa-objective, the function that the optimizer is really trying to improve and subjective experience. I’m going into territory I don’t understand nearly well enough. But maybe I can leave the thought at, I think this is a really exciting and interesting aspect of the problem as well. Do you think that consciousness and subjective experience have a role to play, the study of that in the context of these machines? Or are you-
Ben (01:05:44):
I think not so much of that. There’s a difficulty here where there’s obviously the different notions of consciousness people use. So I guess I predominantly think of it in I guess the David [inaudible 01:05:55] sense of conscious experience as this at least hypothesized phenomenological thing that’s not intrinsically a part of the… It’s not like a physical process, so it’s not a description of how something processes information. It’s an experience that’s layered on top of the mechanical stuff that happens in the brain. Whereas if you’re illusionist, you think that there is no such thing as this, and this is like a woo-woo thing. But I guess for that notion of consciousness, it doesn’t seem in a sense very directly relevant because it doesn’t actually have the weird aspects of it. It’s by definition or a hypothesis, not something that actually physically influences anything that’s happened somewhat behaviorally. And you could have zombies where they behave just the same way, but they don’t have this additional layer of consciousness on the top.
Ben (01:06:44):
So that version of consciousness, I don’t see as being very relevant to understanding how machine learning training works or how issues on MACE optimization work. And maybe there’s mechanistic things that people sometimes refer to using consciousness, which I think sometimes has to do with the information system. Somehow having representations of themselves is maybe one traits that people pick out sometimes when they use the term consciousness. It seems like maybe some of that stuff is relevant or maybe beliefs about what your own goals are, this sort of thing. Maybe this has some interesting relationship to optimization and human self-consciousness and things like that. So I could see a link there, but I guess this is all to say it depends a bit on the notion of consciousness that one has in mind.
Jeremie (01:07:38):
No, makes perfect sense. And it’s interesting how much these things do overlap with so many different areas from economics to theories of consciousness, theories of mind. Thanks so much for sharing your insights, Ben, I really appreciate it. Do you have a Twitter or a personal website that you’d like to share so people can check out your work because I think you’re working on fascinating stuff.
Ben (01:07:57):
Yeah. So I do have a personal website with very little on it, but there’s like a few papers I reference. That’s benmgarfinkel.com. And I have a Twitter account, but I’ve never tweeted from. I forget what my username is, but if you would like to find that and follow me, I may one day tweet from it.
Jeremie (01:08:15):
That is a compelling pitch. So everyone, look into the possibility of Ben tweeting some time.
Ben (01:08:22):
You could be among the first people to ever see a tweet from me if you get on the ground floor right now.
Jeremie (01:08:27):
They’re getting it at seed. This is time to invest seed stage. Awesome. Thanks so much, Ben. I will link to both those things including the Twitter.
Ben (01:08:36):
I look forward to the added Twitter followers.
Jeremie (01:08:40):
There you go. Yeah. Everybody, go and follow Ben, check out his website. And I’ll be posting some links as well in the blog post that will accompany this podcast just to… Some of the specific papers and pieces of work that Ben’s put together that we’ve referenced in this conversation because I think there’s a lot more to dig into there. So Ben, thanks a lot. Really appreciate it.
Ben (01:08:56):
Thanks so much. This was a super fun conversation.