
아무 것도 없
DataAnalytics(ko)
Deep Learning with Keras Cheat Sheet (2021), Python for Data Science -번역
KERAS 치트 시트 (2021), 데이터 과학을위한 파이썬으로 깊은 학습
2021 년에 깊은 학습을위한 초보자를위한 절대적인 기본 사항

Keras는 깊은 학습 모델을 개발하고 평가하기 위해 고급 신경 네트워크 API를 제공하는 Tensorflow를위한 강력하고 사용하기 쉬운 깊은 학습 라이브러리입니다.
KERAS를 최적화하여 다양한 깊은 학습 모델을 만드는 방법을 배우려면 아래 섹션을 확인하십시오.
섹션 :
1.기본 예제
2.데이터
삼.사전 처리
4.모델 아키텍처
5.컴파일 모델
6.모델 훈련
7.예측
8.모델의 성능을 평가하십시오
9.모델을 저장 / 다시로드하십시오
Basic Example
아래 코드는 KERAS를 사용하여 데이터 집합에서 깊은 학습 모델을 만들고 실행하는 기본 단계를 보여줍니다.
코드의 단계는 다음과 같습니다. loadi엔g 데이터를 전처리하고, 모델을 생성하고, 모델에 레이어를 추가하고, 데이터에 모델을 구성하고, 트레이닝 된 모델을 사용하여 테스트 세트에 대한 예측을하고, 마침내 모델의 성능을 평가하는 데이터를
& gt; & gt;numpy를 np로 가져 오기
& gt; & gt;Keras.Models 가져 오기 순차적으로
& gt; & gt;Keras.Layers에서 가져 오기 밀도
& gt; & gt;Keras.Datasets에서 Boston_Housing 가져 오기
& gt; & gt;(x_train, y_train), (x_test, y_test) = boston_housing.load_data ()
& gt; & gt;모델 = 순차 ()
& gt; & gt;model.add (빽빽한 (12, 활성화 = 'RELU', input_dim = 8))
& gt; & gt;model.add (빽빽한 (1))
& gt; & gt;model.compile (Optimizer = 'rmsprop', loss = 'mse', metrics = [ 'ma']))
& gt; & gt;model.fit (x_train, y_train, batch_size = 32, epochs = 15)
& gt; & gt;model.predict (x_test, batch_size = 32)
& gt; & gt;Score = model.evaluate (x_test, y_test, batch_size = 32)
Data
데이터를 숫자 배열로 저장하거나 숫자 배열 목록으로 저장해야합니다.이상적으로는 Sklearn.cross_validation의 train_test_split 모듈에도 해당하는 교육 및 테스트 세트의 데이터를 분리합니다.
예제 데이터 집합의 경우 Keras 라이브러리에 통합 된 Boson Housing DataSet을 사용할 수 있습니다.
& gt; & gt;Keras.Datasets에서 Boston_Housing 가져 오기
& gt; & gt;(x_train, y_train), (x_test, y_test) = boston_housing.load_data ()
Preprocessing
데이터 집합을 가져온 후 모델이 적합 할 준비가되지 않을 수 있습니다.이 경우 모델에 대한 데이터를 준비하기 위해 사전 처리를해야합니다.
범주 구성 기능 인코딩
0과 n_classes-1 사이의 값을 가진 대상 레이블을 인코딩합니다.
& gt; & gt;keras.utils 가져 오기 to_categorical.
& gt; & gt;y_train = to_categorical (y_train, num_classes)
& gt; & gt;y_test = to_categorical (y_test, num_classes)
Train and Test Sets
데이터 세트를 X 및 Y 변수 모두에 대한 교육 및 테스트 세트로 분할합니다.
& gt; & gt;SKLEARN.MODEL_SELECTION IMPORT TRAT_TEST_SPLIT.
& gt; & gt;x_train, x_test, y_train, y_test = train_test_split (x, y,
test_size = 0.33, random_state = 42)
Standardization
표준화는 평균 및 확장을 단위 분산으로 제거하여 기능입니다.
& gt; & gt;SKLEARN.PREPROPESSING 가져 오기 StandardScaler에서
& gt; & gt;스케일러 = StandardScaler (). 맞춤 (x_train)
& gt; & gt;Standardized_x = scaler.transform (x_train)
& gt; & gt;표준화 된 _x_test = scaler.transform (x_test)
Model Architecture
이 섹션에서는 레이어별로 다른 깊은 학습 모델 레이어를 구축하는 방법을 배우게됩니다.
순차 모델
순차적 인 모델은 각 층이 정확히 하나의 입력 텐서 및 하나의 출력 텐서를 갖는 평평한 층의 일반 스택에 적합합니다.이것은 일반적으로 어떤 모델에서도 추가 할 첫 번째 레이어입니다.
& gt; & gt;Keras.Models 가져 오기 순차적으로
& gt; & gt;모델 = 순차 ()
Artificial Neural Network (ANN)
깊은 학습 모델을 위해 사용되었습니다분류과회귀.
바이너리 분류 :
아래 코드는 바이너리 분류에 사용되는 ANN 모델의 예입니다 (0 또는 1로 클래스를 식별하십시오).코드는 모델에 3 개의 계층을 추가합니다.첫 번째는 입력 레이어이며 12 개의 노드가 있으며, 제 2 계층은 8 개의 노드를 가지며, 마지막 층은 출력 노드 또는 예측 된 것인 것입니다.
& gt; & gt;Keras.Layers에서 가져 오기 밀도
& gt; & gt;model.add (짙은 (12, input_dim = 8, kernel_initializer = '유니폼',
활성화 = 'RELU')))
& gt; & gt;model.add (빽빽한 (8, kernel_initializer = 'uniform', 활성화 = 'RELU'))
& gt; & gt;model.add (짙은 (1, kernel_initializer = 'uniform', 활성화 = 'sigmoid'))
멀티 클래스 분류 :
아래 코드는 다중 클래스 분류에 사용되는 앤 모델의 예입니다.코드는 모델에 4 개의 레이어를 추가합니다.첫 번째는 입력 레이어이며 52 개의 노드가 있으며, 두 번째는 오버 퍼팅을 줄이는 데 사용되는 드롭 아웃 층이며, 제 3 계층은 52 개의 노드를 가지며, 마지막 층은 특정 관찰이 10 가지 중 하나로 이동하는 확률 인 10 개의 노드를 가지고 있습니다.클래스.
& gt; & gt;Keras.Layers 가져 오기 드롭 아웃
& gt; & gt;model.add (조밀 한 (52, 활성화 = 'RELU'), input_shape = (78,))
& gt; & gt;model.add (드롭 아웃 (0.2))
& gt; & gt;model.add (빽빽한 (52, 활성화 = 'RELU'))
& gt; & gt;model.add (짙은 (10, 활성화 = 'softmax'))
회귀 :
아래 코드는 회귀에 사용되는 앤 모델의 예입니다.코드는 모델에 2 개의 레이어를 추가합니다.첫 번째는 64 개의 노드를 갖는 입력 계층이고, 제 2는 예측 된 값인 단지 1 개의 노드를 갖는 출력 계층이다.
& gt; & gt;model.add (조밀함 (64, 활성화 = 'RELU', input_dim = train_data.shape [1]))
& gt; & gt;
model.add (빽빽한 (1))
Convolution Neural Network (CNN)
깊은 학습 모델그림의 분류.이 모델은 상당히 복잡하며 아래 코드에서 볼 수있는 꽤 많은 레이어가 포함되어 있습니다.그 코드는 CNN 모델이 보이는 것의 기본 예를 제공합니다.
각 계층이 무엇을 확인하는지 이해하고 싶다면Keras 문서.
>>> from keras.layers import Activation,Conv2D,MaxPooling2D,Flatten >>> model2.add(Conv2D(32,(3,3),padding='same',input_shape=x_train.shape[1:]))
>>> model2.add(Activation('relu'))
>>> model2.add(Conv2D(32,(3,3)))
>>> model2.add(Activation('relu'))
>>> model2.add(MaxPooling2D(pool_size=(2,2)))
>>> model2.add(Dropout(0.25))
>>> model2.add(Conv2D(64,(3,3), padding='same'))
>>> model2.add(Activation('relu'))
>>> model2.add(Conv2D(64,(3, 3)))
>>> model2.add(Activation('relu'))
>>> model2.add(MaxPooling2D(pool_size=(2,2)))
>>> model2.add(Dropout(0.25))
>>> model2.add(Flatten())
>>> model2.add(Dense(512))
>>> model2.add(Activation('relu'))
>>> model2.add(Dropout(0.5))
>>> model2.add(Dense(num_classes))
>>> model2.add(Activation('softmax'))
Recurrent Neural Network (RNN)
깊은 학습 모델시간 시리즈.
아래 코드는 시계열에 사용되는 RNN 모델의 예입니다.코드는 모델에 3 개의 계층을 추가합니다.첫 번째 레이어는 입력 레이어이고, 두 번째 레이어는 긴 단기 메모리라고 불리는 것이며 세 번째 레이어는 출력 레이어이거나 모델에서 예측 된 것입니다.
& gt; & gt;keras.klayers 수입 embedding, lstm.
& gt; & gt;model.add (Empedding (20000,128))
& gt; & gt;model.add (lstm (128, dropout = 0.2, recurrent_dropout = 0.2))
& gt; & gt;model.add (빽빽한 (1, 활성화 = 'sigmoid'))
Compile Model
모델이 구성된 후에는 모델을 컴파일합니다.컴파일하면 모델을 훈련하고 평가하는 데 사용될 교육 구성 (최적화, 손실, 메트릭)을 사용하려는 작업을 지정합니다.
Ann : 바이너리 분류
바이너리 분류에 사용되는 Ann 모델에 대해 이러한 교육 구성을 사용하십시오.
& gt; & gt;model.compile (Optimizer = 'Adam',
손실 = 'binary_crossentropy',
메트릭 = [ '정확도'])
ANN: Multi-Class Classification
멀티 클래스 분류에 사용되는 앤 모델에 대해 이러한 교육 구성을 사용하십시오.
& gt; & gt;model.compile (Optimizer = 'rmsprop',
손실 = 'categorical_crossentropy',
메트릭 = [ '정확도'])
ANN: Regression
회귀 분석에 사용되는 앤 모델에 대해 이러한 교육 구성을 사용하십시오.
& gt; & gt;model.compile (Optimizer = 'rmsprop',
손실 = 'MSE',
메트릭 = [ 'mae'])
Recurrent Neural Network
RNN 모델에 대해 이러한 교육 구성을 사용하십시오.
& gt; & gt;model.compile (loss = 'binary_crossentropy',
Optimizer = 'Adam',
메트릭 = [ '정확도'])
Model Training
모델을 컴파일 한 후에는 이제 교육 세트에 맞게 맞게됩니다.배치 크기는 한 번에 모델에 얼마나 많은 관찰을 입력하는지 결정하고 epochs는 모델이 교육 세트에 맞게 원하는 횟수를 나타냅니다.
& gt; & gt;model.fit (x_train,
Y_Train,
batch_size = 32,
epochs = 15)
Prediction
숙련 된 모델을 사용하여 테스트 세트를 예측합니다
& gt; & gt;model.predict (x_test, batch_size = 32)
Evaluate Your Model’s Performace
테스트 세트에서 모델이 얼마나 잘 수행되는지 결정하십시오.
& gt; & gt;Score = model.evaluate (x_test, y_test, batch_size = 32)
Save/Reload Models
깊은 학습 모델은 훈련하고 실행하는 데 꽤 오랜 시간이 걸릴 수 있으므로 완료되면 다시 저장하고 다시로드 할 수 있으므로 해당 프로세스를 통과 할 필요가 없습니다.
& gt; & gt;keras.models 가져 오기 load_model.
& gt; & gt;model.save ( 'model_file.h5')
& gt; & gt;my_model = load_model ( 'my_model.h5')
Python은 현재 및 가까운 장래에 데이터 과학에 관해서 상위 개입니다.깊은 학습을위한 가장 강력한 라이브러리 중 하나 인 Keras에 대한 지식은 종종 오늘날 데이터 과학자들에게 요구 사항입니다.
이 치트 시트를 처음에 가이드로 사용하고 필요할 때 다시 돌아 오면 Keras Library를 마스터하는 방법에 잘 될 것입니다.
Keras 라이브러리와 함수에 대해 더 자세히 알고 싶다면 설명서를 확인하지 않았습니다.keras.,여전히 많은 유용한 기능이 있으므로 배워야합니다.
2K + 사람들이있는 내 이메일 목록에 가입하여 데이터 과학 치트 시트 소책자가 무료로 완전한 파이썬을 얻을 수 있습니다.
There is more to ‘pandas.read_csv()’ than meets the eye -번역
팁과 트릭
눈을 만나는 것보다 ‘pandas.read_csv ()’가 더 많이 있습니다.
깊은 다이빙은read_csv.팬지의 기능

팬더는 가장 널리 사용되는 도서관 중 하나입니다.데이터 과학생태계.이 다양한 라이브러리는 파이썬에서 데이터를 읽고 탐색하고 조작 할 수있는 도구를 제공합니다.팬더에서 데이터 가져 오기에 사용되는 기본 도구는 다음과 같습니다.read_csv ()...에이 함수는 쉼표로 구분 된 값, a.k.a, csv 파일의 파일 경로를 입력 한 다음 직접 팬더의 데이터 프레임을 반환합니다.ㅏ쉼표로 구분 된 값(CSV.)파일구분 된 것입니다텍스트 파일A.반점값을 분리합니다.
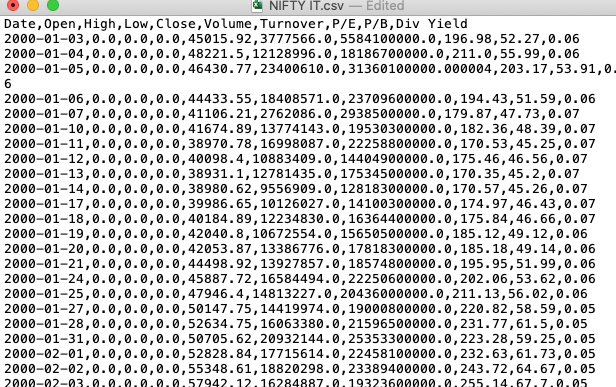
그만큼pandas.read_csv ()…을 … 한 것 매우 미세한 데이터 가져 오기를 허용하는 약 50 가지 선택적 호출 매개 변수.이 기사는 적은 알려진 매개 변수와 데이터 분석 작업에서 사용 중 일부를 터치합니다.
pandas.read_csv () 매개 변수
기본 매개 변수를 사용하여 팬더에서 CSV 파일을 가져 오는 구문은 다음과 같습니다.
PANDAS를 PD로 가져 오십시오
df = pd.read_csv (filepath)1. verbose
그만큼말 수가 많은매개 변수,로 설정된 경우진실다음과 같이 CSV 파일 읽기에 대한 추가 정보를 인쇄합니다.
- 유형 변환,
- 메모리 정리, 및
- 토큰 화.
PANDAS를 PD로 가져 오십시오
df = pd.read_csv ( 'fruits.csv', verbose = true)

2. Prefix
헤더는 모든 열의 내용에 대한 정보가 들어있는 CSV 파일의 행입니다.이름이 제안되면 파일 맨 위에 나타납니다.
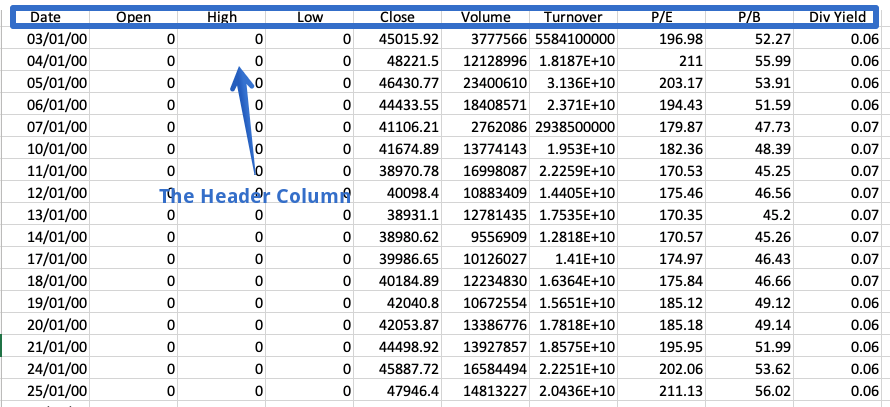
때로는 데이터 집합에 헤더가 포함되어 있지 않습니다.이러한 파일을 읽으려면 다음을 설정해야합니다.머리글명시 적으로 매개 변수;그렇지 않으면 첫 번째 행이 헤더로 간주됩니다.
df = pd.read_csv ( 'fruings.csv', header = 없음)
Df.

결과 데이터 프레임은 컬럼 이름 대신 열 번호로 구성되어 0부터 시작됩니다.또는 우리는 그를 사용할 수 있습니다접두사매개 변수는 열 번호에 추가 할 접두어를 생성합니다.
df = pd.read_csv ( 'fruings.csv', header = 없음, 접두어 = '열')
Df.
대신에기둥선택한 이름을 지정할 수 있습니다.
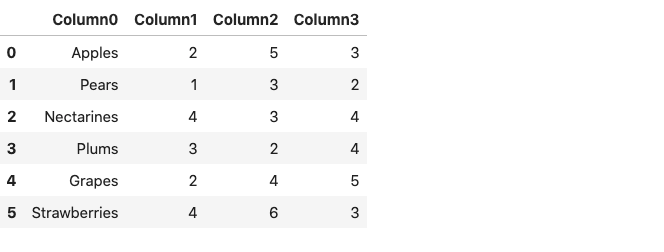
3. mangle_dupe_cols
데이터 프레임이 중복 된 열 이름으로 구성된 경우, ‘x’, ‘x’등mangle_dupe_cols.이름을 ‘x’, ‘x1’로 자동 변경하고 반복되는 열을 구별합니다.

df = pd.read_csv ( 'file.csv', mangle_dupe_cols = true)
Df.
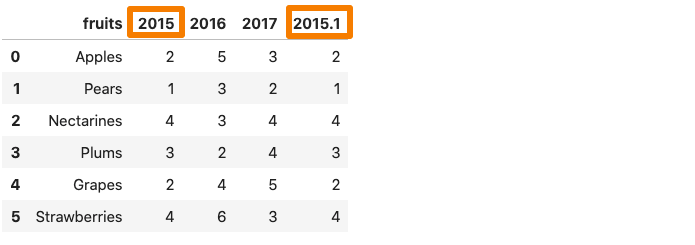
그 중 하나2015 년데이터 프레임의 열은 AS 로의 이름을 삭제합니다2015.1.…에
4. chunksize.
그만큼pandas.read_csv ()기능은 A.chunksize.매개 변수그것은 청크의 크기를 제어합니다.팬더에서 메모리 데이터 집합을로드하는 데 도움이됩니다.chunking을 사용하려면 처음에 청크의 크기를 선언해야합니다.이것은 우리가 반복 할 수있는 객체를 반환합니다.
chunk_size = 5000.
batch_no = 1.
pd.read_csv ( 'yellow_tripdata_2016-02.csv', chunksize = chunk_size)의 chunk의 경우 :
chunk.to_csv ( 'chunk'+ str (batch_no) + '. csv', index = false)
batch_no + = 1.
위의 예에서는 5000의 청크 크기를 선택합니다. 이는 한 번에 5000 줄의 데이터 만 가져올 수 있습니다.우리는 각각 5000 열의 다중 청크를 얻고 각 청크는 팬더 데이터 프레임으로 쉽게로드 될 수 있습니다.
df1 = pd.read_csv ( 'chunk1.csv')
df1.head ()
아래에 설명 된 기사에서 청킹에 대해 자세히 알아볼 수 있습니다.
5. 압축
많은 시간, 우리는 압축 된 파일을받습니다.잘,pandas.read_csv.이러한 압축 파일을 쉽게 처리 할 필요없이 쉽게 처리 할 수 있습니다.기본적으로 압축 매개 변수는 다음으로 설정됩니다미루다,자동으로 파일의 종류를 추론 할 수 있습니다그물,지퍼,BZ2.,xz.파일 확장명에서.
df = pd.read_csv ( 'sample.zip')또는 긴 형태 :df = pd.read_csv ( 'sample.zip', 압축 = 'zip')
6. thousands
데이터 집합의 열에 A.천분리 기호,pandas.read_csv ()그것을 정수가 아닌 문자열로 읽습니다.예를 들어 판매 열에 쉼표 구분 기호가 포함 된 위치에있는 데이터 집합을 고려하십시오.
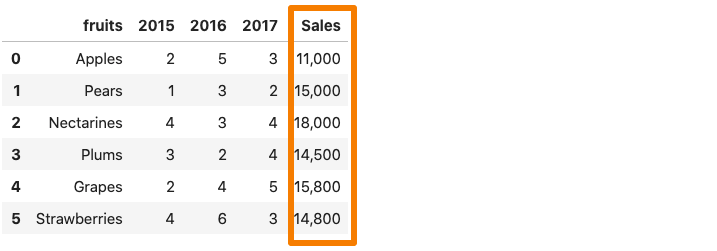
이제 위의 데이터 집합을 팬더 데이터 프레임으로 읽으려면매상열은 쉼표로 인해 문자열로 간주됩니다.
df = pd.read_csv ( 'sample.csv')
df.dtypes.

이것을 피하기 위해, 우리는 명시 적으로pandas.read_csv ()쉼표는 쉼표가 수천 개의 장소 표시기입니다.수천 명의매개 변수.
df = pd.read_csv ( 'sample.csv', 수천 = ',')
df.dtypes.

7. skip_blank_lines
빈 줄이 데이터 집합에 있으면 자동으로 건너 뜁니다.빈 줄을 NAN으로 해석하도록 원한다면skip_blank_lines.옵션은 false입니다.
8. 여러 CSV 파일을 읽습니다
이것은 매개 변수가 아니지만 유용한 팁입니다.팬더를 사용하여 여러 파일을 읽으려면 일반적으로 별도의 데이터 프레임이 필요합니다.예를 들어 아래 예제에서는 우리는pd.read_csv ()두 개의 별도의 파일을 두 개의 별개의 데이터 프레임으로 읽으려면 두 번 기능을 수행하십시오.
DF1 = PD.READ_CSV ( 'DATASET1.CSV')
df2 = pd.read_csv ( 'dataset2.csv')
이러한 여러 파일을 함께 읽는 한 가지 방법은 루프를 사용하는 것입니다.다음과 같이 파일 경로 목록을 만들고 목록을 반복합니다.
filenames = [ 'dataset1.csv', 'dataset2, csv']
데이터 프레임 = FILENAMES의 f에 대한 [PD.READ_CSV (f)]
많은 파일 이름이 비슷한 패턴을 가지고있을 때지구본파이썬 표준 라이브러리의 모듈은 편리합니다.우리는 먼저 그를 수입해야합니다지구본내장에서 기능지구본기준 치수.우리는 패턴을 사용합니다멋진 * .csv.접두사로 시작하는 모든 문자열을 일치시킵니다맵시 있는접미사로 끝납니다.csv.그 ‘*'(별표)야생 카드 문자입니다.그것은 0을 포함하여 모든 수의 표준 문자를 나타냅니다.
글로벌 가져 오기
filenames = glob.glob ( '멋진 * .csv')
파일 이름
----------------------------------------------------------------)------------------------------------
[ '멋진 Pharma.csv',
'멋진 it.csv',
'멋진 뱅크 .csv',
'nifty_data_2020.csv',
'nifty fmcg.csv']
위의 코드를 사용하면 멋진 CSV 파일 이름을 선택할 수 있습니다.이제 목록 이해 또는 루프를 사용하여 모든 것이 즉시 읽을 수 있습니다.
데이터 프레임 = FILENAMES의 f에 대한 [PD.READ_CSV (f)]
Conclusion
이 기사에서는 pandas.read_csv () 함수의 몇 가지 매개 변수를 살펴 보았습니다.그것은 유익한 기능이며 우리가 드물게 사용할 수있는 많은 인구 빌드 매개 변수가 제공됩니다.그렇게하지 않는 주요 이유 중 하나는 문서를 읽을 수 없기 때문입니다.중요한 정보가 포함될 수있는 중요한 정보를 발굴하기 위해 문서를 자세히 설명하는 것이 좋습니다.
Data Engineers of Netflix — Interview with Samuel Setegne -번역
Netflix의 데이터 엔지니어 – Samuel Setegne와의 인터뷰
이 게시물은 우리의 일부입니다“Netflix의 데이터 엔지니어”인터뷰 시리즈, 우리의 자체 데이터 엔지니어가 자신의 여정에 대해 이야기하는 곳데이터 공학 @ netflix.…에
Samuel Setegne.핵심 데이터 과학 및 엔지니어링 팀의 고위 소프트웨어 엔지니어입니다.Samuel과 그의 팀은 Netflix에서 데이터 엔지니어링 팀을 지원하는 도구 및 프레임 워크를 구축합니다.이 우편에서 Samuel은 데이터 공학 팀을 지원하기 위해 임상 연구원이되는 것에서 그의 여정에 대해 이야기합니다.
Samuel은 West PH에서 온다나는Ladelphia, 그리고 그는 성전 대학에서 석사 공학을 받았습니다.Netflix 이전에 Samuel은 데이터 과학 & amp에서 여행자 보험에서 일했습니다.부동산 청구의 발병시 심각도와 복잡성을 예측하는 실시간 기계 학습 모델을 구현하는 공학 공간.
그의 가장 좋아하는 TV 쇼 : Bojack Horseman.,마르코 폴로, 그리고요새
그의 가장 좋아하는 영화 :Scarface, 나는 전설과 오래된 경비원이다
샘, 데이터 공학을 위해 그려진 것은 무엇입니까?
일찍 경력에서 나는 임상 연구원으로서의 인생을 향해 완전한 속도를 향했다.많은 의료 종사자들은 경험적 연구에 대해 시험하기 위해 흥미로운 강한 굶주림과 야생 이론을 가지고있었습니다.나는 개인적으로 원시 데이터를보고 기술을 통해 세계의 패턴을 이해하기 위해 그것을 사용합니다.그러나 역할과 함께 온 대부분의 도전은 도메인 관련 이었지만 기술적으로 요구되지는 않습니다.예를 들어, 임상 데이터는 종종 평균 컴퓨터에 메모리에 맞추기에 충분히 작고 드문 경우에만 해당 계산에는 기술적 독창성 또는 대규모 컴퓨팅 전력이 필요합니다.일반적으로 큰 데이터 처리가 함께 제공되는 분산 및 대규모 컴퓨팅 문제를 탐색하는 범위가 충분하지 못했습니다.또한, 엔지니어링 속도는 종종 경질 과정으로 인해 희생됩니다.
순수한 데이터 공학으로 이사하는 것은 저에게 항상 갈망하는 기술적 어려움을 제공 할뿐만 아니라 두 세계에서 가장 좋은 데이터를 통해 점을 연결할 수있는 기회를 제공했습니다.
가장 좋아하는 프로젝트 또는 특히 자랑스러워하는 프로젝트는 무엇입니까?
Netflix 계약자가 모든 데이터 과학 및 엔지니어링의 모든 것을 마이그레이션 했으므로 최초의 프로젝트를 수행했습니다.파이썬 2 코드 Python 3 코드…에이것은 의심의 여지가 없었습니다. 제가적인 프로젝트가 전임 직원으로 조직에 가입하기 위해 문을 열었습니다.다양한 교차 기능 팀의 코드를 분석하고 다른 코딩 패턴과 스타일을 배우는 것은 스릴 있습니다.
이러한 종류의 노출은 나에게 다양한 데이터 엔지니어링 팀과 참여하고 Python Best Practices를 옹호하는 데 도움이되는 기회를 열었습니다.
What drew you to Netflix?
처음에는 Netflix에서 일할 기회에 대한 내 관심을 끌었으며 다양한 품질의 내용이었습니다.우리 가족과 친구들은 마르코 폴로와 타이거 킹처럼 보는 Netflix 쇼 나 영화에 대한 활기차고가 급한 대화를 나누는 것에 대해 항상 황홀했습니다.
다른 훌륭한 회사는 일상 생활에서 역할을 수행하지만 많은 사람들이 일종의 유틸리티로 사용되는 반면, Netflix는 새로운 목소리, 문화 및 관점을 경험할 수있게함으로써 우리를 살고 웃고, 사랑하게 만들 것입니다.…에
Netflix의 문화 메모를 읽은 후에 나는 완전히 판매되었습니다.전에 내가 전에 일한 곳에서 항상 알고 있었던 것을 정확하게 설명했습니다.나는 만트라를 발견했다“과정을 지닌 사람들”매우 상쾌하고 결국 기술적 인 디자인에서 저의 대담하고 창의적인 부분을 잠금 해제한다는 것을 알게되었습니다.예를 들어, 응용 프로그램이나 파이프 라인의 디자인이 새로운 기술이나 건축물의 혜택을 누릴 것이라고 느끼면 과도한 빨간 테이프없이 탐험하고 혁신 할 자유가 있습니다.일반적으로 대기업에서는 엄격하고 중복 된 프로세스에 연결되어 엔지니어에게 많은 피로가 발생합니다.내가 Netflix에 착륙했을 때, 우리가 자유와 책임에 기대고 엔지니어가 경계를 밀고 할 수 있도록하는 것은 신선한 공기의 숨을 멈 췄다.
Sam, how do you approach building tools/frameworks that can be used across data engineering teams?
제 팀은 일반 및 반복적 인 데이터 엔지니어링 작업을위한 일반화 된 솔루션을 제공합니다.이는 데이터 엔지니어링 팀을위한 “포장 된 경로”솔루션을 제공하고 휠을 다시 발명하는 부담을 줄입니다.…에고도로 숙련 된 엔지니어로 구성된 많은 전문 팀이있을 때 데이터 엔지니어에게 마지막으로 원하는 것은 크고 넓고 영향력있는 문제의 내부에 보통 묻혀있는 작은 문제를 해결하는 데 너무 많은 시간을 보내는 것입니다.우리가 모든 데이터 과학 & amp의 모든 엔지니어에게이를 외삽 할 때;엔지니어링 팀, 쉽게 추가하고 최적화 할 가치가있는 것입니다.
데이터 엔지니어 지출 사이클이 뇌의 데이터 엔지니어링 부분이 꺼져있는 작업에서 작업하는 시간을 보내면 더 나은 툴링이 도움이되는 기회입니다.
예를 들어 많은 데이터 엔지니어링 팀은 다운 스트림 종속성이있는 중요한 테이블을 변경할 때 알림 캠페인을 조정해야합니다.이는 데이터 엔지니어가 달성 할 수 있지만 변경 사항을 완료하는 것이 안전을 지키기 위해 이러한 다운 스트림 사용자의 마이그레이션을 새 테이블 또는 테이블 스키마로 추적하는 것이 매우 시간이 많이 걸릴 수 있습니다.이 문제는 데이터 엔지니어가 다운 스트림 사용자를 자동으로 식별하고 JIRA를 활용하여 알림 및 상태 추적 기능을 제공 할 수있는 “마이그레이션 캠페인”을 쉽게 시작할 수있는 “마이그레이션 캠페인”을 쉽게 시작할 수있는 중앙 숙련 된 팀 구성원 중 한 명이 해결되었습니다.목표는 데이터 엔지니어가 이러한 캠페인 중 하나를 신속하게 발사하고 다른 작업에 초점을 맞추기 위해 해당 추가 시간을 사용하는 동시에 이러한 캠페인 중 하나를 신속하게 발사 할 수있게하는 것입니다.
올바른 툴링을 투자하여 중복 (아직 필요한) 작업을 간소화하여 Netflix의 혁신을 가속시키면서 높은 데이터 엔지니어링 생산성과 효율성을 높일 수 있습니다.
더 많은 것을 배우십시오
Netflix의 데이터 역할에 대해 더 자세히 알고 싶습니까?당신은 올바른 곳에 있습니다!작업 사이트를 방문하여 데이터 과학 및 엔지니어링에서 열려있는 역할을 보관하십시오.여기…에우리의문화우리의 영향과 성장의 핵심입니다.여기…에Dhevi Rajendran과의 채팅을 확인하여 전염병 동안 데이터 엔지니어로서 새로운 역할을 시작하는 것에 대해 더 알고 있습니다.여기…에
8 Exciting Case Studies of Machine Learning Applications in Life Sciences and Biotechnology -번역
생명 과학 및 생명 공학의 기계 학습 응용 분야의 흥미로운 사례 연구
기술 산업으로 스릴과 성공한 산업

Covid-19는 우리에게 우리에게 집중하고 생명 과학과 생명 공학 산업에 대한 포커스를 만들었습니다.
건강은 우리의 가장 소중한 자산이며 건강을 유지하는 데는 비용이 들지 않습니다.그래서 생명 과학과 생명 공학 산업은 거대하고 매우 다양합니다.많은 하위부터…에가장 알려진 분야는 약물 발견 및 제조, 치료학, 진단, 치료학, 유전체학 및 프로테오믹스, 수의학 과학뿐만 아니라 화장품, 의료 기술 및 유통도 있습니다.
엄청난 양의 데이터가 Inh.이자형이 산업에 임대하십시오.데이터는 임상 시험, 약물, 치료법, 진단, 유전체학, 건강 관리 제공자 및 모든 개인 운동 데이터의 증가와 함께 사용할 수 있습니다.
생명 과학과 생명 공학은 많은 분야에서 큰 데이터 산업에 있습니다.
반면에 새로운 치료법, 약물 또는 백신을 개발하는 데 드는 비용은 거의 10 억 달러의 달러와 희귀 한 질병을 위해 2 자리 10 억 달러를 시작합니다.비교, Biontech와 Moderna를 위해 각 회사는 백신 개발을 위해 거의 10 억 달러의 외부 자금을 받았습니다.총 개발 비용은 대중이 아니지만 그 중 배수를 가정합니다.
이것들은 엄청난 투자량이며, 업계는 비용과 비용을 줄이고 치료법과 치료법을 더 빠르게 만들기위한 모든 노력을 기울이고 있습니다.따라서 업계는 기술 산업으로 데이터 주도적입니다.
그래서 생명 과학과 생명 공학 산업은 데이터 과학자들을위한 낙원입니다.플레이어는 많은 양의 데이터가 있으며 데이터 과학자는 매일 큰 데이터 영역에서 작동합니다.
많은 데이터 과학자 들이이 업계에 익숙하지 않습니다.하나의 엔트리 장벽은 해당 분야에서 주제를 이해하고 작업하는 데 필요한 매우 전문화 된 지식입니다.
둘째, 인과 관계 및 정밀도는 중요성이 높고 깊은 수학 및 (바이오) 통계적 배경이 많이 필요합니다.알고리즘이 대규모 기술 회사 중 하나의 서비스 사용자에게 잘못된 광고로 이어지면 아무 일도 일어나지 않습니다.알고리즘이 마약 개발의 잘못된 결정으로 인도하면 투자 또는 죽은 사람에 대한 대규모 손실이 발생할 수 있습니다.
나는 수년 동안 생명 과학과 생명 공학 산업에서 데이터 과학 컨설턴트로 일했습니다.그리고 나는 항상 내가 항상 가장 복잡하고 흥미로운 문제를 해결하기 때문에 그것을 좋아했습니다.
이 흥미 진진한 산업에 대한 통찰력을 가져 오려면 8 개의 실제 데이터 과학 사용 사례를 제시합니다.이렇게하면 응용 프로그램의 인상을주고 해당 분야에 대한 필수 비즈니스 지식을 익히십시오.
제약, 생명 과학 및 생명 공학에 데이터 과학자가 부족합니다.결국, 나는 당신이 기술 산업만큼이나 급수적 인 흥미 진진한 산업으로 움직이는 동기를 부여 할 수 있습니다.
1. 미생물 치료제의 개발
우리는 박테리아, 곰팡이, 바이러스 및 기타 단일 세포 유기체와 같은 소위 미생물을 소위 미생물 소위 소위 미생물을 보유하고 있습니다.미생물의 모든 유전자는 미생물로 알려져 있습니다.이들 유전자의 수는 수조이고, 예를 들어, 인체의 박테리아는 인간보다 100 배 이상의 독특한 유전자를 갖는다.
미생물은 인간의 건강에 막대한 영향을 미치고, 불균형은 파킨슨 병이나 염증성 장 질환과 같은 많은 장애를 일으키고 있습니다.그러한 불균형이 여러 가지자가 면역 질환을 일으키는 것도 추정됩니다.그래서 미생물 연구는 매우 유행이 많은 연구 분야입니다.
미생물에 영향을 미치고 미생물 치료제를 역전시키기 위해 미생물 치료제를 개발하기 위해 미생물의 유전자와 우리의 몸에 영향을 미치는 것이 필요합니다.오늘날 모든 유전자 시퀀싱 가능성을 통해 데이터의 테라 바이트는 이용 가능하지만 아직 조사되지는 않습니다.
미생물 표적 처리를 개발하고 미생물 약물 상호 작용을 예측하기 위해서는 하나의 요구가 먼저 그러한 상호 의존성을 알아야합니다.그리고 이것은 기계 학습이 오는 곳입니다.
첫 번째 단계는 패턴을 찾는 것입니다.한 가지 예는 모터 뉴런 질병, 즉 골격근 활동을위한 세포를 파괴하는 장애, 즉 근육을 더 이상 통제 할 수없는 장애를 일으키는 장애의 불균형이다.일반적으로 1000 명 이상의 개인 매개 변수가 포함됩니다.Supervised ML 및 보강 학습은 해당 단계의 주 알고리즘입니다.
투약 형태, 약물 용해도, 약물 안정성 및 약물 관리와 치료법을 설계하기 위해 약물 투여 및 제조와 같은 수백 가지 요인을 고려해야합니다.예를 들어, 임의의 숲은 종종 마약 안정성을 중심으로 질문에 사용됩니다.
마지막 단계는 치료법의 개인화입니다.이를 위해서는 미생물 및 약물의 반응과 상호 작용을 예측해야합니다.원칙 구성 요소 분석 다음에 감독 된 학습 알고리즘이 뒤 따르는 것은 표준 기술입니다.이 단계에서 가장 큰 도전은 여전히 모델을 훈련시키는 큰 데이터베이스가 부족합니다.
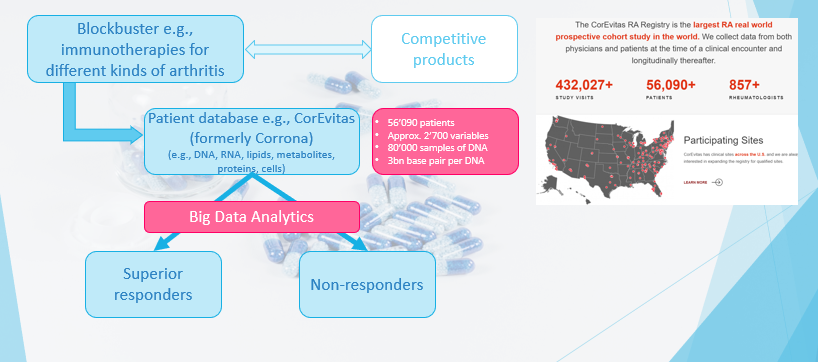
2. 류마티스 관절염 블록버스터의 정밀 약
블록버스터는 10 억 달러 이상의 적어도 연간 매출을 창출하는 엄청난 인기있는 약물입니다.블록버스터는 당뇨병, 고혈압, 일반적인 암 유형 또는 천식과 같은 일반적인 질병을 다룹니다.일반적으로 시장에서 많은 경쟁 제품이 있습니다.
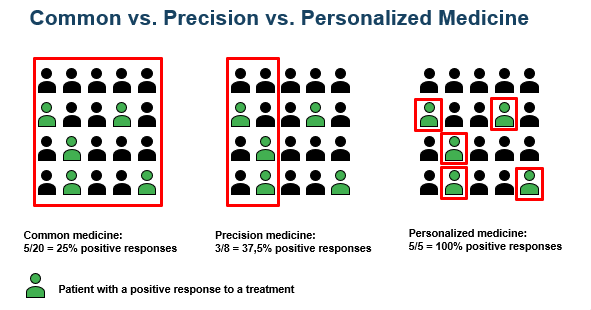
“정밀 의학”은 특정 치료법에 반응하는 특정 특성을 공유하는 개인 그룹에 대한 치료법입니다 (아래 그래픽을 참조하십시오짐마자
다른 약물과의 차별화를 위해, 제품의보다 구체적인 표적 및 마케팅을 위해, 질병 억제와 관련하여 우수한 환자 그룹이 결정된다.목표는 모든 마케팅 분석 프로젝트와 동일합니다.사용 된 데이터는 소위 실제 데이터 (RWD), 즉 치료 된 환자의 데이터가 아니라 임상 시험이 아니라.
주요 방법은 원하는 출력 값이 있기 때문에 학습 방법을 감독합니다.회귀 분구 / 물류 회귀, 지원 벡터 기계 및 랜덤 포리스트의 일반적인 방법 외에도 많은 양의 데이터를 통해 Convolutional 신경망 (CNN)과 같은 심층 학습 알고리즘이 적용됩니다.CNN은 종종 다른 방법을 능가합니다.
삼. 모바일 건강 상태에서 심부전을 예측합니다
심부전은 일반적으로 비상 사태 또는 병원 입학을 이끌고 있습니다.그리고 노화 된 인구로 인구의 심부전의 백분율이 증가 할 것으로 예상됩니다.
심부전을 겪는 사람들은 대개 기존의 질병을 가지고 있습니다.따라서 텔레나드 인 시스템이 환자를 모니터하고 상담하고 혈압, 체중 또는 심박수와 같은 모바일 건강 데이터가 수집되어 전송되는 것은 드문 일이 아닙니다.
대부분의 예측 및 예방 시스템은 고정 규칙을 기반으로합니다. 예를 들어 특정 측정치가 미리 정의 된 임계 값을 초과하면 환자가 경고합니다.그러한 예측 시스템은 높은 수의 거짓 경고, 즉 거짓 긍정을 갖는 자명하다.
경고가 대부분 병원 입원으로 이어지기 때문에 너무 많은 거짓 경고가 건강 비용을 증가시키고 환자의 예측에 대한 신뢰가 악화됩니다.결국, 그녀는 의료 도움을 권고 한 후에 멈출 것입니다.
따라서 나이, 성별, 흡연자 또는 균육, 균육 및 혈액의 나트륨, 칼륨 또는 헤모글로빈 농도와 같은 환자의 기준 데이터 및 심장 박동, 체중 (수축기 및 이완기)과 같은 모니터링 된 특성을 기반으로합니다.혈압, 또는 신체 활동에 대한 혈압, 또는 신체 활동에 대한 답변, 순진한 베이를 기반으로 한 분류자가 마침내 개발되었습니다.
거짓 경고는 73 % 감소했으며AUC (곡선 아래의 영역 “)약 70 %의
4. 정신병 예측, 진단 및 치료
그것은에서의 것으로 추정된다글로벌 인구의 최소 10 %정신 장애가 있습니다.정신 질환으로 인한 경제적 손실은 약 10 조까지 달약합니다.정신 장애는 다른 사람들, 불안, 우울증, 물질 사용 장애, 예를 들어 오피오이드, 양극성 장애, 정신 분열증 또는 식습 장애를 포함합니다.
따라서 정신 장애의 탐지와 가능한 한 일찍 탐지하는 것이 중요합니다.두 가지 주요 접근 방식이 있습니다 : 진단을 지원하기 위해 정신과 의사를위한 질병과 도구를 탐지하는 소비자를위한 앱이 있습니다.
소비자를위한 앱은 일반적으로 컴퓨터 학습 알고리즘으로 향상된 대화식 샤 봇입니다.앱은 소비자의 구어력을 분석하고 도움을 요청하는 권장 사항이 제공됩니다.권장 사항은 과학적 증거를 기반으로해야하므로 제안서와 개별 언어 패턴의 상호 작용 및 대응은 가능한 한 정확하게 예측해야합니다.
적용되는 방법은 다릅니다.첫 번째 단계는 거의 항상 감정 분석입니다.더 간단한 모델에서는 랜덤 숲과 순진한 베이가 사용됩니다.이 모델은 최대 3 개의 숨겨진 레이어가있는 신경 네트워크가 엄청나게 능숙합니다.
5. 뇌졸중의 바이오 마커를위한 연구 출판 및 데이터베이스 검색
뇌졸중은 장애와 사망의 주된 이유 중 하나입니다.성인 인물의 평생 위험은 한 번 뇌졸중의 약 25 %입니다.그러나 뇌졸중은 매우 이질적인 장애입니다.그래서, 개별화 된 사전 뇌졸중과 뇌졸중 관리가 치료법의 성공을 위해 중요합니다.
이 개별화 된 치료를 결정하기 위해 사람의 표현형, 즉, 관찰 가능한 특성을 선택해야합니다.그리고 이것은 보통 바이오 마커에 의해 달성됩니다.소위 바이오 마커는 환자가 층화 될 수 있도록 측정 가능한 데이터 포인트입니다.예는 질병의 심각도 점수, 라이프 스타일 특성 또는 게놈 특성입니다.
이미 알려진 바이오 마커가 이미 게시되거나 데이터베이스에 있습니다.또한 모든 다른 질병에 대한 바이오 마커의 탐지에 대해 매일 수백 명의 과학 간행물이 있습니다.
연구는 엄청나게 비싸고 장애를 예방하기 위해 중요합니다.그래서, 생명 공학 회사는 특정 질병에 가장 효과적이고 효율적인 해당 바이오 마커를 이해해야합니다.정보의 양은 매우 거대합니다. 이는 수동으로 수행 할 수 없습니다.
데이터 과학은 데이터베이스 및 출판물에서 관련 바이오 마커를 찾기 위해 정교한 NLP 알고리즘을 개발하는 데 도움이됩니다.그러한 바이오 마커가 특정 유형의 뇌졸중과 관련이있는 경우 콘텐츠를 이해하는 것 외에도, 출판 된 결과의 품질에 대한 판단이 달성되어야합니다.이것은 전반적으로 매우 복잡한 작업입니다.
6. 3D Bioprinting.
Bioprinting은 생명 공학 분야의 또 다른 뜨거운 주제입니다.디지털 청사진을 기반으로 프린터는 피부, 장기, 혈관 또는 뼈와 같은 층별 생활 조직을 인쇄하기 위해 바이오 링크라고도하는 셀 및 자연적 또는 합성 생체 재료를 사용합니다.
기관 기부에 따라 프린터에서보다 윤리적으로 비용 효율적으로 생산 될 수 있습니다.또한 약물 검사는 동물 또는 인간 테스트보다 합성 구조 조직에서 수행됩니다.전체 기술은 높은 복잡성으로 인해 초기 성숙도에 있습니다.이 인쇄의 복잡성에 대처하기 위해 가장 필수적인 부분 중 하나는 데이터 과학입니다.
인쇄 프로세스 및 품질은 고유 한 변형 또는 다양한 인쇄 매개 변수가있는 바이오 링크의 속성과 같은 수많은 요소에 의존합니다.예를 들어 사용 가능한 출력을 얻는 성공을 높이기 위해 인쇄 프로세스를 최적화하는 것,베이지안 최적화은 적용되다.
인쇄 속도는 프로세스의 핵심 구성 요소입니다.샴 네트워크 모델최적화 된 속도를 결정하기 위해 배포됩니다.재료를 검출하기 위해, 즉, 조직 결함, 컨볼 루넥 신경망은 층별 조직의 이미지에 적용된다.
사전 생산, 생산 및 후 생산 공정 중에 더 많은 응용 프로그램이 있지만이 세 가지 예는 이미 복잡성과 고급 모델이 필요합니다.제 의견 으로이 분야는 데이터 과학자들에게 생명 공학에서 가장 흥미로운 것들 중 하나입니다.
7. 난소 암 치료의 맞춤 치료
“개인화 된”은 한 개인의 요구와 일치하는 치료가 적용된다는 것을 의미합니다 (위의 그래픽을 참조하십시오짐마자의료 치료는 환자의 개별화 된 특성을 기반으로 점점 더 많습니다.
이러한 특성은 질병 아형, 개인 환자의 위험, 건강 예후 및 분자 및 행동 바이오 마커입니다.우리는 환자가 층화 될 수 있도록 환자들이 측정 가능한 데이터 포인트임을 측정 할 수있는 데이터 포인트임을 나타 냈습니다.그 데이터를 기반으로 한 환자에게 가장 좋은 개별 처리가 결정됩니다.
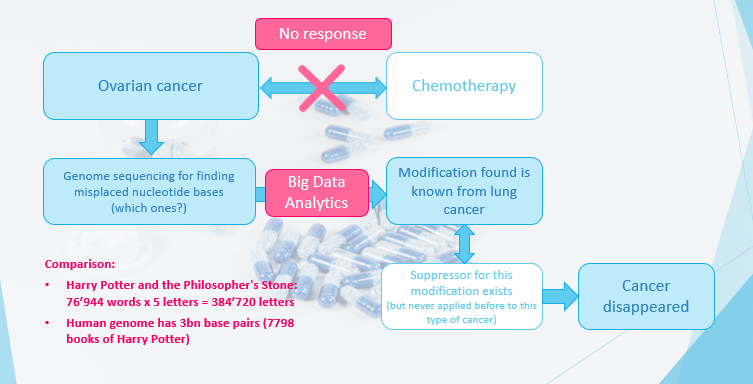
난소 암으로 한 환자의 경우 일반적인 화학 요법은 효과적이지 않았습니다.그래서, 하나는 게놈 시퀀싱을 수행하기로 결정 하여이 암을 유발하는 잘못된 뉴클레오타이드 염기를 찾기로 결정했습니다.Big Data Analytics를 사용하면 해리 포터의 “철학자의 돌”의 7798 권의 단어의 숫자에 해당하는 인간의 3 억 개의베이스 쌍 사이의 수정을 발견했습니다.
적용되는 방법은 일반적으로 소위 공분산 모델이며 종종 임의의 숲과 같은 분류 자와 결합됩니다.흥미롭게도,이 변형은 약물이 존재하지만 난소 암이 아닌 폐암으로부터 알려져있다.따라서 폐암 치료가 적용되었고 환자가 회복되었습니다.
8. 공급망 최적화
마약의 생산은 시간, 특히 특정 물질 및 생산 방법을 기반으로하는 오늘날의 하이테크 치료법을 필요로합니다.또한 전체 프로세스가 여러 단계로 분해되며, 그 중 몇 가지는 전문가 제공자에게 아웃소싱됩니다.
우리는 현재 COVID-19 백신 생산을 보장합니다.백신 발명가는 청사진을 제공하며 생산은 멸균 생산 전문 기업의 식물에 있습니다.백신은 임상 조건 하에서 작은 복용량을 채우는 회사에 탱크로 전달되며 마지막으로 다른 회사가 공급을합니다.
또한, 약물은 제한된 시간 동안 만 저장 될 수 있으며, 예를 들어 냉장실에서 특별한 저장 조건 하에서 종종 저장 될 수 있습니다.
적절한 생산 능력을 갖는 적절한 시간에 적절한 생산 능력을 갖는 올바른 입력 물질을 갖는 올바른 입력 물질을 갖는 전체 계획은 매우 복잡한 시스템입니다.그리고 이것은 각각 특정 조건을 가진 수백 가지와 수천 개의 치료법을 위해 관리되어야합니다.
계산 방법은 이러한 복잡성을 관리하는 데 필수적입니다.예를 들어, 최적의 파트너 회사의 생산 공정에서 선택하는 것은 지원 벡터 기계와 같은 감독 학습에 의해 수행됩니다.
동적 수요 예측은 종종 소위 소위에 의존합니다벡터 회귀를 지원합니다생산 최적화 자체가 신경망을 배치합니다.
결론
현대 기술과 과학이 오늘날을 달성 할 수있는 것은 매우 매력적입니다.그것은 데이터 과학과 함께 가장 상당한 가치를 펼칩니다.
방법으로, 우리는 랜덤 포리스트, 순진한 베이 및 지원 벡터 기계가 자주 사용되는 감독 학습 방법이 종종 사용되며, 보강 학습, NLP 및 심층 학습이 지배적입니다.
또한, 높은 차원 데이터에 대처하고 주성분 분석 및 공분산 모델과 같은 검색을위한 계산 방법이 필요합니다.
혁신의 국경에서 일하는 것은 베이지안 최적화, 컨볼 루션 신경망 또는 샴 네트워크와 같은 특정 주제에 대한 지식이 필요합니다.
이 필드에 대한 가장 중요한 항목 장벽은 주제별 지식이므로 (원시) 데이터를 이해합니다.가장 빠른 경로가 익숙해지는 것은 과학적 간행물과 알려지지 않은 각 표현식을 읽고 부지런히 조회합니다.그 필드에서 일할 때 전문가의 말로 말해야합니다.
그런 다음 오직 데이터 과학자만큼 엄청난 영향을 미칠 수 있습니다.그러나 이것은 또한 가장 보람있는 측면이기도합니다.
나는 생명 과학과 생명 공학 산업보다 직장에 더 많은 영향을 미칠 수 없었습니다.
내 이야기를 좋아하니?여기에서 더 많은 것을 찾을 수 있습니다.
I’m a part-time Amazon delivery driver. Here’s how we cheat to get around the strict rules. -번역

Jenny Powers
Jay (그의 진짜 이름)는 2019 년 이래로 시골 미시간에서 아마존을위한 패키지를 파트 타임 운전자로 일했습니다. 그는 익명으로 자신의 위치를 잃어 버렸습니다.그의 정체성은 내부자에 의해 확인되었습니다.
온라인 분류 광고를 보면서 2019 년 Amazon의 운전자로서의 업무를 시작했습니다.나는 여행을 즐긴다. 나는 몇몇 추가 벅을 사용할 수 있었다. 그래서 나는 적용했다.
나의 출발 비용은 1 시간 만에 16 달러였습니다.1 년 기념일을 위해, 나는 1 시간에 0.25 달러를 증가 시켰습니다.최근 운전자는 Covid-19 보너스를 받았습니다 – 150 달러를 받았습니다.
아마존이 계약을 맺는 것은 비밀이 아닙니다제 3 자 배달 서비스 제공 업체를 통해 배달의 대량(DSP), 그래서 제가 아마존 패키지를 독점적으로 전달하고 브랜드 의류를 착용하는 동안 나는 아마존을 위해 실제로 작동하지 않습니다.
나는 DSP가 일하고있는 DSP를 좋아합니다. 그러나 일자리에 대해 감사하지만 Amazon의 새로운 규칙을 구현해야 할 필요성은 실망 스러울 수 있으며 직장에서 많은 매출을 가져 왔습니다.
전임 25 ~ 30 개의 풀 타임 드라이버가 있으며 일반적으로 주변의 주말 운전자가 동일합니다.이것은 부분적으로 파트 타이머의 더 높은 매출로 인한 것입니다.최선의 견적은 작년부터 30-40 명의 새로운 운전자가 있습니다.
내가 들어올 때마다 새로운 얼굴이있는 것은 결코 끝나는 회전 문과 같습니다.
Amazon은 안전, 안전, 안전성 및 그대로 미디어에 대한 훌륭한 서술이며, 다른 이야기의 장면 뒤에 있습니다.
DSP에 많은 압박감이 있습니다. 그렇지 않으면 그들의 계약을 뽑아 낼 위험이 있으며이 압력은 미국 운전자에게 흘러 내리고 있습니다.
안전의 이름으로 Amazon은 모든 것을 추적하여 탭을 유지하지만 실제로 수행하는 것이 더 많은 압력을 창출합니다.
그들은 모든 것을 모니터링합니다. 우리가 가속, 제동, 코너링, 역전, 심지어 움직이는 동안 우리의 스크린을 만지는 것과 더불어 우리의 안전 벨트를 착용할지 여부를 모니터링합니다.멘토라는 앱…에
앱은 휴대 전화 또는 DSP가 제공하는 전화로 다운로드 할 수 있습니다. 이는 Person Person에 추적기가있는 아이디어를 좋아하지 않기 때문에 내가 선택한 것입니다.
전형적으로 9 ~ 11 시간 사이의 각 변화가 끝나면 앱은 우리가 얼마나 잘 운전했는지에 따라 점수를 생성합니다.가장 높은 점수는 850입니다.
내가 거의 2 년 전에 시작했을 때, 550 명이 괜찮 았지만 더 이상은 아닙니다.이제 그들은 당신이 높은 700 년대에 있기를 바랍니다.
나는 550 명을 가지고 있었지만 이제는 750처럼, 기본적으로 가장 낮은 점수 아마존이 DSP가 곤경에 빠지지 않고도 허용 할 것입니다.
문제는 당신의 점수가 당신의 통제에서 완전히 완전히 튀어 나올 수 있습니다.
예를 들어, 아이가 축구 공을 쫓는 거리에 들어가는 경우, 당신은 예기치 않게 브레이크를 칠해야만합니다.사슴이 당신의 밴 앞에서 다트가 닿지 않고 사고를 피하기 위해스러워하면 점수에도 불구합니다.운전하고있는 경우 GPS가 갑자기 내리고 궤도에 돌아 오기 위해 화면을 만지면 다른 상관이 있습니다.우리는 이러한 상황에서 무엇을해야합니까?
나는 사고가 발생한 적이 없지만 이러한 유형의 인스턴스는 운전자의 점수를 아래로 끌어 올리면 최종선이 모든 것이 당신의 점수로 내려갑니다.
내 DSP는 비즈니스를 위태롭게하고 싶지 않으므로 시스템을 게임에 해결 방법으로 만들었습니다.
운전자의 점수가 겪기 시작하면 우리 감독자가 우리의 변화의 시작 부분에 앱에 로그인하라고 말하면 전화를 통해 전형적으로 높은 점수를 얻으려면 전형적으로 높은 점수를 얻으려고합니다.문제 해결됨.
나는 공식 아마존 차량과는 반대로 렌트 밴을 운전합니다. 이는 70mph 이상이 될 수 없기 때문에 내가 원하는 것은 아니기 때문에 내가 원하는 것입니다.
내가 내 밴에서 카메라를 얻어야한다고 말하면, 나는 아마도 계속해서 거기에서 일하지 않을 것이라고 말할 수 있습니다.나는 안전을 지키지 않더라도 하루 종일 일정한 감시에있을 필요가 없습니다.
우리가 직장에 도착한 순간부터, 우리는 우리의 허슬을 켜야합니다.
우리가 많이 도착하면 우리는 노선에 배정되기 전에 우리의 차량을 개인적으로 수행하고 패킷을 발급 한 패키지에 파도로 보내기 전에 우리의 패키지를 픽업하기 전에 차량에 대해 60 점 검사를 수행해야합니다.우리가 각 변화를 확인하는 데 필요한 일들의 몇 가지 예는 우리의 와이퍼 유체가 떨어지는 지 여부입니다. 우리의 차량은 가스 캡이 누락되었는데, 우리의 역 카메라가 작동하고, 대머리, 압력 및 밟는 깊이에 대한 우리의 타이어입니다.
허브는 차량을로드하기 전에 모든 패키지를 스캔해야하기 때문에 모든 사람들이 직조하는 모든 사람과 함께 거대한 꿀벌의 둥지와 같습니다.그런 다음 우리는 실제로 우리가 10 시까 지 실제로 모든 것을 전달할 수 있도록 빨리 움직여야합니다.아마존의 요구 사항입니다.
나는 10 월에서 12 월까지 운행하는 피크 시즌간에 평균 약 150 개 패키지와 130 정거지와 약 30 %에서 40 % 이상입니다.피크에서 Amazon은 $ 150 시즌 보너스와 같은 파트 타임 드라이버를 제공합니다.
나는 대부분의 시골 길을 가졌으므로, 내가 원하는 마지막 일은 어두운 후에 패키지를 배달하는 가로등이없는 일부 시골 길에서 여기에 나가는 것입니다.
우리는 우리의 변화와 점심 시간 동안 2 배 15 분 휴식을 취하기 위해 전자 통지를 얻지 만, 나는 항상 통지를 기각하고 운전하는 동안 그냥 먹는다.시간이 끝나고 배달되지 않은 패키지를 다시 허브로 되돌릴 필요가 없습니다.
DSP는 임계 값이 무엇인지 모르지만 패키지를 반환하기 위해 벌칙을받습니다.몇 가지 주소에서 패키지를 남기는 것이 안전하지 않으므로이를 위해 수당이 내장되어 있지만 너무 많은 사람들이 다시 가져 오면 DSP가 페널티를 받게됩니다.
나는 그것을 인정하는 것을 자랑스럽게 생각하지 않지만, 나는 내 길에서 시간을 절약하기 위해 병을 끼워 넣었다.
그것은 부분적으로 선택, 일부 필수품입니다.이 나라 노선에서 일하면서 때로는 빠른 음식 레스토랑이나 주유소를 찾을 수있는 20 분이 걸릴 수 있으며, 그런 종류의 시간이 없습니다.
주택과 주변에는 4 마일이 있지 않으면 나는 시골 길에서 오줌을 올릴 수 있지만 더 자주 밴의 병입니다.
나는 많은 상업적 배달을하기 때문에 UPS를 위해 일했을 때 거의이를해야만했습니다. 나는 시설을 사용할 수있는 사업에 항상 상대적으로 가깝습니다.
일찍 일찍 끝내기 위해 관리하는 날에도, 나는 다른 모든 경로에서 운전자를 돕기 위해 다시 보낼 것을 보장 할 것입니다. 그것은 내가하고 싶은 모든 일이 그 시점에서 집에 가기 때문에 이상적이지 않습니다.
최근에 노동 조합에 대해서는 많은 이야기가 있었지만 개인적으로 나는 노동 조합의 큰 팬이 아닙니다.나는 1940 년대 -50 년대에 그들이 유익한 느낌이지만, 이제는 큰 욕심 많은 힘을 잡습니다.
UPS에서 온도 운전사로 일했을 때, 나는 제분지 상태로 인해 혜택을받을 자격이 없었지만 여과 회비를 지불해야했습니다.
아마존과 운전자 간 가장 큰 문제 중 하나는 모든 규칙을 만드는 사람들이 바퀴가 아닌 사무실에 앉아 있지 않습니다.
그렇지 않은 것보다 더 자주 더 자주 구현되는 규칙은 실제로 우리의 직업을 안전하고 효율적으로 수행하는 데 실제로 취하는 것이 반대적입니다.
Amazon은 컨트롤 하에서 운전자 안전을 얻는 데 자부심을 가지므로 시스템을 회피 할 수있는 수요가 있습니다.
Insider에 대한 진술서에서 Amazon 대변인은 다음과 같이 말했다 : 우리는 근처 화장실 시설과 주유소를 볼 수있는 아마존 배달 앱에서 아마존 배달 앱 내에 목록을 제공하는 데 필요한 시간을 할애 해야하는 운전자를 지원합니다. 드라이버는 휴식을 취하고 화장실을 사용하는 경로에 내장 된 시간을 내장합니다. 사실, 앱은 휴식 시간이 될 때 경고합니다. 우리는 DSP와 긴밀히 협력하여 그들 또는 그들의 운전자에게 과도한 압력을 가하지 않는 사실적인 기대를 설정합니다. 우리는 패키지 볼륨, 주소 복잡성 및 휴식 시간에 적합한 시간과 같은 수많은 요소를 고려하여 특정 시간 내에 경로가 완료 될 수있는 정교한 기술을 사용합니다. 사실 75 % 이상의 운전자가 계획된 시간에 30 분 이상 노선을 완성합니다. VANS, 운전자 안전 교육 프로그램 또는 매핑 및 라우팅 기술의 지속적인 개선 사항의 최첨단 안전 기술이 아니라, 우리는 네트워크 전역의 안전 메커니즘에 수백만 달러를 투자했으며 정기적으로 안전을 가장 잘 알고 있습니다. 운전자에게 관행.
더 위대한 이야기를 위해,내부자의 홈페이지를 방문하십시오…에
How to process a DataFrame with millions of rows in seconds -번역
수백만 행이 초 단위로 데이터 프레임을 처리하는 방법
그러나 당신이 알아야 할 데이터 분석을위한 또 다른 파이썬 라이브러리 – 그리고 아니, 나는 불꽃이나 마시에 대해 이야기하지 않습니다.
비파이썬의 IG 데이터 분석은 르네상스를 갖고 있습니다.그것은 모두이 기사에서 제시하고있는 도구 뒤에있는 빌딩 블록 중 하나 인 숫자 인 NUMPY로 시작되었습니다.
2006 년에 큰 데이터는 특히 Hadoop의 출시로 천천히 견인력을 얻은 주제였습니다.팬더는 데이터 프레임으로 곧 뒤를이었습니다.2014 년은 큰 자료가 주류가되었을 때의 해였으며, Apache Spark는 그 해에 해당되었습니다.2018 년에는 파이썬의 데이터 분석을 위해 Dask와 다른 라이브러리가있었습니다.
매월 나는 지느러미디내가 배우기를 열망하는 새로운 데이터 분석 도구.장기적으로 많은 시간을 절약 할 수 있으므로 시간 또는 2 시간을 보낼 수있는 가치있는 투자입니다.또한 최신 기술을 계속 연락하는 것도 중요합니다.
이 기사가 마스크에 관한 것이라고 기대하는 동안 당신은 잘못되었습니다.나는 당신이 알아야 할 데이터 분석을 위해 또 다른 파이썬 라이브러리를 발견했습니다.
파이썬처럼 SQL에 능숙 해지는 것이 똑같이 중요합니다.당신이 그것에 익숙하지 않은 경우, 당신은 여분의 돈이 있고,이 과정을 확인하십시오 :Master SQL, 빅 데이터 분석을위한 핵심 언어…에
파이썬의 큰 데이터 분석은 르네상스를 가지고 있습니다
다른 데이터 분석 도구에 대해 내 기사를 놓친 경우 :
VAEX를 만나십시오
VAEX는 게으른 핵심 데이터 프레임 (PandaS와 유사)을위한 고성능 Python 라이브러리로 큰 표 형식 데이터 집합을 시각화하고 탐색합니다.
초당 10 억 줄 이상의 행에 대한 기본 통계를 계산할 수 있습니다.큰 데이터의 대화식 탐색을 허용하는 여러 시각화를 지원합니다.
VAEX와 DASK의 차이점은 무엇입니까?
VAEX는 DASK와 유사하지 않지만 상단 팬더 데이터 프레임을 기반으로하는 DASK 데이터 프레임과 유사합니다.이것은 그 마술사를 의미합니다팬더 문제를 상속받습니다, 높은 메모리 사용량과 같습니다.이것은 VAEX의 경우가 아닙니다.
VAEX는 메인 메모리가 적은 시스템에서 더 큰 데이터 프레임을 처리 할 수 있도록 데이터 프레임을 복사하지 않습니다.
VAEX와 DASK는 모두 게으른 가공을 사용합니다.유일한 차이점은 VAEX가 필요할 때 필드를 계산하는 것입니다. Compute 함수를 명시 적으로 사용해야하는 Dask.
데이터는 HDF5 또는 Apache 화살표 형식이어야합니다. VAEX를 최대한 활용해야합니다.
VAEX를 설치하는 방법?
VAEX를 설치하려면 다른 Python 패키지를 설치하는 것만 큼 간단합니다.
PIP 설치 VAEX
Let’s take Vaex to a test drive
큰 데이터 파일을 만들려면 100 만 개의 행과 1000 개의 열이있는 팬더 데이터 프레임을 만들어 봅시다.
VAEX 가져 오기
PANDAS를 PD로 가져 오십시오
numpy를 np로 가져 오기n_rows = 1000000.
n_cols = 1000.
df = pd.dataFrame (np.random.randint (0, 100, size = (n_rows, n_cols)), columns = [ 'col % d'% i 범위 (n_cols)]df.head ()

이 데이터 프레임은 얼마나 많은 메모리를 사용합니까?
df.info (memory_usage = '깊이')

우리가 vaex로 나중에 읽을 수 있도록 디스크에 저장합시다.
file_path = 'big_file.csv'
df.to_csv (file_path, index = false)
우리는 속도가 팬더와 유사하므로 전체 CSV를 VAEX로 직접 읽는 것으로 많은 것을 얻지 못할 것입니다.둘 다 내 랩톱에서 약 85 초를 필요로합니다.
우리는 CSV를 HDF5 (계층 적 데이터 형식 버전 5)로 변환하여 VAEX의 이점을 확인해야합니다.VAEX에는 소규모 덩어리를 변환하여 주 메모리보다 큰 파일을 지원하는 변환 기능이 있습니다.
Pandas로 큰 파일을 열 수없는 경우 메모리 제약 조건으로 인해 HDF5로 덮어 VAEX로 처리 할 수 있습니다.
dv = vaex.from_csv (file_path, convert = true, chunk_size = 5_000_000)
이 함수는 HDF5 파일을 만들고 디스크에 지속됩니다.
DV의 데이터 유형은 무엇입니까?
유형 (DV)# 출력
vaex.hdf5.dataset.hdf5MemoryMapped.
이제 VAEX로 7.5GB 데이터 집합을 읽으려고합니다. 이미 DV 변수에 이미 있으므로 다시 읽을 필요가 없습니다.이것은 단지 속도를 테스트하는 것입니다.
dv = vaex.open ( 'big_file.csv.hdf5')
VAEX는 위의 명령을 실행하기 위해 1 초 미만이 필요했습니다.그러나 지연 로딩 때문에 VAEX가 실제로 파일을 읽지 않았습니다.
COL1의 합계를 계산하여 읽을 것을 강요합시다.
suma = dv.col1.sum ()
수마# 출력
# 배열 (49486599)
나는 이것을 정말로 놀랐다.VAEX는 합계를 계산하기 위해 1 초 미만이 필요했습니다.어떻게 가능합니까?
이러한 데이터를 열면 디스크의 파일 크기에 관계없이 순간적입니다.VaEx는 메모리에서 읽는 대신 데이터를 메모리 맵핑합니다.이것은 사용 가능한 RAM보다 큰 대형 데이터 세트를 사용하는 최적의 방법입니다.
플로팅
데이터를 플로팅 할 때 VAEX도 빠릅니다.특수 플로팅 기능 PLOT1D, PLOT2D 및 PLOT2D_CONTOUR가 있습니다.
dv.plot1d (dv.col2, figsize = (14, 7))
Virtual columns
VAEX는 새 열을 추가 할 때 가상 열을 만듭니다.
dv [ 'col1_plus_col2'] = dv.col1 + dv.col2
DV [ 'COL1_PLUS_COL2']]

Efficient filtering
VAEX는 훨씬 더 많은 메모리 효율 인 데이터를 필터링 할 때 데이터 프레임 복사본을 만들지 않습니다.
DVV = DV [dv.col1 & gt;90]
Aggregations
집계는 팬더보다 약간 다르게 작동하지만 더 중요한 것은 뻔뻔스럽게 빨리됩니다.
col1 ≥ 50 이진 가상 가상 열을 추가합시다.
DV [ 'COL1_50'] = DV.COL1 & gt; = 50
VAEX는 그룹별로 단일 명령으로 집계를 결합합니다.아래 명령은 “COL1_50″열에 의해 데이터를 그룹화하고 COL3 열의 합계를 계산합니다.
dv_group = dv.groupby (dv [ 'col1_50'], agg = vaex.agg.sum (dv [ 'col3']))
dv_group.

Joins
VAEX는 메모리 복사본을 저장하지 않고 데이터를 조인하여 주 메모리를 저장합니다.Pandas 사용자는 조인 기능에 익숙합니다.
dv_join = dv.join (dv_group, on = 'col1_50')
Conclusion
결국, 당신은 다음과 같이 묻습니다 : 우리는 팬더에서 VAEX로 전환해야합니까?대답은 큰 아니오입니다.
Pandas는 여전히 파이썬에서 데이터 분석을위한 최고의 도구입니다.가장 일반적인 데이터 분석 작업을위한 잘 지원되는 기능이 있습니다.
더 큰 파일에 관해서, 팬더는 가장 빠른 도구가 아닐 수도 있습니다.이것은 VAEX가 뛰어 내리는 훌륭한 장소입니다.
VAEX는 데이터 분석 도구 상자에 추가 해야하는 도구입니다.
팬더가 너무 느리거나 간단히 충돌하는 분석 작업에서 작업 할 때 VAEX를 도구 상자에서 가져오고 가장 중요한 항목을 필터링하고 팬더로 분석을 계속하십시오.
가기 전에
-SQL에서 날짜 시리즈를 만드는 방법[조]-데이터 과학자 및 amp에 대한 무료 기술 테스트;기계 학습 엔지니어-사이버 보안 (60 % OFF)에서 경력을 향상시킵니다 [코스]-Microsoft Azure [코스]를 사용하는 클라우드 개발자가 되십시오.-빅 데이터 분석의 핵심 언어 인 마스터 SQL [코스]
위의 링크 중 일부는 제휴 링크이며 구입을 위해 구입을 위해 그들을 통과하면위원회를 벌 수 있습니다.나는 당신의 구매로부터받는위원회로 인해 품질로 인해 과정을 링크한다는 것을 명심하십시오.
나를 따라 가라트위터, 내가 정기적으로 여기서트위터데이터 과학 및 기계 학습에 대해서.
Build and Run a Docker Container for your Machine Learning Model -번역
기계 학습 모델을위한 Docker 컨테이너 구축 및 실행
간단한 기계 학습 모델이있는 Docker 컨테이너의 빠르고 쉬운 빌드

이 기사의 아이디어는 간단한 기계 학습 모델을 사용하여 도커 컨테이너를 빠르고 쉽게 빌드하는 것입니다.이 기사를 읽기 전에 주저하지 말고 읽지 마십시오.왜 기계 학습을 위해 Docker를 사용하십시오과빠른 설치 및 먼저 Docker를 사용하십시오…에
기계 학습 모델을위한 Docker 컨테이너 구축을 시작하려면 세 가지 파일을 고려해 보겠습니다.DockerFile, Train.py, Inference.py.
모든 파일을 찾을 수 있습니다github.…에
그만큼train.py파이썬입니다 CSV 파일 (Train.csv)에서 EEG 데이터를 섭취하고 정규화하고 두 모델을 훈련시키는 스크립트 (Scikit-Learn 사용) 데이터를 분류합니다.스크립트는 선형 판별 분석 (CLF_LDA) 및 신경 네트워크 다층 PercePtron (CLF_NN)을 저장합니다.
그만큼inference.py이전에 생성 된 두 모델을로드하여 배치 추론을 수행하도록 호출됩니다.응용 프로그램은 CSV 파일 (test.csv)에서 오는 새로운 EEG 데이터를 정규화하고 데이터 집합에서 추론을 수행하고 분류 정확도와 예측을 인쇄합니다.
간단하게 만들어 봅시다DockerFile.와 더불어jupyter / scipy-notebook.이미지로서의 이미지로서의 이미지.우리는 설치해야합니다joblib.숙련 된 모델의 직렬화와 탈 수성을 허용합니다.우리는 train.csv, test.csv, train.py 및 inference.py 파일을 이미지에 복사합니다.그런 다음, 우리는 달리고 있습니다train.py기계 학습 모델에 맞는 이미지 빌드 프로세스의 일부로 기계 학습 모델을 적합하고 직렬화 할 것입니다. 프로세스 시작시 디버그 할 수있는 기능과 같은 몇 가지 장점을 제공하는 경우 도커 이미지 ID를 추적하거나 다른 버전을 사용할 수 있습니다.
이미지를 빌드하려면 터미널에서 다음 명령을 실행합니다.
Docker Build -t Docker-ML 모델 -F Dockerfile.
출력은 다음과 같습니다.
새 데이터 (test.csv)에서 추론을 수행 할 시간입니다.
Docker는 Docker-ML-Model Python3 Inference.py를 실행합니다
출력은 다음과 같습니다.

우리는 우리의 컨테이너 경험을 향상시킬 수있는 몇 가지 일을 할 수 있습니다.우리는 예를 들어 DockerFile에서 WorkDir을 사용하여 컨테이너의 호스트 디렉토리를 바인딩 할 수 있습니다.
에inference.py, 우리는 예를 들면 AN을 구하기로 결정할 수 있습니다Output.csv.파일과 함께 파일x_test.데이터의 데이터 :
당신이 그것을 빌드하고 그것을 실행하면 당신은 그것을 볼 수 있어야합니다.Output.csv.파일의 파일/ mydata.:
우리는 또한 추가 할 수 있습니다음량DockerFile의 명령으로 새 마운트 지점을 만드는 이미지가 생성됩니다.
우리가 지정한 이름으로,음량명령어는 우리가 처리하고자하는 데이터를 찾는 기본 호스트 또는 다른 컨테이너에서 외부 마운트 된 볼륨을 보유하는 것으로 태그가있는 마운트 포인트를 만듭니다.
개발의 미래를 위해 훈련 된 모델을 유지하기 위해 빌드 시간에 한 번만 환경 변수를 설정해야하며 특정 위치에 추가 데이터 또는 메타 데이터를 추가 할 수 있습니다.환경 변수 설정의 장점은 코드 전체에 필요한 경로의 하드 코드를 방지하고 합의 된 디렉토리 구조에서 다른 사람들과 작업을보다 잘 공유하는 것입니다.
새로운 DockerFile을 사용하여 다른 예제를 살펴 보겠습니다.
우리는 환경 변수를 추가해야합니다train.py:
과inference.py:
무엇 향후 계획 ?
목표는 간단한 기계 학습 모델로 Docker 컨테이너를 구축하기위한 빠르고 쉬운 단계를 생성하는 것이 었습니다.건물은 A를하는 것만 큼 간단합니다Docker Build -t My-Docker-Image.…에
이 단계에서 우리는 훨씬 더 간단 해지고 기계 학습 모델을 게시하고 확장하기 위해 두려움을 제거하는 모델의 배포를 시작할 수 있습니다.다음 단계는 Jenkins와 같은 CI / CD 공구 (연속 통합 / 연속 배송)가있는 워크 플로우를 생성하는 것입니다.이 접근 방식 덕분에 Docker Container를 구축하고 봉사하고 REST API를 노출하여 외부 이해 관계자가 소비 할 수 있도록 가능합니다.높은 계산 요구가 필요한 깊은 학습 모델을 교육하는 경우 컨테이너를 고성능 컴퓨팅 서버 또는 구내, 개인 또는 공용 클라우드와 같은 원하는 플랫폼으로 이동할 수 있습니다.이 아이디어는 모델을 확장 할 수 있지만 지역 / 가용성 영역에서 컨테이너를 확장 할 수 있으므로 탄력적 인 배포를 만듭니다.
나는 당신이 큰 단순함과 유연성 컨테이너가 제공하기를 바랍니다.기계 / 깊은 학습 응용 프로그램을 컨테이너로하여 세계에서 볼 수 있습니다.다음 단계는 클라우드에 배포하고 노출하는 것입니다.특정 시점에서는 Red Hat Openshift, kubernetes 배포와 같은 기술의 도움을 받아 수백만 명의 사용자에게 제공하도록 컨테이너를 조정, 모니터링 및 확장해야합니다.
소스
https://docs.docker.com/engine/reference/builder/