
기계 학습 모델을위한 Docker 컨테이너 구축 및 실행
간단한 기계 학습 모델이있는 Docker 컨테이너의 빠르고 쉬운 빌드

이 기사의 아이디어는 간단한 기계 학습 모델을 사용하여 도커 컨테이너를 빠르고 쉽게 빌드하는 것입니다.이 기사를 읽기 전에 주저하지 말고 읽지 마십시오.왜 기계 학습을 위해 Docker를 사용하십시오과빠른 설치 및 먼저 Docker를 사용하십시오…에
기계 학습 모델을위한 Docker 컨테이너 구축을 시작하려면 세 가지 파일을 고려해 보겠습니다.DockerFile, Train.py, Inference.py.
모든 파일을 찾을 수 있습니다github.…에
그만큼train.py파이썬입니다 CSV 파일 (Train.csv)에서 EEG 데이터를 섭취하고 정규화하고 두 모델을 훈련시키는 스크립트 (Scikit-Learn 사용) 데이터를 분류합니다.스크립트는 선형 판별 분석 (CLF_LDA) 및 신경 네트워크 다층 PercePtron (CLF_NN)을 저장합니다.
그만큼inference.py이전에 생성 된 두 모델을로드하여 배치 추론을 수행하도록 호출됩니다.응용 프로그램은 CSV 파일 (test.csv)에서 오는 새로운 EEG 데이터를 정규화하고 데이터 집합에서 추론을 수행하고 분류 정확도와 예측을 인쇄합니다.
간단하게 만들어 봅시다DockerFile.와 더불어jupyter / scipy-notebook.이미지로서의 이미지로서의 이미지.우리는 설치해야합니다joblib.숙련 된 모델의 직렬화와 탈 수성을 허용합니다.우리는 train.csv, test.csv, train.py 및 inference.py 파일을 이미지에 복사합니다.그런 다음, 우리는 달리고 있습니다train.py기계 학습 모델에 맞는 이미지 빌드 프로세스의 일부로 기계 학습 모델을 적합하고 직렬화 할 것입니다. 프로세스 시작시 디버그 할 수있는 기능과 같은 몇 가지 장점을 제공하는 경우 도커 이미지 ID를 추적하거나 다른 버전을 사용할 수 있습니다.
이미지를 빌드하려면 터미널에서 다음 명령을 실행합니다.
Docker Build -t Docker-ML 모델 -F Dockerfile.
출력은 다음과 같습니다.
새 데이터 (test.csv)에서 추론을 수행 할 시간입니다.
Docker는 Docker-ML-Model Python3 Inference.py를 실행합니다
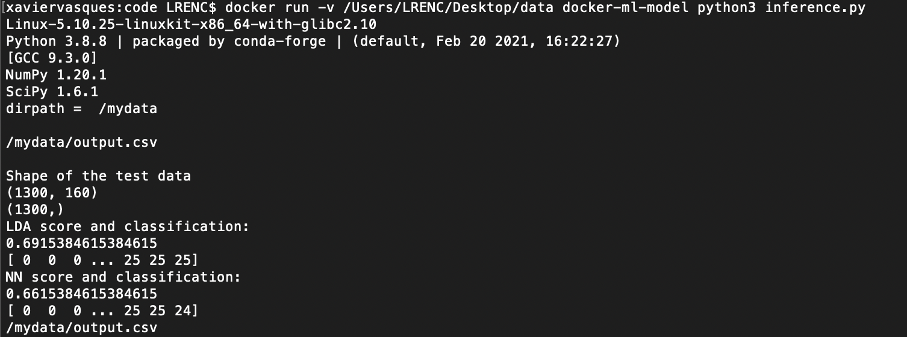
출력은 다음과 같습니다.

우리는 우리의 컨테이너 경험을 향상시킬 수있는 몇 가지 일을 할 수 있습니다.우리는 예를 들어 DockerFile에서 WorkDir을 사용하여 컨테이너의 호스트 디렉토리를 바인딩 할 수 있습니다.
에inference.py, 우리는 예를 들면 AN을 구하기로 결정할 수 있습니다Output.csv.파일과 함께 파일x_test.데이터의 데이터 :
당신이 그것을 빌드하고 그것을 실행하면 당신은 그것을 볼 수 있어야합니다.Output.csv.파일의 파일/ mydata.:
우리는 또한 추가 할 수 있습니다음량DockerFile의 명령으로 새 마운트 지점을 만드는 이미지가 생성됩니다.
우리가 지정한 이름으로,음량명령어는 우리가 처리하고자하는 데이터를 찾는 기본 호스트 또는 다른 컨테이너에서 외부 마운트 된 볼륨을 보유하는 것으로 태그가있는 마운트 포인트를 만듭니다.
개발의 미래를 위해 훈련 된 모델을 유지하기 위해 빌드 시간에 한 번만 환경 변수를 설정해야하며 특정 위치에 추가 데이터 또는 메타 데이터를 추가 할 수 있습니다.환경 변수 설정의 장점은 코드 전체에 필요한 경로의 하드 코드를 방지하고 합의 된 디렉토리 구조에서 다른 사람들과 작업을보다 잘 공유하는 것입니다.
새로운 DockerFile을 사용하여 다른 예제를 살펴 보겠습니다.
우리는 환경 변수를 추가해야합니다train.py:
과inference.py:
무엇 향후 계획 ?
목표는 간단한 기계 학습 모델로 Docker 컨테이너를 구축하기위한 빠르고 쉬운 단계를 생성하는 것이 었습니다.건물은 A를하는 것만 큼 간단합니다Docker Build -t My-Docker-Image.…에
이 단계에서 우리는 훨씬 더 간단 해지고 기계 학습 모델을 게시하고 확장하기 위해 두려움을 제거하는 모델의 배포를 시작할 수 있습니다.다음 단계는 Jenkins와 같은 CI / CD 공구 (연속 통합 / 연속 배송)가있는 워크 플로우를 생성하는 것입니다.이 접근 방식 덕분에 Docker Container를 구축하고 봉사하고 REST API를 노출하여 외부 이해 관계자가 소비 할 수 있도록 가능합니다.높은 계산 요구가 필요한 깊은 학습 모델을 교육하는 경우 컨테이너를 고성능 컴퓨팅 서버 또는 구내, 개인 또는 공용 클라우드와 같은 원하는 플랫폼으로 이동할 수 있습니다.이 아이디어는 모델을 확장 할 수 있지만 지역 / 가용성 영역에서 컨테이너를 확장 할 수 있으므로 탄력적 인 배포를 만듭니다.
나는 당신이 큰 단순함과 유연성 컨테이너가 제공하기를 바랍니다.기계 / 깊은 학습 응용 프로그램을 컨테이너로하여 세계에서 볼 수 있습니다.다음 단계는 클라우드에 배포하고 노출하는 것입니다.특정 시점에서는 Red Hat Openshift, kubernetes 배포와 같은 기술의 도움을 받아 수백만 명의 사용자에게 제공하도록 컨테이너를 조정, 모니터링 및 확장해야합니다.
소스
https://docs.docker.com/engine/reference/builder/