
Build and Run a Docker Container for your Machine Learning Model
A quick and easy build of a Docker container with a simple machine learning model

The idea of this article is to do a quick and easy build of a Docker container with a simple machine learning model and run it. Before reading this article, do not hesitate to read Why use Docker for Machine Learning and Quick Install and First Use of Docker.
In order to start building a Docker container for a machine learning model, let’s consider three files: Dockerfile, train.py, inference.py.
You can find all files on GitHub.
The train.py is a python script that ingest and normalize EEG data in a csv file (train.csv) and train two models to classify the data (using scikit-learn). The script saves two models: Linear Discriminant Analysis (clf_lda) and Neural Networks multi-layer perceptron (clf_NN).
The inference.py will be called to perform batch inference by loading the two models that has been previously created. The application will normalize new EEG data coming from a csv file (test.csv), perform inference on the dataset and print the classification accuracy and predictions.
Let’s create a simple Dockerfile with the jupyter/scipy-notebook image as our base image. We need to install joblib to allow serialization and deserialization of our trained model. We copy the train.csv, test.csv, train.py and inference.py files into the image. Then, we run train.py which will fit and serialize the machine learning models as part of our image build process which provide several advantages such as the ability to debug at the beginning of the process, use Docker Image ID for keeping track or use different versions.
In order to build the image, we run the following command in our terminal:
docker build -t docker-ml-model -f Dockerfile .
The output is the following:
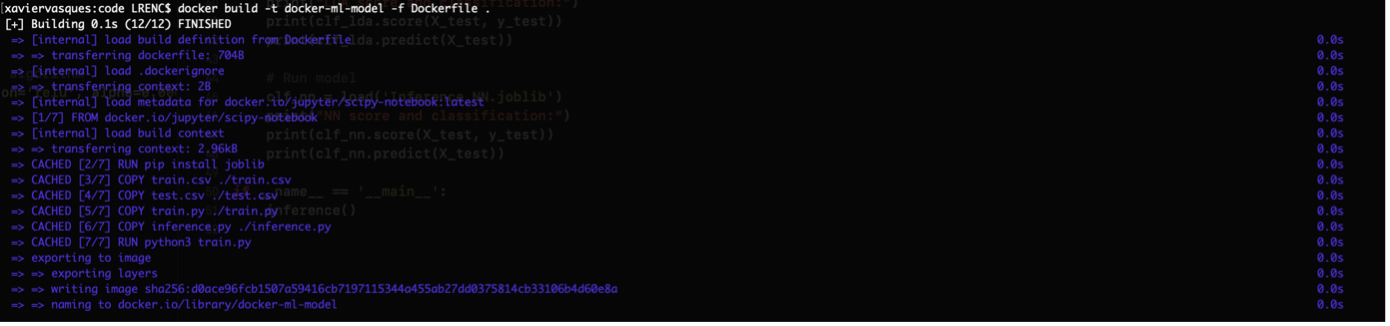
It’s time to perform the inference on new data (test.csv):
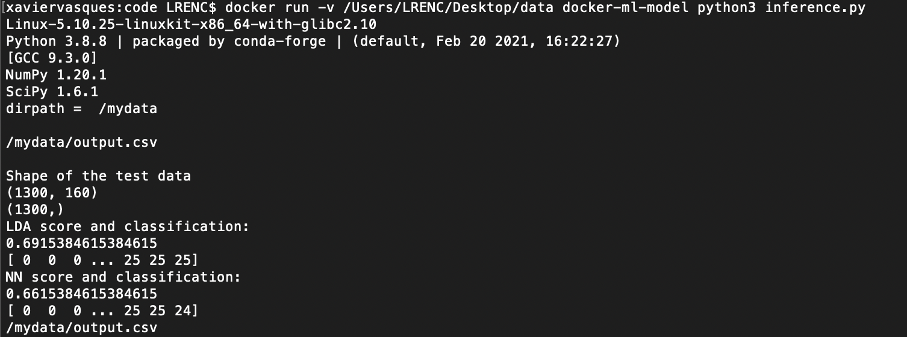
docker run docker-ml-model python3 inference.py
The output is the following:

We can do a few things that can improve our containerization experience. We can for example bind a host directory in the container using WORKDIR in the Dockerfile:
In inference.py, we can decide for example to save an output.csv file with the X_test data in it:
When you build it and run it you should be able to see the output.csv file in /mydata :
We can also add the VOLUME instruction in the Dockerfile resulting in an image that will create a new mount point:
With the name that we specify, the VOLUME instruction creates a mount point which is tagged as holding externally mounted volume from native host or other containers where we find the data we want to process.
For the future of your developments, it can be necessary to set environment variables from the beginning, just once at the build time, for persisting the trained model and maybe add additional data or metadata to a specific location. The advantage of setting environment variables is to avoid the hard code of the necessary paths all over your code and to better share your work with others on an agreed directory structure.
Let’s take another example, with a new Dockerfile:
We need to add the environment variables to train.py:
and inference.py:
What’s Next ?
The goal was to produce quick and easy steps to build a Docker container with a simple machine learning model. Building is as simple as doing a docker build -t my-docker-image ..
From this step, we can start the deployment of our models which will be much simpler and removing the fear to publish and scale your machine learning model. The next step is to produce a workflow with a CI/CD tool (Continuous Integration/Continuous Delivery) such as Jenkins. Thanks to this approach, it will be possible to build and serve anywhere a docker container and expose a REST API so that external stakeholders can consume it. If you are training a deep learning model that needs high computational needs, you can move your containers to high performance computing servers or any platform of your choice such as on premises, private or public cloud. The idea is that you can scale your model but also create resilient deployment as you can scale the container across regions/availability zones.
I hope you can see the great simplicity and flexibility containers provide. By containerizing your machine/deep learning application, you can make it visible to the world. The next step is to deploy it in the cloud and expose it. At certain points in time, you will need to orchestrate, monitor and scale your containers to serve millions of users with the help of technologies such as Red Hat OpenShift, a Kubernetes distribution.
Sources
https://docs.docker.com/engine/reference/builder/