
팁과 트릭
눈을 만나는 것보다 ‘pandas.read_csv ()’가 더 많이 있습니다.
깊은 다이빙은read_csv.팬지의 기능

팬더는 가장 널리 사용되는 도서관 중 하나입니다.데이터 과학생태계.이 다양한 라이브러리는 파이썬에서 데이터를 읽고 탐색하고 조작 할 수있는 도구를 제공합니다.팬더에서 데이터 가져 오기에 사용되는 기본 도구는 다음과 같습니다.read_csv ()...에이 함수는 쉼표로 구분 된 값, a.k.a, csv 파일의 파일 경로를 입력 한 다음 직접 팬더의 데이터 프레임을 반환합니다.ㅏ쉼표로 구분 된 값(CSV.)파일구분 된 것입니다텍스트 파일A.반점값을 분리합니다.
그만큼pandas.read_csv ()…을 … 한 것 매우 미세한 데이터 가져 오기를 허용하는 약 50 가지 선택적 호출 매개 변수.이 기사는 적은 알려진 매개 변수와 데이터 분석 작업에서 사용 중 일부를 터치합니다.
pandas.read_csv () 매개 변수
기본 매개 변수를 사용하여 팬더에서 CSV 파일을 가져 오는 구문은 다음과 같습니다.
PANDAS를 PD로 가져 오십시오
df = pd.read_csv (filepath)1. verbose
그만큼말 수가 많은매개 변수,로 설정된 경우진실다음과 같이 CSV 파일 읽기에 대한 추가 정보를 인쇄합니다.
- 유형 변환,
- 메모리 정리, 및
- 토큰 화.
PANDAS를 PD로 가져 오십시오
df = pd.read_csv ( 'fruits.csv', verbose = true)

2. Prefix
헤더는 모든 열의 내용에 대한 정보가 들어있는 CSV 파일의 행입니다.이름이 제안되면 파일 맨 위에 나타납니다.
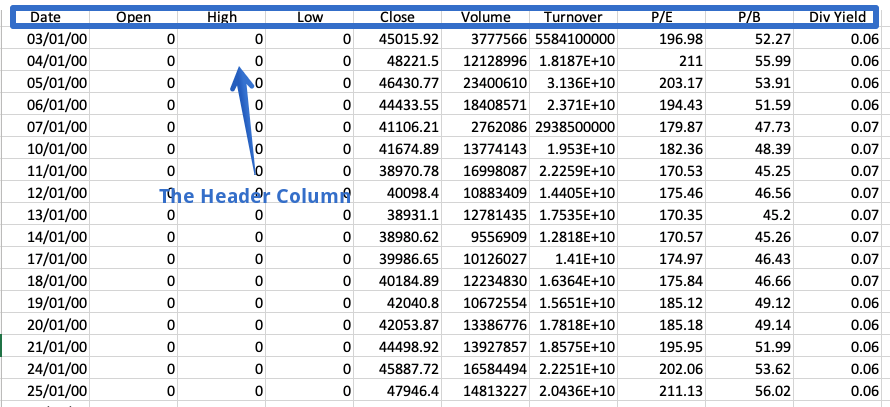
때로는 데이터 집합에 헤더가 포함되어 있지 않습니다.이러한 파일을 읽으려면 다음을 설정해야합니다.머리글명시 적으로 매개 변수;그렇지 않으면 첫 번째 행이 헤더로 간주됩니다.
df = pd.read_csv ( 'fruings.csv', header = 없음)
Df.

결과 데이터 프레임은 컬럼 이름 대신 열 번호로 구성되어 0부터 시작됩니다.또는 우리는 그를 사용할 수 있습니다접두사매개 변수는 열 번호에 추가 할 접두어를 생성합니다.
df = pd.read_csv ( 'fruings.csv', header = 없음, 접두어 = '열')
Df.
대신에기둥선택한 이름을 지정할 수 있습니다.
3. mangle_dupe_cols
데이터 프레임이 중복 된 열 이름으로 구성된 경우, ‘x’, ‘x’등mangle_dupe_cols.이름을 ‘x’, ‘x1’로 자동 변경하고 반복되는 열을 구별합니다.

df = pd.read_csv ( 'file.csv', mangle_dupe_cols = true)
Df.
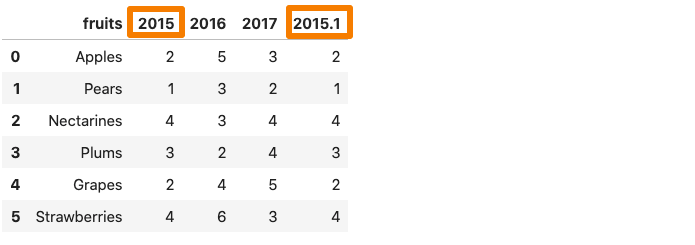
그 중 하나2015 년데이터 프레임의 열은 AS 로의 이름을 삭제합니다2015.1.…에
4. chunksize.
그만큼pandas.read_csv ()기능은 A.chunksize.매개 변수그것은 청크의 크기를 제어합니다.팬더에서 메모리 데이터 집합을로드하는 데 도움이됩니다.chunking을 사용하려면 처음에 청크의 크기를 선언해야합니다.이것은 우리가 반복 할 수있는 객체를 반환합니다.
chunk_size = 5000.
batch_no = 1.
pd.read_csv ( 'yellow_tripdata_2016-02.csv', chunksize = chunk_size)의 chunk의 경우 :
chunk.to_csv ( 'chunk'+ str (batch_no) + '. csv', index = false)
batch_no + = 1.
위의 예에서는 5000의 청크 크기를 선택합니다. 이는 한 번에 5000 줄의 데이터 만 가져올 수 있습니다.우리는 각각 5000 열의 다중 청크를 얻고 각 청크는 팬더 데이터 프레임으로 쉽게로드 될 수 있습니다.
df1 = pd.read_csv ( 'chunk1.csv')
df1.head ()
아래에 설명 된 기사에서 청킹에 대해 자세히 알아볼 수 있습니다.
5. 압축
많은 시간, 우리는 압축 된 파일을받습니다.잘,pandas.read_csv.이러한 압축 파일을 쉽게 처리 할 필요없이 쉽게 처리 할 수 있습니다.기본적으로 압축 매개 변수는 다음으로 설정됩니다미루다,자동으로 파일의 종류를 추론 할 수 있습니다그물,지퍼,BZ2.,xz.파일 확장명에서.
df = pd.read_csv ( 'sample.zip')또는 긴 형태 :df = pd.read_csv ( 'sample.zip', 압축 = 'zip')
6. thousands
데이터 집합의 열에 A.천분리 기호,pandas.read_csv ()그것을 정수가 아닌 문자열로 읽습니다.예를 들어 판매 열에 쉼표 구분 기호가 포함 된 위치에있는 데이터 집합을 고려하십시오.
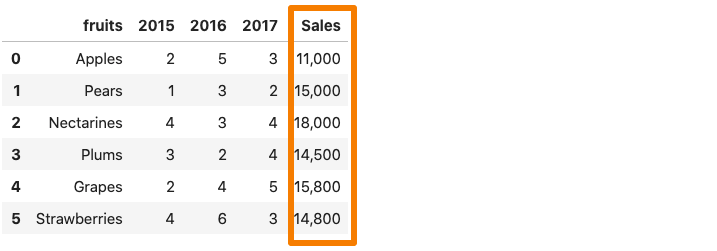
이제 위의 데이터 집합을 팬더 데이터 프레임으로 읽으려면매상열은 쉼표로 인해 문자열로 간주됩니다.
df = pd.read_csv ( 'sample.csv')
df.dtypes.

이것을 피하기 위해, 우리는 명시 적으로pandas.read_csv ()쉼표는 쉼표가 수천 개의 장소 표시기입니다.수천 명의매개 변수.
df = pd.read_csv ( 'sample.csv', 수천 = ',')
df.dtypes.

7. skip_blank_lines
빈 줄이 데이터 집합에 있으면 자동으로 건너 뜁니다.빈 줄을 NAN으로 해석하도록 원한다면skip_blank_lines.옵션은 false입니다.
8. 여러 CSV 파일을 읽습니다
이것은 매개 변수가 아니지만 유용한 팁입니다.팬더를 사용하여 여러 파일을 읽으려면 일반적으로 별도의 데이터 프레임이 필요합니다.예를 들어 아래 예제에서는 우리는pd.read_csv ()두 개의 별도의 파일을 두 개의 별개의 데이터 프레임으로 읽으려면 두 번 기능을 수행하십시오.
DF1 = PD.READ_CSV ( 'DATASET1.CSV')
df2 = pd.read_csv ( 'dataset2.csv')
이러한 여러 파일을 함께 읽는 한 가지 방법은 루프를 사용하는 것입니다.다음과 같이 파일 경로 목록을 만들고 목록을 반복합니다.
filenames = [ 'dataset1.csv', 'dataset2, csv']
데이터 프레임 = FILENAMES의 f에 대한 [PD.READ_CSV (f)]
많은 파일 이름이 비슷한 패턴을 가지고있을 때지구본파이썬 표준 라이브러리의 모듈은 편리합니다.우리는 먼저 그를 수입해야합니다지구본내장에서 기능지구본기준 치수.우리는 패턴을 사용합니다멋진 * .csv.접두사로 시작하는 모든 문자열을 일치시킵니다맵시 있는접미사로 끝납니다.csv.그 ‘*'(별표)야생 카드 문자입니다.그것은 0을 포함하여 모든 수의 표준 문자를 나타냅니다.
글로벌 가져 오기
filenames = glob.glob ( '멋진 * .csv')
파일 이름
----------------------------------------------------------------)------------------------------------
[ '멋진 Pharma.csv',
'멋진 it.csv',
'멋진 뱅크 .csv',
'nifty_data_2020.csv',
'nifty fmcg.csv']
위의 코드를 사용하면 멋진 CSV 파일 이름을 선택할 수 있습니다.이제 목록 이해 또는 루프를 사용하여 모든 것이 즉시 읽을 수 있습니다.
데이터 프레임 = FILENAMES의 f에 대한 [PD.READ_CSV (f)]
Conclusion
이 기사에서는 pandas.read_csv () 함수의 몇 가지 매개 변수를 살펴 보았습니다.그것은 유익한 기능이며 우리가 드물게 사용할 수있는 많은 인구 빌드 매개 변수가 제공됩니다.그렇게하지 않는 주요 이유 중 하나는 문서를 읽을 수 없기 때문입니다.중요한 정보가 포함될 수있는 중요한 정보를 발굴하기 위해 문서를 자세히 설명하는 것이 좋습니다.