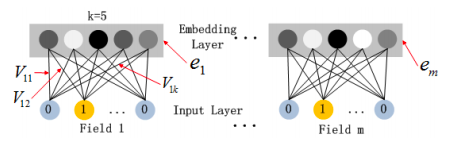
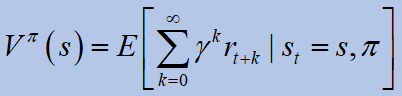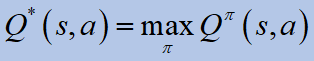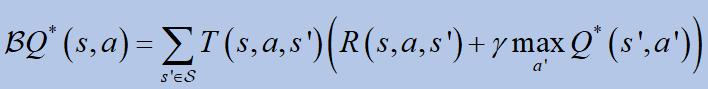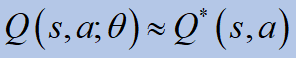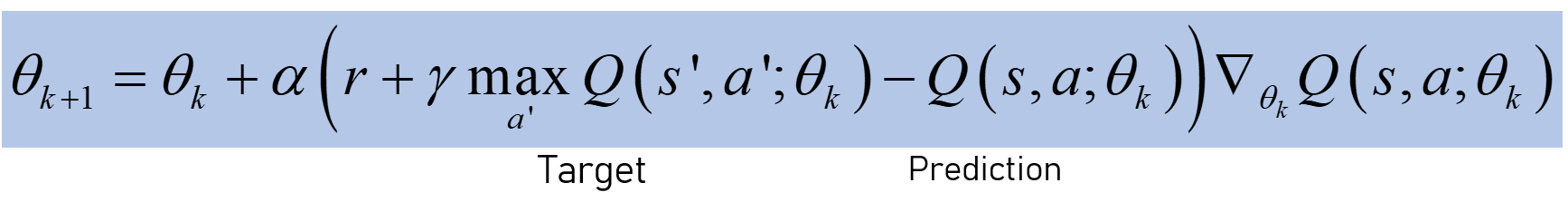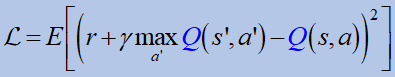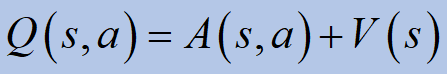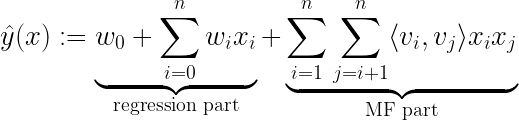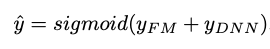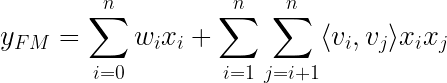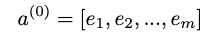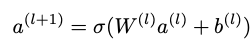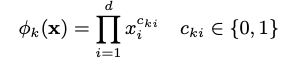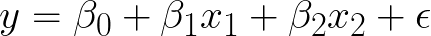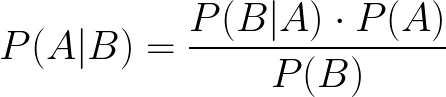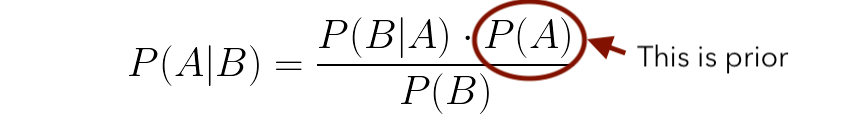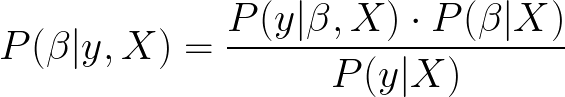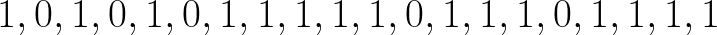저는 항상 도시지도를 좋아했고 몇 주 전에 나만의 예술적 버전을 만들기로 결정했습니다.인터넷 검색을 한 후이 놀라운 사실을 발견했습니다.지도 시간작성자프랭크 세발 로스.매혹적이고 편리한 튜토리얼이지만 더 자세하고 사실적인 청사진 맵을 선호합니다.그래서 나만의 버전을 만들기로 결정했습니다.이제 작은 파이썬 코드와 OpenStreetMap 데이터로 아름다운지도를 만드는 방법을 살펴 보겠습니다.
OSMnx 설치
우선, 우리는Python 설치가 있습니다.나는 사용하는 것이 좋습니다콘다깔끔한 작업 공간을 확보하기위한 가상 환경 (venv).또한 OpenStreetMap에서 공간 데이터를 다운로드 할 수있는 OSMnx Python 패키지를 사용할 것입니다.Venv를 만들고 두 개의 Conda 명령을 작성하기 만하면 OSMnx를 설치할 수 있습니다.
conda 구성-채널 앞에 추가 conda-forge conda create -n ox --strict-channel-priority osmnx
Downloading street networks
OSMnx를 성공적으로 설치 한 후 코딩을 시작할 수 있습니다.가장 먼저해야 할 일은 데이터를 다운로드하는 것입니다.데이터 다운로드는 다양한 방법으로 수행 할 수 있습니다. 가장 쉬운 방법 중 하나는graph_from_place ().
베를린 거리 네트워크 다운로드
graph_from_place ()여러 매개 변수가 있습니다.장소OpenStreetMaps에서 데이터를 검색하는 데 사용할 쿼리입니다.보유 _ 모두다른 요소와 연결되어 있지 않더라도 우리에게 모든 거리를 줄 것입니다.단순화반환 된 그래프를 약간 정리하고network_type얻을 거리 네트워크의 유형을 지정하십시오.
나는 검색을 찾고있다모두가능한 데이터를 사용하지만 드라이브 도로 만 다운로드 할 수도 있습니다.드라이브, 또는산책.
또 다른 가능성은graph_from_point ()GPS 좌표를 지정할 수 있습니다.이 옵션은 일반적인 이름을 가진 장소와 같은 여러 경우에 더 편리하며 더 정확합니다.사용dist그래프 중심의이 수 미터 내에있는 노드 만 유지할 수 있습니다.
마드리드 거리 네트워크 다운로드
또한 마드리드 나 베를린과 같은 더 큰 장소에서 데이터를 다운로드하는 경우 모든 정보를 검색하기 위해 조금 기다려야한다는 점을 고려해야합니다.
데이터 압축 풀기 및 채색
양자 모두graph_from_place ()과graph_from_point ()다음과 같이 목록에 압축을 풀고 저장할 수있는 MultiDiGraph를 반환합니다.Frank Ceballos 튜토리얼.
이 지점에 도달하면 데이터를 반복하고 색상을 지정하기 만하면됩니다.색상을 지정하고 조정할 수 있습니다.선폭거리 기지길이.
그러나 특정 도로를 식별하고 다르게 색상을 지정할 수도 있습니다.
내 예에서는 다음 색상으로 만 colourMap.py Gist를 사용하고 있습니다.
색상 =“# a6a6a6”
색상 =“# 676767”
색상 =“# 454545”
색상 =“#bdbdbd”
색상 =“# d5d5d5”
색상 =“#ffff”
그러나 취향에 맞는 새로운지도를 만들기 위해 색상이나 조건을 자유롭게 변경하십시오.
지도 플로팅 및 저장
마지막으로,지도를 그리는 데 남은 한 가지만 있으면됩니다.먼저지도의 중심을 식별해야합니다.중심이 될 GPS 좌표를 선택하십시오.그런 다음 테두리와 배경색을 추가하고bgcolor.북쪽,남쪽,동쪽과서쪽서쪽은 우리지도의 새로운 경계가 될 것입니다.이 좌표는 이러한 경계에서 이미지 기반을 자르고 더 큰지도를 원할 때 경계를 늘리면됩니다.다음을 사용하는 경우graph_from_point ()방법을 늘릴 필요가 있습니다dist당신의 필요에 따라 가치 기반.에 대한bgcolor청사진을 시뮬레이션하기 위해 파란색에서 진한 파란색 # 061529를 선택했지만 원하는대로 조정할 수 있습니다.
그런 다음지도를 플로팅하고 저장하기 만하면됩니다.나는 사용을 추천한다fig.tight_layout (pad = 0)서브 플롯이 잘 맞도록 플롯 매개 변수를 조정합니다.
결과
이 코드를 사용하여 다음 예제를 작성할 수 있지만 각 도시의 선 너비 또는 경계 제한과 같은 설정을 실행하는 것이 좋습니다.
마드리드 도시지도 — 포스터 크기
고려해야 할 한 가지 차이점graph_from_place ()과graph_from_point ()그것은graph_from_point ()주변에서 거리 데이터를 얻습니다.dist설정합니다.간단한지도를 원하는지 더 자세한지도를 원하는지에 따라 서로 교환 할 수 있습니다.마드리드 도시지도는graph_from_place ()베를린 도시지도는graph_from_point ().
베를린 시티지도
그 위에 포스터 크기 이미지를 원할 수도 있습니다.이를 달성하는 한 가지 쉬운 방법은무화과내부 속성ox.plot_graph ().무화과너비, 높이를 인치 단위로 조정할 수 있습니다.나는 보통 같은 더 큰 크기를 선택했습니다figsize = (27,40).
보너스 : 물 추가
OpenStreetMap에는 강 및 호수 또는 수로와 같은 기타 천연 수원의 데이터도 있습니다.다시 OSmnx를 사용하여이 데이터를 다운로드 할 수 있습니다.
천연 수원 다운로드
이전과 같은 방식으로이 데이터를 반복하고 색상을 지정할 수 있습니다.이 경우 # 72b1b1 또는 # 5dc1b9와 같은 파란색을 선호합니다.
마지막으로 그림을 저장하면됩니다.이 경우에는 테두리를 사용하지 않습니다.bbox내부plot_graph.그것은 당신이 놀 수있는 또 다른 것입니다.
강을 성공적으로 다운로드 한 후 두 이미지를 결합하면됩니다.약간의 Gimp 또는 Photoshop이 트릭을 수행 할 것입니다. 동일한 두 이미지를 만들어야합니다.fig_size또는 경계 제한,bbox,보다 쉬운 보간을 위해.
베를린 천연 수원
마무리
내가 추가하고 싶은 것은 도시 이름, GPS 좌표 및 국가 이름이 포함 된 텍스트입니다.한 번 더 Gimp 또는 Photoshop이 트릭을 수행합니다.
또한 물을 추가하면 일부 공간을 채우거나 바닷물과 같은 다른 수원을 칠해야합니다.강의 선은 일정하지 않지만 페인트 통 도구를 사용하여 이러한 간격을 채울 수 있습니다.
코드 및 결론
이러한지도를 만드는 코드는 내GitHub.자유롭게 사용 하시고 결과를 보여주세요 !!이 게시물을 좋아하고 다시 감사드립니다.프랭크 세발 로스및 Medium 커뮤니티.또한 포스터를 인쇄하고 싶다면 작은 가게를 열었습니다.Etsy내지도 제작과 함께.
A Short Introduction to Reinforcement Learning (RL)
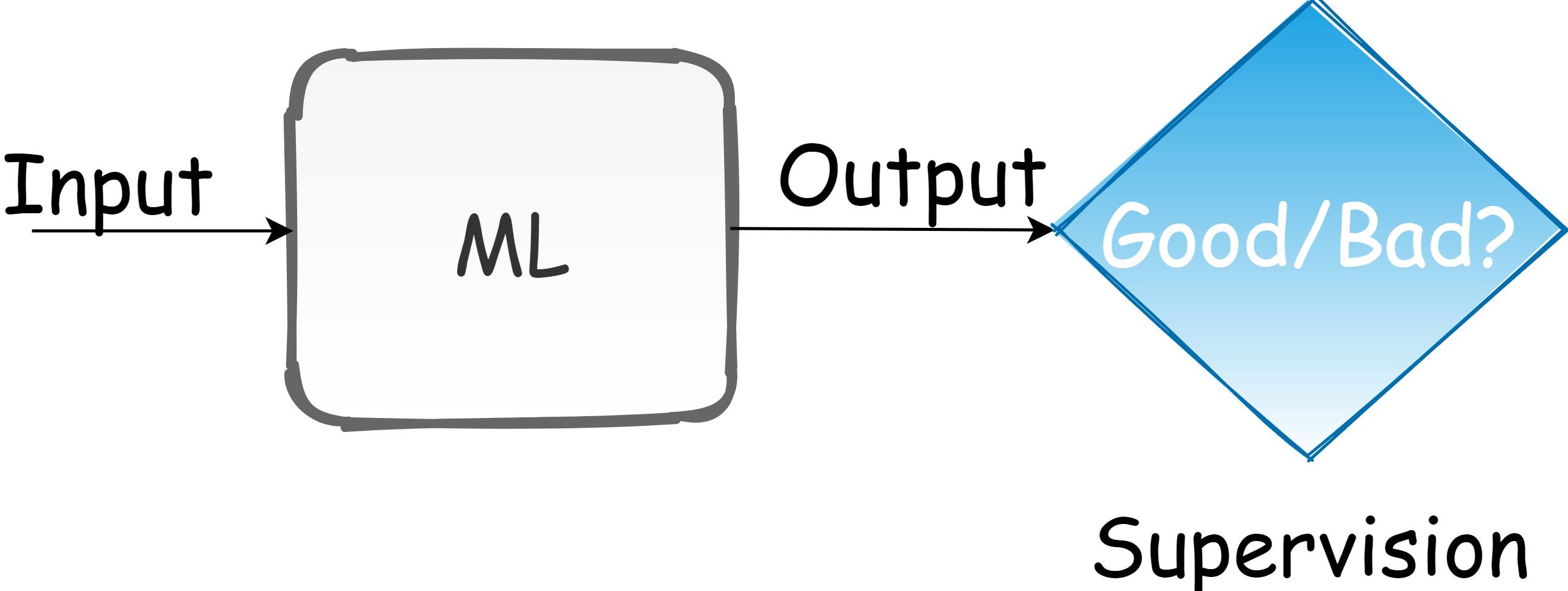
일반적인 기계 학습 접근 방식에는 세 가지 유형이 있습니다. 1) 학습 시스템이 레이블이 지정된 예를 기반으로 잠재 맵을 학습하는지도 학습, 2) 학습 시스템이 레이블이없는 예를 기반으로 데이터 배포를위한 모델을 설정하는 비지도 학습, 3) 강화 학습, 여기서의사 결정 시스템은 최적의 결정을 내릴 수 있도록 훈련됩니다.디자이너의 관점에서 모든 종류의 학습은 손실 함수에 의해 감독됩니다.감독의 출처는 인간에 의해 정의되어야합니다.이를 수행하는 한 가지 방법은 손실 함수입니다.
작성자의 이미지
감독 중디학습, 지상 실측 레이블이 제공됩니다.그러나 RL에서는 환경을 탐색하여 에이전트를 가르칩니다.에이전트가 과제를 해결하려는 세상을 디자인해야합니다.이 디자인은 RL과 관련이 있습니다.공식 RL 프레임 워크 정의는 [1]에 의해 제공됩니다.
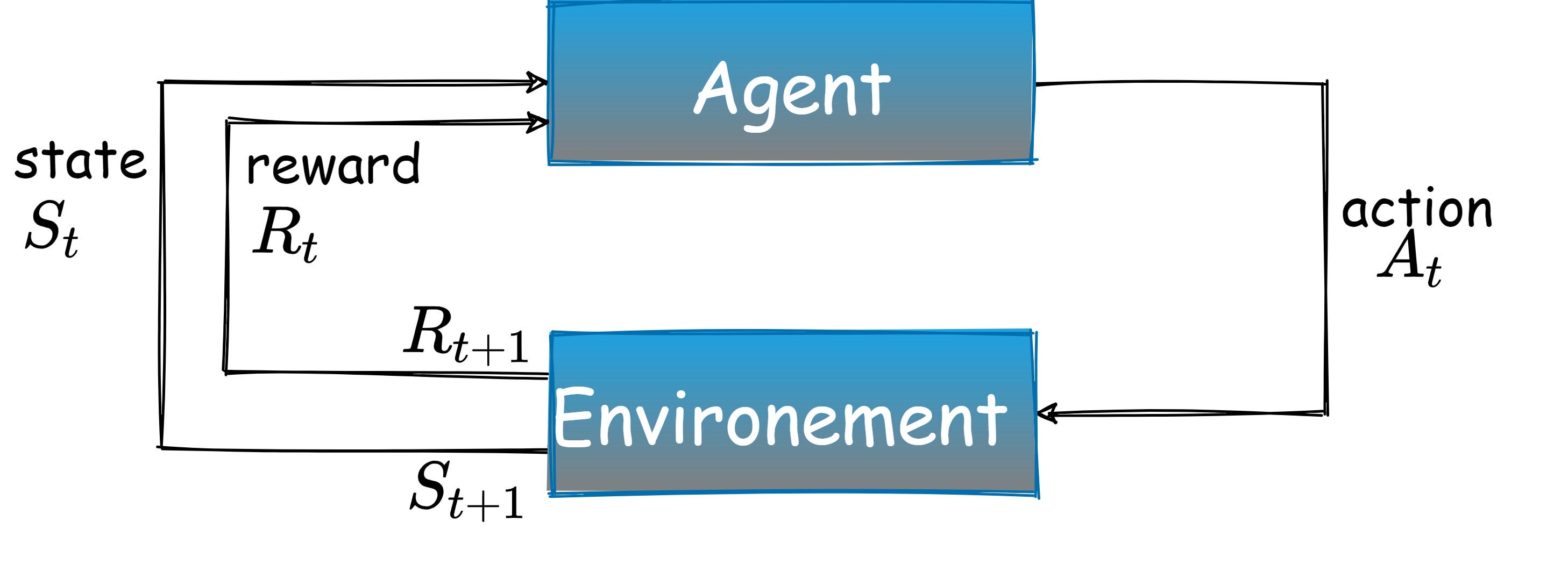
an에이전트에서 연기환경.모든 시점에서 에이전트는상태환경을 결정하고동작상태를 변경합니다.이러한 각 작업에 대해 에이전트는보상신호.에이전트의 역할은받은 총 보상을 극대화하는 것입니다.
RL 다이어그램 (저자 이미지)
그래서 어떻게 작동합니까?
RL은 시행 착오를 통해 순차적 인 의사 결정 문제를 해결하는 방법을 배우기위한 프레임 워크입니다.가끔 보상을 제공하는 세계의 오류.이것은 어떤 목표를 달성하기 위해 불확실한 환경에서 수행 할 일련의 작업을 경험을 통해 결정하는 작업입니다.행동 심리학에서 영감을받은 강화 학습 (RL)은이 문제에 대한 공식적인 틀을 제안합니다.인공 에이전트는 환경과 상호 작용하여 학습 할 수 있습니다.수집 된 경험을 사용하여 인공 에이전트는 누적 보상을 통해 주어진 일부 목표를 최적화 할 수 있습니다.이 접근법은 원칙적으로 과거 경험에 의존하는 모든 유형의 순차적 의사 결정 문제에 적용됩니다.환경은 확률적일 수 있으며 에이전트는 현재 상태에 대한 일부 정보 만 관찰 할 수 있습니다.
왜 깊이 들어가야합니까?
지난 몇 년 동안 RL은 도전적인 순차적 의사 결정 문제를 성공적으로 해결함으로써 점점 인기를 얻었습니다.이러한 성과 중 일부는 RL과 딥 러닝 기술의 조합 때문입니다.예를 들어 딥 RL 에이전트는 수천 개의 픽셀로 구성된 시각적 지각 입력으로부터 성공적으로 학습 할 수 있습니다 (Mnih et al., 2015/2013).
“AI에서 가장 흥미로운 분야 중 하나입니다.그것은 세계를 표현하고 이해하기 위해 심층 신경망의 힘과 능력을 합쳐서 세상을 행동하고 이해하는 능력과 결합하는 것입니다.”
이전에는 기계에 도달 할 수 없었던 광범위한 복잡한 의사 결정 작업을 해결했습니다.Deep RL은 의료, 로봇 공학, 스마트 그리드, 금융 등에서 많은 새로운 애플리케이션을 엽니 다.
RL의 유형
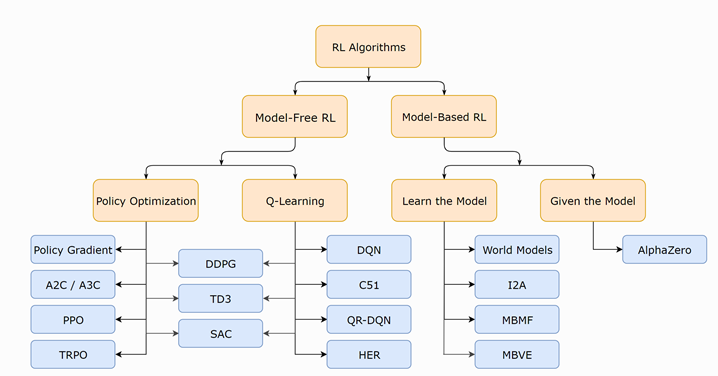
가치 기반: 상태 또는 상태-작업 값을 학습합니다.주에서 가장 좋은 행동을 선택하여 행동하십시오.탐험이 필요합니다.정책 기반: 상태를 행동으로 매핑하는 확률 적 정책 함수를 직접 학습합니다.샘플링 정책에 따라 행동하십시오.모델 기반: 세계의 모델을 배우고 모델을 사용하여 계획합니다.모델을 자주 업데이트하고 다시 계획하십시오.
수학적 배경
이제 우리는 “모델없는”접근 방식에 속하는 가치 기반 방법에 초점을 맞추고,보다 구체적으로 Q- 학습에 속하는 DQN 방법에 대해 논의 할 것입니다.이를 위해 필요한 수학적 배경을 빠르게 검토합니다.
어디이자형기대 값 연산자, 감마는 할인 계수,파이이다정책.그만큼최적의 기대 수익다음과 같이 정의됩니다.
최적의 V- 값 함수는 주어진 상태에서 예상되는 할인 된 보상입니다.에스에이전트는 정책을 따릅니다.파이 *그후에.
2.Q 값
관심있는 더 많은 기능이 있습니다.그중 하나는 품질 가치 기능입니다.
V- 기능과 유사하게 최적의큐값은 다음과 같이 지정됩니다.
최적큐-value는 주어진 상태에있을 때 그리고 주어진 행동에 대해 예상되는 할인 된 수익입니다.ㅏ,에이전트는 정책을 따릅니다.파이 *그후에.최적의 정책은이 최적 값에서 직접 얻을 수 있습니다.
삼.장점 기능
마지막 두 기능을 연관시킬 수 있습니다.
행동이 얼마나 좋은지 설명합니다.ㅏ직접 정책을 따를 때 예상 수익과 비교됩니다.파이.
4.Bellman 방정식
배우려면큐값, Bellman 방정식이 사용됩니다.독특한 솔루션을 약속합니다큐*:
어디비Bellman 연산자입니다.
최적의 가치를 약속하기 위해 : 상태-액션 쌍은 개별적으로 표현되고 모든 액션은 모든 상태에서 반복적으로 샘플링됩니다.
Q- 학습
정책을 벗어난 방법의 Q 학습은 주에서 행동을 취하고 학습하는 것의 가치를 배웁니다.큐가치와 세상에서 행동하는 방법을 선택합니다.상태-액션 값 함수를 정의합니다.에스,실행할 수 있는ㅏ, 및 팔로우파이.표 형식으로 표시됩니다.에 따르면큐에이전트는 모든 정책을 사용하여큐미래의 보상을 극대화합니다.큐직접 근사치큐*, 에이전트가 각 상태-작업 쌍을 계속 업데이트 할 때.
딥 러닝이 아닌 접근 방식의 경우이 Q 함수는 표일뿐입니다.
작성자의 이미지
이 표에서 각 요소는 보상 값이며, 훈련 중에 업데이트되어 정상 상태에서 할인 계수로 보상의 예상 값에 도달해야합니다.큐*값.실제 시나리오에서 가치 반복은 비현실적입니다.
Google의 이미지
에서브레이크 아웃 게임,상태는 화면 픽셀입니다. 이미지 크기 : 84×84, 연속 : 4 개 이미지, 회색 수준 : 256. 따라서큐-테이블은 :
언급하자면, 우주에는 10⁸² 원자가 있습니다.이것이 우리가 다음과 같은 문제를 해결해야하는 좋은 이유입니다.브레이크 아웃 게임심층 강화 학습에서…
DQN : Deep Q-Networks
우리는 신경망을 사용하여큐함수:
신경망은 함수 근사로 유용합니다.DQN은 Atari 게임에서 사용되었습니다.손실 함수에는 두 가지 Qs 함수가 있습니다.
표적: 특정 상태에서 행동을 취할 때 예상되는 Q 값.예측: 실제로 그 행동을 취할 때 얻는 가치 (다음 단계에서 가치를 계산하고 총 손실을 최소화하는 것을 선택).
매개 변수 업데이트 :
가중치를 업데이트 할 때 대상도 변경됩니다.신경망의 일반화 / 외삽으로 인해 상태-행동 공간에 큰 오류가 발생합니다.따라서 Bellman 방정식은 w.p.1.이 업데이트 규칙으로 오류가 전파 될 수 있습니다 (느림 / 불안정 등).
DQN 알고리즘은 다양한 ATARI 게임에 대한 온라인 설정에서 강력한 성능을 얻을 수 있으며픽셀.불안정성을 제한하는 두 가지 경험적 방법 : 1. 대상의 매개 변수큐-network는 N 반복마다 업데이트됩니다.이렇게하면 불안정성이 빠르게 전파되는 것을 방지하고 분산 위험을 최소화합니다.경험 리플레이 메모리 트릭을 사용할 수 있습니다.
DQN 아키텍처 (MDPI : 경제학에서 심층 강화 학습 방법 및 응용 프로그램에 대한 포괄적 인 검토)
DQN 트릭 : 리플레이와 엡실론 탐욕스러운 경험
리플레이 체험
DQN에서는 CNN 아키텍처가 사용됩니다.비선형 함수를 사용한 Q- 값의 근사값은 안정적이지 않습니다.경험 리플레이 트릭에 따르면 모든 경험은 리플레이 메모리에 저장됩니다.네트워크를 훈련 할 때 가장 최근의 작업 대신 재생 메모리의 임의 샘플이 사용됩니다.즉, 에이전트는 기억 / 저장 경험 (상태 전환, 행동 및 보상)을 수집하고 훈련을위한 미니 배치를 만듭니다.
엡실론 탐욕 탐사
로큐기능 수렴큐*, 실제로 발견 한 첫 번째 효과적인 전략으로 해결됩니다.따라서 탐사는 탐욕 스럽습니다.탐색하는 효과적인 방법은 확률이 “엡실론”이고 그렇지 않은 경우 (1- 엡실론), 탐욕스러운 행동 (가장 높은 Q 값)을 가진 무작위 행동을 선택하는 것입니다.경험은 엡실론 탐욕 정책에 의해 수집됩니다.
DDQN : Double Deep Q-Networks
의 최대 연산자큐-학습은 행동을 선택하고 평가하기 위해 동일한 값을 사용합니다.이는 과대 평가 된 값 (노이즈 또는 부정확 한 경우)을 선택하여 과도하게 낙관적 인 값을 추정하게 만듭니다.DDQN에는 각각 별도의 네트워크가 있습니다.큐.따라서 두 개의 신경망이 있습니다.현재 가중치로 얻은 값에 따라 정책이 여전히 선택되는 편향을 줄이는 데 도움이됩니다.
견인 신경망,큐각 기능 :
이제 손실 함수는 다음과 같이 제공됩니다.
Deep Q-Networks 결투
큐포함이점(ㅏ)값 (V) 그 상태에 있습니다.ㅏ조치를 취하는 이점으로 일찍 정의ㅏ주에스다른 모든 가능한 작업 및 상태 중에서.당신이 취하고 자하는 모든 행동이“아주 좋은”것이라면, 우리는 그것이 얼마나 더 나은지 알고 싶습니다.
결투 네트워크는 두 개의 개별 추정치를 나타냅니다. 하나는 상태 값 함수를위한 것이고 다른 하나는 상태 의존적 행동 이점 함수를위한 것입니다.코드 예제를 더 읽으려면듀얼 딥 큐 네트워크게시크리스 윤.
요약
우리는 강화 학습에 대한 일반적인 소개와이를 딥 러닝 맥락에 넣을 동기 부여와 함께 가치 기반 방법의 Q- 러닝을 제시했습니다.수학적 배경, DQN, DDQN, 몇 가지 트릭 및 결투 DQN이 탐구되었습니다.
저자 정보
Barak Or는 B.Sc.(2016), M.Sc.(2018) 항공 우주 공학 학위 및 B.A.Technion, Israel Institute of Technology에서 경제 및 경영학 박사 (2016, Cum Laude).그는 Qualcomm (2019–2020)에서 주로 기계 학습 및 신호 처리 알고리즘을 다루었습니다.Barak은 현재 그의 Ph.D.하이파 대학교에서.그의 연구 관심 분야는 센서 융합, 내비게이션, 기계 학습 및 추정 이론입니다.
이 게시물은실제 사례를 통해 향상 모델링의 메커니즘에 대한 심층 분석.여기에서는 데이터 과학 팀의탈라기한이 지난 차용인이 대출금을 상환 할 수 있도록 업 리프트 모델링을 적용했습니다.Tala는 세계에서 가장 접근하기 쉬운 소비자 신용 상품을 제공하며, 스마트 폰 앱을 통해 공식적인 신용 기록이없는 사람들에게 대출을 즉시 인수하고 지불합니다.
소개
그 기계는 여러 가지 방법 중학습은 비즈니스를위한 가치를 창출 할 수 있으며 개선 모델링은 덜 알려진 것 중 하나입니다.그러나 많은 사용 사례에서 가장 효과적인 모델링 기술 일 수 있습니다.비즈니스가 다른 고객을 위해 선택적으로 취할 수있는 비용이 많이 드는 조치가있는 모든 상황에서 고객의 행동에 영향을 미치기 위해 업 리프트 모델링은 해당 조치의 영향을 가장 많이받는 고객 하위 집합을 찾는 강력한 후보가되어야합니다.이는 비즈니스 전략에 대한 투자 수익을 극대화하는 데 중요합니다.
이 게시물에서는 Tala에서 업 리프트 모델링으로 다룬 비즈니스 문제, 업 리프트 모델의 기본 사항 및 모델 구축 방법, 업 리프트 모델의 예측을 설명 할 수있는 방법, 업 리프트 개념을 확장하여 직접 제공하는 방법에 대해 설명합니다.재정적 통찰력 및 생산에서 상승 모델의 성능을 모니터링하기위한 고려 사항.
Tala의 사용 사례 : 연체 대출자
차용인이 대출 만기일을 지나면 자신의 재정 건전성과 대출 한 사업의 건전성을 위험에 빠뜨립니다.기한이 지난 대출자에게 연락하여 대출금을 상환하도록 장려하는 Tala의 기본 수단 중 하나는 전화를 이용하는 것입니다.그러나 이것은 비용이 많이 드는 프로세스이며 전화 통화가 가져올 것으로 예상되는 수익 증가와 균형을 이루어야합니다. 차용인이 전화를 걸면 대금을 지불 할 가능성이 얼마나됩니까?
수학적으로 우리는 차용인에게 전화를함으로써 지불 가능성이 높아지는 것에 관심이 있습니다.이것은 차용인이 전화를 받았을 때와 전화를받지 않았을 때의 지불 확률의 차이로 정의됩니다.
작성자의 이미지
업 리프트 모델링의 전제는 전화가 주어지면 상환 가능성이 가장 큰 차용자를 식별하는 데 도움이 될 수 있다는 것입니다.즉, 더 설득력있는 사람.이러한 차용자를 식별 할 수 있다면 차용자와 Tala의 재정 건전성을 극대화하기 위해 리소스의 우선 순위를보다 효과적으로 지정할 수 있습니다.
기회에 집중
이제 개선 모델링의 목표를 알았으니 어떻게 거기에 도달 할 수 있을까요?향상 모델링은 무작위로 통제 된 실험에 의존합니다. 우리는 전화를받은 치료 그룹과 전화를받지 않은 통제 그룹 모두에있는 모든 다른 종류의 대출자의 대표 표본이 필요합니다.
이 데이터 세트를 얻은 후, 우리는 지불을하는 차용자의 비율이 대조군보다 치료 그룹에서 훨씬 더 높음을 관찰했습니다.이것은 전화 통화가 모든 차용자에게 평균적으로 상환을 효과적으로 장려한다는 의미에서“효과적”이라는 증거를 제공했습니다.이것은평균 치료 효과(먹었다).ATE의 정량화는 A / B 테스트의 일반적인 결과입니다.
그러나 우리가 관찰 한 대부분의 ATE에 대해 치료 그룹 내의 차용인 중 일부만이 책임이있을 수 있습니다.극단적 인 예로, 치료 그룹의 차용인 중 절반이 전체 ATE를 담당했을 수 있습니다.우리가 치료에 더 쉽게 대응할 수있는이 차용자를 미리 식별 할 수있는 방법이 있다면, 우리는 그들에게 전화 자원을 집중할 수있을 것이며 전화 통화가 거의 또는 전혀없는 사람들에게 시간을 낭비하지 않을 것입니다.효과.비 응답자를 참여시킬 다른 방법을 찾아야 할 수도 있습니다.이 사람들이 가지고있는 다양한 특성에 따라 사람마다 다양한 치료 효과를 결정하는 과정은 우리가조건부 평균 치료 효과(CATE).여기에서 머신 러닝과 예측 모델링이 등장합니다.
향상 모델 구축 및 설명
기계 학습에서 우리는 다음을 통해 차용자 간의 차이점을 설명 할 수 있습니다.풍모, 차용자에게 특정한 다양한 수량입니다.차용인의 결제 내역, 과거 전화 통화 결과 및 Tala 앱과의 상호 작용과 관련된 기능을 설계했습니다.이 기능은 차용인의갚을 의지와 능력,뿐만 아니라Tala와의 관계 구축 및 유지.차용인은듣고 배우다그들과 똑같이 할 수있는 기회를 주겠습니까?
위에서 설명한 기능과 모델링 프레임 워크로 무장 한 우리는 업 리프트 모델을 구축 할 준비가되었습니다.우리는 S-Learner라는 접근 방식을 사용했습니다.이에 대한 자세한 내용은업 리프트 모델링에 대한 이전 블로그 게시물.S-Learner를 구축하고 테스트 한 후 목표 변수 인 uplift (치료를 받고 치료하지 않은 예측 확률의 차이)와 S-Learner를 교육하는 데 사용되는 동일한 기능을 사용하여 교육 세트에 대해 별도의 회귀 모델을 교육했습니다.(S-Learner 접근 방식의 기능으로 간주되는 처리 플래그 제외).이 회귀 모델의 테스트 세트 SHAP 값을 사용하여 어떤 모델 기능이 상승 예측에 가장 큰 영향을 미치는지에 대한 통찰력을 얻을 수있었습니다.
여기서는 기능 이름이 익명으로 처리되었지만 가장 예측 가능한 기능에 대한 해석은 지불 의사가 있고, 대출 경험이 있으며, 다시 빌리고 싶을 수 있고, 전화를 통해 연락을받는 차용인이전화를 통해 상환하도록 장려 할 가치가있는 차용인.
상승 모델에 대한 SHAP 값으로, 예측에 영향을 미치는 상위 5 개의 익명화 된 요인을 나타냅니다.기능은 차용인의 지불 및 전화 통화 내역을 기반으로합니다.작성자의 이미지.
모델 사용 및 모니터링을위한 전략 설계
예측 된 확률 상승을 아는 것이 모델 기반 전략의 첫 번째 단계였습니다.그러나 우리는 누군가가 지불 할 가능성이 얼마나 더 높은지뿐만 아니라 전화 지원으로 인한 지불 금액의 증가 가능성에도 관심이 있습니다.이를 결정하기 위해 확률 증가를 차용자가 빚진 금액 및 지불 가능한 금액에 대한 정보와 결합했습니다.이것은 예측 된 확률 상승을수익 증가전화를 걸면 얼마나 가치가 있는지 차용인의 순위를 매길 수 있습니다.
예상 수익 상승에 대한 차용자의 순위를 매기는 기회는 예측 수익 상승의 여러 빈에 대한 처리 그룹과 통제 그룹 간의 평균 수익 차이로 실제 수익 상승을 계산하여 볼 수 있습니다.이러한 분석은 상세한 상향 십 분위수 차트의 아이디어와 유사합니다.여기.이를 위해 모델 테스트 세트를 사용했습니다.
수익 증가 십 분위수 차트 : 예상 수익 증가를 기준으로 계정의 순위를 매길 때 처리 및 통제 간의 평균 수익 차이입니다.작성자의 이미지.
결과에 따르면 예상 수익 증가는 전화 통화가 더 가치있는 계정을 효과적으로 식별합니다.이러한 방식으로 순위를 매긴 차용인 중 상위 10 % 만 호출하면 모든 차용자를 호출하여 사용할 수있는 증분 수익의 절반 이상을 얻을 수 있으며, 차용인 상위 절반을 호출하면 증분 수익의 90 %를 얻을 수 있습니다.실제로 녹색 선으로 표시된 차용자 당 전화 통신 서비스의 평균 비용을 고려할 때 차용자의 상위 50 % 만 전화를 걸 수있는 것이 분명합니다.
예상 수익 증가를 사용하여 전화 통신 지원을 안내 할 수있는 분명한 기회를 고려하여이 모델을 배포하여 전략을 안내했습니다.배포 후 모델 성능을 모니터링하기 위해 예측 된 전체 범위에서 전화 통화의 실제 증가를 조사 할 수있는 두 그룹을 만들었습니다.우리는 예상되는 상승률에 관계없이 무작위로 선택된 5 %의 대출자를 호출하고 다른 5 %를 호출하지 않음으로써이를 수행했습니다.이 테스트의 결과를 바탕으로 여기와 제 사이트에 표시된 것과 동일한 종류의 모델 평가 메트릭을 사용하여 모델이 프로덕션에서 의도 한대로 작동하고 있다는 결론을 내릴 수있었습니다.동반자 블로그 게시물.
결론적으로, 업 리프트 모델링을 통해 Tala는 이러한 노력을 가장 잘 수용 할 수있는 대출자에게 상환 노력을 집중하여 시간과 비용을 절약 할 수있었습니다.향상 모델링에 대한 Tala의 경험이 귀하의 작업에 도움이 되었기를 바랍니다.
딥 러닝 방법론이 발전함에 따라 신경망의 크기를 늘리면 성능이 향상된다는 데 일반적으로 동의했습니다.그러나 이는 메모리 및 컴퓨팅 요구 사항에 해를 끼치며 모델 학습을 위해 증가시켜야합니다.
이것은 Google의 사전 학습 된 언어 모델의 성능을 비교하여 관점에서 볼 수 있습니다.BERT, 다양한 아키텍처 크기에서.원래종이, Google의 연구원들은 평균접착제BERT-Base 79.6 점, BERT-Large 82.1 점.2.5의이 작은 증가는 추가로 230M 매개 변수 (110M 대 340M)를 가져 왔습니다!
로아르 자형계산을해도 각 매개 변수가 32 바이트의 정보 인 단 정밀도 (아래에서 자세히 설명)로 저장되면 230M 매개 변수는 메모리에서 0.92Gb와 동일합니다.이것은 그 자체로는 너무 크지 않은 것처럼 보일 수 있지만 각 훈련 반복 동안 이러한 매개 변수는 일련의 행렬 산술 단계를 거쳐 기울기와 같은 추가 값을 계산합니다.이러한 모든 추가 값은 빠르게 관리 할 수 없게 될 수 있습니다.
2017 년에 NVIDIA의 연구원 그룹은종이라는 기술을 사용하여 신경망 훈련의 메모리 요구 사항을 줄이는 방법을 자세히 설명합니다.혼합 정밀 교육 :
모델 정확도를 잃거나 하이퍼 파라미터를 수정할 필요없이 반 정밀도 부동 소수점 숫자를 사용하여 심층 신경망을 훈련하는 방법을 소개합니다.이것은 메모리 요구 사항을 거의 절반으로 줄이고 최근 GPU에서 산술 속도를 높입니다.
이 기사에서는 혼합 정밀도 훈련이 딥 러닝의 표준 알고리즘 프레임 워크에 어떻게 부합하는지와 모델 성능에 영향을주지 않고 계산 수요를 줄일 수있는 방법을 이해하는 방법을 살펴볼 것입니다.
부동 소수점 정밀도
이진 형식으로 부동 소수점 숫자를 나타내는 데 사용되는 기술 표준은 다음과 같습니다.IEEE 754, 1985 년 전기 전자 공학 연구소에서 설립.
IEEE 754에 명시된대로 2 진 16 (절반 정밀도)에서 2 진 256 (8 진 정밀도)까지 다양한 수준의 부동 소수점 정밀도가 있습니다. 여기서 “2 진”뒤의 숫자는 부동 소수점을 나타내는 데 사용할 수있는 비트 수와 같습니다.-포인트 값.
비트가 부호에 대해 예약 된 단일 비트를 사용하여 숫자의 이진 형식을 나타내는 정수 값과 달리 부동 소수점 값도 지수를 고려해야합니다.따라서 이러한 숫자를 이진 형식으로 표현하면 더 미묘하고 정밀도에 상당한 영향을 미칠 수 있습니다.
역사적으로 딥 러닝은 매개 변수를 표현하기 위해 단 정밀도 (binary32 또는 FP32)를 사용했습니다.이 형식에서 1 비트는 부호, 8 비트는 지수 (-126 ~ +127), 23 비트는 숫자로 예약되어 있습니다.반면에 반 정밀도 또는 FP16은 부호에 대해 1 비트, 지수에 대해 5 비트 (-14 ~ +14), 숫자에 대해 10을 예약합니다.
FP16 (상단) 및 FP32 (하단) 부동 소수점 숫자의 형식 비교.설명을 위해 표시된 숫자는 각 형식으로 표시 할 수있는 1보다 작은 가장 큰 숫자입니다.작가의 삽화.
그러나 이것은 비용이 듭니다.각각에 대한 최소 및 최대 양수, 정상 값은 다음과 같습니다.
뿐만 아니라 모든 지수 비트가 0으로 설정된 더 작은 비정규 화 된 숫자를 나타낼 수 있습니다.FP16의 경우 절대 한계는 2 ^ (-24)입니다. 그러나 비정규 화 된 숫자가 작아 질수록 정밀도가 감소합니다.
이 기사에서 부동 소수점 정밀도의 정량적 한계를 이해하기 위해 여기서 더 깊이 들어 가지 않을 것이지만 IEEE는 포괄적 인선적 서류 비치추가 조사를 위해.
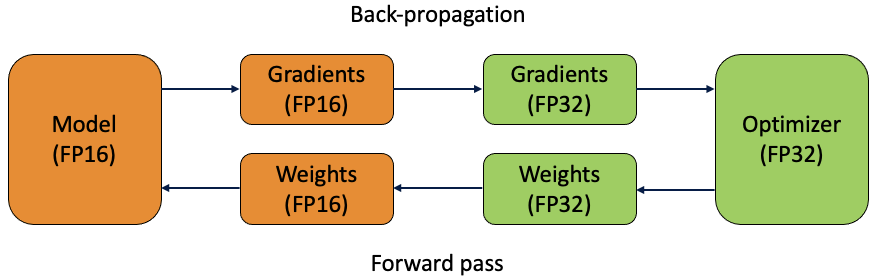
혼합 정밀 훈련
신경망 FP32의 표준 훈련 중에 증가 된 메모리 요구 사항으로 모델 매개 변수를 나타냅니다.혼합 정밀도 훈련에서 FP16은 훈련 반복 중에 가중치, 활성화 및 기울기를 저장하는 데 대신 사용됩니다.
그러나 위에서 보았 듯이 FP16이 저장할 수있는 값의 범위가 FP32보다 작고 숫자가 매우 작아 질수록 정밀도가 떨어지기 때문에 문제가 발생합니다.그 결과 계산 된 부동 소수점 값의 정밀도에 따라 모델의 정확도가 감소합니다.
이를 방지하기 위해 가중치의 마스터 사본이 FP32에 저장됩니다.이것은 각 훈련 반복의 일부 동안 FP16으로 변환됩니다 (1 회 전진 패스, 역 전파 및 가중치 업데이트).반복이 끝나면 가중치 기울기를 사용하여 최적화 단계에서 마스터 가중치를 업데이트합니다.
혼합 정밀도 훈련은 가중치를 FP16으로 변환하고 기울기를 계산 한 후 학습률을 곱하고 최적화 프로그램에서 가중치를 업데이트하기 전에 FP32로 다시 변환합니다.작가의 삽화.
여기에서 가중치의 FP32 사본을 유지하는 이점을 볼 수 있습니다.학습률이 종종 작기 때문에 가중치 기울기를 곱하면 종종 작은 값이 될 수 있습니다.FP16의 경우 크기가 2 ^ (-24)보다 작은 숫자는 표현할 수 없기 때문에 0과 동일합니다 (FP16의 비정규 화 된 한계입니다).따라서 FP32에서 업데이트를 완료하면 이러한 업데이트 값을 유지할 수 있습니다.
FP16과 FP32를 모두 사용하기 때문에이 기술이 호출됩니다.혼합-정밀 교육.
손실 스케일링
혼합 정밀도 훈련은 대부분 정확도 유지 문제를 해결했지만 실험 결과 학습률을 곱하기 전에도 작은 기울기 값이 발생하는 경우가있었습니다.
NVIDIA 팀은 2 ^ -27 미만의 값이 주로 훈련과 관련이 없지만 보존하는 데 중요한 [2 ^ -27, 2 ^ -24) 범위의 값이 있지만 FP16 한계를 벗어난 값이 있음을 보여주었습니다.훈련 반복 동안 0으로 동일시합니다.정밀도 한계로 인해 기울기가 0과 같은이 문제를 언더 플로우라고합니다.
따라서 그들은 손실 스케일링을 제안하는데, 이는 순방향 패스가 완료된 후 역 전파 전에 손실 값에 스케일 팩터를 곱하는 프로세스입니다.그만큼연쇄 법칙모든 그라디언트가 FP16 범위 내에서 이동 한 동일한 요소에 의해 이후에 배율이 조정됨을 나타냅니다.
그래디언트가 계산되면 이전 섹션에서 설명한대로 FP32에서 마스터 가중치를 업데이트하는 데 사용되기 전에 동일한 배율로 나눌 수 있습니다.
손실 스케일링 동안 손실은 표현 가능한 FP16 값의 범위 내에 있는지 확인하기 위해 포워드 패스 후 미리 정의 된 계수에 의해 스케일됩니다.체인 규칙으로 인해 동일한 요소로 그라디언트 크기가 조정되므로 역 전파 후 실제 그라디언트를 검색 할 수 있습니다.작가의 삽화.
NVIDIA “딥 러닝 성능”선적 서류 비치, 배율 인수 선택에 대해 설명합니다.이론적으로는 오버플로로 이어질만큼 충분히 크지 않는 한 큰 스케일링 계수를 선택하는 데 단점이 없습니다.
스케일링 계수를 곱한 기울기가 FP16의 최대 제한을 초과하면 오버플로가 발생합니다.이 경우 그래디언트가 무한이되고 NaN으로 설정됩니다.신경망 훈련의 초기 시대에 다음 메시지가 나타나는 것은 비교적 일반적입니다.
그라데이션 오버플로.스킵 단계, 손실 스케일러 0 손실 스케일 감소…
이 경우 무한 기울기를 사용하여 가중치 업데이트를 계산할 수없고 향후 반복을 위해 손실 척도가 감소하므로 단계를 건너 뜁니다.
자동 혼합 정밀도
2018 년에 NVIDIA는파이 토치전화꼭대기, 여기에는 AMP (자동 혼합 정밀도) 기능이 포함되어 있습니다.이것은 PyTorch에서 혼합 정밀도 훈련을 사용하기위한 간소화 된 솔루션을 제공했습니다.
단 몇 줄의 코드로 훈련을 FP32에서 GPU의 혼합 정밀도로 이동할 수 있습니다.이것은두 가지 주요 이점:
훈련 시간 단축— 훈련 시간은 모델 성능의 현저한 감소없이 1.5 배에서 5.5 배까지 감소 된 것으로 나타났습니다.
메모리 요구 사항 감소— 이것은 아키텍처 크기, 배치 크기 및 입력 데이터 크기와 같은 다른 모델 요소를 증가시키기 위해 메모리를 확보했습니다.
이번 주에는 홀로 코스트 메모리얼 데이와 가장 저명한 우생 학자들의 집이었던 University College London (UCL)의 통계학과에서 공부 한 5 년이 끝났습니다.
이번 주까지는 Galton Lecture Theatre와 Pearson Building에서 칼 피어슨과 로널드 피셔의 작품을 공부 한 것이 신경 쓰이지 않았습니다.하지만 그래야만했다.
우리 가족의 대부분은 T에서 살해당했습니다h“열등한 인종”을 근절하기위한 정권의 일환으로 홀로 코스트.그러나 나는 여전히 피어슨, 피셔, 갈튼 (그리고 다른 사람들)을 그들의 기여에 대해 인정 받고 존경받을 자격이있는 통계의 아버지로 여겼다.나는 그들이 시간의 산물이고 그들의 연구가 유전학이면의 통계에서 자연스러운 진보라고 순진하게 생각했습니다.이것은 사실이 아닙니다.
참고 : 이것은 내 자신의 순진함을 설명하기 위해 작성한 개인 기사입니다.그러나 이것은 우리 분야의 진정한 기원을 고려하지 않은 유일한 사람이 아니기 때문에 다른 통계 학자 및 데이터 과학자를 대상으로합니다.
Galton은 통계 개발에 매우 근본적으로 중요하고 비판적인 것으로 간주되어 많은 사람들이 1883 년 그의 우생학 분야 설립을 의도적으로 간과 할 것입니다.
그의 시간의 산물?
Galton의 삶에 관한 4 권의 책을 검토하면서 Clauser (2007) ¹는이 주장을 사용하여 한 권의 책을 비판합니다.
“우생학에 대한 그의 견해와 관련하여 Galton의 삶의 모든 측면을 보는 Brookes의 경향으로 인해 볼륨이 제한됩니다.Brookes는 그가 살았던 시대의 맥락에서 Galton의 견해를 배치하지 못합니다…Galton의 편협함의 증거.”
‘당시의 산물’주장은 수년 동안 편협함을 정당화하기 위해 끊임없이 사용됩니다.이를 관점에서 살펴보면 Galton은 그의 사촌의 작품 인 The Origin of Species에서 영감을 얻었습니다.다윈은 특정 인구를 설명하기 위해 ‘야만인’과 같은 단어를 사용했기 때문에 당시의 산물이라고 할 수 있습니다.그러나 Darwin은 인종 차별에 대해 공개적으로 반대했으며 Galton의 우생학에 대한 연구를 홍보하거나 기여하지 않았습니다 .² Galton의 ‘우생학’에서 타고난 인종주의에 대해 의문이있는 경우 다음은 그의 용어를 만든 이유입니다.
우리는 재고를 개선하는 과학을 간단히 표현하기를 원합니다.… 아무리 멀리 떨어져있는 경향이있는 모든 영향을 인식하여 더 적합한 종족이나 혈통이 적합하지 않은 종족보다 빠르게 우세 할 수있는 더 나은 기회를 제공합니다.그렇지 않으면 그랬을 것입니다 .³
그리고 Galton의 견해에 대해 여전히 의심이 있다면 그는 또한 다음과 같이 썼습니다.
열등한 종족의 점진적인 멸종에 대해 대부분 상당히 불합리한 감정이 존재합니다 .⁴
대학 첫날 Galton Lecture Theatre에 앉았을 때 Galton이 대량 학살이 ‘대부분의 경우 상당히 비합리적’이라고 느꼈다고 들었다면 그의 이름과 내 주변의 사진에 대해 덜 편안하게 느꼈을 것입니다.내 연구는 근본적으로 Galton의 연구에 의존하고 있으며 Galton에게 빚을졌습니다.그렇다고 3 년 동안 매일 그의 이름을 듣고 말해야한다는 의미는 아닙니다.
UCL에서 열린 Galton 전시회는 우생학에 대한 그들의 기여에 대한 인식을 높이기 위해 열렸습니다.크레딧 : UCL Image Store.⁵
칼 피어슨
Karl Pearson은 Galton의 제자이자 많은 주목할만한 업적 중 하나입니다.
가설 테스트 개발
p- 값 사용 개발
카이-제곱 검정 정의
순간의 방법 도입
반세 미티
Mein Kampf가 출판 된 해에 Pearson은 유대인 인구에 대해 다음과 같이 썼습니다.
“[그들은] 기생 종족으로 발전 할 것입니다…평균적으로, 남녀 모두에 대해이 외국인 유대인 인구는 원주민보다 육체적으로나 정신적으로 다소 열등합니다.”⁶
그리고 히틀러가 수상이되었을 때 피어슨은 다음과 같이 말했습니다.
오늘날에도 제한적이거나 너무 자주 잘못 해석 된 경험에서 비롯된 일반적인 인상이 너무 많고, 어떤 국가에서든 우생 법을 무제한으로 서둘러 진행하기에는 너무 많은 부적절하게 입증되고 너무 가볍게 받아 들여진 이론이 있습니다 .⁷
그의 경고가 즉시 나타날 때까지 합리적으로 보일 수 있습니다.
그러나이 진술은 성 문제에 대한 모든 우생 교육과 모든 형태의 공동 활동을 무기한 중단하는 변명으로 받아 들여서는 안됩니다 .⁷
나는 Pearson 건물의 작은 교실에서 Pearson의 작업에 근본적으로 의존하는 프레젠테이션으로 학부를 마쳤습니다.UCL의 우생학과의 첫 번째 의장 인 피어슨은 내가 무시할 수없고 무시할 수없는 방식으로 내 삶과 일에 기여해 왔습니다.그의 공헌은 통계 분야와 다른 많은 분야에 필수적이었습니다.그러나 다시 나는 내가 Pearson 건물을 걷는 것이 편하다고 느꼈을 지 궁금해합니다.
UCL 피어슨 빌딩 (왼쪽), 1985.⁸크레딧 : UCL 이미지 스토어.
로널드 피셔 경
Fisher의 통계 작업은 통계적 추론의 많은 중요한 방법을 수립하고 장려했습니다.그의 공헌은 다음과 같습니다.
유의 한 p- 값에 대한 정규 임계 값으로 p = 0.05 설정
최대 가능성 추정 촉진
분석 분석 (ANOVA) 개발
그만큼아이리스데이터 세트 (이것은 믿을 수 없을 정도로 사소한 기여로 보이지만 매일 사용합니다) ⁹
Pearson과 Galton처럼 Fisher는 존경 받았습니다.’다윈 이후 가장 위대한 생물 학자’가 누구인지 물었을 때 Richard Dawkins는 Fisher¹⁰를 지명했습니다 (도킨스가 공개 한 견해를 감안할 때 놀라운 일이 아닐 수 있음).Fisher의 학생 중 한 명인 Bodmer는 Fisher의 삶에 대한 짧지 만 빛나는 전기를 썼고 Fisher를“달콤”하고“좋다”라고 묘사했습니다 .¹¹ 우생학에 대해서는 언급하지 않았습니다.
나치 우생 학자 Otmar Freiherr von Verschuer에 대해 Fisher는 다음과 같이 썼습니다.
그들의 편견에도 불구하고 나는 당이 특히 정신적으로 부족한 사람들과 같은 명백한 결함을 제거함으로써 독일 인종 주식에 진심으로 이익을주기를 원했다는 것은 의심 할 여지가 없습니다. 그리고 나는 von Verschuer가 내가 가져야하는 것처럼 주었다는 것을 의심하지 않습니다.그와 같은 운동에 대한 그의 지원을 받았습니다 .¹²
저는 UCL에서 3 학년이 될 때까지 Fisher의 이름을 접하지 못했으며 다시 한 번 훌륭한 통계학 자로 찬사를 받았습니다.말할 것도없이 대량 학살은 논의되지 않았습니다.
건물 및 성명
최근 기사에서 사람들의 이름을 딴 건물에 대해 설명합니다.
그것들과 그들의 아이디어를 이해하는 올바른 방법은 그것이 드러나는 것보다 더 많은 것을 숨기는 주석이없는 기념관을 통하는 것이 아니라 박물관에서 적절하게 맥락화 된 전시를 통하는 것입니다 .¹³
사람에 대한 포괄적 인 진술도 마찬가지입니다.나는 Dawkins가 Fisher를“Darwin 이래로 가장 위대한 생물 학자”라고 묘사했을 때 이것은 순수한 산출물과 그 분야에만 기여한 것에 근거한 것이라고 생각합니다.그러나 피셔의 이름을 딴 건물처럼“가장 큰”이라는 단어는 그 사람 자체에 대한 판단을 포함합니다.이 사람이 “위대한”사람이라고 암시 적으로 가정하고 우리는 자동으로 “위대한”이 “좋은”을 의미한다고 가정합니다 (정의의 일부는 아니지만).주석이없는 기념관과 마찬가지로 전면적 인 진술은 그들이 드러내는 것보다 더 많은 것을 숨 깁니다.
통계와 우생학의 아버지
건물과 강의실의 이름을 바꾸는 것은 쉽습니다.오래전에 취해야 할 조치이지만 UCL을 비판하는 것은 아닙니다.공로로 그들은 정보를 수집하고 모든 사람의 피드백과 의견을 듣기 위해 설문 조사를 실시하는 데 수년을 보냈습니다.
통계 또는 데이터 과학 분야에서 일하는 것은 우생학의 그늘에서 일하는 것입니다.5 년 동안 나는 내가이 그림자 아래 있다는 사실조차 알지 못했고 매우 부끄럽습니다.하지만 나 자신을 탓할 수는 없습니다.나는 제공된 방정식을 사용하고 내가들은 방법을 연구했지만 방법에 속하는 이름은 고려하지 않았습니다.나는 다른 수학자 및 통계 학자와 다수가 될 가능성이 있다고 생각합니다.이것은 괜찮지 않습니다.나는 모든 통계 과정에 통계의 전체 역사와 그“아버지”에 대한 강의가 최소한 하나 포함되어야한다고 생각합니다.
실패에서 성공
건물의 이름이 바뀌어도‘Pearson ’s Chi-Squared test’와‘Fisher ’s information’을 (매일) 사용하겠습니다.그들의 이름은 저와 영원히 붙어 있고 이제 그들의 신념도 그렇습니다.나는이 사람들이 통계에 기여한 것을 존중하고 영감을받을 것이지만, 이제 그들의 성격을 칭찬하거나 우연히 그들의 신념을 용인하지 않고도 그들에 대해 이야기 할 수 있습니다.나는 과거의 방법을 활용하여 미래의 긍정적, 선, 윤리적 선택을 촉진 할 것입니다.다른 사람들이 실패한 부분을 배우면 여러 세대의 통계학자가 성공하는 방법을 배울 수 있습니다.
우리 시대의 제품
안타깝게도 경고로만 끝낼 수 있습니다.우생학이 현대 정치에서 다시 등장 할 가능성은 거의 없지만 (불가능하지는 않지만), 통계와 데이터는 그 어느 때보 다 조작되고 있습니다.
잘못된 결과를 반환하는 기계 학습의 순진한 오용에서 원시 데이터의 악의적 인 조작에 이르기까지이 분야는 테스트되고 있습니다.정부에서 개인, 러시아에서 팔로 알토, 안티 마스 커에서 안티 백서까지;데이터 및 통계 과실의 전체 결과는 아직 알려지지 않았습니다.
이런 일이 일어나 자 멍하니 앉아 있으면 우리는 ‘그 시대의 산물’이 될 것입니다.이것만으로는 충분하지 않습니다.데이터 과학에는 더 많은 규제가 필요합니다.의사들은 히포크라테스 선서가 있습니다. 우리는 나이팅게일 선서를하지 않는 이유는 무엇입니까?“데이터 나 결과를 조작하지 마십시오.통계의 윤리적 사용을 장려합니다.이해하는 모델 만 훈련하십시오.우생학을 홍보하지 마십시오”.
Pandas는 Python을위한 매우 인기있는 데이터 분석 및 조작 라이브러리입니다.데이터를 표 형식으로 처리 할 수있는 다양하고 강력한 기능을 제공합니다.
Pandas의 두 가지 핵심 데이터 구조는 DataFrame과 Series입니다.DataFrame은 레이블이있는 행과 열이있는 2 차원 구조입니다.SQL 테이블과 유사합니다.시리즈는 레이블이 지정된 1 차원 배열입니다.시리즈의 값 레이블을 인덱스라고합니다.DataFrame과 Series는 모든 데이터 유형을 저장할 수 있습니다.
이 기사에서는시리즈에서 수행 할 수있는 다양한 작업을 보여주는 20 개의 예제를 살펴 보겠습니다.
먼저 라이브러리를 가져온 다음 예제부터 시작하겠습니다.
numpy를 np로 가져 오기 팬더를 pd로 가져 오기
1. DataFrame is composed of Series
DataFrame의 개별 행 또는 열은 시리즈입니다.
왼쪽의 DataFrame을 고려하십시오.특정 행이나 열을 선택하면 반환되는 데이터 구조는 시리즈입니다.
a = df.iloc [0, :] 인쇄 (유형 (a)) pandas.core.series.Seriesb = df [0] 유형 (b) pandas.core.series.Series
2. Series consists of values and index
시리즈는 레이블이있는 배열입니다.인덱스라고하는 값과 레이블에 액세스 할 수 있습니다.
ser = pd.Series ([ 'a', 'b', 'c', 'd', 'e'])print (ser.index) RangeIndex (시작 = 0, 중지 = 5, 단계 = 1)print (ser.values) ['에이 비 씨 디이']
3. Index can be customized
이전 예에서 볼 수 있듯이 0부터 시작하는 정수 인덱스는 기본적으로 Series에 할당됩니다.그러나 index 매개 변수를 사용하여 변경할 수 있습니다.
이 포스트에서는FastAPI: Rest API를 생성하기위한 Python 기반 프레임 워크입니다.이 프레임 워크의 몇 가지 기본 기능을 간략하게 소개 한 다음 연락처 관리 시스템을위한 간단한 API 세트를 만들겠습니다.이 프레임 워크를 사용하려면 Python에 대한 지식이 매우 필요합니다.
FastAPI 프레임 워크를 논의하기 전에 REST 자체에 대해 조금 이야기 해 보겠습니다.
Wikipedia에서 :
REST (Representational State Transfer)웹 서비스를 만드는 데 사용할 제약 조건 집합을 정의하는 소프트웨어 아키텍처 스타일입니다.RESTful 웹 서비스라고하는 REST 아키텍처 스타일을 따르는 웹 서비스는 인터넷에서 컴퓨터 시스템 간의 상호 운용성을 제공합니다.RESTful 웹 서비스를 사용하면 요청 시스템이 일관되고 사전 정의 된 상태 비 저장 작업 집합을 사용하여 웹 리소스의 텍스트 표현에 액세스하고 조작 할 수 있습니다.SOAP 웹 서비스와 같은 다른 종류의 웹 서비스는 자체 임의의 작업 집합을 노출합니다. [1]
FastAPI의 제작자는 거인의 어깨에 서서 다음과 같은 기존 도구와 프레임 워크를 사용했다고 믿었습니다.Starlette과Pydantic
Installation and Setup
나는 사용할거야PipenvAPI 개발 환경을 설정합니다.Pipenv를 사용하면 컴퓨터에 설치된 항목에 관계없이 개발 환경을 쉽게 격리 할 수 있습니다.또한 컴퓨터에 설치된 것과 다른 Python 버전을 선택할 수 있습니다.그것은 사용합니다Pipfile모든 프로젝트 관련 종속성을 관리합니다.여기서 Pipenv를 자세히 다루지 않을 것이므로 프로젝트에 필요한 명령 만 사용합니다.
다음을 실행하여 PyPy를 통해 Pipenv를 설치할 수 있습니다.pip 설치 pipenv
pipenv 설치 --python 3.9
설치가 완료되면 다음 명령을 실행하여 가상 환경을 활성화 할 수 있습니다.pipenv 쉘
당신은 또한 실행할 수 있습니다pipenv 설치 --three여기서 3은 Python 3.x를 의미합니다.
설치가 완료되면 다음 명령을 실행하여 가상 환경을 활성화 할 수 있습니다.pipenv 쉘
먼저FastAPI다음 명령을 실행합니다.pipenv 설치 fastapi
그것은pipenv, 핍이 아닙니다.쉘에 들어가면 다음을 사용할 것입니다.pipenv.기본적으로 pip를 사용하고 있지만 모든 항목은Pipfile.그만큼Pipfile아래와 같이 보일 것입니다.
이제 개발 환경을 설정했습니다.이제 첫 번째 API 엔드 포인트 작성을 시작할 때입니다.다음과 같은 파일을 생성하겠습니다.main.py.이것이 우리 앱의 진입 점이 될 것입니다.
fastapi에서 가져 오기 FastAPI앱 = FastAPI ()@앱.가져 오기("/") def home () : return { "Hello": "FastAPI"}
Flask에서 작업 한 적이 있다면 거의 비슷할 것입니다.필요한 라이브러리를 가져온 후앱인스턴스를 만들고 데코레이터로 첫 번째 경로를 만들었습니다.
이제 어떻게 실행하는지 궁금합니다.음, FastAPI는유비 콘ASGI 서버입니다.당신은 단순히 명령을 실행합니다uvicorn main : app --reload
파일 이름 (본관이 경우 .py) 및 클래스 객체 (앱이 경우) 서버를 시작합니다.나는-재 장전변경 될 때마다 자동으로 다시로드되도록 플래그를 지정합니다.
방문http://localhost:8000/JSON 형식으로 메시지가 표시됩니다.{ "Hello": "FastAPI"}
멋지죠?
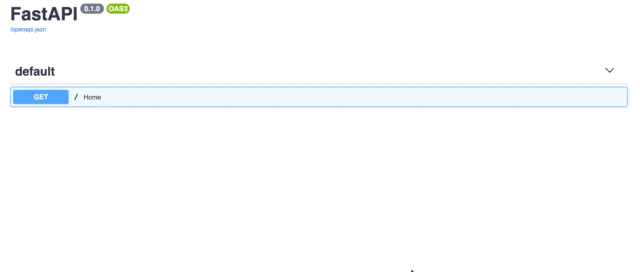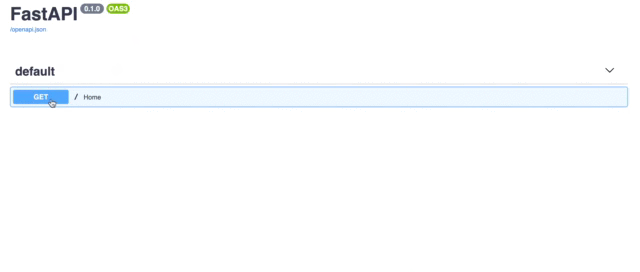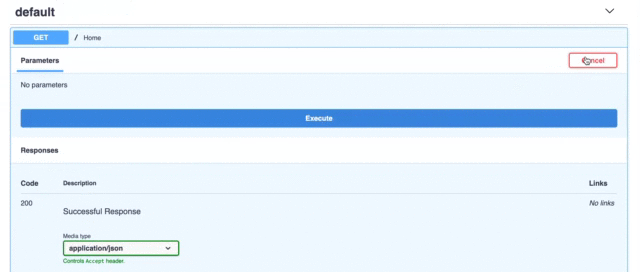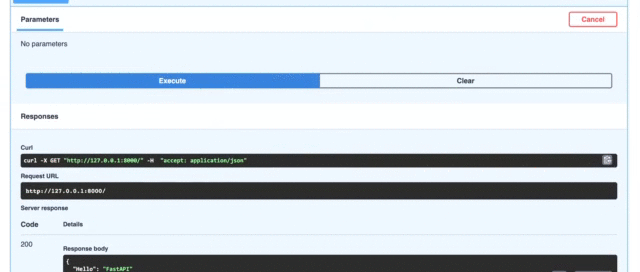
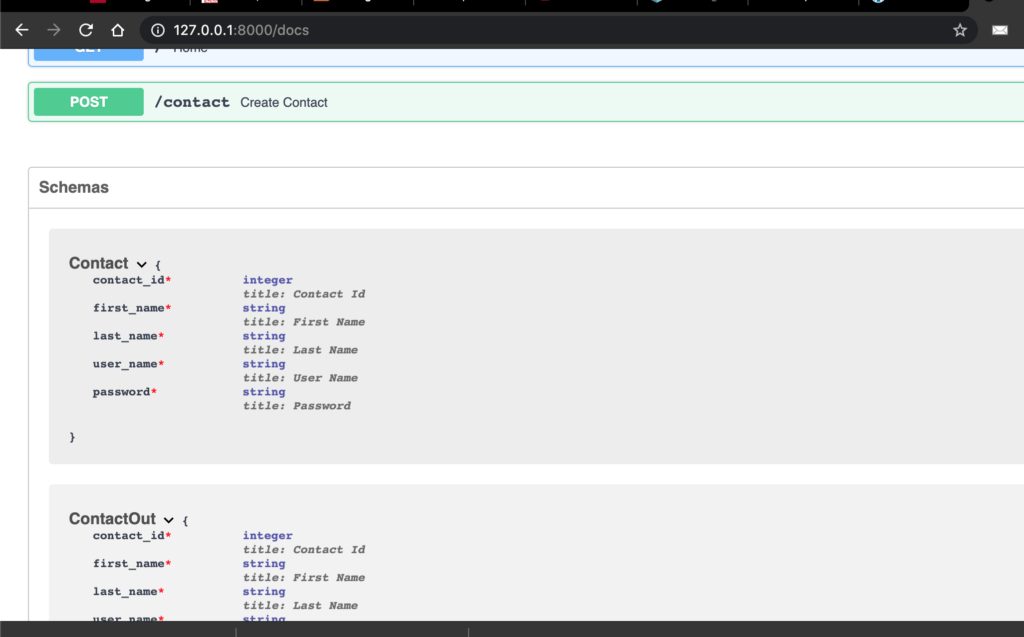
FastAPI는 API 문서 엔진도 제공합니다.방문하면http://localhost:8000/docsSwagger UI 인터페이스를 사용하고 있습니다.
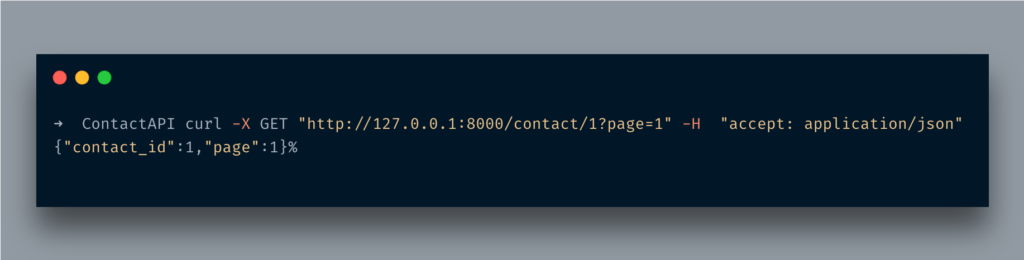
여기에서 다른 매개 변수를 전달했습니다.페이지유형을 설정선택 사항 [int]여기.선택 사항이며 이름에서 알 수 있습니다.선택 과목매개 변수.유형 설정int정수 값만 받아들이도록하는 것입니다. 그렇지 않으면 위에서했던 것처럼 오류가 발생합니다.
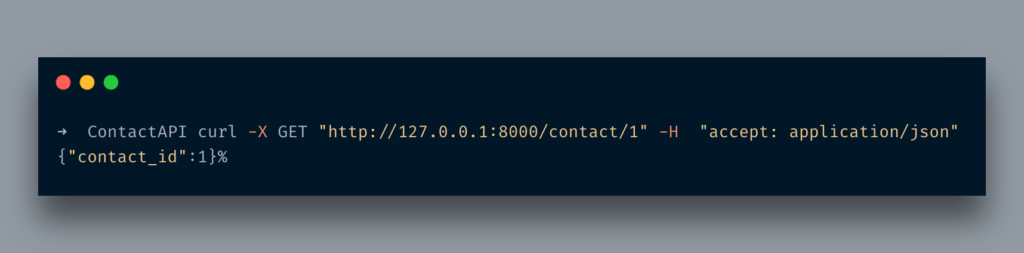
URL에 액세스http://127.0.0.1:8000/contact/1?page=5다음과 같은 내용이 표시됩니다.
멋지죠?
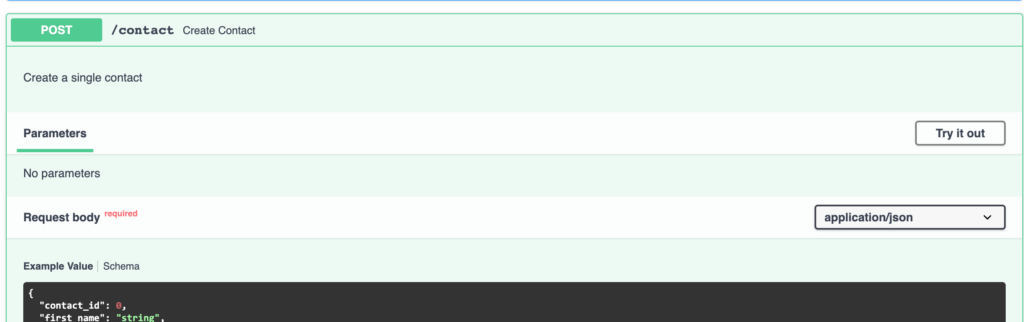
지금까지 우리는 수동으로dict.시원하지 않습니다.단일 값을 입력하고 YUUGE JSON 구조를 반환하는 것은 매우 일반적입니다.FastAPI는이를 처리하는 우아한 방법을 제공합니다.Pydantic 모델.
Pydantic모델은 실제로 데이터 유효성 검사에 도움이됩니다. 그게 무슨 뜻입니까?전달되는 데이터가 유효한지 확인하고 그렇지 않으면 오류를 반환합니다.우리는 이미 Python의 유형 힌트를 사용하고 있으며 이러한 데이터 모델은 삭제 된 데이터가 통과되도록합니다.약간의 코드를 작성해 봅시다.이 목적을 위해 연락처 API를 다시 확장하겠습니다.
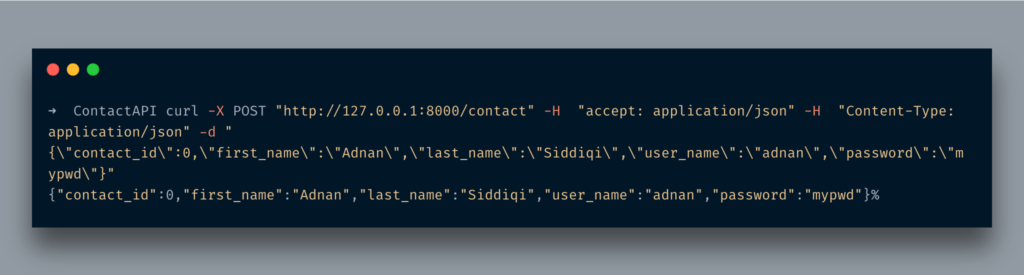
나는 수입했다BaseModelpydantic의 클래스.그 후, 저는BaseModel클래스에 3 개의 필드를 설정합니다.나는 또한 그것의 유형을 설정하고 있음을 주목하십시오.완료되면우편API 끝점 및접촉그것에 매개 변수.나는 또한 사용하고 있습니다비동기여기에 간단한 파이썬 함수를코 루틴.FastAPI는 즉시 지원합니다.
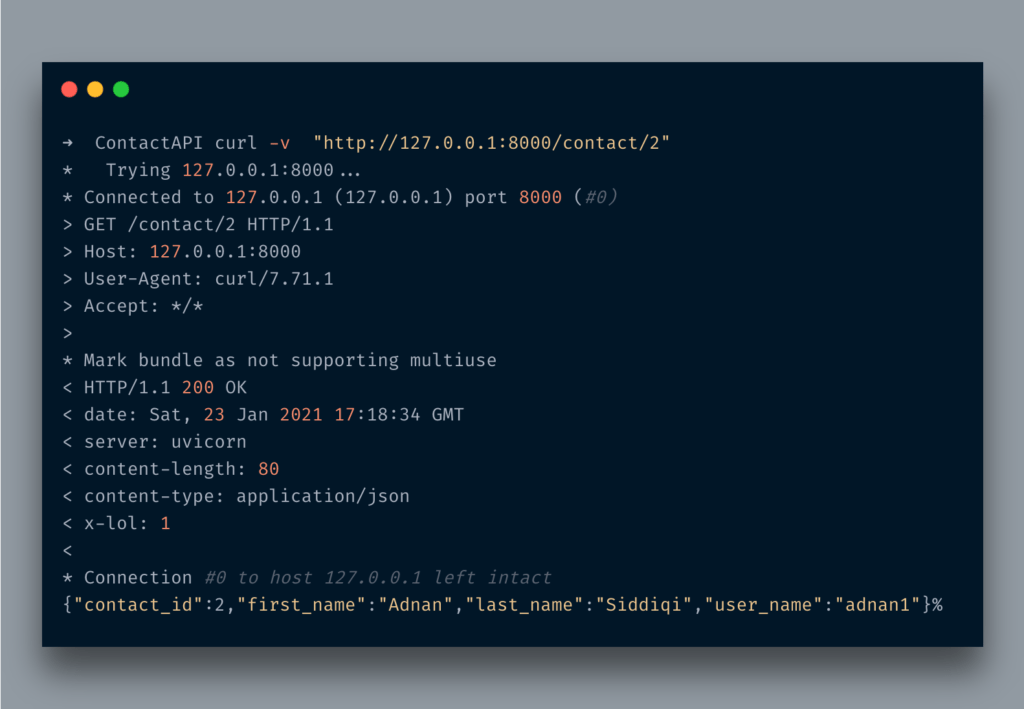
이동http://localhost:8080/docs다음과 같은 내용이 표시됩니다.
CURL 명령을 실행하면 다음과 같은 내용이 표시됩니다.
예상대로 방금 반환접촉JSON 형식의 개체.
아시다시피 암호를 포함하여 전체 모델을 JSON 형식으로 덤프합니다.암호가 일반 텍스트 형식이 아니더라도 의미가 없습니다.그래서 뭐 할까?응답 모델답입니다.
응답 모델이란?
이름에서 알 수 있듯이응답 모델요청에 대한 응답을 보내는 동안 사용되는 모델입니다.기본적으로 방금 모델을 사용하면 모든 필드를 반환합니다.응답 모델을 사용하여 사용자에게 반환 할 데이터의 종류를 제어 할 수 있습니다.코드를 약간 변경해 보겠습니다.
클래스 Contact (BaseModel) : contact_id : int first_name : str last_name : str user_name : str 암호 : strContactOut (BaseModel) 클래스 : contact_id : int first_name : str last_name : str user_name : str@앱.가져 오기("/") def home () : return { "Hello": "FastAPI"}@앱.post ( '/ contact', response_model = ContactOut) async def create_contact (연락처 : 연락처) : 반환 연락처
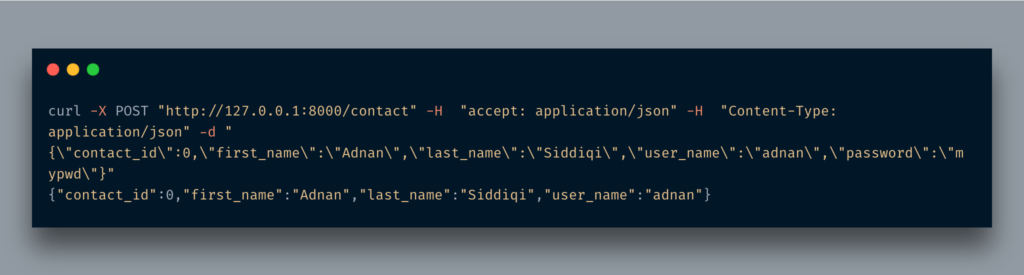
다른 수업을 추가했습니다.ContactOut거의 사본입니다접촉수업.여기서 다른 점은암호들.그것을 사용하기 위해, 우리는 그것을response_model매개 변수우편데코레이터.그게 다야.이제 동일한 URL을 실행하면 암호 필드가 반환되지 않습니다.
보시다시피 여기에는 비밀번호 필드가 표시되지 않습니다.눈치 채면/ docsURL도 볼 수 있습니다.
여러 방법으로 사용하려는 경우 다른 응답 모델을 사용하는 것이 가능하지만 단일 방법에서 기밀 정보를 생략하려는 경우에는 다음을 사용할 수도 있습니다.response_model_exclude데코레이터의 매개 변수.
After running the curl command you will see something like the below:
You can find x-lol헤더 중.LOL!
Conclusion
따라서이 게시물에서는 고성능 API를 빌드하기 위해 FastAPI를 사용하는 방법을 배웠습니다.우리는 이미 Flask라는 최소한의 프레임 워크를 가지고 있지만 FastAPI의 비동기 지원은 REST API를 통해 액세스되는 기계 학습 모델과 같은 최신 프로덕션 시스템에 매우 매력적입니다.나는 그 표면을 긁었다.자세한 내용은official FastAPI웹 사이트.
다음 포스트에서는 DB와의 통합, 인증 등과 같은 몇 가지 고급 주제에 대해 논의 할 것입니다.
최근 2019 년 5 월에 Facebook은 몇 가지 추천 접근 방식을 오픈 소스로 제공하고DLRM(딥 러닝 추천 모델).이 블로그 게시물은 DLRM 및 기타 최신 추천 접근 방식이 도메인의 이전 결과에서 파생 될 수있는 방법을 살펴보고 내부 작동 및 직관을 자세히 설명함으로써 어떻게 그리고 왜 잘 작동하는지 설명하기위한 것입니다.
맞춤형 AI 기반 광고는요즘 온라인 마케팅에서 게임의 이름은 Facebook, Google, Amazon, Netflix 및 co와 같은 회사가 온라인 마케팅 정글의 왕입니다. 왜냐하면 이러한 추세를 채택했을뿐만 아니라 본질적으로이를 발명하고 전체 비즈니스 전략을 구축했기 때문입니다.그것.넷플릭스의“즐길 수있는 다른 영화”나 아마존의“이 상품을 구매 한 고객도 구매했습니다…”는 온라인 세상에서 많은 예입니다.
자연스럽게, 저는 일상적인 Facebook과 Gooogle 사용자로서 어느 시점에서 스스로에게 물었습니다.
“이게 정확히 어떻게 작동합니까?”
예, 우리 모두는 협업 필터링 / 행렬 분해가 작동하는 방식을 설명하는 기본적인 영화 추천 예제를 알고 있습니다.또한, 사용자가 특정 제품을 좋아하는지 여부에 대한 확률을 출력하는 간단한 분류기를 사용자별로 훈련시키는 접근 방식에 대해 말하는 것이 아닙니다.이 두 가지 접근 방식, 즉 협업 필터링과 콘텐츠 기반 추천은 사용할 수있는 성능과 예측을 산출해야하지만 Google, Facebook 및 Co는 확실히 더 나은 것을 가져야합니다. 그렇지 않으면 어디에 있지 않을 것입니다.그들은 오늘입니다.
오늘날의 고급 추천 시스템의 출처를 이해하려면 문제에 대한 두 가지 기본 접근 방식을 살펴보아야합니다.
특정 사용자가 특정 항목을 얼마나 좋아하는지 예측합니다.
온라인 마케팅 세계에서는 평점, 좋아요 등과 같은 명시적인 피드백과 클릭, 검색 기록, 댓글 또는 같은 암시 적 피드백을 기반으로 가능한 광고의 클릭률 (CTR)을 예측하는 데 추가됩니다.웹 사이트 방문.
콘텐츠 기반 필터링과협업필터링
1. 콘텐츠 기반 필터링
느슨하게 말한 콘텐츠 기반 추천은 사용자의 온라인 기록을 사용하여 사용자가 특정 제품을 좋아하는지 여부를 예측하는 것을 의미합니다.여기에는 사용자가 제공 한 좋아요 (예 : Facebook), 검색 한 키워드 (예 : Google), 단순히 특정 웹 사이트를 클릭하고 방문한 횟수가 포함됩니다.대체로 사용자의 선호도에 초점을 맞 춥니 다.예를 들어이 사용자의 특정 광고 그룹에 대한 클릭률 (또는 등급)을 출력하는 간단한 이진 분류기 (또는 회귀 자)를 생각할 수 있습니다.
2. 협업 필터링
그러나 협업 필터링은 유사한 사용자의 선호도를 조사하여 사용자가 특정 제품을 좋아할지 여부를 예측하려고합니다.여기에서 등급 매트릭스가 사용자와 영화에 대한 하나의 임베딩 매트릭스로 분해되는 영화 추천에 대한 표준 매트릭스 분해 (MF) 접근 방식을 생각할 수 있습니다.
클래식 MF의 단점은 예를 들어 어떤 부가 기능도 사용할 수 없다는 것입니다.영화 장르, 개봉일 등 MF 자체는 기존의 상호 작용을 통해 배워야합니다.또한 MF는 아직 누구에게도 평가되지 않은 신작은 추천 할 수없는 이른바 ‘콜드 스타트 문제’에 시달리고있다.콘텐츠 기반 필터링은 이러한 두 가지 문제를 해결하지만 유사한 사용자의 선호도를 볼 수있는 예측 능력이 부족합니다.
두 가지 다른 접근 방식의 장점과 단점은 두 아이디어가 어떻게 든 하나의 모델로 결합되는 하이브리드 접근 방식의 필요성을 매우 분명하게 나타냅니다.
하이브리드 추천 모델
1. 분해 기계
2010 년 Steffen Rendle이 소개 한 아이디어 중 하나는분해 기계.행렬 분해와 회귀를 결합하는 기본적인 수학적 접근 방식을 보유합니다.
학습 중에 추정해야하는 모델 매개 변수는 다음과 같습니다.
⟨∙, ∙⟩은 V에서 행으로 볼 수있는 ℝᵏ 크기의 vᵢ와 vⱼ 두 벡터 사이의 내적입니다.
이 모델에 던져지는 데이터 x를 표현하는 방법의 예를 볼 때이 방정식이 어떻게 의미가 있는지 보는 것은 매우 간단합니다.Steffen Rendle의 Factorization Machines에 대한 백서에 설명 된 예제를 살펴 보겠습니다.
사용자가 특정 시간에 영화에 등급을 부여하는 영화 리뷰에 다음과 같은 거래 데이터가 있다고 상상해보십시오.
user u ∈ U = {Alice (A), Bob (B), . . .}
movie (item) i ∈ I = {Titanic (TI), Notting Hill (NH), Star Wars (SW), Star Trek (ST), . . .}
rating r ∈ {1,2,3,4,5} at time t ∈ ℝ
Fig.1, S. Rendle — 2010 IEEE International Conference on Data Mining, 2010- “Factorization Machines”
위의 그림을 보면 하이브리드 추천 모델에 대한 데이터 설정을 볼 수 있습니다.사용자와 항목을 나타내는 희소 특성과 추가 메타 또는 부가 정보 (예 :이 예에서 “시간”또는 “최근 영화 등급”)는 모두 대상 y에 매핑되는 특성 벡터 x의 일부입니다.이제 핵심은 모델에 의해 처리되는 방법입니다.
FM의 회귀 부분은 표준 회귀 작업과 같이 희소 데이터 (예 : “사용자”)와 고밀도 데이터 (예 : “시간”)를 모두 처리하므로 FM 내에서 콘텐츠 기반 필터링 접근 방식으로 해석 될 수 있습니다.
FM의 MF 부분은 이제 기능 블록 간의 상호 작용 (예 : “사용자”와 “영화”간의 상호 작용)을 설명합니다. 여기서 행렬 V는 협업 필터링 접근 방식에 사용되는 임베딩 행렬로 해석 될 수 있습니다.이러한 교차 사용자 영화 관계는 다음과 같은 통찰력을 제공합니다.
vⱼ를 포함하는 다른 사용자 j와 유사한 임베딩 vᵢ (영화 속성에 대한 선호도를 나타냄)를 가진 사용자 i는 사용자 j와 유사한 영화를 매우 좋아할 수 있습니다.
회귀 부분과 MF 부분에 대한 두 가지 예측을 함께 추가하고 하나의 비용 함수에서 매개 변수를 동시에 학습하면 이제 사용자를위한 권장 사항을 만들기 위해 “양쪽 세계의 최고”접근 방식을 사용하는 하이브리드 FM 모델이 생성됩니다.
언뜻보기에 Factorization Machine의이 하이브리드 접근 방식은 이미 NLP 또는 컴퓨터 비전과 같은 많은 다른 AI 분야가 과거에 입증 되었 듯이 완벽한 “양쪽 세계의 최고”모델 인 것처럼 보입니다.
“신경망에 던져 넣으면 더 나아질 것입니다.”
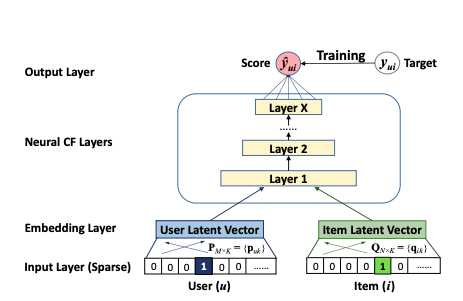
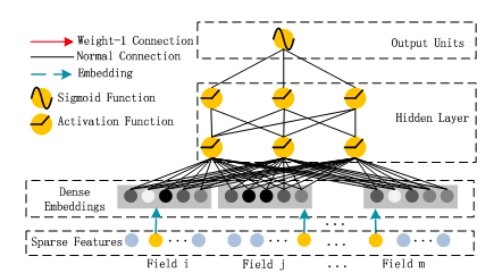
2. 넓고 깊은 NCF (Neural Collaborative Filtering) 및 DeepFM (Deep Factorization Machine)
먼저 NCF 논문을 살펴봄으로써 신경망 접근 방식으로 협업 필터링을 어떻게 해결할 수 있는지 살펴볼 것입니다. 이는 분해 기계의 신경망 버전 인 Deep Factorization Machines (DeepFM)로 이어질 것입니다.왜 그들이 일반 FM보다 우월하고 신경망 아키텍처를 해석 할 수 있는지 알아볼 것입니다.추천 시스템에서 딥 러닝의 첫 번째 주요 혁신 중 하나 인 Google에서 이전에 출시 한 Wide & amp; Deep 모델을 개선하여 DeepFM이 어떻게 개발되었는지 살펴 보겠습니다.이것은 마침내 우리를 DeepFM에 대한 단순화 및 약간의 조정으로 볼 수있는 2019 년 Facebook에서 발표 한 앞서 언급 한 DLRM 문서로 이어질 것입니다.
NCF
2017 년에 연구원 그룹은작업신경 협업 필터링에 대해.여기에는 신경망을 사용한 협업 필터링에서 행렬 분해에 의해 모델링 된 기능적 관계를 학습하기위한 일반화 된 프레임 워크가 포함되어 있습니다.저자는 또한 고차 상호 작용을 달성하는 방법 (MF는 차수 2에 불과 함)과 두 접근 방식을 결합하는 방법을 설명했습니다.
일반적인 아이디어는 신경망이 (이론적으로) 모든 기능적 관계를 배울 수 있다는 것입니다.즉, 협업 필터링 모델이 표현하는 MF와의 관계도 신경망으로 학습 할 수 있습니다.NCF는 기본적으로 신경망을 통해 두 임베딩 간의 MF 내적 관계를 학습하기 위해 사용자와 항목 (표준 MF와 유사) 모두에 대한 간단한 임베딩 계층을 제안한 다음 간단한 다층 퍼셉트론 신경망이 뒤 따릅니다.
그림 2. X He, L Liao, H Zhang, L Nie, X Hu, TS Chua의“Neural Collaborative Filtering”에서 발췌 한 제 26 차 월드 와이드 웹 국제 컨퍼런스, 2017 년
이 접근 방식의 장점은 MLP의 비선형성에 있습니다.MF에서 사용되는 간단한 내적은 항상 2 차 학습 상호 작용으로 모델을 제한하는 반면, X 레이어가있는 신경망은 이론적으로 훨씬 더 높은 수준의 상호 작용을 학습 할 수 있습니다.예를 들어 남성, 십대 및 RPG 컴퓨터 게임과 같이 상호 작용이있는 세 가지 범주 적 기능을 생각해보십시오.
실제 문제에서 우리는 임베딩에 대한 원시 입력으로 사용자 및 항목 이진화 된 벡터를 사용하는 것이 아니라 가치있을 수있는 다양한 기타 메타 또는 부가 정보 (예 : 연령, 국가, 오디오 / 텍스트 녹음, 타임 스탬프)를 분명히 포함합니다.,…) 그래서 실제로 우리는 매우 고차원적이고 매우 희소하며 연속적인 카테고리 혼합 데이터 세트를 가지고 있습니다.이 시점에서, 위에서 제시된 그림 2의 신경망은 단순한 이진 분류 피드-포워드 신경망의 형태로 콘텐츠 기반 추천으로 해석 될 수 있습니다.그리고이 해석은 CF와 콘텐츠 기반 추천 간의 하이브리드 접근 방식이되는 방식을 이해하는 데 중요합니다.네트워크는 실제로 모든 기능적 관계를 학습 할 수 있으므로 CF 차원의 3 차 이상의 상호 작용 (예 :x₁ ∙ x₂ ∙ x₃ 또는 σ (… σ (w₁x₁ + w₂x₂ + w₃x₃ + b)) 형식의 고전적인 신경망 분류 의미의 비선형 변환을 여기서 배울 수 있습니다.
고차 상호 작용을 학습하는 힘을 갖추고 있으므로 신경망을 저차 학습으로 잘 알려진 모델과 결합하여 모델이 차수 1과 2의 저차 상호 작용도 쉽게 학습 할 수 있도록 만들 수 있습니다.상호 작용, Factorization Machine.이것이 DeepFM의 저자가 논문에서 제안한 내용입니다.고차 및 저차 기능 상호 작용을 동시에 학습하기위한이 조합 아이디어는 많은 최신 추천 시스템의 핵심 부분이며 업계에서 제안 된 거의 모든 네트워크 아키텍처에서 어떤 형태로든 찾을 수 있습니다.
DeepFM
DeepFM은 FM과 심층 신경망 간의 혼합 접근 방식으로, 둘 다 동일한 입력 임베딩 레이어를 공유합니다.원시 기능은 연속 필드가 자체적으로 표현되고 범주 형 필드가 원-핫 인코딩되도록 변환됩니다.NN의 마지막 레이어에서 제공하는 최종 (예 : CTR) 예측은 다음과 같이 정의됩니다.
이것은 두 네트워크 구성 요소 인 FM 구성 요소와 Deep 구성 요소의 시그 모이 드 활성화 합계입니다.
그만큼FM 성분신경망 아키텍처 스타일로 꾸민 일반 Factorization Machine입니다.
그림 2. Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, Xiuqiang He.DeepFM : CTR 예측을위한 인수 분해 기계 기반 신경망.arXiv 사전 인쇄 arXiv : 1703.04247, 2017.
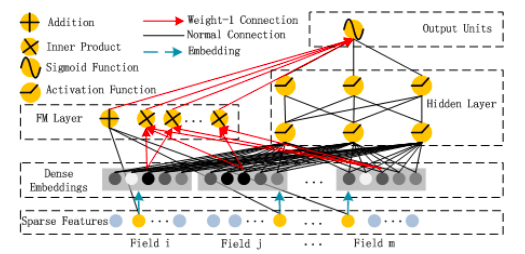
FM 레이어의 덧셈 부분은 원시 입력 벡터 x를 직접 가져 와서 (Sparse Features Layer) 각 요소에 가중치를 곱한 다음 ( “Normal Connection”) 합산합니다.FM 레이어의 Inner Product 부분도 원시 입력 x를 가져 오지만, 임베딩 레이어를 통과 한 후에 만 임베딩 벡터 사이에 가중치 (“Weight-1 Connection”)없이 내적을 취합니다.다른 “Weight-1 연결”을 통해 두 부분을 함께 추가하면 앞서 언급 한 FM 방정식이 생성됩니다.
이 방정식에서 xᵢxⱼ 곱셈은 i = 1에서 n까지의 합을 쓸 수있을 때만 필요합니다.실제로 신경망 계산의 일부가 아닙니다.네트워크는 임베딩 레이어 아키텍처로 인해 내적을 취하기 위해 어떤 임베딩 벡터 vᵢ, vⱼ를 자동으로 인식합니다.
이 임베딩 레이어 아키텍처는 다음과 같습니다.
그림 4. Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, Xiuqiang He.DeepFM : CTR 예측을위한 인수 분해 기계 기반 신경망.arXiv 사전 인쇄 arXiv : 1703.04247, 2017.
Vᵖ는 k 개의 열이있는 각 필드 p = {1,…, m}에 대한 임베딩 행렬이지만 필드의 이진화 된 버전에는 요소가 있습니다.따라서 임베딩 레이어의 출력은 다음과 같이 제공됩니다.
이것은 완전히 연결된 레이어가 아닙니다. 즉, 필드의 원시 입력과 다른 필드의 임베딩간에 연결이 없다는 점에 유의해야합니다.이렇게 생각해보십시오. 성별에 대한 원-핫 인코딩 벡터 (예 : (0,1))는 평일의 임베딩 벡터와 관련이 없습니다 (예 : (0,1,0,0,0,0,0))원시 이진화 된 평일 “화요일”이며 예를 들어 k = 4; (12,4,5,9))와 함께 벡터를 임베딩합니다.
Factorization Machine 인 FM 구성 요소는 차수 1 및 차수 2 상호 작용의 높은 중요성을 반영하며, 이는 Deep 구성 요소 출력에 직접 추가되고 최종 레이어의 시그 모이 드 활성화에 공급됩니다.
그만큼깊은 구성 요소이론상 모든 심층 신경망 아키텍처로 제안됩니다.저자는 특히 일반적인 피드 포워드 MLP 신경망 (소위 PNN)을 살펴 보았습니다.일반 MLP는 다음 그림에 나와 있습니다.
그림 3. Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, Xiuqiang He.DeepFM : CTR 예측을위한 인수 분해 기계 기반 신경망.arXiv 사전 인쇄 arXiv : 1703.04247, 2017.
원시 데이터 (원-핫 인코딩 된 범주 입력으로 인해 매우 희소)와 다음과 같은 신경망 계층 사이에 임베딩 계층이있는 표준 MLP 네트워크 :
σ는 활성화 함수, W는 가중치 행렬, a는 이전 계층의 활성화, b는 편향입니다.
이를 통해 전반적인 DeepFM 네트워크 아키텍처가 생성됩니다.
매개 변수와 함께 :
특성 i와 다른 특성 (임베딩 레이어) 간의 상호 작용의 영향을 측정하기위한 잠재 벡터 Vᵢ
Vᵢ은 FM 구성 요소로 전달되어 주문 2 상호 작용 (FM 구성 요소)을 모델링합니다.
원시 특성 i (FM 구성 요소)의 순서 1 중요성에 가중치 부여
Vᵢ는 또한 모든 고차 상호 작용을 모델링하기 위해 Deep 구성 요소로 전달됩니다 (& gt; 2) (Deep 구성 요소).
Wˡ 및 bˡ, 신경망 가중치 및 편향 (Deep Component)
고차 및 저차 상호 작용을 동시에 얻는 열쇠는 특히 FM과 Deep 구성 요소 모두에 대해 동일한 임베딩 레이어를 사용하여 하나의 비용 함수로 모든 매개 변수를 동시에 훈련하는 것입니다.
Wide & amp; Deep 및 NeuMF와 비교
이 아키텍처를 잠재적으로 더 좋게 만드는 방법에 대해 상상할 수있는 많은 변형이 있습니다.그러나 핵심은 고차 및 저차 상호 작용을 동시에 모델링하는 방법에 대한 하이브리드 접근 방식에서 모두 유사합니다.DeepFM의 저자는 또한 MLP 부분을 내장 계층과 결합 된 초기 입력으로 FM 계층을 가져 오는 심층 신경망 인 소위 PNN과 교환 할 것을 제안했습니다.
NCF 논문의 저자는 또한 NeuMF ( “Neural Matrix Factorization”)라고하는 유사한 아키텍처를 내놓았습니다.FM을 하위 구성 요소로 사용하는 대신 활성화 함수에 공급되는 정규 행렬 분해를 사용했습니다.그러나이 접근 방식에는 FM의 선형 부분에 의해 모델링 된 특정 순서 1 상호 작용이 없습니다.또한 저자는 MLP 부분뿐만 아니라 행렬 분해에 대해 모델이 다른 사용자 및 항목 임베딩을 학습 할 수 있도록 특별히 허용했습니다.
앞서 언급했듯이 Google의 연구팀은 하이브리드 추천 접근 방식을위한 신경망을 최초로 제안한 팀 중 하나였습니다.DeepFM은 다음과 같은 Google의 Wide & amp; Deep 알고리즘의 추가 개발이라고 생각할 수 있습니다.
그림 1 : Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, 그리고 Hemal Shah.와이드 & amp;추천 시스템을위한 딥 러닝.Proc.추천 시스템을위한 딥 러닝에 대한 1 차 워크숍, 7-10 페이지, 2016.
오른쪽은 임베딩 레이어가있는 잘 알려진 MLP이지만 왼쪽에는 최종 전체 출력 장치에 직접 공급되는 다른 수동 엔지니어링 입력이 있습니다.내적 연산 형태의 저차 상호 작용은 이러한 수동 엔지니어링 기능에 숨겨져 있으며 저자는 다음과 같이 여러 가지가 될 수 있다고 말합니다.
이것은 (xᵢ이 k 번째 변환의 일부인 경우 지수가 1과 같음) 서로 교차 곱하여 d 피처 (다른 이전 임베딩 포함 또는 제외) 간의 상호 작용을 캡처합니다.
DeepFM이 선험적 인 기능 엔지니어링이 필요하지 않고 하나의 공통 임베딩 레이어를 공유하는 정확히 동일한 입력 데이터에서 저차 및 고차 상호 작용을 학습 할 수 있기 때문에 얼마나 개선되었는지 쉽게 알 수 있습니다.DeepFM은 실제로 핵심 네트워크의 일부로 FM 모델을 가지고있는 반면 Wide & amp; Deep은 실제 신경망의 일부로 내적 계산을 수행하지 않고 기능 엔지니어링 단계에서 미리 수행합니다.
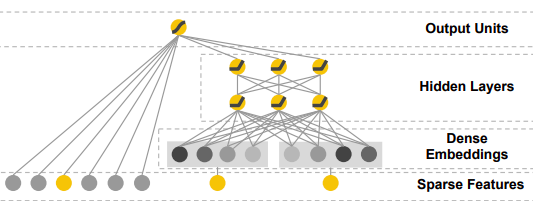
3. DLRM — 딥 러닝 추천 모델
따라서 Google, Huawei (DeepFM 아키텍처 관련 연구팀) 등의 다양한 옵션을 사용하여 Facebook이 사물을 보는 방식을 살펴 보겠습니다.그들은 이러한 모델의 실용적인 측면에 많은 초점을 맞춘 2019 년에 DLRM 논문을 발표했습니다.병렬 교육 설정, GPU 컴퓨팅 및 연속 기능과 범주 기능의 다양한 처리.
DLRM 아키텍처는 아래 그림에 설명되어 있으며 다음과 같이 작동합니다. 범주 형 기능은 각각 임베딩 벡터로 표시되는 반면 연속 기능은 임베딩 벡터와 동일한 길이를 갖도록 MLP에 의해 처리됩니다.이제 두 번째 단계에서는 임베딩 벡터와 처리 된 (MLP 출력) 고밀도 벡터의 모든 조합 사이의 내적이 계산됩니다.그 후, 내적은 조밀 한 특징의 MLP 출력과 연결되고 또 다른 MLP를 통과하여 마지막으로 확률을 제공하는 시그 모이 드 함수로 전달됩니다.
이 DLRM 제안은 임베딩 벡터 간의 내적 계산도 사용한다는 점에서 DeepFM의 단순화되고 수정 된 버전이지만 MLP 계층을 통해 임베딩 된 범주 형 기능을 직접 강제하지 않음으로써 고차 상호 작용에서 벗어나려고합니다..이 설계는 Factorization Machine이 임베딩 간의 2 차 상호 작용을 계산하는 방식을 모방하도록 조정되었습니다.전체 DLRM 설정을 FM 구성 요소 인 DeepFM의 특수한 부분으로 생각할 수 있습니다.DeepFM의 최종 레이어에서 FM 구성 요소의 결과에 추가 된 (그리고 시그 모이 드 함수에 공급되는) DeepFM의 고전적인 Deep Component는 DLRM 설정에서 완전히 생략 된 것으로 볼 수 있습니다.DeepFM의 이론적 이점은 설계 상 고차 상호 작용을 배우기 위해 더 잘 갖추어 졌기 때문에 분명하지만 Facebook에 따르면 다음과 같습니다.
“… 다른 네트워크에서 발견되는 2 차 이상의 고차 상호 작용은 반드시 추가 계산 / 메모리 비용의 가치가 없을 수 있습니다.”
4. 전망과 코딩
다양한 심층 추천 접근 방식, 그들의 직감, 장단점을 이론적으로 소개 한 후 제안 된 내용을 살펴 보았습니다.PyTorch 구현Facebook의 GitHub 페이지에서 DLRM의.
구현의 세부 사항을 확인하고 다양한 원시 데이터 세트를 직접 처리하기 위해 내장 된 사전 정의 된 데이터 세트 API를 사용해 보았습니다.둘 다Kaggle 디스플레이 광고 도전Criteo뿐만 아니라테라 바이트 데이터 세트사전 구현되고 다운로드 할 수 있으며 이후에 단 하나의 bash 명령으로 전체 DLRM을 훈련하는 데 사용할 수 있습니다 (지침은 DLRM repo 참조).그런 다음 Facebook의 DLRM 모델 API를 확장하여 다른 데이터 세트에 대한 전처리 및 데이터로드 단계를 포함합니다.2020 DIGIX 광고 CTR 예측.그것을 확인하시기 바랍니다여기.
digix 데이터를 다운로드하고 압축을 푼 후 비슷한 방식으로 이제 단일 bash 명령으로이 데이터에 대한 모델을 학습 할 수 있습니다.모든 전처리 단계, 임베딩의 모양 및 신경망 아키텍처 매개 변수는 digix 데이터 세트를 처리하도록 조정됩니다.명령을 안내하는 노트북을 찾을 수 있습니다.여기.digix 데이터 뒤에 숨겨진 원시 데이터와 광고 프로세스를 더 잘 이해하여 성능을 향상시키기 위해 계속 노력하고 있기 때문에 모델은 괜찮은 결과를 제공합니다.특정 데이터 정리, 하이퍼 파라미터 튜닝 및 기능 엔지니어링은 모두 제가 추가로 작업하고 싶은 작업이며공책.첫 번째 목표는 원시 digix 데이터를 입력으로 사용할 수있는 DLRM 모델 API의 기술적으로 건전한 확장을 갖는 것이 었습니다.
대체로 하이브리드 딥 모델은 추천 작업을 해결하는 가장 강력한 도구 중 하나라고 생각합니다.그러나 최근에 협업 필터링 문제를 해결하는 데있어 매우 흥미롭고 창의적인 감독되지 않은 접근 방식이 있습니다.오토 인코더.따라서이 시점에서 저는 오늘날 거대 인터넷 거대 기업이 우리가 클릭 할 가능성이 가장 높은 광고를 제공하기 위해 무엇을 사용하고 있는지 추측 할 수 있습니다.앞서 언급 한 오토 인코더 접근 방식과이 기사에 제시된 딥 하이브리드 모델의 일부 형태의 조합이 될 수 있다고 가정합니다.
참고 문헌
스테 펜 렌들.분해 기계.Proc.데이터 마이닝에 관한 2010 IEEE 국제 컨퍼런스, 페이지 995–1000, 2010.
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu 및 Tat-Seng Chua.신경 협업 필터링.Proc.26th Int.Conf.World Wide Web, 페이지 173–182, 2017.
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, Xiuqiang He.DeepFM : CTR 예측을위한 분해 기계 기반 신경망.arXiv 사전 인쇄 arXiv : 1703.04247, 2017.
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie 및 Guangzhong Sun.xDeepFM : 추천 시스템에 대한 명시 적 및 암시 적 기능 상호 작용 결합.Proc.제 24 회 ACM SIGKDD International Conference on Knowledge Discovery & amp;데이터 마이닝, 1754–1763 페이지.ACM, 2018 년.
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu 및 Hemal Shah.와이드 & amp;추천 시스템을위한 딥 러닝.Proc.추천 시스템을위한 딥 러닝에 대한 1 차 워크숍, 7-10 페이지, 2016.
M. Naumov, D. Mudigere, HM Shi, J. Huang, N. Sundaraman, J. Park, X. Wang, U. Gupta, C. Wu, AG Azzolini, D. Dzhulgakov, A. Mallevich, I. Cherniavskii,Y. Lu, R. Krishnamoorthi, A. Yu, V. Kondratenko, S. Pereira, X. Chen, W. Chen, V. Rao, B. Jia, L. Xiong, M. Smelyanskiy,“딥 러닝 추천 모델개인화 및 추천 시스템,”CoRR, vol.abs / 1906.00091, 2019. [온라인].유효한:http://arxiv.org/abs/1906.00091 [39]
이것은 많은 소개가 필요하지 않습니다.수천 개의 기사, 논문이 작성되었으며 베이지안 대 빈도주의에 대한 몇 가지 전쟁이 벌어졌습니다.내 경험상 대부분의 사람들은 일반적인 선형 회귀로 시작하여 더 복잡한 모델을 구축하기 위해 노력하고 소수만이 신성한 Bayes 풀에 발을 담그고 주제의 간결함과 함께 이러한 기회가 부족하여 구멍을 뚫습니다.이해에서 적어도 나에게는 그랬다.
나는되고 싶지 않다너무 많은 수학적 방정식으로 인해 어려움을 겪고 베이지안 통계의 내용, 이유 및 위치를 직관적으로 이해하고자합니다.이것은 저의 겸손한 시도입니다.
베이지안 분석에 대한 직관을 구축해 보겠습니다.나는 한 번 또는 다른 당신이 Frequentism과 Bayesian 사이의 논쟁에 빠졌을 것이라고 믿습니다.통계적 추론의 두 가지 접근 방식의 차이점을 설명 할 수있는 많은 문헌이 있습니다.
요컨대빈도주의변수의 유의성을 측정하기 위해 p- 값을 사용하여 데이터에서 학습하는 일반적인 접근 방식입니다.빈도주의 접근법은 포인트 추정에 관한 것입니다.내 선형 방정식이 다음과 같으면
y는 반응 변수, x₁, x₂는 종속 변수입니다.β₁ 및 β₂는 추정해야하는 계수입니다.β₀은 절편 항입니다.x₁이 1 단위 씩 변하면 y는 β₁ 단위의 영향을받습니다.x₁이 1이고 β₁이 2이면 y는 2 단위의 영향을받습니다.일반적인 선형 물건.여기서 주목해야 할 점은 회귀 방정식이 다양한 β의 값을 추정한다는 것입니다.이 값은 제곱 오차 (최적 적합 선)의 합을 최소화하여 현재 데이터를 가장 잘 설명하며 추정 된 값은 단일 점입니다.β₀에 대한 값, β₁에 대한 값, β₂에 대한 값 등.β의 추정값은최대 가능성 추정입력 값 x와 출력값 y를 고려할 때 가장 가능성이 높은 값이기 때문입니다.
베이지안데이터와는 별도로 데이터에 대한 사전 지식을 고려한다는 점에서 빈도주의 접근 방식과 다릅니다.여기에서 두 그룹 사이에 쇠고기가 놓여 있습니다.빈도 주의자들은 데이터를 복음으로 받아들이는 반면 베이지안 사람들은 우리가 시스템에 대해 항상 알고있는 것이 있고 매개 변수 추정에 그것을 사용하지 않는 이유가 있다고 생각합니다.
사전 지식과 함께 데이터는 사후라고 알려진 것을 추정하기 위해 함께 취해지며 단일 값이 아니라 분포입니다.베이지안 방법은 빈도주의 접근법의 경우와 같이 단일 최상의 값이 아닌 모델 매개 변수의 사후 분포를 추정합니다.
모델 매개 변수에 대해 선택한 사전은 단일 값이 아니지만 분포이기도합니다. 정규, 코시, 이항, 베타 또는 추측에 따라 적합하다고 간주되는 다른 분포 일 수 있습니다.
베이 즈 정리의 토착어와 대본을 알고 계시길 바랍니다.
(베이 즈 정리를 이미 이해하고 있다면이 섹션을 건너 뛰어도됩니다.)
비록 그것은 매우 자명하지만 아주 기본적인 예의 도움으로 설명하겠습니다.
P (A | B)는 B가 이미 발생한 경우 A의 확률을 나타냅니다.예 :52 장의 카드 더미에서 무작위 카드를 가져옵니다.킹 GIVEN이 하트 카드를 뽑았을 확률은 얼마입니까??
A = 카드는 왕, B = 카드는 하트 스위트에서 가져온 것입니다.
P (A = 왕 | B = 하트)
P (A) = P (왕) = 4/52 = 1/13
P (B) = P (하트) = 13/52 = 1/4
P (B | A) = P (하트 | 킹) = 하트 카드를받을 확률 주어진 킹 = 1/4 (52 개 세트에는 4 개의 킹이 있으며 그중 하나의4 왕)
종합하면 P (A | B) = (1/4).(1/13) / (1/4) =1/13, 그래서 13 분의 1의 기회는 그것이 하트라면 왕을 얻을 수 있습니다.
저는이 간단한 예를 선택했습니다. 왜냐하면 베이 즈의 규칙을 풀 때 실제로 필요하지 않기 때문에 초보자도 직관적으로 생각할 수 있습니다.하트 카드라면 왕이 될 확률은 13 점 만점에 1 점입니다.
베이지안 접근 방식에는 사전 정보가 어떻게 포함됩니까?
P (A)는 근사치 또는 데이터가있는 값입니다.위의 예에서 P (A)는 스위트에 관계없이 킹을 얻을 확률입니다.우리는 왕을 얻을 확률이 1/4이라는 것을 알고 있으므로 깨끗한 슬레이트로 시작하는 대신 시스템에 0.25의 값을 제공합니다.
그건 그렇고, Thomas Bayes는 Laplace가 한 위의 방정식을 생각해 내지 못했습니다.Bayes는“기회 교리의 문제 해결에 대한 에세이”그의 생각 실험에.Bayes가 사망 한 후 그의 친구 Richard Price가이 논문을 발견하고 몇 번의 판본을 읽은 후 런던 왕립 학회에서이 논문을 읽었습니다.
베이지안 추론의 경우 :
P (β | y, X)는 데이터 X와 y가 주어지면 모델 매개 변수 β의 사후 분포라고합니다. 여기서 X는 입력이고 y는 출력입니다.
P (y | β, X)는 데이터가 다음과 같이 곱해질 가능성입니다.사전 확률매개 변수의 P (β | X)를 정규화 상수라고하는 P (y | X)로 나눕니다.이 정규화 매개 변수는 P (β | y, X) 값의 합이 1이되도록하는 데 필요합니다.
간단히 말해서, 모델 매개 변수에 대한 이전 정보와 사후를 추정하기 위해 데이터를 사용하고 있습니다.
여기까지왔다면 등을 가볍게 두 드리십시오!:)
출처 : Giphy.com
베이지안의 많은 사상가들은 Enigma의 해결책을 Alan Turing에 기인합니다.네, 그는 실제로 확률 모델을 만들었지 만 폴란드 수학자들이 그를 도왔습니다.전쟁이 있기 오래 전 폴란드의 수학자들은 영국인들이 여전히 언어 학적으로 그것을 풀려고 할 때 수학적 접근법을 사용하여 수수께끼를 풀었습니다.빗발마리안 레유 스키!
Moment of truth through an example
우리의 직관을 구축하기위한 몇 가지 간단한 예를 통해 위에서 배운 것을 이해할 수 있는지 봅시다.
동전을 20 번 던집니다. 1은 앞면, 0은 뒷면입니다.동전 던지기의 결과는 다음과 같습니다.
이 데이터의 평균은 0.75입니다.즉, 꼬리 (0)를 얻는 것보다 앞면 (1)을 얻을 확률이 75 %입니다.
그건 그렇고, 정규적으로 두 개의 결과 0 또는 1 만있는 모든 프로세스를베르누이 프로세스.
빈도 주의적 접근 방식을 취하면 동전이 편향된 것 같습니다.
하지만 대부분의 코인은 편향되지 않으며 1 또는 0을 얻을 확률은 50 % 여야합니다.중앙 극한 정리에 따르면 동전을 무한히 던졌다면 확률은 앞면과 뒷면 모두 0.5가 될 것입니다.실생활은 정리와는 상당히 다르며, 아무도 동전을 무한대로 던지지 않을 것입니다.우리가 사용할 수있는 데이터에 대해 결정을 내려야합니다.
바로 베이지안 접근 방식이 도움이됩니다.그것은 우리에게 사전 (우리의 초기 신념)을 포함 할 수있는 자유를 제공하며 이것이 우리가 동전 던지기 데이터에 할 일입니다.사전에 대한 정보가없는 경우 완전히 정보가없는 균일 분포를 사용할 수 있습니다. 실제로 균일 분포의 결과는 각 가능성이 동일 할 가능성이 있음을 모델에 알리기 때문에 빈도주의 접근 방식과 동일합니다.
Non-Bayesian (Frequentist) = 균일 사전이있는 베이지안
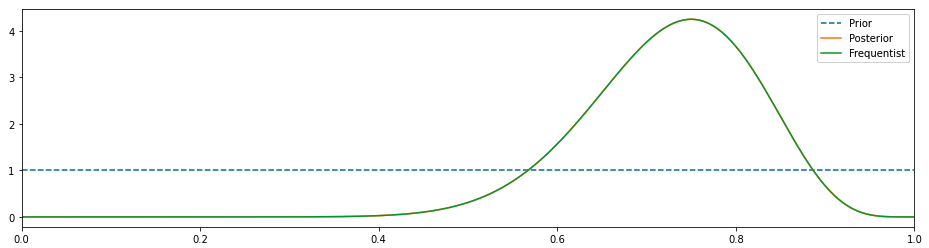
Uninformative prior gives the same results as the frequentist approach(Image by Author)
위의 차트에서 사후 및 빈도주의 결과는 일치하며 약 0.75에서 정점에 이릅니다 (빈도주의 접근 방식과 동일).Prior는 균등 분포를 가정했기 때문에 직선입니다.이 경우 녹색 분포는 실제로 가능성입니다.
나는 우리가 그것보다 더 잘할 수 있다고 믿습니다.더 많은 정보, 아마도 베타 배포판으로 이전을 변경하고 결과를 관찰합시다.
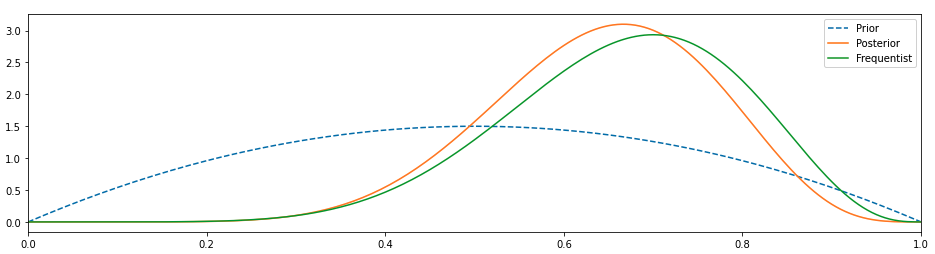
베타 배포판으로 변경되기 전에 빈도 주의자보다 더 잘하고 있음을 알 수 있습니다. (Image by Author)
이것은 더 좋아 보인다.우리의 사전이 변경되었고 사후가 왼쪽으로 이동했기 때문에 0.5 값에 가깝지는 않지만 적어도 0.75에서 빈도 주의자와 일치하지는 않습니다.
우리는 이전 배포판의 몇 가지 매개 변수를 조정하여 더 많은 의견을 제시함으로써 더 개선 할 수 있습니다.
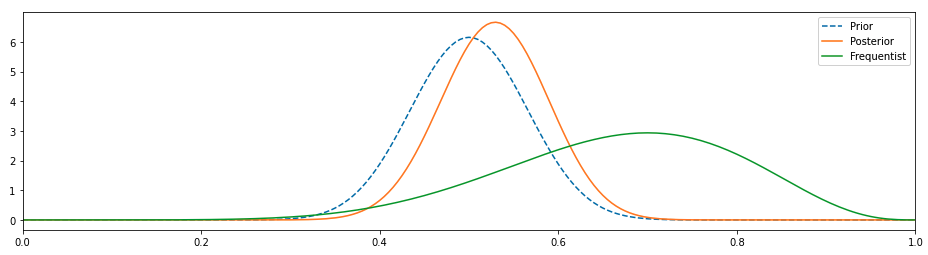
베이지안 접근 방식의 결과가 빈도 주의자에 비해 현실 세계를 모방하도록하는 독단적 사전 (Image by Author)
이것은 훨씬 더 좋아 보이며, 우리가 이전을 변경함에 따라 사후가 바뀌었고, 편향되지 않은 동전이 시간의 50 %를 차지하고 나머지 시간 동안 이야기를 할 것이라는 사실과 훨씬 더 일치합니다.
코인에 대한 우리의 기존 지식은 결과에 큰 영향을 미쳤으며 이는 의미가 있습니다.그것은 우리가 동전에 대해 아는 것이없고이 20 가지 관찰이 복음이라고 가정하는 빈도 주의적 접근과 정반대입니다.
Conclusion
따라서 데이터가 부족함에도 불구하고 베이지안을 통해 모델에 초기 신념을 포함했을 때 거의 올바른 결론에 도달 할 수 있었던 방법을 알 수 있습니다.Bayes의 규칙은 Bayesian 통계의 직관 뒤에 있으며 (이러한 명백한 진술) 빈도주의에 대한 대안을 제공합니다.
베이지안 접근 방식은 사전 정보를 통합하며 데이터가 제한적일 때 견고한 도구가 될 수 있습니다.
2. 접근 방식은 직관적 인 것 같습니다. 솔루션이 무엇인지 추정하고 더 많은 데이터를 수집할수록 해당 추정치를 개선합니다.
베이지안이 모든 데이터 과학 문제를 해결하기위한 최선의 접근 방식이라는 의미는 아닙니다.이는 접근 방식 중 하나 일 뿐이며 이러한 사고 학파 간의 십자군 전쟁에 맞서기보다는 베이지안과 빈도주의 방법을 모두 배우는 것이 유익 할 것입니다.
W큰 힘에는 큰 책임이 따른다.모든 것을 소금 한 알로 가져 가십시오.베이지안 방법의 명백한 이점이 있지만 고도로 편향된 결과를 생성하는 것이 훨씬 쉽습니다.전체 결과를 바꿀 수있는 사전을 선택할 수 있습니다.예를 들어, 제약 업계에서 안전하고 효과적인 약물을 연구하고 개발하는 데 수백만 달러를 투자하는 것보다 먼저 ‘올바른’것을 선택하는 것이 훨씬 쉽고 저렴합니다.수십억 달러에 달하는 경우 약탈적인 저널에 평범한 연구를 게시하고이를 이전 연구로 사용하는 것이 더 쉽습니다.
추가 읽기 :
Johnson, S. (2002).출현 : 개미, 뇌, 도시 및 소프트웨어의 연결된 삶.사이먼과 슈스터.