
심층 강화 학습의 가치 기반 방법
심층 강화 학습은 지난 몇 년 동안 떠오르는 분야였습니다.시작하기에 좋은 접근 방식은 상태 (또는 상태-작업) 값을 학습하는 값 기반 방법입니다.이 게시물에서는 Q-learning 및 확장에 중점을 둔 포괄적 인 리뷰가 제공됩니다.

A Short Introduction to Reinforcement Learning (RL)
일반적인 기계 학습 접근 방식에는 세 가지 유형이 있습니다. 1) 학습 시스템이 레이블이 지정된 예를 기반으로 잠재 맵을 학습하는지도 학습, 2) 학습 시스템이 레이블이없는 예를 기반으로 데이터 배포를위한 모델을 설정하는 비지도 학습, 3) 강화 학습, 여기서의사 결정 시스템은 최적의 결정을 내릴 수 있도록 훈련됩니다.디자이너의 관점에서 모든 종류의 학습은 손실 함수에 의해 감독됩니다.감독의 출처는 인간에 의해 정의되어야합니다.이를 수행하는 한 가지 방법은 손실 함수입니다.
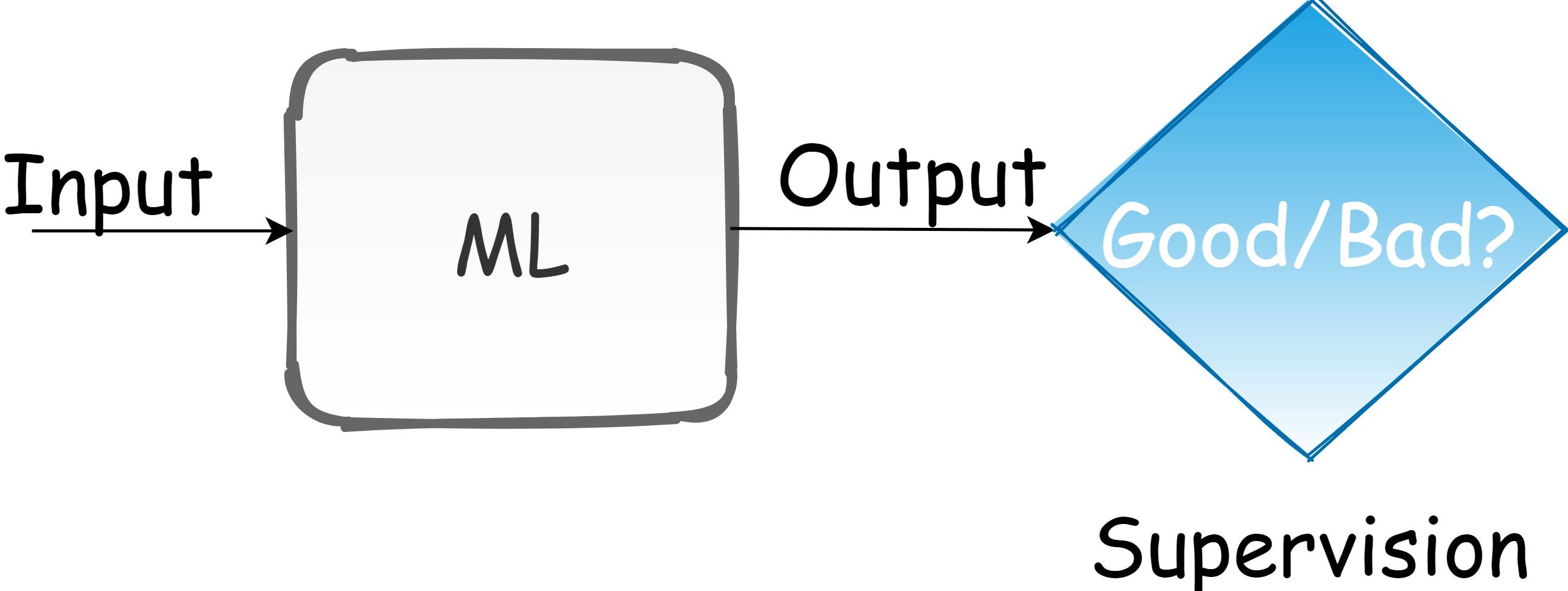
감독 중디학습, 지상 실측 레이블이 제공됩니다.그러나 RL에서는 환경을 탐색하여 에이전트를 가르칩니다.에이전트가 과제를 해결하려는 세상을 디자인해야합니다.이 디자인은 RL과 관련이 있습니다.공식 RL 프레임 워크 정의는 [1]에 의해 제공됩니다.
an에이전트에서 연기환경.모든 시점에서 에이전트는상태환경을 결정하고동작상태를 변경합니다.이러한 각 작업에 대해 에이전트는보상신호.에이전트의 역할은받은 총 보상을 극대화하는 것입니다.
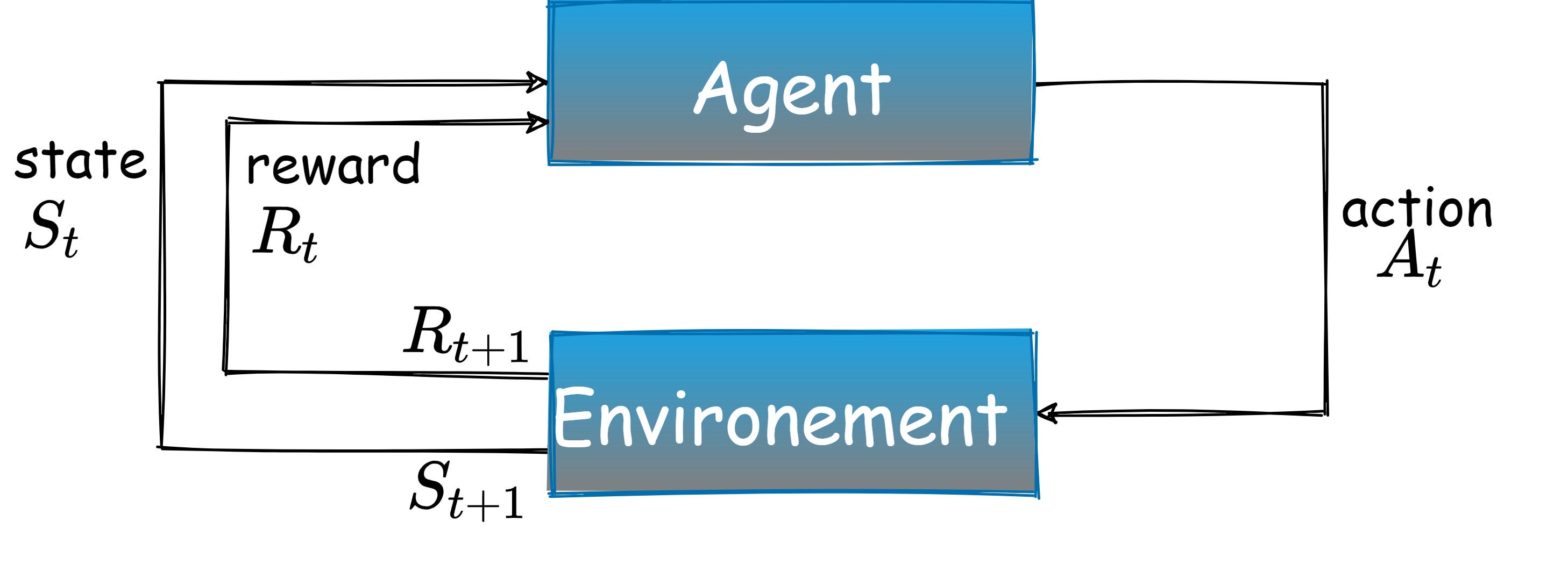
그래서 어떻게 작동합니까?
RL은 시행 착오를 통해 순차적 인 의사 결정 문제를 해결하는 방법을 배우기위한 프레임 워크입니다.가끔 보상을 제공하는 세계의 오류.이것은 어떤 목표를 달성하기 위해 불확실한 환경에서 수행 할 일련의 작업을 경험을 통해 결정하는 작업입니다.행동 심리학에서 영감을받은 강화 학습 (RL)은이 문제에 대한 공식적인 틀을 제안합니다.인공 에이전트는 환경과 상호 작용하여 학습 할 수 있습니다.수집 된 경험을 사용하여 인공 에이전트는 누적 보상을 통해 주어진 일부 목표를 최적화 할 수 있습니다.이 접근법은 원칙적으로 과거 경험에 의존하는 모든 유형의 순차적 의사 결정 문제에 적용됩니다.환경은 확률적일 수 있으며 에이전트는 현재 상태에 대한 일부 정보 만 관찰 할 수 있습니다.
왜 깊이 들어가야합니까?
지난 몇 년 동안 RL은 도전적인 순차적 의사 결정 문제를 성공적으로 해결함으로써 점점 인기를 얻었습니다.이러한 성과 중 일부는 RL과 딥 러닝 기술의 조합 때문입니다.예를 들어 딥 RL 에이전트는 수천 개의 픽셀로 구성된 시각적 지각 입력으로부터 성공적으로 학습 할 수 있습니다 (Mnih et al., 2015/2013).
같이렉스 프리드먼말했다 :
“AI에서 가장 흥미로운 분야 중 하나입니다.그것은 세계를 표현하고 이해하기 위해 심층 신경망의 힘과 능력을 합쳐서 세상을 행동하고 이해하는 능력과 결합하는 것입니다.”
이전에는 기계에 도달 할 수 없었던 광범위한 복잡한 의사 결정 작업을 해결했습니다.Deep RL은 의료, 로봇 공학, 스마트 그리드, 금융 등에서 많은 새로운 애플리케이션을 엽니 다.
RL의 유형
가치 기반: 상태 또는 상태-작업 값을 학습합니다.주에서 가장 좋은 행동을 선택하여 행동하십시오.탐험이 필요합니다.정책 기반: 상태를 행동으로 매핑하는 확률 적 정책 함수를 직접 학습합니다.샘플링 정책에 따라 행동하십시오.모델 기반: 세계의 모델을 배우고 모델을 사용하여 계획합니다.모델을 자주 업데이트하고 다시 계획하십시오.
수학적 배경
이제 우리는 “모델없는”접근 방식에 속하는 가치 기반 방법에 초점을 맞추고,보다 구체적으로 Q- 학습에 속하는 DQN 방법에 대해 논의 할 것입니다.이를 위해 필요한 수학적 배경을 빠르게 검토합니다.
몇 가지 수학적 수량을 정의 해 보겠습니다.
- 기대 수익
RL 에이전트의 목표는 예상 수익을 최적화하는 정책을 찾는 것입니다 (V- 값 함수).
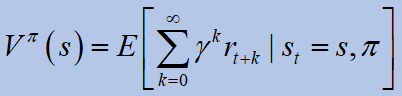
어디이자형 기대 값 연산자, 감마는 할인 계수,파이이다 정책.그만큼최적의 기대 수익다음과 같이 정의됩니다.

최적의 V- 값 함수는 주어진 상태에서 예상되는 할인 된 보상입니다. 에스 에이전트는 정책을 따릅니다. 파이 *그후에.
2.Q 값
관심있는 더 많은 기능이 있습니다.그중 하나는 품질 가치 기능입니다.

V- 기능과 유사하게 최적의큐값은 다음과 같이 지정됩니다.
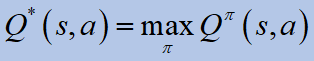
최적큐-value는 주어진 상태에있을 때 그리고 주어진 행동에 대해 예상되는 할인 된 수익입니다.ㅏ, 에이전트는 정책을 따릅니다.파이 *그후에.최적의 정책은이 최적 값에서 직접 얻을 수 있습니다.

삼.장점 기능
마지막 두 기능을 연관시킬 수 있습니다.

행동이 얼마나 좋은지 설명합니다.ㅏ 직접 정책을 따를 때 예상 수익과 비교됩니다.파이.
4.Bellman 방정식
배우려면큐값, Bellman 방정식이 사용됩니다.독특한 솔루션을 약속합니다큐*:

어디비Bellman 연산자입니다.
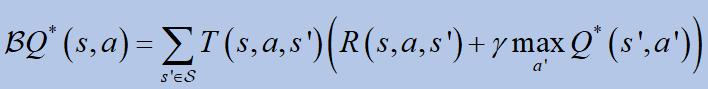
최적의 가치를 약속하기 위해 : 상태-액션 쌍은 개별적으로 표현되고 모든 액션은 모든 상태에서 반복적으로 샘플링됩니다.
Q- 학습
정책을 벗어난 방법의 Q 학습은 주에서 행동을 취하고 학습하는 것의 가치를 배웁니다.큐가치와 세상에서 행동하는 방법을 선택합니다.상태-액션 값 함수를 정의합니다.에스,실행할 수 있는ㅏ, 및 팔로우파이.표 형식으로 표시됩니다.에 따르면큐에이전트는 모든 정책을 사용하여큐미래의 보상을 극대화합니다.큐직접 근사치큐*, 에이전트가 각 상태-작업 쌍을 계속 업데이트 할 때.

딥 러닝이 아닌 접근 방식의 경우이 Q 함수는 표일뿐입니다.

이 표에서 각 요소는 보상 값이며, 훈련 중에 업데이트되어 정상 상태에서 할인 계수로 보상의 예상 값에 도달해야합니다.큐*값.실제 시나리오에서 가치 반복은 비현실적입니다.
에서브레이크 아웃 게임,상태는 화면 픽셀입니다. 이미지 크기 : 84×84, 연속 : 4 개 이미지, 회색 수준 : 256. 따라서큐-테이블은 :

언급하자면, 우주에는 10⁸² 원자가 있습니다.이것이 우리가 다음과 같은 문제를 해결해야하는 좋은 이유입니다.브레이크 아웃 게임심층 강화 학습에서…
DQN : Deep Q-Networks
우리는 신경망을 사용하여큐함수:
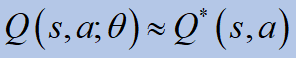
신경망은 함수 근사로 유용합니다.DQN은 Atari 게임에서 사용되었습니다.손실 함수에는 두 가지 Qs 함수가 있습니다.

표적: 특정 상태에서 행동을 취할 때 예상되는 Q 값.예측: 실제로 그 행동을 취할 때 얻는 가치 (다음 단계에서 가치를 계산하고 총 손실을 최소화하는 것을 선택).
매개 변수 업데이트 :
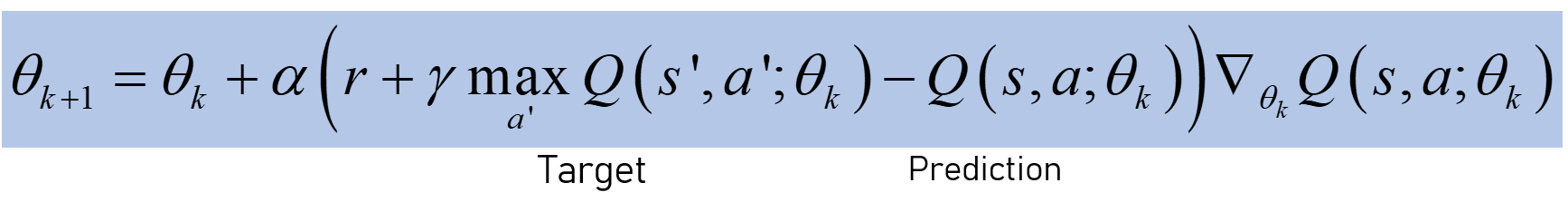
가중치를 업데이트 할 때 대상도 변경됩니다.신경망의 일반화 / 외삽으로 인해 상태-행동 공간에 큰 오류가 발생합니다.따라서 Bellman 방정식은 w.p.1.이 업데이트 규칙으로 오류가 전파 될 수 있습니다 (느림 / 불안정 등).
DQN 알고리즘은 다양한 ATARI 게임에 대한 온라인 설정에서 강력한 성능을 얻을 수 있으며픽셀.불안정성을 제한하는 두 가지 경험적 방법 : 1. 대상의 매개 변수큐-network는 N 반복마다 업데이트됩니다.이렇게하면 불안정성이 빠르게 전파되는 것을 방지하고 분산 위험을 최소화합니다.경험 리플레이 메모리 트릭을 사용할 수 있습니다.

DQN 트릭 : 리플레이와 엡실론 탐욕스러운 경험
리플레이 체험
DQN에서는 CNN 아키텍처가 사용됩니다.비선형 함수를 사용한 Q- 값의 근사값은 안정적이지 않습니다.경험 리플레이 트릭에 따르면 모든 경험은 리플레이 메모리에 저장됩니다.네트워크를 훈련 할 때 가장 최근의 작업 대신 재생 메모리의 임의 샘플이 사용됩니다.즉, 에이전트는 기억 / 저장 경험 (상태 전환, 행동 및 보상)을 수집하고 훈련을위한 미니 배치를 만듭니다.
엡실론 탐욕 탐사
로큐기능 수렴큐*, 실제로 발견 한 첫 번째 효과적인 전략으로 해결됩니다.따라서 탐사는 탐욕 스럽습니다.탐색하는 효과적인 방법은 확률이 “엡실론”이고 그렇지 않은 경우 (1- 엡실론), 탐욕스러운 행동 (가장 높은 Q 값)을 가진 무작위 행동을 선택하는 것입니다.경험은 엡실론 탐욕 정책에 의해 수집됩니다.
DDQN : Double Deep Q-Networks
의 최대 연산자큐-학습은 행동을 선택하고 평가하기 위해 동일한 값을 사용합니다.이는 과대 평가 된 값 (노이즈 또는 부정확 한 경우)을 선택하여 과도하게 낙관적 인 값을 추정하게 만듭니다.DDQN에는 각각 별도의 네트워크가 있습니다.큐.따라서 두 개의 신경망이 있습니다.현재 가중치로 얻은 값에 따라 정책이 여전히 선택되는 편향을 줄이는 데 도움이됩니다.
견인 신경망,큐각 기능 :


이제 손실 함수는 다음과 같이 제공됩니다.
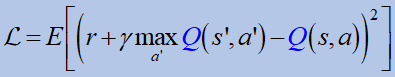
Deep Q-Networks 결투
큐포함이점(ㅏ) 값 (V) 그 상태에 있습니다.ㅏ조치를 취하는 이점으로 일찍 정의ㅏ주에스다른 모든 가능한 작업 및 상태 중에서.당신이 취하고 자하는 모든 행동이“아주 좋은”것이라면, 우리는 그것이 얼마나 더 나은지 알고 싶습니다.
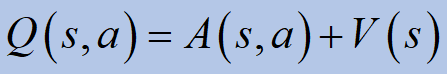
결투 네트워크는 두 개의 개별 추정치를 나타냅니다. 하나는 상태 값 함수를위한 것이고 다른 하나는 상태 의존적 행동 이점 함수를위한 것입니다.코드 예제를 더 읽으려면듀얼 딥 큐 네트워크게시크리스 윤.
요약
우리는 강화 학습에 대한 일반적인 소개와이를 딥 러닝 맥락에 넣을 동기 부여와 함께 가치 기반 방법의 Q- 러닝을 제시했습니다.수학적 배경, DQN, DDQN, 몇 가지 트릭 및 결투 DQN이 탐구되었습니다.
저자 정보
Barak Or는 B.Sc.(2016), M.Sc.(2018) 항공 우주 공학 학위 및 B.A.Technion, Israel Institute of Technology에서 경제 및 경영학 박사 (2016, Cum Laude).그는 Qualcomm (2019–2020)에서 주로 기계 학습 및 신호 처리 알고리즘을 다루었습니다.Barak은 현재 그의 Ph.D.하이파 대학교에서.그의 연구 관심 분야는 센서 융합, 내비게이션, 기계 학습 및 추정 이론입니다.
www.Barakor.com|https://www.linkedin.com/in/barakor/
References
[1] Sutton, Richard S. 및 Andrew G. Barto.강화 학습 : 소개.MIT Press, 2018 년.
[2] 심층 강화 학습을 통한 인간 수준 제어, Volodymyr Mnih et al., 2015. on Nature.
Mosavi, Amirhosein, et al.”심층 강화 학습 방법 및 경제학 적용에 대한 종합적인 검토.”수학8.10 (2020) : 1640.
[4] 베어드, 리몬.”잔류 알고리즘 : 함수 근사를 통한 강화 학습.”기계 학습 절차 1995.Morgan Kaufmann, 1995. 30–37.