
최신 추천 시스템
Facebook 및 Google과 같은 회사가 비즈니스를 구축 한 AI 알고리즘에 대해 자세히 알아보십시오.
최근 2019 년 5 월에 Facebook은 몇 가지 추천 접근 방식을 오픈 소스로 제공하고DLRM(딥 러닝 추천 모델).이 블로그 게시물은 DLRM 및 기타 최신 추천 접근 방식이 도메인의 이전 결과에서 파생 될 수있는 방법을 살펴보고 내부 작동 및 직관을 자세히 설명함으로써 어떻게 그리고 왜 잘 작동하는지 설명하기위한 것입니다.

맞춤형 AI 기반 광고는 요즘 온라인 마케팅에서 게임의 이름은 Facebook, Google, Amazon, Netflix 및 co와 같은 회사가 온라인 마케팅 정글의 왕입니다. 왜냐하면 이러한 추세를 채택했을뿐만 아니라 본질적으로이를 발명하고 전체 비즈니스 전략을 구축했기 때문입니다.그것.넷플릭스의“즐길 수있는 다른 영화”나 아마존의“이 상품을 구매 한 고객도 구매했습니다…”는 온라인 세상에서 많은 예입니다.
자연스럽게, 저는 일상적인 Facebook과 Gooogle 사용자로서 어느 시점에서 스스로에게 물었습니다.
“이게 정확히 어떻게 작동합니까?”
예, 우리 모두는 협업 필터링 / 행렬 분해가 작동하는 방식을 설명하는 기본적인 영화 추천 예제를 알고 있습니다.또한, 사용자가 특정 제품을 좋아하는지 여부에 대한 확률을 출력하는 간단한 분류기를 사용자별로 훈련시키는 접근 방식에 대해 말하는 것이 아닙니다.이 두 가지 접근 방식, 즉 협업 필터링과 콘텐츠 기반 추천은 사용할 수있는 성능과 예측을 산출해야하지만 Google, Facebook 및 Co는 확실히 더 나은 것을 가져야합니다. 그렇지 않으면 어디에 있지 않을 것입니다.그들은 오늘입니다.
오늘날의 고급 추천 시스템의 출처를 이해하려면 문제에 대한 두 가지 기본 접근 방식을 살펴보아야합니다.
특정 사용자가 특정 항목을 얼마나 좋아하는지 예측합니다.
온라인 마케팅 세계에서는 평점, 좋아요 등과 같은 명시적인 피드백과 클릭, 검색 기록, 댓글 또는 같은 암시 적 피드백을 기반으로 가능한 광고의 클릭률 (CTR)을 예측하는 데 추가됩니다.웹 사이트 방문.
콘텐츠 기반 필터링과협업필터링
1. 콘텐츠 기반 필터링
느슨하게 말한 콘텐츠 기반 추천은 사용자의 온라인 기록을 사용하여 사용자가 특정 제품을 좋아하는지 여부를 예측하는 것을 의미합니다.여기에는 사용자가 제공 한 좋아요 (예 : Facebook), 검색 한 키워드 (예 : Google), 단순히 특정 웹 사이트를 클릭하고 방문한 횟수가 포함됩니다.대체로 사용자의 선호도에 초점을 맞 춥니 다.예를 들어이 사용자의 특정 광고 그룹에 대한 클릭률 (또는 등급)을 출력하는 간단한 이진 분류기 (또는 회귀 자)를 생각할 수 있습니다.
2. 협업 필터링
그러나 협업 필터링은 유사한 사용자의 선호도를 조사하여 사용자가 특정 제품을 좋아할지 여부를 예측하려고합니다.여기에서 등급 매트릭스가 사용자와 영화에 대한 하나의 임베딩 매트릭스로 분해되는 영화 추천에 대한 표준 매트릭스 분해 (MF) 접근 방식을 생각할 수 있습니다.
클래식 MF의 단점은 예를 들어 어떤 부가 기능도 사용할 수 없다는 것입니다.영화 장르, 개봉일 등 MF 자체는 기존의 상호 작용을 통해 배워야합니다.또한 MF는 아직 누구에게도 평가되지 않은 신작은 추천 할 수없는 이른바 ‘콜드 스타트 문제’에 시달리고있다.콘텐츠 기반 필터링은 이러한 두 가지 문제를 해결하지만 유사한 사용자의 선호도를 볼 수있는 예측 능력이 부족합니다.
두 가지 다른 접근 방식의 장점과 단점은 두 아이디어가 어떻게 든 하나의 모델로 결합되는 하이브리드 접근 방식의 필요성을 매우 분명하게 나타냅니다.
하이브리드 추천 모델
1. 분해 기계
2010 년 Steffen Rendle이 소개 한 아이디어 중 하나는분해 기계.행렬 분해와 회귀를 결합하는 기본적인 수학적 접근 방식을 보유합니다.
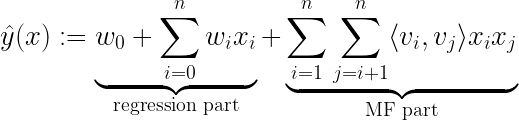
학습 중에 추정해야하는 모델 매개 변수는 다음과 같습니다.
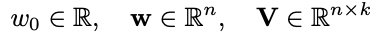
⟨∙, ∙⟩은 V에서 행으로 볼 수있는 ℝᵏ 크기의 vᵢ와 vⱼ 두 벡터 사이의 내적입니다.
이 모델에 던져지는 데이터 x를 표현하는 방법의 예를 볼 때이 방정식이 어떻게 의미가 있는지 보는 것은 매우 간단합니다.Steffen Rendle의 Factorization Machines에 대한 백서에 설명 된 예제를 살펴 보겠습니다.
사용자가 특정 시간에 영화에 등급을 부여하는 영화 리뷰에 다음과 같은 거래 데이터가 있다고 상상해보십시오.
- user u ∈ U = {Alice (A), Bob (B), . . .}
- movie (item) i ∈ I = {Titanic (TI), Notting Hill (NH), Star Wars (SW), Star Trek (ST), . . .}
- rating r ∈ {1,2,3,4,5} at time t ∈ ℝ

위의 그림을 보면 하이브리드 추천 모델에 대한 데이터 설정을 볼 수 있습니다.사용자와 항목을 나타내는 희소 특성과 추가 메타 또는 부가 정보 (예 :이 예에서 “시간”또는 “최근 영화 등급”)는 모두 대상 y에 매핑되는 특성 벡터 x의 일부입니다.이제 핵심은 모델에 의해 처리되는 방법입니다.
- FM의 회귀 부분은 표준 회귀 작업과 같이 희소 데이터 (예 : “사용자”)와 고밀도 데이터 (예 : “시간”)를 모두 처리하므로 FM 내에서 콘텐츠 기반 필터링 접근 방식으로 해석 될 수 있습니다.
- FM의 MF 부분은 이제 기능 블록 간의 상호 작용 (예 : “사용자”와 “영화”간의 상호 작용)을 설명합니다. 여기서 행렬 V는 협업 필터링 접근 방식에 사용되는 임베딩 행렬로 해석 될 수 있습니다.이러한 교차 사용자 영화 관계는 다음과 같은 통찰력을 제공합니다.
vⱼ를 포함하는 다른 사용자 j와 유사한 임베딩 vᵢ (영화 속성에 대한 선호도를 나타냄)를 가진 사용자 i는 사용자 j와 유사한 영화를 매우 좋아할 수 있습니다.
회귀 부분과 MF 부분에 대한 두 가지 예측을 함께 추가하고 하나의 비용 함수에서 매개 변수를 동시에 학습하면 이제 사용자를위한 권장 사항을 만들기 위해 “양쪽 세계의 최고”접근 방식을 사용하는 하이브리드 FM 모델이 생성됩니다.
언뜻보기에 Factorization Machine의이 하이브리드 접근 방식은 이미 NLP 또는 컴퓨터 비전과 같은 많은 다른 AI 분야가 과거에 입증 되었 듯이 완벽한 “양쪽 세계의 최고”모델 인 것처럼 보입니다.
“신경망에 던져 넣으면 더 나아질 것입니다.”
2. 넓고 깊은 NCF (Neural Collaborative Filtering) 및 DeepFM (Deep Factorization Machine)
먼저 NCF 논문을 살펴봄으로써 신경망 접근 방식으로 협업 필터링을 어떻게 해결할 수 있는지 살펴볼 것입니다. 이는 분해 기계의 신경망 버전 인 Deep Factorization Machines (DeepFM)로 이어질 것입니다.왜 그들이 일반 FM보다 우월하고 신경망 아키텍처를 해석 할 수 있는지 알아볼 것입니다.추천 시스템에서 딥 러닝의 첫 번째 주요 혁신 중 하나 인 Google에서 이전에 출시 한 Wide & amp; Deep 모델을 개선하여 DeepFM이 어떻게 개발되었는지 살펴 보겠습니다.이것은 마침내 우리를 DeepFM에 대한 단순화 및 약간의 조정으로 볼 수있는 2019 년 Facebook에서 발표 한 앞서 언급 한 DLRM 문서로 이어질 것입니다.
NCF
2017 년에 연구원 그룹은작업신경 협업 필터링에 대해.여기에는 신경망을 사용한 협업 필터링에서 행렬 분해에 의해 모델링 된 기능적 관계를 학습하기위한 일반화 된 프레임 워크가 포함되어 있습니다.저자는 또한 고차 상호 작용을 달성하는 방법 (MF는 차수 2에 불과 함)과 두 접근 방식을 결합하는 방법을 설명했습니다.
일반적인 아이디어는 신경망이 (이론적으로) 모든 기능적 관계를 배울 수 있다는 것입니다.즉, 협업 필터링 모델이 표현하는 MF와의 관계도 신경망으로 학습 할 수 있습니다.NCF는 기본적으로 신경망을 통해 두 임베딩 간의 MF 내적 관계를 학습하기 위해 사용자와 항목 (표준 MF와 유사) 모두에 대한 간단한 임베딩 계층을 제안한 다음 간단한 다층 퍼셉트론 신경망이 뒤 따릅니다.
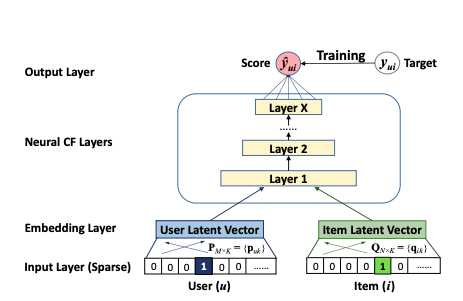
이 접근 방식의 장점은 MLP의 비선형성에 있습니다.MF에서 사용되는 간단한 내적은 항상 2 차 학습 상호 작용으로 모델을 제한하는 반면, X 레이어가있는 신경망은 이론적으로 훨씬 더 높은 수준의 상호 작용을 학습 할 수 있습니다.예를 들어 남성, 십대 및 RPG 컴퓨터 게임과 같이 상호 작용이있는 세 가지 범주 적 기능을 생각해보십시오.
실제 문제에서 우리는 임베딩에 대한 원시 입력으로 사용자 및 항목 이진화 된 벡터를 사용하는 것이 아니라 가치있을 수있는 다양한 기타 메타 또는 부가 정보 (예 : 연령, 국가, 오디오 / 텍스트 녹음, 타임 스탬프)를 분명히 포함합니다.,…) 그래서 실제로 우리는 매우 고차원적이고 매우 희소하며 연속적인 카테고리 혼합 데이터 세트를 가지고 있습니다.이 시점에서, 위에서 제시된 그림 2의 신경망은 단순한 이진 분류 피드-포워드 신경망의 형태로 콘텐츠 기반 추천으로 해석 될 수 있습니다.그리고이 해석은 CF와 콘텐츠 기반 추천 간의 하이브리드 접근 방식이되는 방식을 이해하는 데 중요합니다.네트워크는 실제로 모든 기능적 관계를 학습 할 수 있으므로 CF 차원의 3 차 이상의 상호 작용 (예 :x₁ ∙ x₂ ∙ x₃ 또는 σ (… σ (w₁x₁ + w₂x₂ + w₃x₃ + b)) 형식의 고전적인 신경망 분류 의미의 비선형 변환을 여기서 배울 수 있습니다.
고차 상호 작용을 학습하는 힘을 갖추고 있으므로 신경망을 저차 학습으로 잘 알려진 모델과 결합하여 모델이 차수 1과 2의 저차 상호 작용도 쉽게 학습 할 수 있도록 만들 수 있습니다.상호 작용, Factorization Machine.이것이 DeepFM의 저자가 논문에서 제안한 내용입니다.고차 및 저차 기능 상호 작용을 동시에 학습하기위한이 조합 아이디어는 많은 최신 추천 시스템의 핵심 부분이며 업계에서 제안 된 거의 모든 네트워크 아키텍처에서 어떤 형태로든 찾을 수 있습니다.
DeepFM
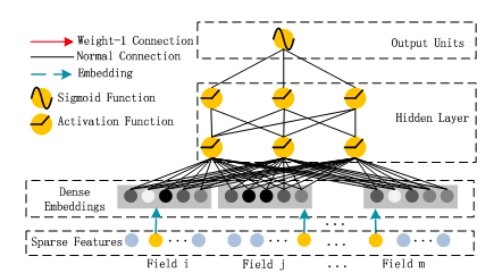
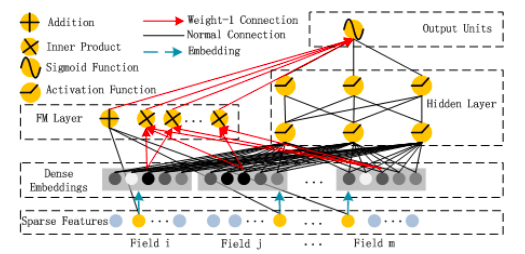
DeepFM은 FM과 심층 신경망 간의 혼합 접근 방식으로, 둘 다 동일한 입력 임베딩 레이어를 공유합니다.원시 기능은 연속 필드가 자체적으로 표현되고 범주 형 필드가 원-핫 인코딩되도록 변환됩니다.NN의 마지막 레이어에서 제공하는 최종 (예 : CTR) 예측은 다음과 같이 정의됩니다.
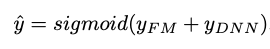
이것은 두 네트워크 구성 요소 인 FM 구성 요소와 Deep 구성 요소의 시그 모이 드 활성화 합계입니다.
그만큼FM 성분신경망 아키텍처 스타일로 꾸민 일반 Factorization Machine입니다.

FM 레이어의 덧셈 부분은 원시 입력 벡터 x를 직접 가져 와서 (Sparse Features Layer) 각 요소에 가중치를 곱한 다음 ( “Normal Connection”) 합산합니다.FM 레이어의 Inner Product 부분도 원시 입력 x를 가져 오지만, 임베딩 레이어를 통과 한 후에 만 임베딩 벡터 사이에 가중치 (“Weight-1 Connection”)없이 내적을 취합니다.다른 “Weight-1 연결”을 통해 두 부분을 함께 추가하면 앞서 언급 한 FM 방정식이 생성됩니다.
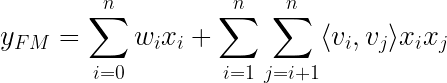
이 방정식에서 xᵢxⱼ 곱셈은 i = 1에서 n까지의 합을 쓸 수있을 때만 필요합니다.실제로 신경망 계산의 일부가 아닙니다.네트워크는 임베딩 레이어 아키텍처로 인해 내적을 취하기 위해 어떤 임베딩 벡터 vᵢ, vⱼ를 자동으로 인식합니다.
이 임베딩 레이어 아키텍처는 다음과 같습니다.
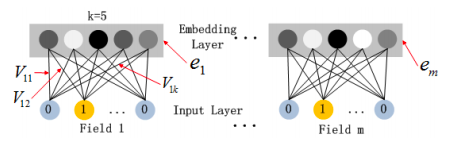
Vᵖ는 k 개의 열이있는 각 필드 p = {1,…, m}에 대한 임베딩 행렬이지만 필드의 이진화 된 버전에는 요소가 있습니다.따라서 임베딩 레이어의 출력은 다음과 같이 제공됩니다.
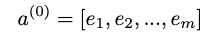
이것은 완전히 연결된 레이어가 아닙니다. 즉, 필드의 원시 입력과 다른 필드의 임베딩간에 연결이 없다는 점에 유의해야합니다.이렇게 생각해보십시오. 성별에 대한 원-핫 인코딩 벡터 (예 : (0,1))는 평일의 임베딩 벡터와 관련이 없습니다 (예 : (0,1,0,0,0,0,0))원시 이진화 된 평일 “화요일”이며 예를 들어 k = 4; (12,4,5,9))와 함께 벡터를 임베딩합니다.
Factorization Machine 인 FM 구성 요소는 차수 1 및 차수 2 상호 작용의 높은 중요성을 반영하며, 이는 Deep 구성 요소 출력에 직접 추가되고 최종 레이어의 시그 모이 드 활성화에 공급됩니다.
그만큼깊은 구성 요소이론상 모든 심층 신경망 아키텍처로 제안됩니다.저자는 특히 일반적인 피드 포워드 MLP 신경망 (소위 PNN)을 살펴 보았습니다.일반 MLP는 다음 그림에 나와 있습니다.
원시 데이터 (원-핫 인코딩 된 범주 입력으로 인해 매우 희소)와 다음과 같은 신경망 계층 사이에 임베딩 계층이있는 표준 MLP 네트워크 :
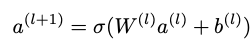
σ는 활성화 함수, W는 가중치 행렬, a는 이전 계층의 활성화, b는 편향입니다.
이를 통해 전반적인 DeepFM 네트워크 아키텍처가 생성됩니다.
매개 변수와 함께 :
- 특성 i와 다른 특성 (임베딩 레이어) 간의 상호 작용의 영향을 측정하기위한 잠재 벡터 Vᵢ
- Vᵢ은 FM 구성 요소로 전달되어 주문 2 상호 작용 (FM 구성 요소)을 모델링합니다.
- 원시 특성 i (FM 구성 요소)의 순서 1 중요성에 가중치 부여
- Vᵢ는 또한 모든 고차 상호 작용을 모델링하기 위해 Deep 구성 요소로 전달됩니다 (& gt; 2) (Deep 구성 요소).
- Wˡ 및 bˡ, 신경망 가중치 및 편향 (Deep Component)
고차 및 저차 상호 작용을 동시에 얻는 열쇠는 특히 FM과 Deep 구성 요소 모두에 대해 동일한 임베딩 레이어를 사용하여 하나의 비용 함수로 모든 매개 변수를 동시에 훈련하는 것입니다.
Wide & amp; Deep 및 NeuMF와 비교
이 아키텍처를 잠재적으로 더 좋게 만드는 방법에 대해 상상할 수있는 많은 변형이 있습니다.그러나 핵심은 고차 및 저차 상호 작용을 동시에 모델링하는 방법에 대한 하이브리드 접근 방식에서 모두 유사합니다.DeepFM의 저자는 또한 MLP 부분을 내장 계층과 결합 된 초기 입력으로 FM 계층을 가져 오는 심층 신경망 인 소위 PNN과 교환 할 것을 제안했습니다.
NCF 논문의 저자는 또한 NeuMF ( “Neural Matrix Factorization”)라고하는 유사한 아키텍처를 내놓았습니다.FM을 하위 구성 요소로 사용하는 대신 활성화 함수에 공급되는 정규 행렬 분해를 사용했습니다.그러나이 접근 방식에는 FM의 선형 부분에 의해 모델링 된 특정 순서 1 상호 작용이 없습니다.또한 저자는 MLP 부분뿐만 아니라 행렬 분해에 대해 모델이 다른 사용자 및 항목 임베딩을 학습 할 수 있도록 특별히 허용했습니다.
앞서 언급했듯이 Google의 연구팀은 하이브리드 추천 접근 방식을위한 신경망을 최초로 제안한 팀 중 하나였습니다.DeepFM은 다음과 같은 Google의 Wide & amp; Deep 알고리즘의 추가 개발이라고 생각할 수 있습니다.
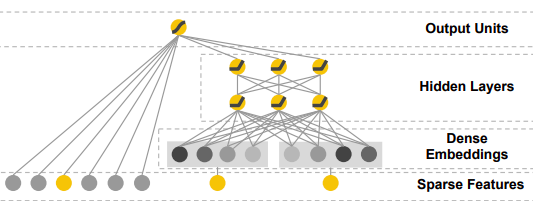
오른쪽은 임베딩 레이어가있는 잘 알려진 MLP이지만 왼쪽에는 최종 전체 출력 장치에 직접 공급되는 다른 수동 엔지니어링 입력이 있습니다.내적 연산 형태의 저차 상호 작용은 이러한 수동 엔지니어링 기능에 숨겨져 있으며 저자는 다음과 같이 여러 가지가 될 수 있다고 말합니다.
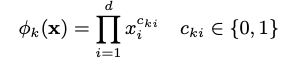
이것은 (xᵢ이 k 번째 변환의 일부인 경우 지수가 1과 같음) 서로 교차 곱하여 d 피처 (다른 이전 임베딩 포함 또는 제외) 간의 상호 작용을 캡처합니다.
DeepFM이 선험적 인 기능 엔지니어링이 필요하지 않고 하나의 공통 임베딩 레이어를 공유하는 정확히 동일한 입력 데이터에서 저차 및 고차 상호 작용을 학습 할 수 있기 때문에 얼마나 개선되었는지 쉽게 알 수 있습니다.DeepFM은 실제로 핵심 네트워크의 일부로 FM 모델을 가지고있는 반면 Wide & amp; Deep은 실제 신경망의 일부로 내적 계산을 수행하지 않고 기능 엔지니어링 단계에서 미리 수행합니다.
3. DLRM — 딥 러닝 추천 모델
따라서 Google, Huawei (DeepFM 아키텍처 관련 연구팀) 등의 다양한 옵션을 사용하여 Facebook이 사물을 보는 방식을 살펴 보겠습니다.그들은 이러한 모델의 실용적인 측면에 많은 초점을 맞춘 2019 년에 DLRM 논문을 발표했습니다.병렬 교육 설정, GPU 컴퓨팅 및 연속 기능과 범주 기능의 다양한 처리.
DLRM 아키텍처는 아래 그림에 설명되어 있으며 다음과 같이 작동합니다. 범주 형 기능은 각각 임베딩 벡터로 표시되는 반면 연속 기능은 임베딩 벡터와 동일한 길이를 갖도록 MLP에 의해 처리됩니다.이제 두 번째 단계에서는 임베딩 벡터와 처리 된 (MLP 출력) 고밀도 벡터의 모든 조합 사이의 내적이 계산됩니다.그 후, 내적은 조밀 한 특징의 MLP 출력과 연결되고 또 다른 MLP를 통과하여 마지막으로 확률을 제공하는 시그 모이 드 함수로 전달됩니다.

이 DLRM 제안은 임베딩 벡터 간의 내적 계산도 사용한다는 점에서 DeepFM의 단순화되고 수정 된 버전이지만 MLP 계층을 통해 임베딩 된 범주 형 기능을 직접 강제하지 않음으로써 고차 상호 작용에서 벗어나려고합니다..이 설계는 Factorization Machine이 임베딩 간의 2 차 상호 작용을 계산하는 방식을 모방하도록 조정되었습니다.전체 DLRM 설정을 FM 구성 요소 인 DeepFM의 특수한 부분으로 생각할 수 있습니다.DeepFM의 최종 레이어에서 FM 구성 요소의 결과에 추가 된 (그리고 시그 모이 드 함수에 공급되는) DeepFM의 고전적인 Deep Component는 DLRM 설정에서 완전히 생략 된 것으로 볼 수 있습니다.DeepFM의 이론적 이점은 설계 상 고차 상호 작용을 배우기 위해 더 잘 갖추어 졌기 때문에 분명하지만 Facebook에 따르면 다음과 같습니다.
“… 다른 네트워크에서 발견되는 2 차 이상의 고차 상호 작용은 반드시 추가 계산 / 메모리 비용의 가치가 없을 수 있습니다.”
4. 전망과 코딩
다양한 심층 추천 접근 방식, 그들의 직감, 장단점을 이론적으로 소개 한 후 제안 된 내용을 살펴 보았습니다.PyTorch 구현Facebook의 GitHub 페이지에서 DLRM의.
구현의 세부 사항을 확인하고 다양한 원시 데이터 세트를 직접 처리하기 위해 내장 된 사전 정의 된 데이터 세트 API를 사용해 보았습니다.둘 다Kaggle 디스플레이 광고 도전Criteo뿐만 아니라테라 바이트 데이터 세트사전 구현되고 다운로드 할 수 있으며 이후에 단 하나의 bash 명령으로 전체 DLRM을 훈련하는 데 사용할 수 있습니다 (지침은 DLRM repo 참조).그런 다음 Facebook의 DLRM 모델 API를 확장하여 다른 데이터 세트에 대한 전처리 및 데이터로드 단계를 포함합니다.2020 DIGIX 광고 CTR 예측.그것을 확인하시기 바랍니다여기.
digix 데이터를 다운로드하고 압축을 푼 후 비슷한 방식으로 이제 단일 bash 명령으로이 데이터에 대한 모델을 학습 할 수 있습니다.모든 전처리 단계, 임베딩의 모양 및 신경망 아키텍처 매개 변수는 digix 데이터 세트를 처리하도록 조정됩니다.명령을 안내하는 노트북을 찾을 수 있습니다.여기.digix 데이터 뒤에 숨겨진 원시 데이터와 광고 프로세스를 더 잘 이해하여 성능을 향상시키기 위해 계속 노력하고 있기 때문에 모델은 괜찮은 결과를 제공합니다.특정 데이터 정리, 하이퍼 파라미터 튜닝 및 기능 엔지니어링은 모두 제가 추가로 작업하고 싶은 작업이며공책.첫 번째 목표는 원시 digix 데이터를 입력으로 사용할 수있는 DLRM 모델 API의 기술적으로 건전한 확장을 갖는 것이 었습니다.
대체로 하이브리드 딥 모델은 추천 작업을 해결하는 가장 강력한 도구 중 하나라고 생각합니다.그러나 최근에 협업 필터링 문제를 해결하는 데있어 매우 흥미롭고 창의적인 감독되지 않은 접근 방식이 있습니다.오토 인코더.따라서이 시점에서 저는 오늘날 거대 인터넷 거대 기업이 우리가 클릭 할 가능성이 가장 높은 광고를 제공하기 위해 무엇을 사용하고 있는지 추측 할 수 있습니다.앞서 언급 한 오토 인코더 접근 방식과이 기사에 제시된 딥 하이브리드 모델의 일부 형태의 조합이 될 수 있다고 가정합니다.
참고 문헌
스테 펜 렌들.분해 기계.Proc.데이터 마이닝에 관한 2010 IEEE 국제 컨퍼런스, 페이지 995–1000, 2010.
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu 및 Tat-Seng Chua.신경 협업 필터링.Proc.26th Int.Conf.World Wide Web, 페이지 173–182, 2017.
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, Xiuqiang He.DeepFM : CTR 예측을위한 분해 기계 기반 신경망.arXiv 사전 인쇄 arXiv : 1703.04247, 2017.
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie 및 Guangzhong Sun.xDeepFM : 추천 시스템에 대한 명시 적 및 암시 적 기능 상호 작용 결합.Proc.제 24 회 ACM SIGKDD International Conference on Knowledge Discovery & amp;데이터 마이닝, 1754–1763 페이지.ACM, 2018 년.
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu 및 Hemal Shah.와이드 & amp;추천 시스템을위한 딥 러닝.Proc.추천 시스템을위한 딥 러닝에 대한 1 차 워크숍, 7-10 페이지, 2016.
M. Naumov, D. Mudigere, HM Shi, J. Huang, N. Sundaraman, J. Park, X. Wang, U. Gupta, C. Wu, AG Azzolini, D. Dzhulgakov, A. Mallevich, I. Cherniavskii,Y. Lu, R. Krishnamoorthi, A. Yu, V. Kondratenko, S. Pereira, X. Chen, W. Chen, V. Rao, B. Jia, L. Xiong, M. Smelyanskiy,“딥 러닝 추천 모델개인화 및 추천 시스템,”CoRR, vol.abs / 1906.00091, 2019. [온라인].유효한:http://arxiv.org/abs/1906.00091 [39]