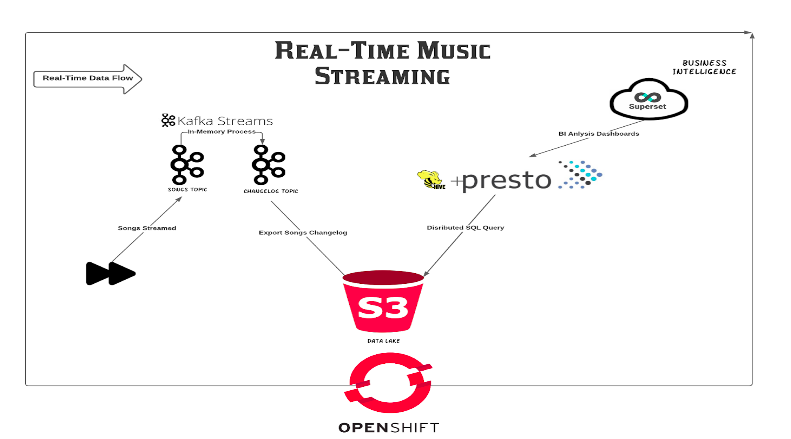
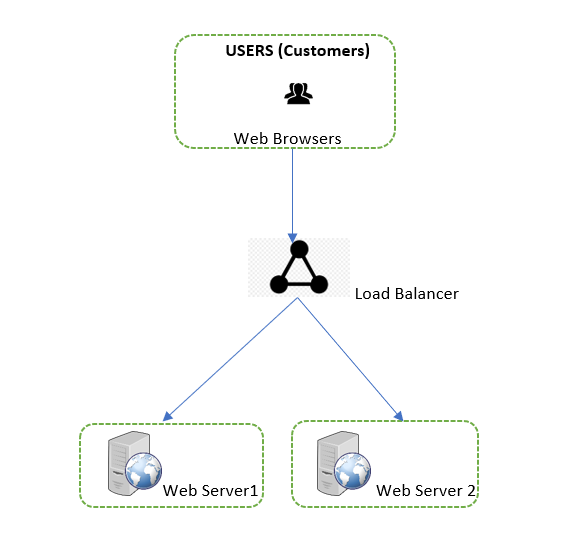
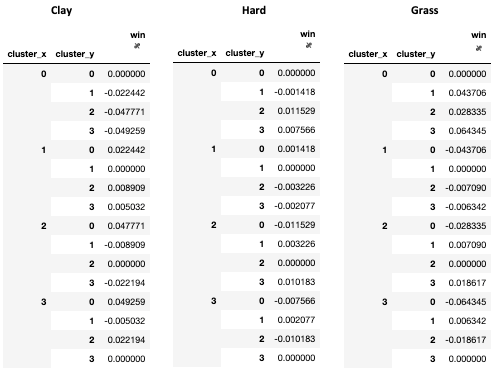
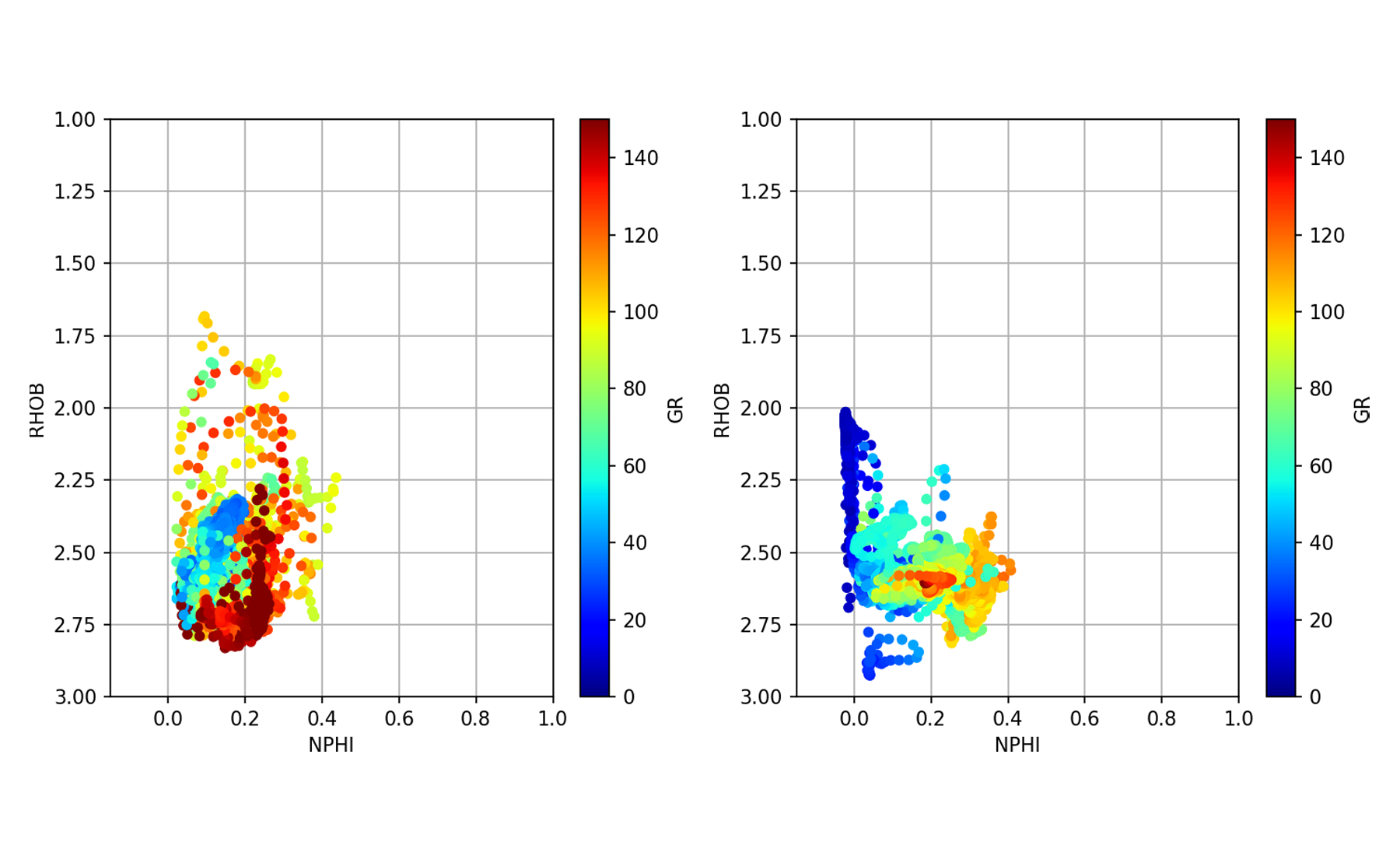
성적 증명서 아래에서 찾으십시오.
Jeremie (00:00:00) :
안녕하세요, 제레미입니다.Towards Data Science 팟 캐스트에 다시 오신 것을 환영합니다.오늘은 AI와 관련된 장기적이고 개량 된 외모, 반 미래 지향적 인 주제를 많이 다루게 될 것이기 때문에 오늘 에피소드가 정말 기대됩니다.그리고 AI 기술이 거버넌스의 미래를 형성하는 방식입니다.인간이 경제적으로 무의미 해 질까요?우리의 일상적인 결정 중 얼마나 많은 것이 기계에 오프로드 될 것입니까?그리고 아마도 가장 중요한 것은, 매우 유능하고 매우 일반적인 AI 시스템의 출현이 민주주의와 거버넌스 자체의 미래에 무엇을 의미할까요?이러한 질문은 어떤 종류의 확실하게 대답 할 수 없지만, 인간 기술 발전의 역사를 오랫동안 바라 보면 힌트를 얻을 수 있습니다.
Jeremie (00:00:41) :
이것이 바로 제 게스트 인 Ben Garfinkel이 AI의 미래에 대한 연구에 적용한 전략입니다.현재 Ben은 Oxford의 Future of Humanity Institute에서 AI를 포함한 첨단 기술의 위험을 예측하는 여러 분야의 연구원입니다.Ben은 또한 AI 위험에 대한 몇 가지 고전적인 주장을 탐구하는 데 많은 시간을 보냈습니다.이 중 상당수는 팟 캐스트에서 접하게 될 것입니다.우리는 많은 손님들이 그들에 대해 자세히 토론하고 탐구했고 그가 동의하지 않는 많은 사람들을 가졌습니다.그리고 우리는 그의 의견 불일치, 그가 가진 이유, 그리고 AI 위험에 대한 논쟁이 약간 불안정하다고 생각하는 부분을 조사 할 것입니다.대화를 정말 즐겼습니다.당신도 그러길 바랍니다.벤, 팟 캐스트에 함께 해주셔서 감사합니다.
Ben (00:01:19) :
네.저를 초대해 주셔서 감사합니다.
Jeremie (00:01:21) :
당신이 여기에있어 정말 기쁩니다.당신의 초점은 인공 지능과 관련된 많은 장기적인 문제들에 있습니다.하지만 그 고기와 감자에 대해 자세히 알아보기 전에이 공간에 오게 된 이유를 더 잘 이해하고 싶습니다.그렇다면 당신의 배경은 무엇이며 AI에서 장기주의를 어떻게 발견 했습니까?
Ben (00:01:38) :
예, 사실 꽤 원형 인 것 같아요.그래서 대학에서 물리학과 철학을 공부했고 실제로 물리학 철학에 관심이 많았고 대학원에가는 것도 고려하고 있었는데 다행스럽게도 그렇게하지 않았습니다.그리고 저는 철학을 통해 윤리에 대해 더 많이 배우기 시작했고 인구 윤리에 대한 특정 아이디어를 접했습니다.우리가 내리는 결정에서 미래 세대를 어떻게 소중히 여기고 미래 세대에 대한 우리의 의무가 무엇인지에 대해 다른 질문이 있다는 생각.또는 다른 사람들에게 적어도 어느 정도 유용 할 수있는 일을하는 것이 얼마나 강력한 지.그리고이를 통해 장기주의에 점점 더 관심을 갖게되었고 유용 해 보이는 것을 알아 내려고 노력했습니다.그리고 저는 아마도 철학과 물리학이 그렇지 않다고 생각하게되었습니다.
Ben (00:02:28) :
그리고 저는 실제로 이번 무렵뿐만 아니라 장기 주의적이거나 미래적인 주제에 대해 더 자세히 살펴 보려고 노력하면서 우연히 예일대에 있던 교수 인 Allan Dafoe를 만났습니다.그는 그저 AI 거버넌스 문제를 해결하기 위해 노력하고있었습니다.그리고 제가 아직 선배 였을 때 그가 연구 조교를 부른 것 같아요.이 주제에 관심이 있었고 AI 위험에 대해 조금 읽었습니다.예를 들어 Superintelligence라는 책을 읽기 시작했는데 그 분야에 실제로 관여하지는 않았지만 중요한 문제가있는 것 같았습니다.기회가 생겨서 Allan과 함께 일하기 시작했습니다.그리고 몇 년이 지난 지금도 저는 여전히 Allan과 함께 일하고 있으며, 신기술의 위험에 대해 작업하는 것이 장기적인 관점에서 적어도 꽤 좋은 일이라는 것을 상당히 확신하게되었습니다.
Jeremie (00:03:14) :
그리고 이것은 실제로 아름다운 segue입니다. 제가 정말로 이야기하고 싶었던 주요 주제 중 하나라고 생각합니다.그리고 그것은 당신이 AI의 실존 적 위험과 그에 대한 주장에 대해 많은 시간을 보냈다는 생각입니다.그중 많은 부분이 실제로 완전히 팔리지 않았다는 것을 알고 있습니다.여기서 시작할 수 있습니다. 특히 사람들, 특히 앨런과 당신이 AI에 대해 걱정하는 실존 적 위험의 본질은 무엇입니까?그런 다음 우리는 그러한 주장에 대한 반론도 할 수 있습니다.하지만 우선, 그 위험은 무엇입니까?
Ben (00:03:44) :
예, 그래서 저는 AI의 장기적인 영향에 대해 생각하는 사람들의 커뮤니티에서 적어도 정말로 우세한 단일 위험이 있다고 생각하지 않습니다.그래서 저는 몇 가지 주요, 매우 광범위하고 다소 모호한 범주가 있다고 말하고 싶습니다.따라서 매우 빠르게 위험의 한 종류는 불안정성으로 인한 위험입니다.따라서 많은 사람들, 특히 국제 안보 영역에서 예를 들어 치명적인 자율 무기 시스템에 대해 걱정하고 있습니다. 어쩌면 국가 간 갈등의 위험이 증가 할 수도 있습니다.우발적, 플래시 충돌 또는 잠재적으로 AI의 특정 응용 프로그램 일 수 있습니다. 2 차 공격 능력을 이동하고 핵전쟁의 위험을 증가 시킨다고 가정 해 보겠습니다.또는 그들은 큰 권력 경쟁에 대해 걱정합니다.그리고 그들이 가지고있는 주요 관심 벡터는 인공 지능이 국내 적으로나 국제적으로 정치를 불안정하게 만들 것이고, 그 후 지속적인 피해를 입힐 전쟁이있을 수도 있고 다른 부정적이고 긴 갈등이있을 수도 있다는 것입니다.
Ben (00:04:43) :
거기에 덜 초점을 맞춘 또 다른 종류의 우려가 있습니다. 특정한 갈등이나 붕괴 또는 전쟁이라고합시다.그리고 AI가 사회를 재편성하는 방식에 일정 수준의 우발성이있을 수 있다는 생각에 더 집중합니다.따라서 정부와 AI가 미래 세대에 영향을 미치고 계속해서 영향을 미칠지에 대해 사람들이 내리는 특정 결정을 생각할 수 있습니다.그리고 사실, 예를 들어, 민주주의가 얼마나 널리 퍼져 있는지, 권력의 분배가 무엇인지, 또는 사람들이 관심을 갖는 다양한 다른 것들, 예를 들어 나쁜 가치가 어떤 의미에서 확고히 자리 잡는 것과 같은 것들이 있습니다.
Jeremie (00:05:23) :
왜냐하면 그 쪽은 아주, 분명히 복잡한 영역이라고 생각합니다.하지만 사람들이 AI가 미래에 민주주의가 유치 할 수있는 거버넌스 모드라고 말할 수있는 범위를 바꾸는 것을 상상하는 방식은 무엇일까요?
Ben (00:05:36) :
그래서 민주주의에 관해서는 분명히 이것에 대한 약간의 추측적인 우위가 있습니다. 그러나 민주주의에 대해 걱정하는 것에 대한 한 가지 주장은 민주주의가 정말로 정상적이지 않다는 것입니다. 역사의 광범위하고 포괄적 인 관점을 살펴보면, 최초의 문명으로 돌아가는 것은 드문 일이 아닙니다. 매우 매주 민주적 인 요소가 있다고합시다. 그래서 그것은 완전한 독재 정치가 아닙니다. 예를 들어 로마 상원 의원 같은 어떤 종류의기구가 있습니다.하지만 로마의 경우 잘 알려진 것입니다. 그러나 그것은 우리가 지금 가지고있는 것과는 매우 거리가 멉니 다. 이는 매우 반응이 빠른 정부와 더 많은 것을위한 일관된 이적을 가진 많은 국가에서 거의 보편적 인 참정권과 같습니다. 이것은 역사적 관점에서 매우 드뭅니다. 그리고 상황이 완전히 독재 화되지 않았거나 이전에 다가 왔더라도 지난 100 년 동안은 매우 다른 일입니다. 그리고이 현대적인 형태의 민주주의가 왜 더 보편화되었는지에 대한 다양한 이론이 있습니다. RCT를 실행하기가 어렵 기 때문에 이에 대해 많은 논쟁이 있습니다. 그러나 많은 사람들은 산업 혁명을 중심으로 발생하는 적어도 특정한 경제적 변화가 적절하다고 지적합니다.
Ben (00:06:43) :
그래서 사람들이 때때로 제기하는 변화의 한 종류는 Androform입니다. 산업 혁명 이전에는 정말 심각한 문제였습니다.몇 가지 우려 사항은 많은 일반 사람들에게 정부의 권력을 주거나 부유 한 행위자들의 부의 주요 형태 인 토지를 재분배하는 [들리지 않음 00:06:56]을 활용한다면보다 광범위하게 파괴적이어야한다는 것입니다..그리고 그것은 국가들이 산업화되고 토지가 부의 형태로서 덜 관련성이있게되면서 이러한 농지 개혁 문제가 방해 요소가되지 않게되었을 것입니다.당신은 더 이상이 땅 귀족이 아니었고, 이처럼 무뚝뚝한 정책 공포를 가졌습니다.
Ben (00:07:18) :
그리고 또 다른 우려는 노동의 가치가 생산적 증가와 마찬가지로 증가했다는 것입니다.그리고 이것은 사람들에게 모호한 의미에서 더 많은 협상력을주었습니다. 왜냐하면 당신은 그들이 한 일과 더 많은 가치를 가진 전형적인 노동자를 가지고 있기 때문입니다.그리고 그들은 기본적으로 노동력을 제거하겠다고 위협함으로써 더 큰 위협을 만들 수 있습니다.또는 조직도 관련성이 있다고 생각했습니다. 도시에 사람들이 꽉 차면 조직하기가 더 쉽고 실제로 성공적인 혁명을 일으킬 수 있습니다.그리고 사람들이 기본적으로 경제 변화라고 지적하는 다양한 요인이있어 민주주의가 그 길을 따라가는 데 도움이되거나 오늘날 왜 더 널리 퍼져 있는지 적어도 부분적으로 설명하는 데 도움이 될 수 있습니다.
Ben (00:07:52) :
따라서 여러분이 상당히 광범위하게 가질 수있는 한 가지 우려는 민주주의의 보급이 어떤 식 으로든 특정 물질적 또는 경제적 요인에 달려 있는지 여부입니다.그렇다면 그것은 지난 몇 100 년 동안 만 유지되었습니다.이것은 정상이 아닐 수도 있습니다. 경제 및 기술 변수를 많이 변경하면 유지되지 않을 수도 있습니다.여기에 좀 더 구체적인 주장이 있습니다.그래서 한 가지 매우 구체적인 주장은 단지 인간 노동의 가치가 매우 낮아지면 대부분의 경우에는 0이된다는 것입니다. 왜냐하면 노동 대신 자본을 대체 할 수 있기 때문입니다.AI 시스템은 사람들이 할 수있는 모든 것을 할 수 있기 때문에, 아마도 우리가 노동자의 힘을 줄일 때, 당신이 법 집행을 자동화 할 수 있거나 군사 기술도 자동화 될 수 있기 때문에 봉기를 억제 할 수 있다면.
Ben (00:08:33) :
아마도 그것은 권위주의 정부를 더 안정되게 만들 것입니다.봉기에 대한 두려움 때문에 양보조차하지 않는다는 뜻입니다.노동의 가치가 0이되면 그 시점에서 누가 자본을 소유하는지 또는 누가 기계를 기본적으로 소유하는지에 따라 크게 달라질 수 있습니다.그리고 그것은 농지 개혁에 대한 사소한 우려와 매우 유사한 상황 인 시스템을 만들 수도 있습니다.부가 이러한 더 모호한 것들에 기반하지 않은 곳에서 사람들의 노동을 나누고 실제로 역할을하지 않았습니다. 그것은 주로 여러분이 소유하고있는 것이 기본적으로 임대료를 징수하는 것입니다.그 체제로 돌아 오면 민주주의의 안정에도 좋지 않을 수 있습니다.
Ben (00:09:09) :
그래서 외부 관점이 있습니다. 이것은 단지 드문 일입니다.우리는 그것이 지속될 것으로 기 대해서는 안되며 많이 바뀝니다.그리고 권위주의 정부를 더 안정되게 만들고 사람들이 [들리지 않음 00:09:24]에 권력을주는 것에 대해 더 걱정하게 만드는 내부 관점의 주장이 더 있습니다.
Jeremie (00:09:24) :
이러한 모든 문제가 얼마나 얽혀 있는지 그리고 이러한 모든 변화가 일어날 때 미래가 어떻게 보일지에 대한 일관된 비전을 표현하는 것이 얼마나 어려운지 정말 흥미 롭습니다.민주주의에서 일어날 일, 경제에서 일어날 일에 대해 이야기하기 시작할 때 저에게 계속 떠오르는 것 중 하나입니다.그리고 협상하는 노동의 힘은 우리가 모든 종류의 시장 구조를 가지고 있다는 기본 가정입니다.
Jeremie (00:09:57) :
그 중 하나는 제가 가질 수있는 거의 어리석은 질문은 그 맥락에서 돈의 가치가 무엇일까요?가격 발견의 가치는 무엇입니까?그러한 맥락에서 가격 발견은 어떻게 발생합니까?그리고 재분배가 의미하는 바는 … 우리가 반드시 희소성 이후 상황에있는 것이 아니라 희소성의 변화를 기대할 수 있습니다.하지만 어쨌든, 제가 여기서 말하고자하는 것이 무엇인지 확신 할 수 없습니다.하지만 당신이 거기에 던져 넣을 것이있는 것 같습니다.
Ben (00:10:23) :
그래서 저는 이것이 정말 심각한 문제라고 생각합니다. 나는 우리가 실제로 어떤 수준의 세부 사항에서도 매우 진보 된 AI로 미래를 상상할 수 있고 실제로 옳을 것이라고 기 대해서는 안된다고 생각합니다. 그래서 제가 가끔 사용한 비유는 AI 시스템이 최소한 사람들이 할 수있는 모든 일을 할 수있는 세상의 특정 측면이 있다고 생각한다는 것입니다. 우리는 추상적으로 어느 정도 추론 할 수 있습니다. 우리는 이러한 경제 모델을 가지고 있고, 우리는 노동을 가지고 있고 여러분은 자본을 가지고 있습니다. 그리고 여러분은 노동 대신 자본을 대체 할 수 있다면 어떤 일이 일어나는지 물어볼 수 있습니다. 그리고 프로젝트조차도 매우 추상적 인 관점입니다. 그리고 우리가 세부 사항을 알지 못하더라도 이러한 이론이 충분히 추상적이기를 바라는 이유가있을 수 있습니다. 우리가 미래에 대해 추론하기 위해 여전히 사용할 수있는 충분한 일반 초록이 있다고 생각할 이유가 있습니다. 하지만 정부가 일하는 방식을 구체적으로 설명하는 것과 같은 우려가 있습니다. 우리는 아마도 정부의 기능이 아주 잘못되었다고 상상할 것입니다.
Ben (00:11:19) :
그래서 제가 가끔 사용한 비유 중 하나는 당신이 1500이라고 말하고 누군가가 당신에게 인터넷을 매우 추상적 인 용어로 설명한다고 가정 해 봅시다. 마치 의사 소통이 훨씬 빨라질 것입니다.정보를 검색하고 학습하는 것이 훨씬 빠릅니다.그리고 그것은 당신에게 그것의 추상적 인 속성의 일부를 제공합니다.추론 할 수있는 몇 가지 사항이 있습니다.
Ben (00:11:40) :
예를 들어,“오, 사람들이 해외에 있고 연락이없는 것과는 달리 사람들과 더 빨리 소통 할 수 있기 때문에 자율성이 떨어질 수 있습니다.또는 이러한 조정 비용이 줄어들 것이기 때문에 비즈니스가 더 커질 수 있습니다. “그에 대해 말할 수있는 내용이 실제로 사실 일 수도 있고 “아마 사람들이 원격으로 일할 수도 있습니다.”라고 말할 수 있는데 세부 사항에 대해 많이 알지 못할 수도 있습니다.하지만 무슨 일이 일어나고 있는지 정말 구체적으로 알아 보려고한다면 아마도 완전히 완전히 틀렸다고 상상할 것입니다.컴퓨터가 실제로 어떤 것인지, 사람들이 컴퓨터와 상호 작용하는 방식에 대해 잘 모르기 때문입니다.
Ben (00:12:15) :
Reddit 및 GameStop 주식이라는 수준의 세부 정보를 얻지 못할 것입니다.이러한 모든 문제가 있으며, 세부 수준에서 예측할 수있는 가능성은 없습니다.그리고 어떻게 든 잘 맞지 않는 추상화를 사용하고 있기 때문에 실제로 적용되지 않을 것이라고 상상할 수있는 많은 문제가 있습니다.그래서 이것은 다소 긴 바람의 말입니다. 저는 우리가 충분히 추상적 인 추론의 이론과 방법을 가지고 있다고 생각하며 적어도 조금은 유지하기를 기대합니다.하지만 우리가 예측할 수없는 것들이 많이 있다고 생각합니다.우리가 정말로 말할 수없는 많은 문제.그리고 오늘 우리가 말하는 많은 것들은 아마도 미래의 관점에서 어리석게 될 것입니다.
Jeremie (00:12:51) :
예,“이번에는 다를 것입니다.”라는 말은 언제나 위험한 말이라고 생각합니다.그러나 AI 혁명의 다음 단계에 관해서는 그렇게 부르고 싶다면.나는 그것이 당신이 사용하는 경향이있는 언어라는 것을 알고 있으며,이 경우에 적절한 것 같습니다.제가 궁금해하는 것 중 하나는 시장과 같은 것을 정의하기 위해 우리가 의존하는 추상화가있는 추상화 유출과 거의 비슷합니다.이것은 우리가 미래를 예측하는 것에 대해 이야기 할 때 우리 추론의 가장 기본적인 요소 중 하나입니다.궁극적으로 가격은 개별 인간이 물건에 대해 기꺼이 지불하는 것이기 때문에 시장은 암묵적으로 사람을 중심으로 회전합니다.시장 참여자가 될 수있는 것에 대한 우리의 정의를 넓히는 범위까지.
Jeremie (00:13:38) :
그리고 여기서 우리는 AI 에이전트를 어떻게 고려할까요?어느 시점에서 사회 참여 구성원입니까?그리고 어떤 시점에서 가격 발견이 실제로 인간이 아닌 시스템과 같은 것들의 요구와 욕구를 중심으로 진행됩니까?이것이 제가 궁금해하기 시작하는 곳이라고 생각합니다. 이것은 기본적으로 비 구조적 관점입니다.그래서“시장은 잘못된 추상화”라고 말하는 것은 도움이되지 않지만 그게 심각하다고 생각하는 문제입니까?
Ben (00:14:06) :
예, 그렇습니다. 저는 확실히 문제가 있다고 생각합니다. 당신이 좋은 구체적인 문제를 지적했다고 생각합니다. 우리는 이렇게 확고한 차이가 있습니다. 사람들은 현재 기계와 소프트웨어와는 매우 다릅니다.그것은 경제 행위자들과 경제에 관한 것들과 매우 비슷합니다 [들리지 않음 00:14:23].그리고 어떤면에서는 사람과 비슷한 [들리지 않음 00:14:29] 어떤 목적으로 기업이 어느 정도 흐릿 해집니다.그러나 그 구별은 상당히 강력합니다.자본과 노동 사이에서도 현재로서는 모호하지 않습니다.
Ben (00:14:41) :
그러나 매우 광범위하고 부드러운 AI 시스템이 미래에 존재할 것이라고 생각한다면.우리는 사람들이 자신의 가치를 추구하기위한 평가를 생성하는 AI 시스템과 흥미로운 관계를 가질 수 있다고 생각합니다.우리가 그리는 많은 구별이 실제로 오늘날보다 훨씬 더 모호해질 수 있다고 생각합니다.그리고 그것들이 미래에 모호 해지는 방식은 우리가하는 어떤 이유 든 정말 뚜렷한 구별에 의존하는 이유가 현재 예측하기 어려운 방식으로 실패하게 만들 수 있습니다.
Jeremie (00:15:12) :
네.정말 예측할 수없고 근본적으로 도전 적이기 때문에 예측하는 것은 흥미로운 위험입니다.그것은 거기에서도 문제 중 하나 인 것 같습니다. 그리고 여러분은 실제로 기술의 역사에 대한 여러분의 작업에서 이것을 탐구합니다.이 기술의 진화에 대한 이야기를 전달하기 위해 어떤 측정 항목을 살펴볼 것인지입니다.그것에 대해 조금 말씀해 주시겠습니까, 귀하의 역사적 전망 및 흥미 롭다고 생각하는 지표는 무엇이며 미래에 관련성이 있거나 관련이없는 이유는 무엇입니까?
Ben (00:15:36) :
네.그래서 저는 사람들이 매우 자주 접근하는 하나의 측정 항목이 글로벌 세계 제품 또는 GDP라고 생각합니다.GDP는 측정 기준으로 흥미 롭습니다. 측정하려는 것은 기본적으로 어느 정도 생산 능력 (예 : 얼마나 많은 물건을 생산할 수 있는지 또는 사람들이 가치있는 물건을 생산할 수있는 물건)과 같은 어느 정도의 생산 능력이기 때문입니다.과-
Jeremie (00:16:01) :
어리석은 질문이 있습니다.그렇다면 GDP는 무엇입니까?GDP의 실제 정의는 무엇입니까?
Ben (00:16:08) :
따라서 최소한 명목 GDP에서는 경제 내에서 판매되는 모든 최종 제품의 총 가격을 합산합니다.따라서 최종 제품은 기본적으로 최종 결과와 같은 것입니다.누군가 나사를 팔면 나사를 사용하여 천장 선풍기 같은 것을 만드는 사람에게 나사를 판매합니다.나사는 두 번 계산하기 때문에 계산되지 않습니다.누군가가 천장 형 선풍기를 구입하고 천장 형 선풍기를 구입할 때 나사를 구입하면 나사도 구입하는 것입니다.따라서 기본적으로 중간 제품을 제외한 경제 내에서 구매하거나 판매하는 모든 제품의 기본 판매 가격을 합산하는 것입니다.
Ben (00:16:48) :
그러나 사람들은 종종 명목 GDP와 다른 실질 GDP에 대해 이야기하고 싶어합니다.따라서 명목 GDP는 기본적으로 모든 가격을 더합니다.명목 GDP의 한 가지 문제는 인플레이션이 발생하면 실제 기초 주식과 관련이없는 이유로 명목 GDP가 증가 할 수 있다는 것입니다.그래서 정부는 더 많은 돈을 인쇄하기로 결정합니다. 갑자기 모든 가격이 1,000 배씩 올라가지 만 여러분은 여전히 똑같은 것을 가지고 있습니다.명목상의 의미에서 GDP 성장률이 극도로 빠르다고 느끼지는 않지만 실제로 더 많은 것을 생산하고 있다는 것을 알려주지는 않습니다.
Jeremie (00:17:25) :
네.베네수엘라는 잘하고 있습니다.
Ben (00:17:27) :
예 바로 그 거예요. 실질 GDP는이를 조정하기위한 것입니다. 그리고 적어도 그것이 작동하는 방식을 대략적으로 말하면 과거에 특정 시점에 존재했던 가격과 관련된 모든 것을 정의하려고 노력하는 것입니다. 경제가 존재한다고 가정 해 봅시다. 판매되는 유일한 제품은 버터이고 버터 가격은 인플레이션으로 인해 어떤 이유로 인해 1,000 배 상승합니다. 그러나 경제에서 판매하는 버터의 양은 두 배에 불과합니다. 실질 GDP는“오, 당신이 판매 한 버터의 양이 2 배 증가했기 때문입니다. 경제 규모는 2 배만 증가했습니다.” 그리고 경제의 규모는 과거의 버터 가격에 오늘날 존재하는 단위 수를 곱한 것으로 정의됩니다. 이것이 실질 GDP입니다. 사람들이 시간이 지남에 따라 새로운 제품을 계속 소개하기 때문에 매우 복잡해집니다. 그렇다면 사람들이 2020 년에 구매하는 대부분의 물건이 1700 년에 존재하지 않았다는 점을 감안할 때 2020 년 경제의 실질 GDP를 1700 년대 경제와 어떻게 비교합니까? 실제로 어떻게 비교합니까? 사람들이 사용하는 다양한 방법이 있지만 제대로 이해하지 못합니다.
Ben (00:18:36) :
하지만 그 질문을하면서 GDP의 주요 문제 중 하나에 도달했습니다.그것은 우리가 기본적으로 얼마나 많은 것을 만드는가와 같은 사회의 생산 능력을 추적하기위한 것입니다.단기간에 실질 GDP를 사용하는 경우 일반적으로 그렇게 많은 신제품을 도입하지 않기 때문에 상당히 문제가 없어 보입니다.그러나 오랜 시간이지나면서 이러한 비교가 실제로 어떻게 작동하는지 모호해집니다.그래서 매우 무딘 비교는 여전히 꽤 괜찮습니다.따라서 BC 10,000 년과 현재의 1 인당 GDP처럼 말할 수 있습니다.다른 100 개 사회의 1 인당 GDP를 정확히 어떻게 정의해야할지 몰라도 여전히 낮다고 확신합니다.
Ben (00:19:21) :
그래서 어떤 의미에서는 무뚝뚝한 도구와 같습니다. 그 유용성은 실제로 토론이나 예측을 얼마나 정확하게하고 싶은지에 달려 있다고 생각합니다.따라서 누군가가 자동화로 인해 1 인당 GDP 성장률이 10 배 증가 할 것이라는 매우 대담한 예측을한다고 가정 해 보겠습니다.누군가 그렇게 대담한 예측을한다면, 어떤 미친 미래 경제에서 실질 GDP가 의미하는 바가 약간 모호합니다.하지만 조금 애매하게 보아도 GDP의 차이 인 성장률은 변하지 않았고 10 배 증가한 성장률은 여전히 충분히 무딘 것입니다.주장을 표현하는 유용한 방법입니다.
Ben (00:19:57) :
그래서 그것은 긴 바람의 말입니다. 제 생각에 GDP 또는 1 인당 GDP는 생산 능력이 얼마나 빨리 증가하는지에 대한 대리 물로서 꽤 좋은 경우가 많습니다.산업 혁명과 같은 일에 유용합니다. 1 인당 GDP로 명확하게 나타납니다.또는 미개발 국가가 발전하지 않는 것처럼 국가가 정말로 정체 된 것처럼 보일 때 1 인당 GDP는 일반적으로 꽤 평평합니다.예를 들어, 중국이 정말 명백한 질적 의미로 도약하기 시작했을 때 1 인당 GDP는 그것을 꽤 잘 추적했습니다.그래서 유용하지만 다양한 문제가 있습니다.그리고 그 밖의 문제도 있습니다. 종종 사람들은 1 인당 GDP와 같은 사람들의 삶이 얼마나 좋은지에 대한 대리 물로 사용하기를 원합니다.
Ben (00:20:38) :
하지만 일반적으로 고려되지 않는 다양한 것들이 있습니다. 의료의 질은 직접적으로 고려되지 않고 대기 오염도 고려되지 않습니다.모든 사람이 매우 우울하거나 마취를했다면 개발중인 마취의 가치는 실제로 나타나지 않습니다.조명의 품질 향상, 전구가 양초보다 훨씬 낫다는 사실을 보여주는 William Nordhaus의 고전적인 논문이 있습니다. 100 년 이상 전에는 실제로 나타나지 않습니다.따라서 최소한 조잡한 척도로서 동일한 재정적 문제를 말하는 장황한 방식입니다. 꽤 좋습니다.하지만 웰빙 및 기타 관심있는 일에 도움이 될 수있는 것만 큼 실제로 상관 관계가있는 것은 아닙니다.
Jeremie (00:21:15) :
마지막 작품에 태그를 달았을 때 웰빙과 잘 관련되지 않는다는 것이 흥미 롭습니다.정렬 문제에 대한 더 나은 캡슐화를 생각할 수 없습니다.기본적으로 측정 항목을 만드는 문제는 여기에 우리가 원하는 것입니다.인간은 정말 나쁘거나 우리가 나쁘다는 것이 아닙니다.말이되는 메트릭을 지정하는 것은 정말 어려운 문제 일 수 있습니다.그리고 당신은 주식 시장이 무엇인지 보시고, 우리는이 하나의 메트릭에 고정하기로 결정했습니다.그리고 한동안 주식 시장은 일반적으로 경제가 어떻습니까? 일반인은 어떻습니까?그러나 그 다음에는 분리가 일어나고 우리는 일반인의 삶에 비해 매우 다른 주식 시장으로 끝납니다.어쨌든 죄송합니다.맞대 겠다는 뜻은 아니었지만 당신은
벤 (00:22:00) :
네.그래서 저는 약간의주의를 기울여야합니다. 현재로서는 GDP가 실제로 측정 기준으로 꽤 좋다고 생각합니다.기대 수명이나 삶의 만족도와 같이 관심있는 것을 자주 정의하는 경우.실제로 현재는 매우 강력한 상관 관계가 있습니다.그리고 저는 여러분이 아무것도 몰랐다고 생각합니다. [들리지 않음 00:22:17] 뒤쳐져 있거나 살 국가를 선택해야합니다. 그리고 여러분이 얻는 유일한 것은 당 GDP입니다.capita.이것은 종종 유용한 정보가 될 것입니다.내 생각은 정렬 문제와 더 일치한다고 생각합니다. 앞으로 더 분리 되어도 놀라지 않을 것입니다.
Ben (00:22:30) :
특히 우리가 결국 노동을 자본과 기계로 완전히 대체했고 사람들이 더 이상 임금을 위해 일하지 않는다고 가정 해 보겠습니다.그리고 경제 성장은 대부분 다른 기계를 만드는 기계이고 작업자는 실제로 관여하지 않습니다.경제가 10 배 증가해도 사람의 생명은 10 배 증가하지 않는다고해서 놀라지 않을 것입니다.
Jeremie (00:22:47) :
네.그것도 흥미롭고 무엇에 대한 의문을 불러 일으키는데, 이것은 GDP의 큰 측면 인 가격 발견으로 돌아갑니다.상황이 복잡 해지는 영역이 너무 많습니다.하지만 흥미로운 것은이 역사적인 기술 탐구에 대해 여러분이 모은 작업 중 일부를 보는 것입니다.이러한 메트릭의 대부분은 실제로 상관 관계가 있습니다.어느 정도는 측정하는 것이 중요하지 않습니다. 지난 2000 년 또는 지난 20,000 년 동안 극적인 일이 일어났습니다.그러나 문화 혁명, 신석기 혁명, 산업 혁명 중 하나를 측정하고 싶습니다.그리고 그것은 마치 인간의 초 유기체, 지구상의 모든 인간은 일종의 최적 또는 국소 최적 또는 그 무엇이든에 매겨진 최적화 알고리즘과 같습니다.그리고 우리는 이제 그 기울기를 정말 가파르게 오르고 있습니다.
Jeremie (00:23:44) :
AI가 그것의 연속적인 한계라고 생각하십니까?그것은 자연스러운 다음 단계와 같습니까?아니면 우리는 그것을 단계 함수와 같은 양자 도약으로 생각해야합니까?
Ben (00:23:56) :
네.정말 좋은 질문이라고 생각합니다.그리고 저는 이것이 경제 성장의 역사나 증가 된 사회적 역량을 정확히 해석하는 방법에 대한 논쟁이라고 생각합니다.또는 어떤 종류의 모호한 용어를 사용하여 사람들이 물건을 만들거나 물건을 바꾸거나 세상에서 물건을 처리하는 능력을 설명 할 때 사용하고 싶은 용어입니다.예를 들어 산업 혁명에 대한 다양한 해석 사이에 실제로 존재하는 논쟁이 있습니다.따라서 영국과 일부 주변 국가에서 대략 1750 년에서 1850 년 사이에 발생한 산업 혁명에 대한 한 가지 해석은 산업 혁명까지 성장이 매우 정체되었다는 것입니다.그리고 나서 약간의 변화가있었습니다. 어떤 흥미로운 피벗이 일어 났을 수도 있고, 아마도 산업 혁명의 반대편에 또 다른 세기가 될 수도 있습니다.어떤 이유로 기술 진보의 속도가 빨라진 곳.
Ben (00:24:55) :
그리고 사람들은 농업 기반 경제에서 산업 경제로 전환했습니다.그리고 사람들은 비 유기농 에너지 원을 사용하기 시작했습니다.그래서 더 이상 나무 나 동물 비료가 아닙니다.이제는 화석 연료와 전기 등으로 전달되는 에너지입니다.그리고 R & amp; D는 이제 경제 성장에 중요한 역할을하고 있습니다. 이전에는 그렇지 않았습니다.몇 가지 흥미로운 단계 전환이나 몇 백년 동안 일어난 일이 있습니다.우리는 단지 한 경제에서 더 빠르게 성장하고 변화 할 수있는 질적으로 다른 경제처럼 전환했습니다.
Ben (00:25:29) :
이제 기본적으로 인간 문명의 역사에 걸쳐서 성장 속도가 점점 빨라지고 있다는 장기적인 추세가 있다는 또 다른 해석이 있습니다.그리고이 해석은 경제의 전반적인 규모가 증가함에 따라 성장률 자체가 성장률 자체가 계속 증가하고 있다는 것을 말합니다.그리고 경제 규모가 계속 커지고 성장률이 계속 커지고 산업 혁명에서 눈에 띄게 폭발 한이 흥미로운 피드백 루프입니다.사람들이 이것을 알아 차릴 수있을만큼 속도가 마침내 빨라진 곳이기 때문에 사실 꽤 일관된 트렌드가있었습니다.실제로 위상 전환이 아니 었습니다.
Ben (00:26:12) :
예를 들어 열린 자선 프로젝트에서 일하는 경제학자 인 David Roodman의 최근 작업이 있습니다.이 지속적인 관점을 주장하거나 탐구하는 인간의 궤도를 모델링 한 그가 쓴 최근 보고서가 있습니다.경제사에서도 논쟁이 있습니다.경제학자 인 Michael Kramer가이 부드러운 가속화 관점과 많은 경제 역사가를 주장했습니다.사실 한 경제에서 다른 경제로 전환하는 데 이상한 점이 있습니다.
Ben (00:26:42) :
나는 단지 경쟁적인 해석이 있다고 말할 것입니다.그래서 누군가는 가끔씩 이렇게 말합니다. 조금 이상하고 약간 특이합니다.어떤 일이 일어나고 약간 불연속적인 변화가 있습니다.그리고 우리는 더 빨리 성장할 수있는 새로운 경제로 전환했습니다.또 다른 해석은 아닙니다. 실제로 이것은 꽤 일관된 숲입니다.상황이 계속 빨라지고 빨라집니다. 위상 전환이 아니고 불연속이 아닙니다. 세상이 점점 더 빠르게 가속하는 매끄럽고 정말 장기적인 추세가있을뿐입니다.
Jeremie (00:27:11) :
이것이 두 개의 다른 하위 문제처럼 얽히는 방식은 흥미 롭습니다.그중 하나는 인간이 거의 지속적으로 학습 하는가?즉, 동굴 사람들이 세대를 거듭하면서 실제로 점점 더 많은 기술을 습득하고있는 경우인데, 그것은 당신이 1 만년 이상을보아야 만 명백해지는 것입니다.아니면 기본적으로 정체되어 있고 모든 것이 진정으로 평평 해지면 이륙 할 수 있습니다.계속 축소하고 계속 축소하면 더 깊은 질문의 일부로 볼 수있는 것처럼 느껴집니다.더 이상 AI가 장악하고있는 미래 경제를 향해 반복되는 인류의 이야기가 아닙니다.그러나 오히려 완전히 생물 적 문제와 빅뱅에서 벗어나 순전히 가치 창출이 전혀 없습니다.
Jeremie (00:28:01) :
나는 그것이 삶이 진화하는 첫 순간 인 단계적 기능이어야한다고 생각한다.이것이 제가 궁금한 부분입니다. 그 관점은 제가 착각하지 않는 한 양자 도약 각도 또는 계단 함수 접근 방식을 더 많이 주장하는 것처럼 보입니다.
Ben (00:28:15) :
네.그래서 저는 그것이 옳다고 생각합니다.분명히 적어도 직관적으로 역사에는 뭔가 다른 일이 일어나는 것처럼 보이는 특정 전환이 있습니다.따라서 생명체로 인정받을 수있는 최초의 자기 복제는 어떤 의미에서 상당히 분리 된 경계와 같아야합니다.또는 그런 것들은 정말 진화의 역사를 모릅니다.하지만 먼저 미토콘드리아 같은 것을 수행하는 것이 세포의 일부가 된 것 같습니다.이것은 상당히 별개의 사건입니다. 저는 유기체 중 하나가 다른 유기체보다 작아서 [들리지 않음] [들리지 않음] 생명체의 전체 진핵 생물이 그로부터 진화했다고 믿습니다.그리고 그로부터 떨어지는 사람들과 같은 다양한 흥미로운 것들이 있습니다. 그것은 또한 직관적으로 제가 정확히 알지 못하는 불연속적인 변화처럼 보입니다.
Ben (00:29:06) :
그래서 직관적으로 어떤 것들이있는 것 같습니다.그리고 또 다른 하나는 사람들이 큰 방식으로 농업을 시작했던 산업 혁명에도 있습니다.일반적인 생각은 이것이 역사적 의미에서 실제로 상당히 빠르거나 인간으로서 자격이 될 수있는 것들이 수천 년 동안 수십 년 동안 존재 해왔다는 것입니다.그리고 아마도 서아시아와 그 이후의 다른 대륙들과 같은 수천 년 동안 사람들은 앉아있는 농업 문명으로 전환했습니다.
Ben (00:29:35) :
대략 10 만년 동안 거대한 빙하기 같았고 빙하기가 끝났다고 생각합니다. 그리고 기후가 바뀌었고 실제로 좌식 농업으로 전환하는 사람들에게 어떤면에서 더 유리 해졌습니다. 그리고 그것은 매우, 상당히 빠르게 일어났습니다. 그래서 네, 제가 개인적으로 그들에 대해 많이 알지 못한다면 적어도 그것이 정말로 느껴지는 역사적 사례가 있다고 생각합니다. 그것은 불연속적인 변화처럼 느껴집니다. 그리고 나는 또한 AI의 경우 어느 정도 그럴 것이라고 생각합니다. 내일 일어나면 안 될 것 같아요. 그러나 우리가 결국 완전 자동화에 도달하거나 AI로 인해 성장률이 다시 증가한다면 생각합니다. 사람들은 아마도 그것을 1950 년 이후로 존재해온 경제 동향의 안정된 지속으로 보지 않을 것입니다. 지금 우리는 매우 꾸준한 경제 성장률을 가지고 있고 꽤 안정적인 자동화 속도를 가지고 있습니다. 그리고 성장률이 미치게되면 사람들은 어떤 변곡점이나 피벗 점 또는 어떤 전환점이 관련된 것처럼 느낄 것이라고 생각합니다.
Jeremie (00:30:36) :
그것은 실제로 제가 정말로 논의하고 싶은 두 번째 영역에 대해 상상할 수있는 전환점만큼 좋은 전환점입니다. 이것이 바로 AI 안전에 대한 여러분의 견해입니다. AI 안전이 반드시 필요한 것은 아닙니다. AI 위험과이 아이디어라고합시다.AI 기반 세계로의 순조로운 전환, 또는 일종의 이상화 또는 실존 적으로 치명적인 시나리오로의 매우 갑작스러운 전환이라고 가정 해 봅시다.그래서 이것에 대한 견해가 있습니까?아마 나는 그것으로 일을 시작할 것입니다.그렇다면 AI 위험 주장이 강하다고 생각하는 부분과 실패한 부분에 대해 생각할 수 있습니까?
Ben (00:31:14) :
네.그래서 저는 처음에 연속성 질문이나 적어도 연속성 질문과의 관련성에 대해 조금만 말할 수 있다고 생각합니다.여러분이 언급했듯이, 이것은 또한 사람들이 AI에 대해 가지고있는 논쟁입니다. 얼마나 갑작 스러울 것인지 … AI 시스템이 기본적으로 인간의 노동을 쓸모 없게 만들고 모든 종류의 다른 미친 짓을 할 수있는 세상에 도달했다고 가정 해 봅시다.얼마나 갑작스러운 전환이 될까요?수십 년의 기간이고 점진적으로 전 세계에 퍼져 나가는 점진적인 산업 혁명의 비유와 같은 것일까 요?
Ben (00:31:48) :
화석 연료를 사용하지 않는 사람들이 화석 연료를 사용하지 않는 것 같은 것조차도 매우 긴 전환이라고 생각합니다.그런 경우와 더 비슷할까요, 아니면 훨씬 더 갑작스럽게 느껴질까요?예를 들어, 우리가 기본적으로 정상적인 상태에서 지금은 모든 것이 AI이거나 심지어 2 년 미만인 2 년의 기간과 같은 시점이 있을까요?그리고 이것은 때때로 장기 주의자 나 미래 주의자에서 일어나는 논쟁입니다 [들리지 않음 00:32:15].그리고 어떤면에서는 위험을 증가 시키거나 결국 감소시키는 어떤면에서 관련이있는 것 같습니다.
Ben (00:32:24) :
따라서 위험 증가 측면에서 갑작 스럽거나 매우 빠른 변화가 의미하는 한 가지는 갑자기 발생할 수 있다는 것입니다. 그래서 그것은 매우 연속적입니다. 여러분은 미리 많은 일들이 일어나고있는 것을 볼 수 있습니다. 정말 갑작 스럽거나 2 년이 걸리는 과정이라면 원칙적으로 지금부터 2 년이 지나면 우리는 아주 다른 세상에서 살 수 있습니다. 또한 준비 할 시간과 중간 수준의 차이에 익숙해지고 시행 착오 학습을 수행하고 위험이 무엇인지 파악할 시간이 줄어 듭니다. 위험이 아닌 것. 우리가 이것을 이야기하고 문제를 찾고 익숙해지는 방법을보고 중간 해결책을 제시하고 실수로부터 배울 수있는 기회를 깨닫는다면. 그리고 이것에 대한 가장 큰 위험은 아마도 마지막 주요 위험 범주 인 잘못 정렬 된 AI와 관련된 위험과 관련이 있다고 생각합니다. 그리고 이것들은 또한 약간 다양하며 팟 캐스트에서 이전 사람들이 그들에 대해 이야기 한 적이 있다고 생각합니다.
Ben (00:33:21) :
그러나 많은 우려는 기본적으로 우리가 앞으로 개발할 많은 AI 시스템이 마치 특정 목표를 추구하는 것처럼 어느 정도 작동 할 것이라는 점으로 요약됩니다.또는 세상에 대한 특정 사항을 극대화하려고합니다.[들리지 않음 00:33:35] 시스템이 형사 사법 관점에서 범죄율에 대한 예측을한다는 점에서 어떤 의미에서는 예측 정확도를 높이려고하는 것입니다.그리고 관심은 AI 시스템이 어떤 의미에서 멀어지고 사람들이 갖는 경향이 있고 이것이 비참한 결과를 초래할 것이라는 목표가 있다는 것입니다.우리는 사람들이 원하는 것과 다른 일을하면서 어떤 목표를 달성하는 데 아주 영리하고 아주 좋은 AI 시스템을 가지고 있습니다.
Ben (00:34:12) :
속도는 이것과 정말 관련이 있습니다. 이것이 누군가의 만연한 문제가 될 것이라고 생각한다면 AI 시스템을 만들고 배포하기 때문입니다.그리고 사람들이 가지고있는 목표와 목표 사이에는 일종의 차이가 있습니다. 이것은 해를 끼칩니다.전 세계에서 더 크고 더 큰 역할을하는 AI 시스템으로의 전환이 계속 진행되고 있다면이 문제의 덜 치명적인 버전을 알거나 작동하거나 작동하지 않는 것을 배우는 데는 시간이 많이 걸릴 것입니다.모든 사람이 점진 성과 시행 착오만으로 문제를 완전히 해결할 수 있다고 확신하는 것은 아닙니다.그러나 실제로 더 많은 사소한 버전의 우려 사항을 확인하고 사소한 경우에 작동하는 솔루션을 찾는 것이 도움이되는 것 같습니다.항상 이런 일은 매우 갑작 스럽습니다. 우리가 내일 깨어 나면 원칙적으로 인간의 노동력을 완전히 대체하고 정부를 운영하고 무엇이든 할 수있는 AI 시스템이 있습니다.
Ben (00:34:59) :
어떤 이유로 든 사용하기로 결정하면.그리고 그들은 어떤 중요한면에서 우리와 다른 목표를 가지고 있었는데, 이것은 아마도 훨씬 더 걱정스럽고 우리는 다가오는 문제를 보지 못할 수도 있습니다.네.그래서 저는 당신의 질문에 이것이 왜 주요 관심사가 아닐 수있는 이유는 무엇입니까? 아니면 어떤 식 으로든 관심사가되는 일련의 주장은 무엇입니까?
Jeremie (00:35:21) :
글쎄요, 사실 짐을 푸는 데 많은 시간이 걸렸다는 더 구체적인 우려가 있다고 생각합니다.그리고 이것은 Nick Bostrom이 그의 책 Superintelligence에서 주장하는 논쟁에 대한 관심입니다.간단히 요약하자면 여기에 티업을하겠습니다. 아이디어는 제가 이것을 도살 할 것입니다. 제가 도살하는 다양한 방법을 자유롭게 강조해주세요.하지만 아이디어는 우리가 AI 팀을 가정한다면 OpenAI와 DeepMind와 그 밖의 모든 것이 점차적으로 반복되고 반복되고 반복되는 것과 같습니다.언젠가 그들 중 하나는 통찰력이나 구매, 전체적인 컴퓨팅 또는 전체 데이터에 대한 액세스 권한을 갖습니다.그것은 시스템을 한심하고 작은 GPT-3에서 이제 갑작스런 인간 수준 이상으로 향상시키는 데 필요한 유일한 것입니다.
Jeremie (00:36:06) :
그 시스템은 인간 수준 이상이기 때문에 인간이 AI 시스템을 개선하는 방법을 알고 있기 때문에 스스로 개선하는 방법을 알 수 있습니다.그래서 아마도 스스로를 개선하는 방법을 알아 내고 루프가 매우 빡빡하므로 AI가 스스로를 개선 할 수 있기 때문에 재귀 루프를 얻을 수 있습니다.그리고 결국 그것은 너무 똑똑해서 압도 할 수 있습니다. 지능을 가진 포획 자들이 세상을 장악하고 완전히 비참한 결과로 이어질 수 있다고합시다.적어도 대략적으로 맞습니까?
Ben (00:36:30) :
네.그래서 나는 그것이 기본적으로 대략 옳다고 생각합니다.네.그래서 생각하는 한 가지 방법은 이러한 정렬 문제의 스펙트럼이 있다고 생각합니다.그리고 그들 중 일부는 시간이 지남에 따라 점진적으로 많은 AI 시스템을 만들고 목표가 우리와 다르며 미래와 그런 종류의 통제력을 점차적으로 상실하는 미래의 모호한 관점에 있습니다.그리고 훨씬 더 극단적 인 곳은 하나의 AI 시스템이 있고 아주 갑자기 도착하는 것과 같습니다.그리고 그것은 어떤 의미에서 광범위하게 초 지능이며 실제로 중요한 전례가 없습니다.그리고 그 시스템은 개별적으로 매우 빠르게 세계에 혼란을 야기합니다.이 하나의 매우 파괴적인 시스템으로 크게 도약하는 것처럼 확실히 우려되는 버전입니다.Nick의 책 Superintelligence와 내러티브 등에서 강조된 것 같습니다. 방금 설명한 것 같습니다.
Ben (00:37:18) :
그래서 인공 지능 위험에 대한 저 자신의 생각 중 상당수는이 스펙트럼의 더 극단적 인 끝에 대한 것이었기 때문에 몇 가지 이유로 초 지능과 같은 곳에서 우려가 나타납니다.하나는 제가 처음 만난 버전이고 특히 관심을 갖게 한 부분이라고 생각합니다. 이것은 부분적으로 개인적인 관심 이유라고 생각합니다.
Ben (00:37:39) :
그리고 다른 사람들은 이것이 단지 많은 AI 얼라인먼트 연구자들이이 버전의 관심사를 염두에 두지 않더라도 단지 일이라고 생각합니다.아직도 꽤 영향력 있고 잘 알려져 있다고 생각합니다.그리고 종종 누군가가 AI 위험에 대해 아는 것이 있다면 이것이 떠오르는 우려의 버전입니다.주목할 가치가있는 특별한 것 같습니다.그래서 제 생각 중 일부는 여러분이 실제로 이처럼 갑작스런 도약을하게되었고 오늘날과 같은 주요 AI 시스템이 실제로는없는 것이 그럴듯한 문제에 관한 것입니다.그리고 갑자기 어딘가에있는 어떤 연구원이이 중요한 돌파구를 갖게되고 여러분은이 단일 시스템으로 끝납니다.지루한 이유로 이것에 대해 상당히 회의적인 것 같습니다.
Ben (00:38:15) :
따라서 초기 지루한 이유 중 하나는 기술이 작동하는 방식이 아니기 때문입니다.좋아요의 관점에서 시작한다면 기술이 일반적으로 세상을 어떻게 변화시키는 지 살펴 보겠습니다.일반적으로 누군가가 무언가를 개발하는 데 수십 년이 걸리는 장기적인 프로세스이고 긴 개선 프로세스 인 경우입니다.그리고 그것은 다른 분야보다 먼저 일부 분야에서 포인트이고 다른 분야보다 먼저 일부 분야에서 유용합니다.그리고 사람들은 그것을 활용하기 위해 무료 발명품을 개발해야합니다.그리고 사람들은 그것을 실제로 적절하게 사용하는 방법을 알아 내야합니다.그리고 예측하지 못한 많은 조정과 문제가있어 프로세스를 느리게 만듭니다.전기처럼 전기 모터가 19 세기 초반에 발명되었다고 생각합니다.그러나 전기 모터는 1930 년대까지 미국 공장에서 우세하지 않습니다.
Ben (00:39:02) :
또는 20 세기 중반의 최초의 디지털 컴퓨터 였지만 90 년대부터 생산성 통계에 큰 의미로 표시됩니다.그리고 그럼에도 불구하고 다른 중요한 맥락에서 널리 사용되는 것과는 달리 실제로는 여전히 많은 국가가 아닙니다.그리고 경제의 더 큰 부분과 같은 의미에서는 아닙니다.그래서 그것은 거기에서 시작이되고 당신은 AI의 세부 사항을 너무 구체적으로 보지 않고 “우리가 가진 다른 기술과 같다면 나는 무엇을 기대할까요?”라고 말하는 것과 같습니다.아마도 그것은 경제적 변화 일 것입니다. 그것은 점진적인 일이 될 것이고, 발생하는 많은 성가신 일들이 될 것입니다.
Jeremie (00:39:35) :
그것에 대해 조금 조사하기 위해서.그래서 제가 상상하는 것 중 하나는 우리가 선택한 기간에 상관없이 지난 100 년 동안 기술의 발전과 보급을 가속화 시켰습니다.우리는 인터넷이하는 역할 등에 대해 꽤 많이 이야기했습니다.특히 제품을 디자인하는 팀, 제품을 배포하는 팀, 제품을 판매하는 팀 간의 피드백 루프를 강화하는 측면에서 커뮤니케이션이 필요합니다.통일성이 커뮤니케이션에 의해 주도되는 정도까지.”내부적으로 일관된 단일 AI 시스템이 있고 본질적으로 무한이 아니라 기계 시간에 맞춰 피드백 루프를 강화할 수있는 경우”라는 의미에서이 주장을 약화시킬 수 있습니까?그 위치가 흥미 롭다고 생각하십니까? 제가 묻고 자하는 것이 아닐까요?
Ben (00:40:28) :
그래서 흥미롭지 만 설득력이 없다고 생각합니다. 그래서 저는 경제적으로 관련된 모든 생산 작업을 제공 할 수있는 매우 광범위하게 사용할 수있는 AI 시스템으로 갑자기 도약한다고 상상하기 위해 뛰어 드는 것과 같은 아이디어가 있다고 말하고 싶습니다. 칩 채굴, 투표 투표소 운영, AI 연구, 더 많은 컴퓨팅 리소스 구축, 군사 전략없이 관리 할 수 있습니다. 갑자기 존재하는 단일 시스템이 있다고 상상하면 외부 요인과 상호 작용하거나 외부 리소스를 사용하지 않고이 모든 작업을 자체적으로 수행하는 것입니다. 통신 효율성 비용이 많이 줄어들었기 때문에 일이 더 빨리 발생할 수 있다는 직감이있는 것 같습니다. 하지만 이런 질문이 있습니다. 이것이 개발이 작동하는 방식이라고 상상해야합니까? 갑자기 이러한 모든 기능을 제공하는 단일 시스템이 될 것입니다. 그리고 AI의 경우에 대해 회의적 일 것입니다. 또 다소 지루한 이유로도 그렇습니다.
Ben (00:41:32) :
그래서 우리는 당신이 동시에 다른 분야에서 발전 할 수 있다는 것을 압니다.그래서 … 아마도 많은 청취자들이 이것, 언어 모델 또는 OpenAI가 개발 한 최근 시스템 GPT-3에 익숙하다고 생각합니다.이것은 대략 같은 시간에 단일 교육 과정을 통해 많은 다른 작업을 꽤 잘 수행 한 시스템의 예입니다.그래서 저는 기본적으로 웹 페이지의 방대한 코퍼스에서 훈련을 받았습니다.그리고 저는 기본적으로 제가 접한 문서에서 이미 접한 단어를 기반으로 가장 덜 놀라운 다음 단어를 예측하도록 훈련 받았습니다.
Ben (00:42:08) :
따라서 뉴스 기사의 헤드 라인을 작성하는 등의 작업에 사용할 수 있습니다. 그런 다음이 헤드 라인이 주어지면 기사에서 가장 놀라운 텍스트가 무엇인지 생각해 보겠습니다.그리고 사람들이 발견 한 한 가지는 실제로 다양한 작업을 수행하는 데 사용할 수 있다는 것입니다.예를 들어 스페인어로 문장을 작성하고 영어 번역이라고 말할 수 있습니다. 문장이 비어 있습니다.그리고 시스템은 적어도 다음에 발견 할 놀라운 것은 기본적으로 그것의 영어 번역과 같을 것이고 그것을시를 쓰는 데 사용할 것입니다.이 Emily Dickinson시와 그런 종류의시에서 가장 놀라운 결말은 무엇입니까?
Ben (00:42:42) :
그러나 어떤 의미에서 많은 다른 기능이있는 이러한 경우에도 한 번에 온라인 상태가됩니다.당신은 여전히 AI가 다른 것들에서 얼마나 좋은지에 대해 분명히 변이를 볼 수 있습니다.따라서 사용 가능한 컴퓨터 코드와 같이 대부분의 경우 쓰기가 매우 나쁩니다.약간은 할 수 있지만 기본적으로 현재로서는 유용한 방식으로 할 수 없습니다.Jabberwocky 스타일의시처럼 쓰는 데 꽤 능숙합니다.이 중 하나가 다른 시보 다 먼저 나왔습니다.그리고 일부 기능이 다른 기능보다 우선하는 확장되는 경우가 될 수도 있다고 생각할 이유가 있습니다.또한이 GPT-3 스타일을 통해서만 순수하게 생산할 수없는 몇 가지 기능이 있습니다.이 대규모 온라인 항목에서 훈련시킬 수 있습니다.
Ben (00:43:23) :
국방부 내부 메모를 번역하려면 다른 것에 대해 교육을 받아야합니다.의료법처럼 쓰길 원한다면 아마 [들리지 않음 00:43:30]은 당신을 위해 그렇게하지 않을 것입니다.슈퍼마켓 가격을 책정하거나 가격 인벤토리에서 설정하거나 실제로 회의를 예약 할시기를 알고있는 이메일을 개인화하려는 경우.다른 훈련 방법이 필요합니다.또는 인간보다 더 잘 수행하고 싶다면 다른 훈련 방법이 필요할 것입니다. 왜냐하면 당신은 그것을 줄 필요가 있기 때문입니다. 기본적으로하는 것은 사람에게 가장 덜 놀라운 일이 무엇인지 말하는 것입니다.인터넷에 글을 썼습니다.하지만 사람보다 더 잘하고 싶다면 다른 것을 사용해야합니다. 일종의 피드백 메커니즘입니다.
Ben (00:43:55) :
따라서 기본적으로 다른 기능이 다른 시간에 온라인으로 제공 될 것이라고 생각하는 이유입니다. 또한 연구자들에게는 실제로 나타나지 않는 여러 특정 영역에서 발생하는 성가신 내용이 많이있을 것입니다. 하지만 공장에서 실제로 전기 모터를 사용하는 사람들에게 [들리지 않음 00:44:07] 법칙과 같은 것을 적용하려는 경우, 공장 현장을 재 설계해야하는 것과 같은 문제가 발생합니다. 더 이상 중앙 증기 기관을 기반으로하지 않기 때문입니다. 하드웨어를 사용하는 것을 재 설계해야합니다. 작업자가 실제로이 기능을 활용하기 위해 사용하는 프로세스를 재 설계해야합니다. 일어나야 할 규정이 있습니다. 그리고 아마도 이러한 것들은 적어도 처음에는 다른 팀에서 어느 정도 처리해야 할 것입니다. 그리고 그들 중 일부는 다른 것보다 어렵거나 다른 것보다 다른 자원을 필요로 할 것입니다. 그리고 이것이 내가 온라인으로 올 것이라고 기대하는 긴 말과 같았다면 기본적으로 놀라 울 것입니다. 이것은 실제로 다른 작업에 대해 꽤 다른 지점에서 세상에서 정말 유용 할 것입니다.
Jeremie (00:44:40) :
흥미 롭군.네, 그게 완벽합니다.저에게 흥미로운 것은 이론가가 만들 시스템을 상상하면서 만드는 오류의 종류라는 것입니다. 그리고 이것이 오류가 아니라이 시나리오는 쉽게 통과 될 수 있습니다.그러나 이는 실제로 시스템과 경제의 최적화보다는 이론적 최적화에 초점을 맞춘 사람의 심리학에 매핑되는 것처럼 보이는 흥미로운 반대입니다.흥미 롭군.따라서이 중 어느 것도 반복적으로 자체 개선하고 [누화 00:45:21] 개발할 수있는 능력을 갖춘 AI 시스템이 미래의 어느 시점에서 가능하지 않을 것이라고 암시하는 것 같습니다.
Jeremie (00:45:23) :
이 질문에는 두 부분이 있습니다.먼저 A 씨, 그렇다고 생각하십니까, 아니면 그러한 시스템을 구축 할 수있을 것이라고 생각하십니까?그리고 B, 그러한 시스템이 구축 될 것입니까 아니면 구축 될 것이라고 생각하십니까?우리를 재귀 적으로 자기 개선하는 AI에 도달하기 위해 쌓이는 일련의 인센티브가 있습니까? [foom 00:45:47], 결국에는 무엇이든할까요?그럴듯한 이야기인가요?
Ben (00:45:51) :
네.그래서 여기에 몇 가지가 있습니다.그래서 첫 번째 부분은 재귀 적 자기 개선이 정말로 중요 할 것이라는 점이 저에게 분명하지 않다는 것입니다.따라서 분명히 피드백 루프가 있으며 향후 피드백 루프가 될 것입니다.따라서 우리는 더 제한된 방식으로 많은 기술을 봅니다.따라서 존재 소프트웨어는 소프트웨어 개발에 유용합니다.소프트웨어 개발자는 소프트웨어를 사용하고 컴퓨터는 컴퓨터 설계에 유용합니다.Nvidia 나 하드웨어 제조업체와 같은 사람들이 사용할 컴퓨터가 없었다면 직업이 훨씬 더 어려워 질 것입니다.따라서 기술 개발을 지원하거나 기술이 다른 기술 개발을 지원 한 경우가 많습니다.일반적으로 재귀 적이 지 않거나 일반적으로 자체적으로 개선되는 것과 똑같은 아티팩트가 아닙니다.
Ben (00:46:44) :
그리고 AI의 경우 재귀적일 것으로 예상 할만한 타당한 이유를 반드시 찾지는 않습니다.올바른 아키텍처를 찾는 AI 개발의 맥락에서 AI가 점점 더 많이 적용될 것으로 기대합니다.또는 기본적으로 다른 시스템을 개발하거나 제대로 작동하도록 만드는 가장 최적의 방법이 무엇인지 알아 내거나 학습합니다.하지만 다른 시스템을 훈련시키는 데 도움이되도록 개발 된 시스템이 아니라 개별 시스템이 자체적으로이를 수행한다고 생각할 강력한 이유를 반드시 확인하지는 않습니다.소프트웨어와 같은 방식은 저절로 개선되지 않습니다.나는 그것이 재귀 적이라는 것에 대한 큰 이점을 실제로 보지 못합니다.그렇게했다면 그럴 수도 있지만 왜 재귀 적인지, 왜 그것이 본질적으로 더 매력적인 지 모르겠습니다.어떤면에서는 덜 매력적으로 보일 수 있습니다.어쩐지 더러워 보이거나 이것이 약간 모듈식이라면 멋져 보입니다.
Jeremie (00:47:33) :
예, 저는 어느 정도 공학적 관점에서이 주장을 조금 강화하기 위해 상상할 수 있습니다 … 그래서 다른 시스템의 추상화가 있습니다.이 용어는 시스템 A가 있고 시스템 B가 있다고 말할 때 사용합니다.시스템 A가 자체적으로 개선되거나 시스템 B가 개선하고있을 수도 있고 시스템 A가 개선되고있을 수도 있습니다.이 경우 제가 생각하는 것은 기계 시간에 결정적으로 작동하는 폐쇄 형 시스템과 같은 것을 다루는 추상화라고 생각합니다.따라서이 형태의 도약과 같이 정의하는 내 마음의 주요 차이점은 이것이 자체 최적화 또는 시스템 A가 시스템 B를 개선한다는 사실이 마이크로 초 정도의 순서로 발생한다는 것입니다.또는 인간이 그 과정에 개입하지 않고 궁극적으로 결과가 우리의 기대에서 크게 벗어날 수있는 결과에 놀라게되는 이유는 무엇입니까?
Ben (00:48:33) :
네.그래서 저는 아마도 주요 차이점 중 하나가 개선 과정에 기본적으로 관련된 노동이라고 생각합니다.따라서이 AI 피드백 루프에 대한 일반적인 카운터는 변경 속도를 실제로 높이는 데 매우 중요합니다.20 세기 초에 연구 자나 엔지니어가했던 많은 작업이 더 이상 수행되지 않는 피드백 루프가 이미있는 것 같습니다.완전히 자동화되었습니다.따라서 실제로 손으로 계산하는 것은 엄청난 시간 낭비와 같습니다.공학을위한 연구 노력과 같습니다.따라서 사람들이 작업에 소비하는 시간 측면에서 방대하고 방대한 자동화가 이루어졌고 그 중 상당 부분이 어느 쪽이든 자동화되었습니다.그런 의미에서 기술 발전이 기술 발전에 도움이 된 정말 강력한 피드백 루프가있었습니다.
Ben (00:49:25) :
그러나 적어도 20 세기 중반 이후로 우리는 적어도 선도 국가에서 기술 발전과 같은 생산성 증가율의 증가를 보지 못했습니다.실제로 느려진 것 같습니다.그리고 그 비율은 현재 미국의 20 세기 초와 비슷합니다. 따라서 분명히이 피드백 루프는 그 자체로는 충분하지 않으며 상쇄되는 것이 있으며 아마도이 아이디어와 같은 것을 찾기가 어려워지고 있음을 의미 할 것입니다.현상.기술이 새로운 것을 만드는 데 도움이되지만, 만들고 싶은 각각의 새로운 것을 이전의 것에서 만드는 것이 조금 더 어렵습니다.쉬웠다면 이미했을 테니까요그래서 그것은 하나의 일반적인 반론입니다.
Ben (00:50:01) :
그리고 그에 대한 반박 론은 우리가 연구에 관련된 많은 작업을 자동화하고 그 작업을 수행 할 기계를 만든 다음 기계를 개선하는 것과 같습니다. 인간 노동은 항상 그것의 일부였습니다. 그리고 만약 당신이 자본에 의해 채워지는 인간 노동이 기본적으로 보완적인 이야기를 가지고 있다면. 우리는 계속 더 차가운 기계를 만들고 더 많은 기계를 만드는 노동 병목 현상이 있다고 생각합니다. 그러나 고정 된 양의 연구 노력으로 인해 기계의 차가움이나 기계의 수량에 대한 수익이 감소하고 있습니다. 따라서 연구 노력이 실제로 병목 현상입니다. 이는 연구자가 수행하거나 연구자가 소유 한 추가 멋진 기술의 한계 가치를 실제로 제한하는 이러한 감소하는 수익 현상을 만듭니다. 그리고 연구자들의 수는 인구와 같은 것들과 연결되어 있기 때문에 그렇게 쉽게 바꿀 수없는 꽤 일정한 기하 급수적 인 속도로 증가합니다.
Ben (00:50:57) :
그래서 제가 말했죠. 실제로 인간의 노동 만 그림에서 완전히 제거하면 사람들은 더 이상 R & amp; D 나 제조에 관여하지 않습니다.그렇다면이 경우 더 이상 수익 감소 효과가 없을 수도 있고, 고정 된 노동량과 같이 자본에 대한 수익이 감소하는 병목 현상이 더 이상 없을 것입니다.아마도 그것은 그저 자신에게 직접적으로 피드백을주고, 감소하는 수익은 어떤 중요한 의미에서 사라집니다.그리고 피드백 루프는 루프에서 사람을 완전히 제거하면 실제로 시작됩니다. 피드백 루프가 미래에 우리가 사용했던 비명 시적 피드백 루프와 다른 이유를 말할 수있는 이야기가 될 것입니다.지난 세기.
Jeremie (00:51:29) :
그리고 저는 인간의 자기 개선에 대한 피드백이 있다고 생각합니다.여기서는 시계 시간이 두드러진 특징이라고 생각하지만 생산성 향상을 위해 노력하고 있으며,이를 제정하기 위해 노력하고 있습니다.나는 나 자신을 향상시키는 방법을 개선하려고 노력합니다.원칙적으로 나는 무한한 수의 파생물 또는 물질에 가깝게 그렇게한다고 생각합니다.기하 급수적 인 특성이 있지만 분명히 저는 아직 Elon Musk가 아닙니다.어려운 도약을하지 못해서 어딘가에 차이가 있습니다.
Ben (00:52:05) :
네.그래서 제가 말하고 싶은 것은 아마 당신의 말이 맞다고 생각합니다. 그것은 실제 현상입니다.많은 규모가 관련되어 있지만 스스로 개선해야 할 정도는 기술보다 훨씬 적다고 생각합니다.연구원 단위가 노트북에있는 사람이라고 가정 해 봅시다.그리고 그것이 연구를 생산하는 것입니다.그 사람은 실제로 코딩을 더 잘할 수 있고, 일을 빠르게하는 방법을 더 잘 배울 수 있고, 배우는 방법을 배울 수 있습니다.그러나 생산성의 실제 차이는 2020 년 평균 연구원에 비해 인적 자본 측면에서 10 배 정도 증가하는 데 도움이 될 수 있습니다.당신의 노트북은 지금보다 훨씬 더 나은 것을 얻을 수 있다는 측면에서 올라갈 수있는 [들리지 않음 00:52:44]이 더 많은 것 같습니다.
Jeremie (00:52:49) :
안타깝게도 그럴 것 같지만 계속 노력하면됩니다.그게 필요한 것 같아요.
Ben (00:52:56) :
네.랩톱의 개선 속도에 대한 경주에서 행운을 빕니다.
Jeremie (00:52:59) :
네.감사.이륙하면 알려 드리겠습니다.정말 흥미 롭습니다. 여러분이 이것에 대해 너무 많은 생각을 해왔고 여러분이 이것에 대해 생각하는 방식에있어서 약간의 변화를 볼 수 있습니다. 확실히 전에 고려하지 않은 측면이 있습니다.그것은 시스템 관점에서 오는 경제학 관점에서 비롯됩니다.이것이 기술 AI 안전 전문가들 사이에서 특히 드물다고 생각하는 방식입니까?아니면 그것이 채택되는 것을보기 시작 했습니까? 저는 여전히 풍경이 어떻게 생겼는지, 그리고 시간이 지남에 따라이 주제에 대한 견해가 어떻게 바뀌고 있는지 함께 모 으려고 노력하고 있습니다.예를 들어 2009 년을 기억하기 때문에 [들리지 않음 00:53:45]이었습니다.기본적으로 모든 사람들이 상자 속의 뇌에 대한 생각이나 기계 자체가 향상되는 빠른 이륙에 대해 이야기했습니다.
Jeremie (00:53:54) :
지금은 OpenAI, Paul Christiano, 그리고 Future of Humanity Institute에서 진행중인 많은 작업 사이에서 실제로처럼 보이지만 상황이 바뀌고 있습니다.그리고 저는 그 변화, 타임 라인, 그리고이 모든 주제들과 관련하여 커뮤니티가 현재 어떤 위치에 있는지에 대한 여러분의 관점을 얻고 싶습니다.
Ben (00:54:11) :
네.그래서 저는 확실히 변화가 있었다고 생각합니다.이 커뮤니티의 중앙값이 그것에 대해 생각하고 있다고 가정 해 봅시다.한 방향으로 생각하는 사람들의 관점에서 다른 생각으로 이동하는 것이 얼마나 많은지 저에게는 조금 모호합니다.더 많은 사람들이 기존에 다른 사고 방식으로 커뮤니티에 진입하는 것에 비해.사람들이 좀 더 구체적인 방식으로 생각하는 요소가 있다고 생각합니다.많은 오래된 분석에서 생각하는 것은 매우 추상적입니다.아주 많이 의존합니다… 그것은 정확히 수학적이 아니라 사람들이 추상적 인 대수를하는 것과 같습니다.하지만 분명히 더 수학적 사고 방식과 같을 것입니다.
Ben (00:54:58) :
시간이 지남에 따라 변화합니다.그 이유 중 하나는 매우 정당하다고 생각합니다. 2000 년대 중반 사람들이 이것에 대해 이야기 할 때입니다.머신 러닝은 정말 큰 일이 아니 었습니다.사람들은 논리 지향 시스템이 AGI가 어떻게 보일 것이라고 생각했습니다.정말 생각할 모델로 사용하기 위해 모든 AGI-ish를 실제로 보았던 모든 것.그리고 저는 기계 학습이 시작되고 사람들이 이러한 시스템을 갖기 시작했다고 생각합니다. 분명히 이것이 AGI가 아니며 아마도 AGI가 그것과 매우 다를 것입니다.AGI로가는 길에있는 작은 디딤돌과 같습니다.마치 AGI 같은 것 같네요.
Ben (00:55:41) :
이러한 구체적인 예를 들으면 약간 다른 방식으로 생각하게됩니다. 이전에 가졌던 추상 프레임 워크의 맥락에서 설명하기가 실제로 약간 어렵다는 사실을 깨닫기 시작합니다. 따라서 GPT-3에는 목표가 있거나이 동작을 예측하려는 경우 얼마나 유용합니다. 다음 단어가 놀랍지 않은 것을 만들어내는 것이 목표라고 생각하지만 그렇게 생각하는 것이 옳다고 생각하지 않습니다. 이 행동을 예측하는 데 얼마나 유용한지는 분명하지 않습니다. 출력을 막기 위해 사람을 죽이는 것과 같은 미친 짓을 할 위험이없는 것 같습니다. 왠지 잘 맞지 않는 것 같은 느낌이 듭니다. 또한 더 구체적인 응용 프로그램을보고 생각하는 것뿐입니다. 예를 들어 Paul Christiano가 어느 정도 낙관적으로 말한 것처럼 말한 것 같습니다. 큰 돌파구가없는 미래.” 사람들에게 전부 또는 전부가 아닌 더 지속적인 의미로 생각하도록합니다. 중간 변형의 디딤돌을 볼 수있는 것과 같습니다.
Ben (00:56:41) :
그래서 좀 더 구체적이면서 중간 응용 프로그램을보고 있다고 생각합니다.그리고 추상적 인 구성에 대해 좀 더 회의적인 느낌이 들었습니다. 단지 당신이보고있는 것에 맞추기가 어렵거나 효과가있는 일부 힘 때문일 수도 있습니다.일반적으로 나는 사물에 접근하는 더 수학적이고 고전적인 방법이 여전히 상당히 유용하거나 사물에 접근하는 주된 방법이라고 생각하는 사람들이 많이 있다고 생각합니다.
Jeremie (00:57:09) :
네.나는 실제로 논증을 들었습니다. GPT-3와 같은 시스템이 당신이 설명한 방식대로 병리학적인 것이 될 것이라는 논증은 꼭 들어 보지 않았습니다.그러나 적어도 그런 시스템이 정말로 심하게 잘못 될 수있는 세계를 설명하는 내부적으로 일관성있는 소리를 들려 줄 수있는 이야기.이 경우 GPT-10을 상상 해보세요.그리고 당신은 반드시 영광스러운 자동 완성 작업처럼 이것을하는 시스템을 가지고있었습니다.하지만 그 작업을 수행하기 위해 분명해 보이는 한 가지는 세계의 상당히 정교한 모델을 개발하고 있다는 것입니다.이것이 암기인지 실제 일반화 가능한 학습인지에 대한 논쟁이 있습니다.하지만 GPT-3에 의심의 이점을 제공하고 일반화 가능한 학습이라고 가정하겠습니다.이 경우 시스템은 점점 더 정교한 세계 모델, 더 크고 더 큰 컨텍스트 창을 계속 개발합니다.
Jeremie (00:58:06) :
결국 세계의 모델에는 GPT-3 자체가 존재하고 세계의 일부라는 사실이 포함됩니다.결국 이러한 실현은 그래디언트를 최적화하려고 시도하면서 “오, 나는 일종의 와이어 헤딩을 통해 내 그래디언트를 직접 제어 할 수 있습니다.”라는 사실을 깨닫게합니다. 일반적으로 [crosstalk 00:58:25] 커뮤니티에서 프레임이 구성됩니다.등등.설명하신 문제가 이런 사고 방식에 적용되는 것 같습니다.하지만 GPT-3이 어떻게 이러한 초록 중 일부에 대한 구체적인 생각을 이끌어 냈는지 흥미 롭습니다.
Ben (00:58:39) :
네.이러한 구체적인 시스템을 갖는 것도 매우 유용하다고 생각합니다. 왜냐하면 그것들이 직관에 차이를 강요한다고 생각하기 때문입니다.또는 컴백과 가정의 차이를 표면에 강요하십시오.예를 들어, 일부 사람들이 이러한 GPT 시스템에 대해 우려를 표명 한 경우가 있습니다. GPT-10을 사용하는 경우 매우 위험 할 수 있습니다.사실 저는 이것을 짐작하지 않았을 것입니다.아니면 다른 사람들이이 직감을 가지고 있지 않았다고 생각하지 않았을 것입니다.내 기본 직관은 기본적으로 시스템이 작동하는 방식에 비해 너무 대략적인 근사치이기 때문입니다.일부 매개 변수의 모델이며 텍스트 코퍼스처럼 노출됩니다.기본적으로 X 단어를 출력하고 다음 단어가 실제로 옳거나 맞지 않습니다.또는 기본적으로 데이터 세트의 실제 단어에 비해 출력을 덜 놀라게하는 그라디언트가 있습니다.
Ben (00:59:35) :
기본적으로 단어 출력에 최적화되어 있습니다. 온라인 어딘가에있는 텍스트에서 X 단어로 찾는 것은 놀라운 일이 아닙니다.그리고 GPT-10을 생각할 때 “와, 그냥 단어를 출력하는 것 같아요. 온라인 웹 페이지에서 찾는 건 그리 놀랍지 않네요.”그것이하는 일과 똑같습니다.그리고 그것이 사람들로 하여금 세상이나 무언가를 파괴하도록 이끄는 출력 단어와 같은 일을한다고 가정 해 봅시다.온라인에서 찾을 때 가장 놀랍지 않은 단어 일 때만 그렇게 할 것 같습니다.세상을 파괴하는 단어가 아니라면, 사람들은 보통 온라인에서 그런 종류의 글을 쓰지 않기 때문에 온라인에서 찾는 것이 놀랍습니다.그렇다면 경사 하강 법 과정에서 이상한 일이 발생한 것 같습니다.
Jeremie (01:00:15) :
그래서 프레임을 만드는 데 정말 좋은 방법이라고 생각합니다.저는 그것에 대한 반론이 마치 20 만년 전의 인간을 섹스 옵티 마이저 또는 이와 비슷한 것으로 볼 수 있다고 생각합니다.그리고 우리는 우리의 진화가 전개되면서 우리가 그렇지 않다는 것을 알게됩니다.제 생각에 여기에있는 경우는 신경망이 실제로 최적화하는 것이 무엇인지에 대한 깊은 질문이 있습니다.손실 함수를 최적화하고 있는지 또는 그래디언트가 업데이트 될 때마다 킥을 느끼는지는 실제로 명확하지 않습니다.“오, 틀렸어요.이것으로 모든 요금을 업데이트하십시오.”
Jeremie (01:00:58) :
그 킥이 아파요?그렇다면 이것이 이러한 시스템에 의해 최적화되고있는 것이 진정한 것일까 요?그리고 그게 사실이라면, 우리가이 주변을 둘러싸고있는이 전체 영역이 분명히 내부 정렬이 있습니다.하지만 그것은 깊은 토끼 구멍입니다.
Ben (01:01:15) :
그래서 저는 시스템을 훈련 할 때 사용되는 손실 함수와이 시스템이하려는 것처럼 작동하는 것 사이에 차이가 있다는 데 동의합니다.그리고 정말 간단한 방법이 하나 있습니다. 그것은 강화 학습 시스템을하는 체스처럼 시작하는 것입니다.그리고 보상 함수, 그와 관련된 손실 함수가 있지만 아직 훈련하지 않았습니다.그것은 체스에서이기려고하는 것처럼 행동하지 않을 것입니다. 왜냐하면 그것은 가장 뻔뻔한 예 중 하나와 같기 때문입니다. 단지 합산되지 않습니다.
Ben (01:01:40) :
그리고 분명히 시스템을 훈련시키는 이식 사례가 있습니다. 예를 들어 비디오 게임에서 왼쪽에 녹색 상자가 열리고 오른쪽에 빨간색 상자와 같은 녹색 상자가 열릴 때마다 점수를 얻는다고 가정 해 보겠습니다.왼쪽에 빨간색 상자가 있고 오른쪽에 녹색 상자가있는 새로운 환경에 배치합니다.지금까지 제공 한 교육 데이터는 실제로 구분하기에 충분하지 않으며 실제로 보상을받는 것과 같은 소리를냅니다.빨간색 상자를 열기위한 것입니까, 아니면 왼쪽에있는 상자를 열기위한 것입니까?예를 들어 시스템이 왼쪽의 상자를 열어도 실제로 손실 함수가 아닌 것이 빨간색 상자이거나 그 반대 일지라도 놀라지 않아야합니다.잘못된 방식으로 일반화되는 것은 놀라운 일이 아닙니다.
Ben (01:02:21) :
그래서 저는 일반화 오류가있을 수 있다는 데 확실히 동의합니다.GPT-3와 같은 경우와 같이 왜 결국 발생하는지 알기 위해 고군분투합니다. 저는 기계적으로 무슨 일이 일어날 지, 어디에서 일어날 지 … 그러니 문제가 텍스트이기 때문이라고 가정 해 봅시다.누군가가 읽은 텍스트를 출력하는 생성 시스템은 모든 사람을 죽이는 무언가에 대한 엔지니어링 청사진입니다.이것이 실존 적 위험을 초래하는 비 공상 과학 버전 같은 것이 있는지는 모르겠지만 그것이하는 일이라고합시다.가끔은 거의 … 대답하거나 뭔가를 놓치고있는 것처럼 느껴집니다.하지만이 등급 설계 프로세스가 왜 그렇게하는 정책을 갖게되는지 기계적으로 이해하지 못합니다.왜 그런 방향으로 최적화 될까요?
Jeremie (01:03:06) :
내가 줄 대답은 이것에 대해 충분히 생각하지 않았을 것입니다.그러나 원칙적으로 상상하면 무제한의 컴퓨팅, 무제한의 데이터 확장 등을 가정 해 보겠습니다.이 모델은 생각하기 시작하고 점점 더 많이 생각하고 세상에 대한 더 크고 더 완전한 그림처럼 발전한다고 가정 해 보겠습니다.다시 말하지만, 최적화하려는 대상에 따라 그라디언트를 최소화하기 위해 최적화하려고한다고 가정합니다.이것은 매우 과정입니다. 저는 어떻게 든 틀렸다고 생각하지만, 신경망이 걷잡을 때마다 기분이 나쁘다고 상상하는 것이 옳다고 생각합니다.모르겠어요.
Ben (01:03:47) :
기분이 나쁘지만 실제로 말이되지 않는다고 생각합니다.제 생각에는 특정 매개 변수가 있고 무언가를 출력하고 훈련 세트와 비교합니다.그런 다음 불일치에 따라 [들리지 않음 01:04:02] 다른 방향으로 걷어 찼습니다.하지만 실제로 내면이 있다고 생각하지 않습니다… 실제로 기분이 나쁘다는 의미는 없다고 생각합니다.막대기처럼 움찔 거리는 매개 변수가 있습니다.이 사람은 막대기를 들고 불일치 또는 불일치 부족을 기준으로 매개 변수를 다른 방향으로 밀고 결국 어딘가로 끝납니다.
Jeremie (01:04:23) :
네.그래서 이것은 그 자체로 가장 멋진 측면 중 하나라고 생각합니다.나는 여기서 내면의 정렬 흥분에 산만해질 것입니다.하지만 그것은 정렬 논쟁에서 저에게 가장 멋진 측면 중 하나입니다. 주관적인 경험과 의식에 대해 궁금해하는 지점에 도달하기 때문입니다.“이건 일종의 학습 과정”이라고 말하지 않고 대화를 나눌 방법이 없기 때문입니다.그리고 학습 과정은 인간과 같은 인공물을 생성하는 경향이 있습니다. 그것은 기본적으로 모든 생명체와 같은 주관적인 경험을 가지고있는 것처럼 보이는 뇌입니다.아메바를보고 현미경으로 움직일 수 있습니다.서로 다른 방식으로 다른 순간에 고통과 기쁨을 경험하는 것 같습니다.
Jeremie (01:05:02) :
어쨌든 유사하게 해석 될 수있는 방식으로 작동하는 이러한 시스템을 보는 것은 적어도 실제 Mesa-objective, 최적화 프로그램이 실제로 개선하려는 기능 및 주관적인 경험 사이의 연결 고리가 무엇인지에 대한 질문을 불러 일으 킵니다.나는 거의 잘 이해하지 못하는 영역으로 가고 있습니다.그러나 아마도 나는 생각을 떠날 수 있습니다. 이것은 또한 문제의 정말 흥미롭고 흥미로운 측면이라고 생각합니다.의식과 주관적 경험이 이러한 기계의 맥락에서 연구 할 역할을한다고 생각하십니까?아니면 당신은-
Ben (01:05:44) :
I think not so much of that. There’s a difficulty here where there’s obviously the different notions of consciousness people use. So I guess I predominantly think of it in I guess the David [inaudible 01:05:55] sense of conscious experience as this at least hypothesized phenomenological thing that’s not intrinsically a part of the… It’s not like a physical process, so it’s not a description of how something processes information. It’s an experience that’s layered on top of the mechanical stuff that happens in the brain. Whereas if you’re illusionist, you think that there is no such thing as this, and this is like a woo-woo thing. But I guess for that notion of consciousness, it doesn’t seem in a sense very directly relevant because it doesn’t actually have the weird aspects of it. It’s by definition or a hypothesis, not something that actually physically influences anything that’s happened somewhat behaviorally. And you could have zombies where they behave just the same way, but they don’t have this additional layer of consciousness on the top.
Ben (01:06:44):
So that version of consciousness, I don’t see as being very relevant to understanding how machine learning training works or how issues on MACE optimization work. And maybe there’s mechanistic things that people sometimes refer to using consciousness, which I think sometimes has to do with the information system. Somehow having representations of themselves is maybe one traits that people pick out sometimes when they use the term consciousness. It seems like maybe some of that stuff is relevant or maybe beliefs about what your own goals are, this sort of thing. Maybe this has some interesting relationship to optimization and human self-consciousness and things like that. So I could see a link there, but I guess this is all to say it depends a bit on the notion of consciousness that one has in mind.
Jeremie (01:07:38) :
아뇨, 완벽합니다.그리고 이러한 것들이 경제학에서 의식 이론, 정신 이론에 이르기까지 다양한 분야와 얼마나 많이 겹치는 지 흥미 롭습니다.통찰력을 공유 해주셔서 감사합니다, Ben, 정말 감사합니다.흥미로운 작업을하고 있다고 생각하기 때문에 사람들이 작업을 확인할 수 있도록 공유하고 싶은 Twitter 또는 개인 웹 사이트가 있습니까?
Ben (01:07:57):
네.그래서 개인 웹 사이트가 거의 없지만 제가 참고하는 논문이 몇 개 있습니다.benmgarfinkel.com입니다.트위터 계정이 있지만 트윗을 한 적이 없습니다.내 사용자 이름이 뭔지 잊어 버렸습니다.하지만 그걸 찾아서 팔로우하고 싶다면 언젠가 그로부터 트윗을 올릴 수 있습니다.
Jeremie (01:08:15) :
그것은 설득력있는 피치입니다.그러니 여러분, Ben이 트윗 할 가능성을 살펴보세요.
Ben (01:08:22) :
지금 당장 1 층에 오시면 저의 트윗을 가장 먼저 본 사람이 될 수 있습니다.
Jeremie (01:08:27) :
그들은 씨앗에서 그것을 얻고 있습니다.지금은 시드 단계를 투자 할 때입니다.대박.고마워요, 벤.나는 Twitter를 포함하여 두 가지 모두에 링크 할 것입니다.
Ben (01:08:36) :
추가 된 트위터 팔로워를 기대합니다.
Jeremie (01:08:40) :
There you go. Yeah. Everybody, go and follow Ben, check out his website. And I’ll be posting some links as well in the blog post that will accompany this podcast just to… Some of the specific papers and pieces of work that Ben’s put together that we’ve referenced in this conversation because I think there’s a lot more to dig into there. So Ben, thanks a lot. Really appreciate it.
Ben (01:08:56) :
정말 고마워.정말 재미있는 대화였습니다.