
자동 오픈 소스 기반 데이터 파이프 라인?구조로 openshift!
Kubernetes는 새로운 운영 체제이며 아무도 더 이상 그것을 의심 할 수 없습니다.마이크로 서비스 접근 방식을 개발하고 쿠베르 네스쪽으로 작업 부하를 마이그레이션하기 위해서는 조직이 데이터 서비스를 남겨 두었습니다.
우리 모두는 Covid-19, 중요한 데이터가 얼마나 중요한지, 적절한 아키텍처 및 데이터 원단을 갖는 것이 얼마나 중요한지.데이터가 성장하지 못하지 않을 것입니다!더보기 다른 일 이후에는 소비 기록을 계속해서 해결할 것입니다.
이 챌린지의 힘에스우리는 모든 마법이 일어나는 쿠베르넷으로 데이터 서비스를 옮겨서 우리의 데이터 서비스를 이동시켜 조직에보다 자동 및 확장 가능한 해결책을 제공합니다.Kubernetes는 건강 검진, 주 보존, 자동 조종사 등을 사용하여 Day-1 및 Day-2 작업을 모두 관리하는 데 도움이되는 운영자를 제공합니다.
이 데모에서는 모든 openshift 설치에서 제공되는 운영자를 사용하여 자동 데이터 파이프 라인을 실행하는 방법을 보여주고 싶습니다.운영자 허브…에나는 취하기로했다실시간 BI.사용 사례 로서이 데모를 구축하십시오.이 데모는 확장 가능한 kubernetes 기반 데이터 파이프 라인을 만들고 이러한 요구 사항을 충족시키기 위해 모든 분류 표준 제품을 사용하기 위해 openshift의 메커니즘을 활용합니다.모든 운영자는 OpenShift 컨테이너 저장소가 오브젝트 및 블록 스토리지 프로토콜 모두에 대해 기본 스토리지 솔루션을 제공하는 동안 모든 연산자가 배포됩니다.
이 데모는 사용자의 동작을 기반으로 이벤트를 생성하는 음악 스트리밍 응용 프로그램을 배포합니다 (추가 추가).
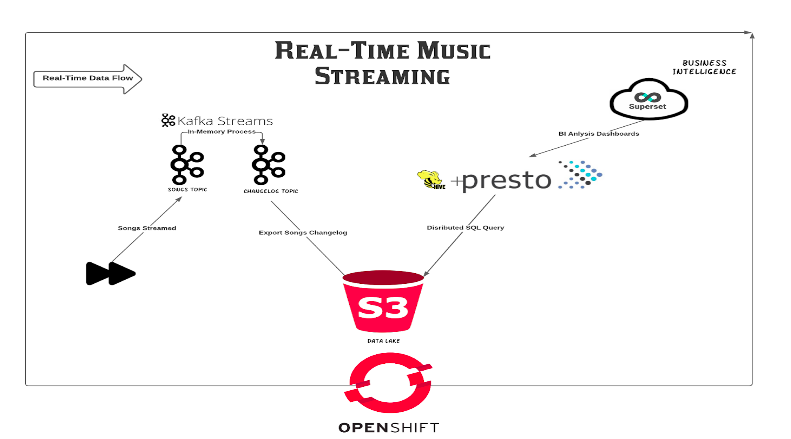
생성되는 데이터를 사용하여 대시 보드 및 시각화를 만들려면 오픈 소스 도구를 사용하고 이해 관계자에게 데이터 과학자가 중요한 데이터를 시각화하는보다 신뢰할 수있는 방법으로 제공됩니다.
이것은 비즈니스 논리에 직접 영향을줍니다!
이제 메시지가 분명 해지려고 해보자!
전제 조건
- 실행중인 Ceph 클러스터 (& gt; rrcs4)
- 실행중인 OpenShift 4 클러스터 (& gt; 4.6.8)
- 외부 모드에서 OCS 클러스터, 오브젝트 및 블록 저장소 모두 제공
설치
모든 리소스를 배포 해야하는 OpenShift 클러스터에서 새 프로젝트를 만듭니다.
$ OC NEW-PROJECT 데이터 - 엔지니어 데모
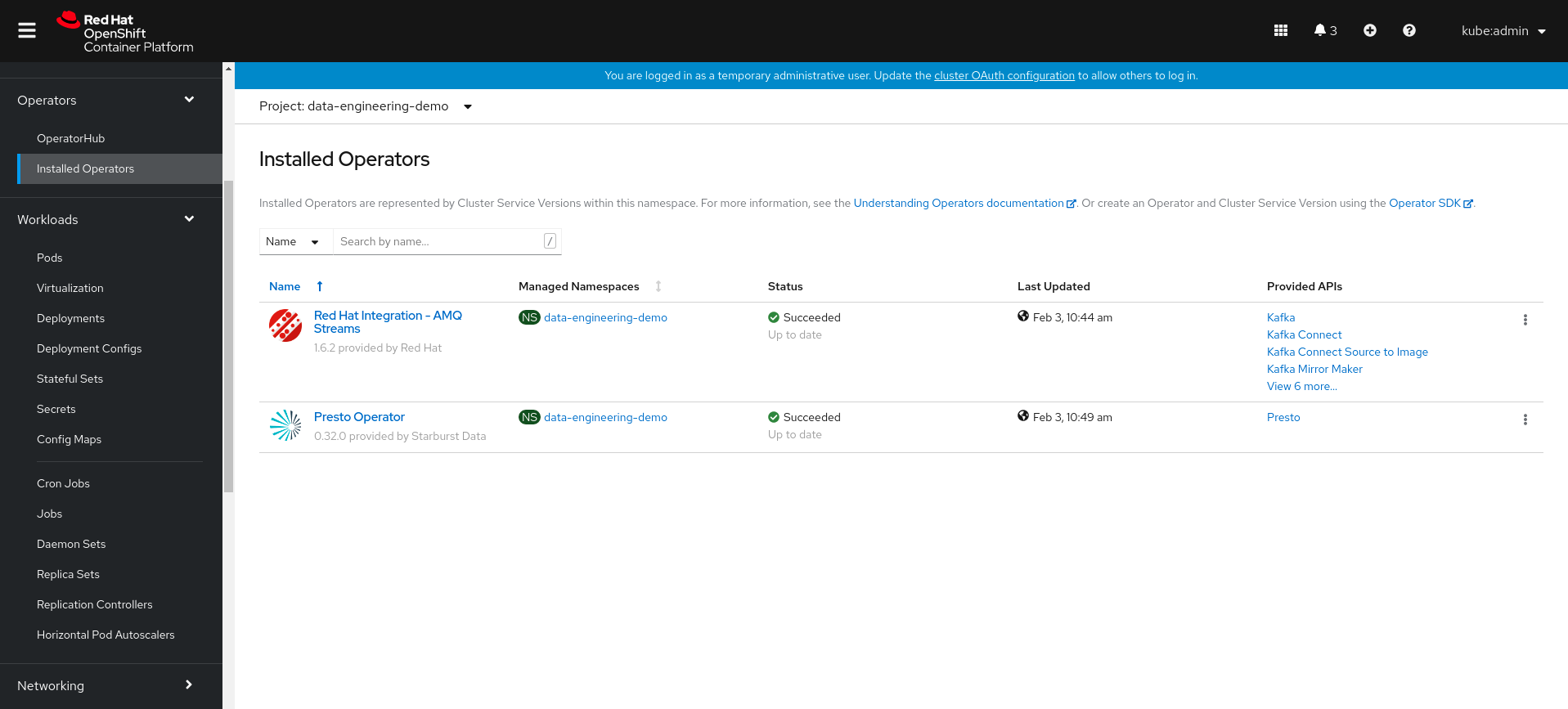
둘 다 설치하십시오amq 스트림과프레스토 악장운영자는 관련 자원을 만드는 것이 필요합니다.그를 가라운영자 허브설치할 왼쪽 패널 섹션 섹션 :
필요한 Git 저장소를 복제하므로 데모를 배포 할 수 있습니다.
$ git clone.https://github.com/shonpaz123/cephdemos.git
디렉토리를 모든 매니페스트가있는 데모 디렉토리로 변경하십시오.
$ CD Cephdemos / 데이터 - 엔지니어링 파이프 라인 - 데모 - OCP
Data Services Preparation
Preparing our S3 environment
이제 모든 전제 조건이 준비되어 있으므로 필요한 S3 리소스를 만들어 시작하겠습니다.우리가 외부 Ceph 클러스터를 사용하는 것처럼 클러스터와 상호 작용하기 위해 필요한 S3 사용자를 만들어야합니다.또한 KAFKA가 이벤트를 데이터 호수로 내보낼 수 있도록 S3 버킷을 만들어야합니다.이러한 리소스를 작성해 봅시다.
$ CD 01-OCS - 외부 -PEPH & AMP; & amp;./run.sh & amp; & amp;CD ..
예상 출력 :
{
"user_id": "데이터 - 엔지니어링 데모",
"display_name": "데이터 - 엔지니어링 - 데모",
"이메일": "",
"일시 중단 된": 0,
"max_buckets": 1000,
"하위저": [],
"키": [
{
"user": "데이터 - 엔지니어링 데모",
"access_key": "hc8v2pt7hx8zfs8nq37r",
"secret_key": "y6cenkxozddikjhqgkblfm38mukbnmwbsa1dxyu"
}
...에
...에
...에
}
make_bucket : 음악 차트 - 노래 - 상점 - 변경
스크립트는 사용합니다Awscli.자격 증명을 환경 변수로 내보내려면 버킷을 올바르게 만들 수 있습니다.이 스크립트가 제대로 작동하도록 모든 열린 포트가있는 엔드 포인트 URL에 액세스 할 수 있는지 확인하십시오.
Kafka New-ETL을 배포합니다
이제 S3 준비가되어 있으므로 필요한 모든 KAFKA 리소스를 배포해야합니다.이 섹션에서는 KAFKA 클러스터를 배포하여amq 스트림조작자, 그 사람을 통해 제공됩니다OpenShift 연산자 허브…에또한 기존 주제 이벤트를 S3 버킷으로 내보내려면 KAFKA 주제와 KAFKA 연결을 배포합니다.중대한!Endpoint URL을 변경해야합니다. 그렇지 않으면 Kafka Connect가 성공없이 이벤트를 노출하려고합니다.
이러한 자원을 만들려면 스크립트를 실행하십시오.
$ CD 02-KAFKA & amp; & amp;./run.sh & amp; & amp;CD ..
이제 모든 포드가 성공적으로 생성되었는지 확인하겠습니다.
$ oc 포드 가져 오기
이름 준비 상태가 나이를 다시 시작합니다
amq-streams-cluster-operator-v1.6.2-5B688F757-VHQCQ 1/1 러닝 0 7H35M
My-Cluster-Entity-operator-5dfbdc56bd-75bxj 3/3 러닝 0 92S
my-cluster-kafka-0 1/1 러닝 0 2m10s
my-cluster-kafka-1 1/1 러닝 0 2m10s
my-cluster-kafka-2 1/1 러닝 0 2m9s
my-cluster-zookeeper-0 1/1 러닝 0 2M42S
my-connect-cluster-connect-7BDC77F479-VWDBS 1/1 실행 0 71S
PRESTO-OPERATOR-DBBC6BC6BC6B78F-M6P6L 1/1 러닝 0 7H30M
우리는 모든 포드가 실행중인 상태에 있고 프로브를 통과 했으므로 필요한 주제를 확인하겠습니다.
$ oc kt를 얻으십시오
이름 클러스터 파티션 복제 계수
Connect-Cluster-Configs My-Cluster 1 3
연결 클러스터 - 오프셋 My-Cluster 25 3
연결 클러스터 - 상태 My-Cluster 5 3
소비자 - 오프셋 --- 84E7A678D08F4BD226872E5CDD2EB527FADC1C6A My-Cluster 50 3
음악 차트 - 노래 - 상점 - 변경 로그 내 클러스터 1 1
연주 - 노래 My-Cluster 12 3.
노래 My-Cluster 12 3.
이러한 주제는 스트리밍 응용 프로그램에서 S3 버킷으로 적절한 형식으로 이벤트를 수신, 변형 및 내보내기 위해 사용됩니다.결국, 주제음악 차트 - 노래 - 상점 - 변경 로그최종 구조로 모든 정보를 보유하므로 쿼리 할 수 있습니다.
분산 쿼리를 위해 Presto를 실행합니다
이 데모에서는 Presto의 S3 버킷 접두사 (관계형 데이터베이스의 테이블과 유사)를 쿼리하는 Presto의 기능을 사용할 것입니다.PRESTO는 생성 할 스키마가 필요합니다.이 예에서는 S3 버킷으로 내보내는 모든 이벤트를 쿼리 해야하는 파일 구조가 무엇인지 이해하기 위해 다음과 같습니다.
{ "count": 7, "songname": "좋은 나쁜 것과 추악한"}
각 파일은 JSON 구조로 내보내집니다. 이는 두 개의 키 값 쌍을 보유합니다.강조하기 위해, 당신은 그것을 테이블로 생각할 수 있으며, 첫 번째 열이있는 두 개의 열이있는카운트두 번째는노래 제목양동이에 쓰여지는 모든 파일은이 구조로 행이 있습니다.
이제 우리는 데이터 구조를 더 잘 이해 했으므로 Presto 클러스터를 배포 할 수 있습니다.이 클러스터는 스키마 메타 데이터를 저장하는 하이브 인스턴스 (스키마 정보를 저장하는 게시물이있는 경우)와 코디네이터 및 작업자 포드가 포함 된 PRESTO 클러스터를 저장합니다.해당 모든 자원은 OpenShift 운영자 허브의 일부로 제공되는 Presto 연산자가 자동으로 생성됩니다.
스크립트를 실행하여 해당 리소스를 만드겠습니다.
$ CD 04-PRESTO & AMP; & amp;./run.sh & amp; & amp;CD ..
이제 모든 포드가 성공적으로 생성되었는지 확인하겠습니다.
$ oc get pods |egrep -e "Presto | Postgres"
이름 준비 상태가 나이를 다시 시작합니다
hive-metastore-presto-cluster-576B7BB848-7BTLW 1/1 실행 0 15s
Postgres-68D5445B7C-G9QKJ 1/1 0 77S.
Presto-Coordinator-Presto-Cluster-8F6CFD6DD-G9P4L 1/2 실행 0 15s
PRESTO-OPERATOR-DBBC6BC6B78F-M6P6L 1/1 러닝 0 7H33M
Presto-Worker-Presto-Cluster-5B87F7C988-CG9M6 1/1 0 15S 실행
Visualizing real-time data with Superset
SuperSet은 시각화 도구로 Presto, Postgres 등 많은 JDBC 리소스에서 시각화 및 대시 보드를 제공 할 수 있습니다. Presto는 데이터를 탐색 할 수있는 기능, 사용 권한 및 RBAC를 제어 할 수있는 실제 UI가 없습니다.superset을 사용하십시오.
클러스터에 수퍼 세트를 배포하려면 스크립트를 실행하십시오.
$ CD 05-superset & amp; & amp;./run.sh & amp; & amp;CD ..
이제 모든 POD가 성공적으로 생성되었는지 확인하십시오.
$ oc get pods |그렙 수퍼 세트
superset-1-deploy 0/1 완료 0 72S.
Superset-1-G65XR 1/1 러닝 0 67S.
superset-db-init-6q75s 0/1 완료 0 71S
좋은!모두 잘 갔다!
데이터 논리 준비
모든 인프라 서비스가 준비되면 스트리밍 응용 프로그램 뒤에 데이터 로직을 만들어야합니다.PRESTO는 S3 버킷의 데이터를 쿼리 할 때 PRESTO가 데이터를 쿼리 해야하는 방법을 알 수 있도록 PRESTO가 구조 지식을 제공하는 테이블로서 PRESTO를 만들 수 있습니다.
귀하에게 로그인하십시오프레스토 코디네이터마디:
$ oc rsh $ (oc get pods | grep 코디네이터 | grep 실행 | awk '{$ 1}')
하이브 카탈로그로 작업하려면 컨텍스트를 변경하십시오.
$ presto-cli --catalog hive.
스키마를 만들어 Presto를 사용하여S3A.커넥터 S3 버킷 접두사에서 데이터를 조회하려면 다음을 수행하십시오.
$ schema hive.songs (location = 's3a : //music-chart-songsore-changelog/music-chart-songs-store-changelog.json/');
스키마 컨텍스트를 변경하고 테이블을 만듭니다.
$ USE HIVE.SONGS;
$ 테이블 곡 (count int, songname varchar)을 사용하여 (format = 'json', external_location = 's3a : //music-chart-songsstore-changelog/music-chart-songsore-changelog.json/');
주의하십시오!테이블 작성 이전 섹션에서 보았 듯이 각 파일의 구조에 대한 실제 지식을 Presto를 제공합니다.이제 S3 버킷을 쿼리하려고 시도하십시오.
곡에서 $ 선택 *
카운트 |노래 제목
------- + -------------
(0 행)쿼리 20210203_162730_00005_7HSQI, 완료, 1 노드
분할 : 17 합계, 17 완료 (100.00 %)
1.01 [0 행, 0b] [0 행 / S, 0b / s]
우리는 데이터가 없으며 괜찮습니다!우리는 모든 데이터를 스트리밍하기 시작하지 않았지만 PRESTO가 S3 서비스에 액세스 할 수 있음을 의미합니다.
실시간 이벤트 스트리밍
이제 모든 리소스가 사용할 준비가되었으므로 마침내 스트리밍 응용 프로그램을 배포 할 수 있습니다!우리의 스트리밍 응용 프로그램은 실제로 미디어 플레이어를 시뮬레이션하는 KAFKA 생산자이며, 미디어 플레이어가 무작위로 “재생”되는 노래 목록이 미리 정의 된 목록이 있습니다.사용자가 노래를 재생할 때마다 이벤트가 KAFKA 주제로 보내집니다.
그런 다음 데이터를 원하는 구조로 변환하기 위해 KAFKA 스트림을 사용하고 있습니다.스트림은 KAFKA로 전송되는 각 이벤트를 가져 와서 변형하고 다른 주제로 작성하여 자동으로 S3 버킷으로 내 보냅니다.
배포를 실행합시다.
$ CD 03 - 음악 차트 - 앱 및 amp; & amp;./run.sh & amp; & amp;CD ..
모든 포드가 실행 중인지 확인합시다플레이어 앱포드는 우리의 미디어 플레이어이며,음악 차트포드는 실제로 모든 KAFKA 스트림 로직을 보유하고있는 포드입니다.
$ oc get pods |egrep -e "플레이어 | 음악"
음악 차트 -576857C7F8-7L65X 1/1 러닝 0 18s.
Player-App-79FB9CD54F-BHTL5 1/1 러닝 0 19S
그를 살펴 보겠습니다플레이어 앱로그 :
$ oc 로그 플레이어 -POP-79FB9CD54F-BHTL52021-02-03 16 : 28 : 41,970 정보 [org.acm.playsongsgenerator] (RXComputationThreadPool-1) 노래 1 : 나쁜 것과 추악한 연주.
2021-02-03 16 : 28 : 46,970 정보 [org.acm.playsongsGenerator] (RXComputationThreadPool-1) 노래 1 : 나쁜 것이 좋고 추악한 연극.
2021-02-03 16 : 28 : 51,970 정보 [org.acm.playsongsgenerator] (RXComputationThreadPool-1) 노래 2 : 믿어.
2021-02-03 16 : 28 : 56,970 정보 [org.acm.playsongsGenerator] (RXComputationThreadPool-1) 노래 3 : 여전히 당신이 연주했습니다.
2021-02-03 16 : 29 : 01,972 Info [org.acm.playsongsGenerator] (RXComputationThreadPool-1) 노래 2 : 믿어.
2021-02-03 16 : 29 : 06,970 정보 [org.acm.playsongsgenerator] (RxComputationThreadPool-1) 노래 7 : Run에서 Fox가 연주되었습니다.
우리는 노래가 재생 될 때마다 데이터가 무작위로 쓰여지는 것을 알 수 있습니다. 이벤트가 KAFKA 주제로 보내집니다.자, 우리를 살펴 보겠습니다음악 차트로그 :
$ OC 로그 음악 차트 -576857C7F8-7L65X.[KTable-Tostream-0000000006] : 2, PlayedSong [Count = 1, SongName = 믿음]
[KTable-Tostream-0000000006] : 8, PlayedSong [Count = 1, SongName = Perfect]
[KTABLE-TOSTREAM-0000000006] : 3, PlayedSong [Count = 1, SongName = 아직도 당신을 사랑합니다]
[KTABLE-TOSTREAM-0000000006] : 1, PlayedSong [Count = 1, SongName = 좋음 및 추악한 선량]
[KTable-Tostream-0000000006] : 6, PlayedSong [Count = 1, SongName = 알 수 없음]
[KTABLE-TOSTREAM-0000000006] : 3, PlayedSong [Count = 2, SongName = 아직도 당신을 사랑합니다]
[KTable-Tostream-0000000006] : 5, PlayedSong [Count = 1, SongName = 때로는]
[KTable-Tostream-0000000006] : 2, PlayedSong [Count = 2, SongName = 믿음]
[KTABLE-TOSTREAM-0000000006] : 1, PlayedSong [Count = 2, SongName = 나쁜 것과 추악한 선량]
우리는 데이터가 성공적으로 변환되고 있으며 사용자가 더 많은 노래를 재생할 때 카운트 번호가 증가합니다.
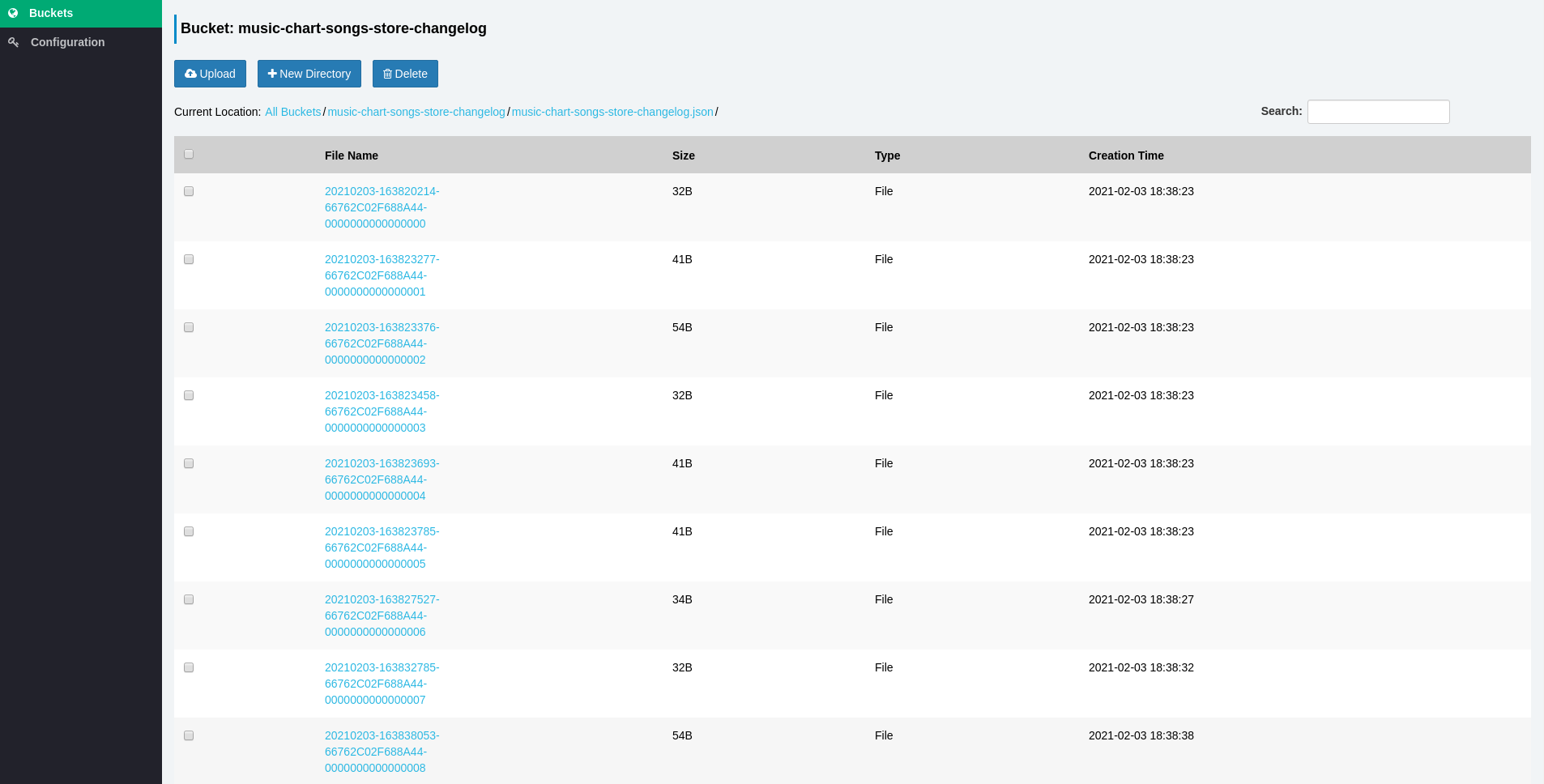
이제 우리는 파이프 라인이 작동하는지 확인해야하므로 모든 이벤트가 성공적으로 내보내는 것을 확인하기 위해 S3 서비스를 보내야합니다.이 목적을 위해 나는 사용했습니다시체S3 브라우저로.올바른 자격 증명 및 엔드 포인트 URL을 사용하고 있는지 확인하십시오.
Presto Coordinator Pod으로 돌아가서 데이터를 다시 쿼리하십시오.
$ PRESTO & GT;PRESTO-CLI --CATALOG HIVE.
$ PRESTO : 노래 & gt;hive.songs를 사용하십시오;
데이터를 가져 오려면 SQL 쿼리를 실행하십시오.
곡에서 $ 선택 *
카운트 |노래 제목
--------------------------------------------------------
1 |보헤미안 랩소디
4 |아직도 너를 사랑해
1 |나쁜 것이 좋고 못생긴 것
3 |믿다
1 |완전한
1 |때때로
2 |나쁜 것이 좋고 못생긴 것
2 |보헤미안 랩소디
3 |아직도 너를 사랑해
4 |때때로
2 |알 수없는 것으로
4 |믿다
4 |알 수없는 것으로
2 |때때로
5 |아직도 너를 사랑해
3 |나쁜 것이 좋고 못생긴 것
놀랄 만한!우리는 데이터가 자동으로 업데이트되고 있음을 알 수 있습니다!이 명령을 몇 번 이상 실행하면 행 수가 자라는 것이 표시됩니다.이제 데이터 시각화를 시작하려면 Superset 경로를 찾으십시오. 여기서 콘솔에 로그인 할 수 있습니다.
$ oc 루트를 얻으십시오이름 호스트 / 포트 경로 서비스 포트 종단 와일드 카드
Superset superset-data-engineering-demo.apps.ocp.spaz.local superset 8088-tcp 없음
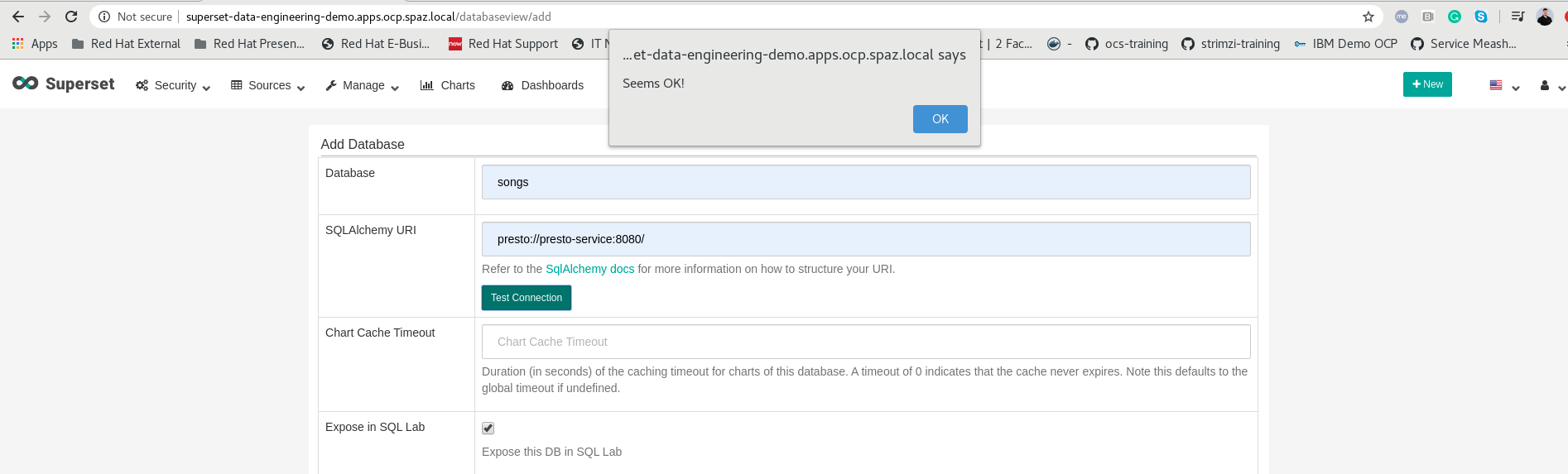
우리가 우리의 Superset 콘솔에 도달하면 (로그인하십시오관리자 : 관리자), 우리는 우리가 갈 수 있음을 알 수 있습니다.데이터베이스 관리– & gt;데이터베이스 만들기Preto 연결을 만들려면 Presto의 클러스터 서비스 이름을 입력했는지 확인하십시오. 마지막으로 연결을 테스트하십시오.
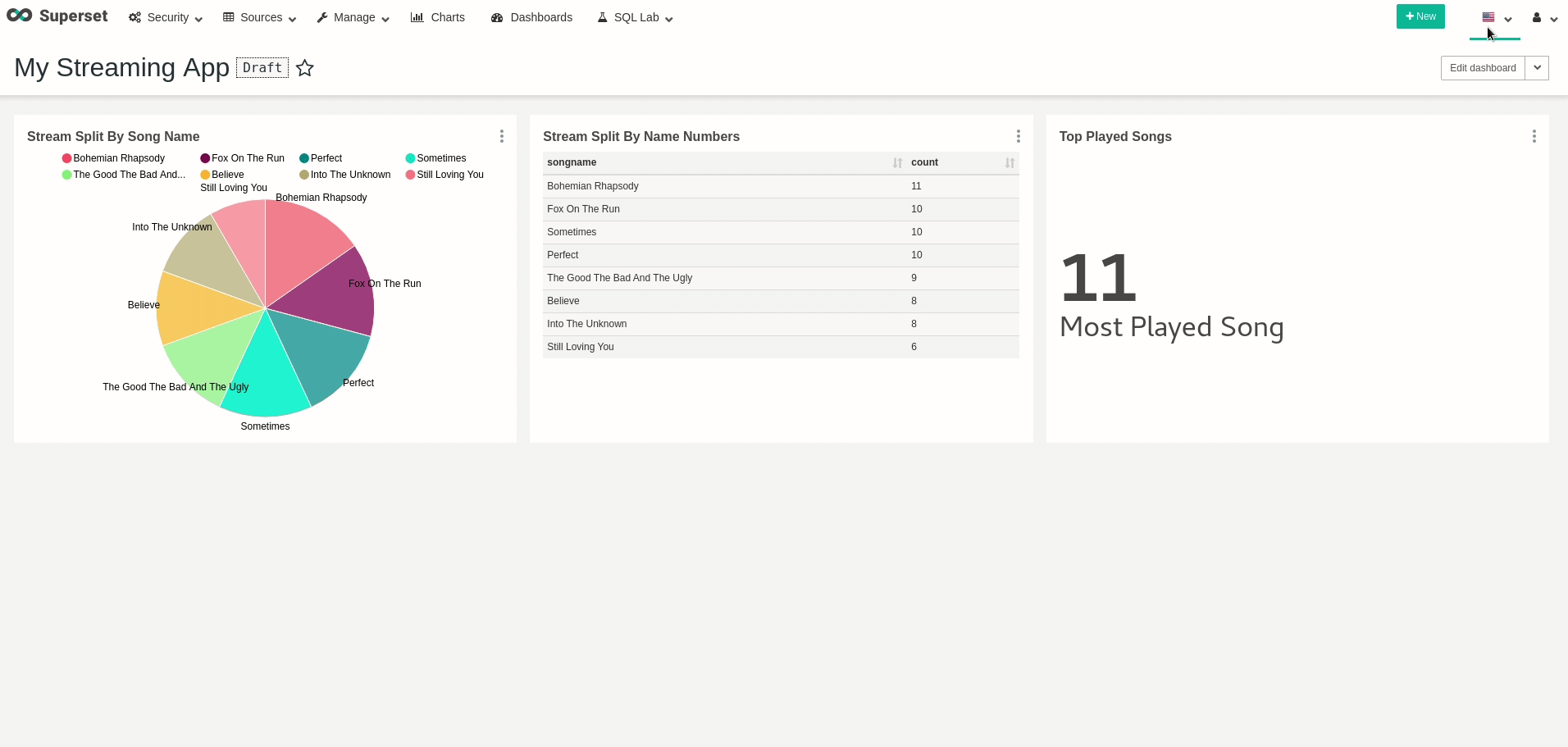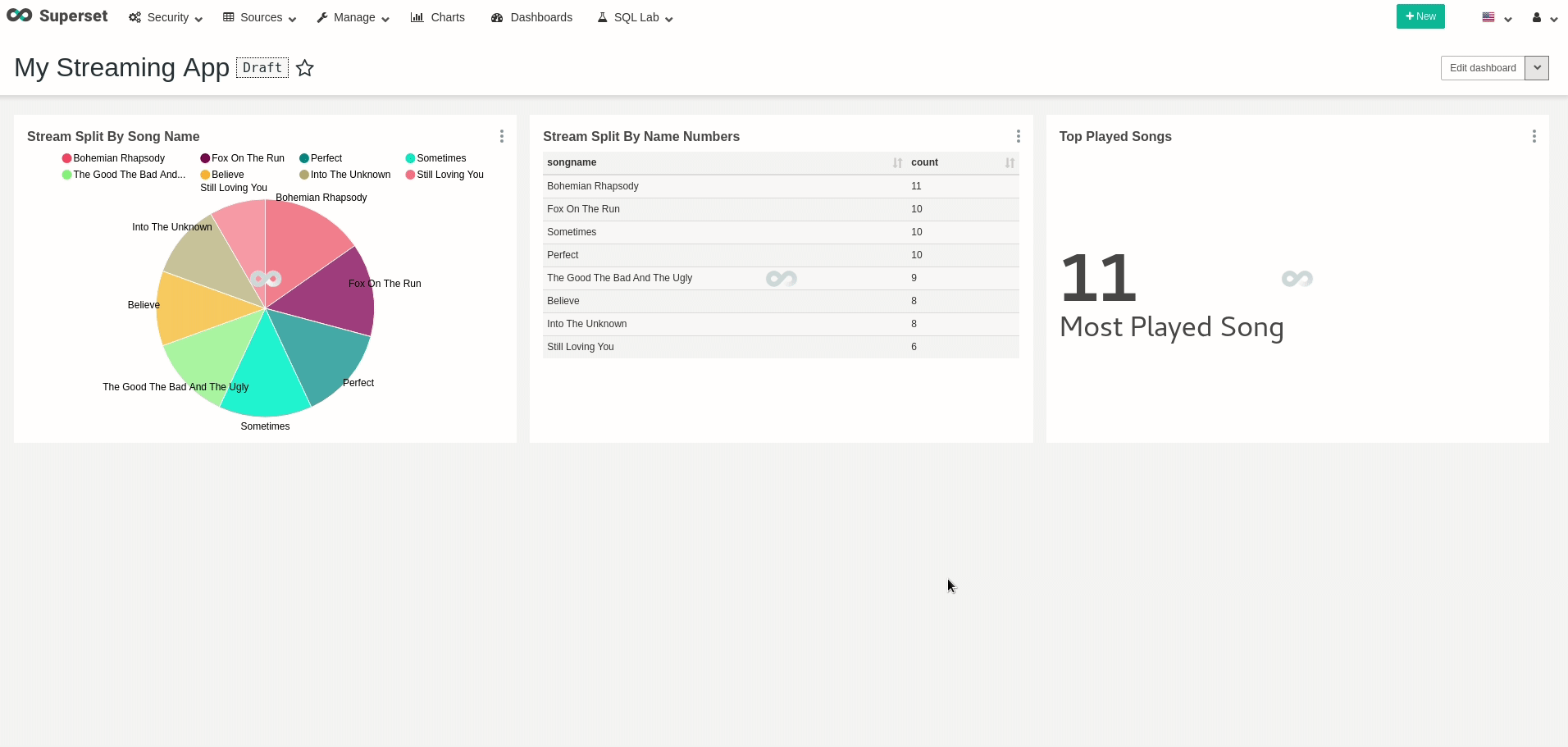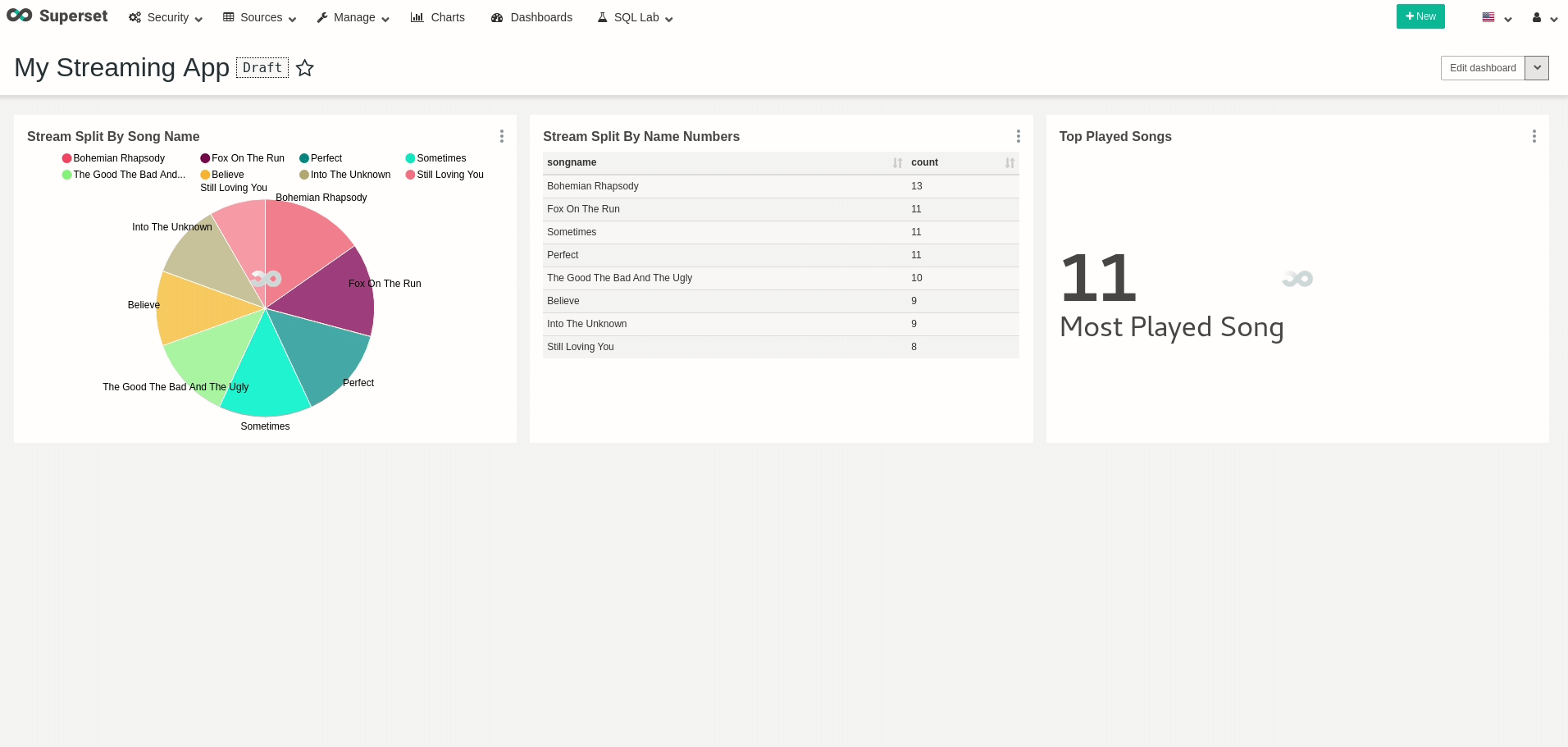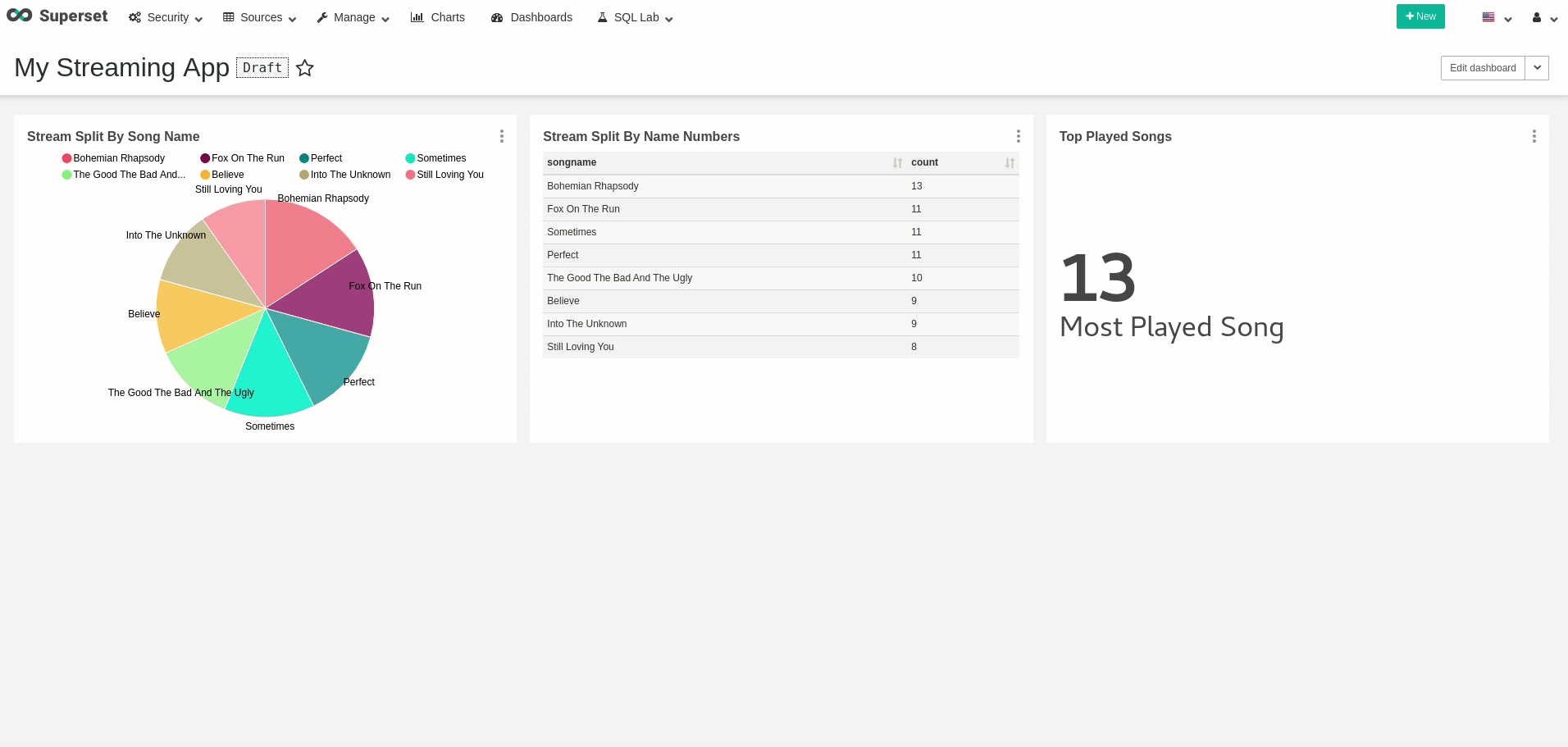
이제 데이터를 쿼리하는보다 편리한 방법을 가질 수 있으므로 데이터를 조금 탐색 해보자 시도 해보십시오.이동SQL LAB.및 이전 쿼리를 수행 할 수 있음을 확인하십시오.강조하기 위해 다음 쿼리를보고 각 노래가 얼마나 많은 시간을 보냈는지 보여줍니다.
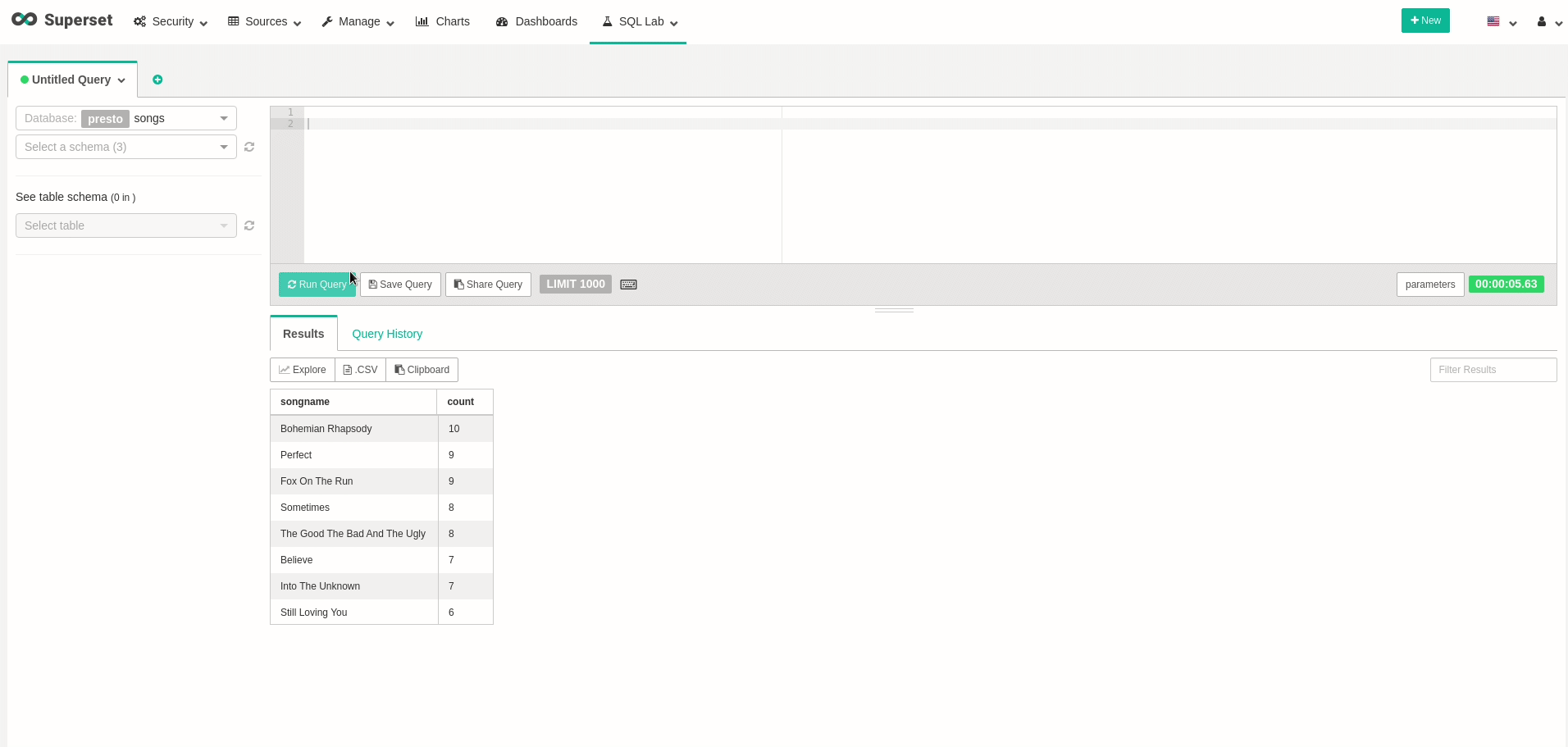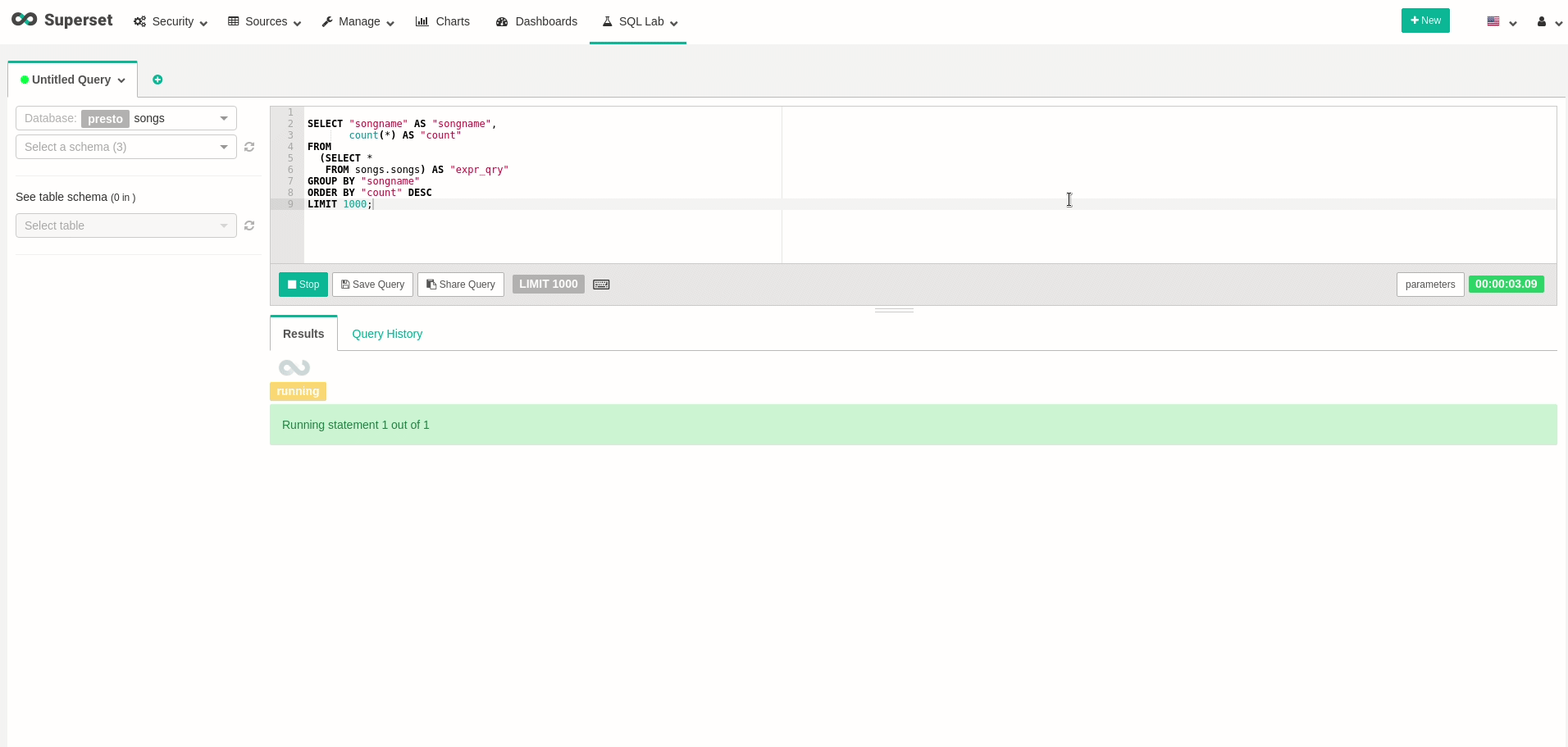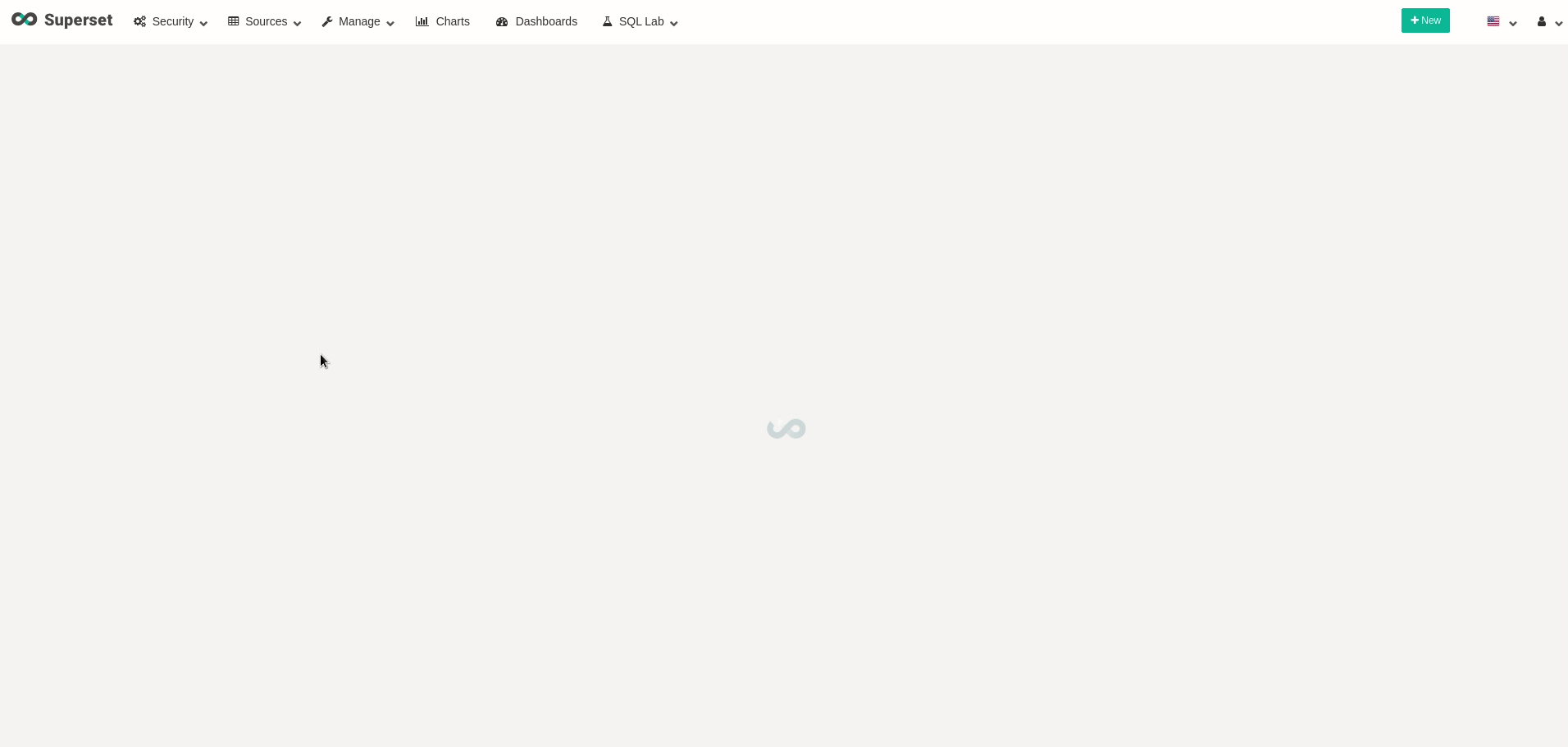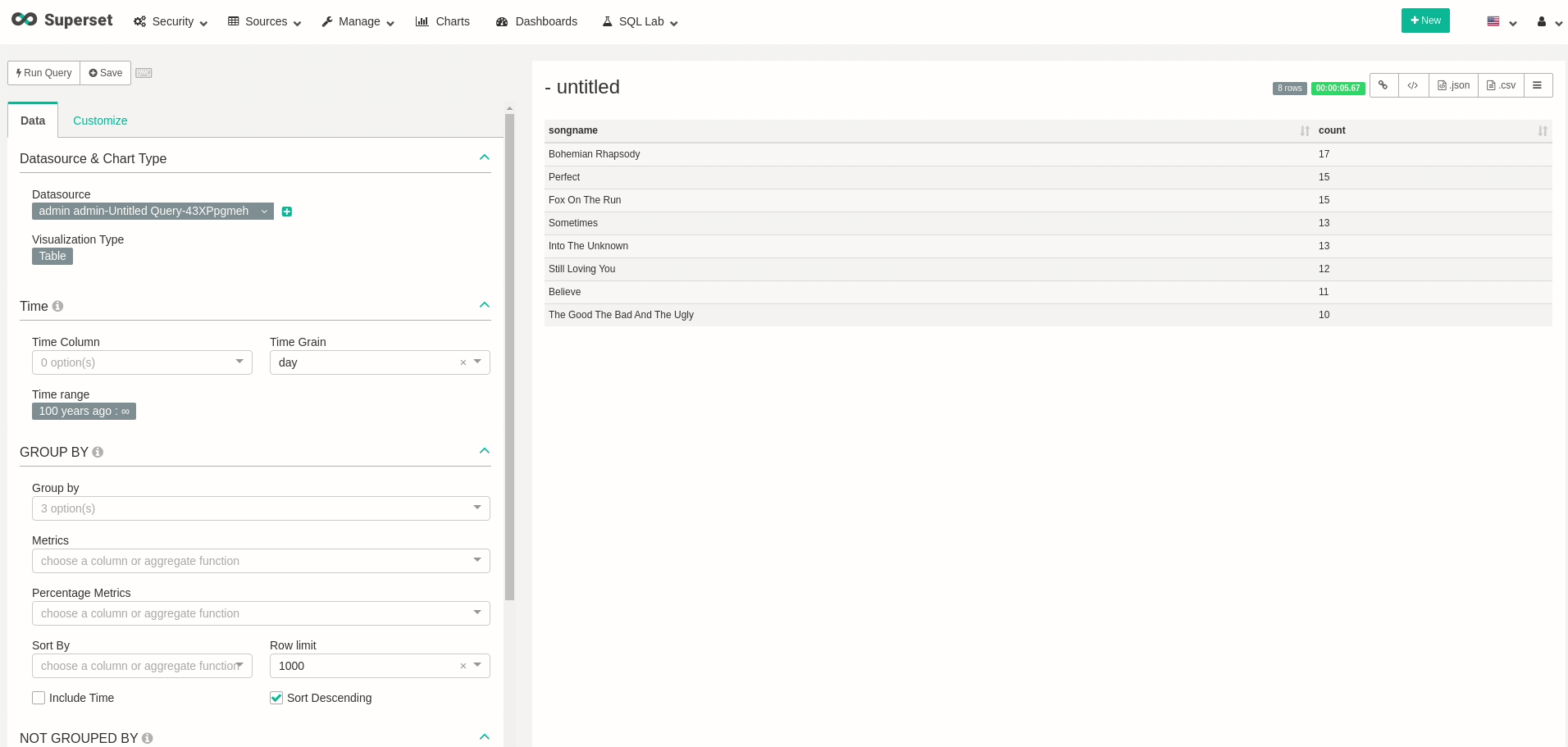
좋은!데이터를 쿼리 할 수 있습니다!원하는 시각화와 대시 보드를 자유롭게 만들 수 있습니다.예를 들어, 대시 보드의 모든 새로 고침을 실제로 다시 쿼리 할 때 실시간으로 변경되는 대시 보드를 만들었습니다.
결론
이 데모에서는 OpenShift에서 예정된 모든 데이터 파이프 라인을 실행하기 위해 오픈 소스 제품을 활용할 수있는 방법을 보았습니다.kubernetes가 채택 기록을 끊으므로 조직은 쿠베르 라이트쪽으로 작업 부하를 움직이는 것을 고려해야하므로 데이터 서비스가 뒤에 남겨지지 않을 것입니다.Red Hat 및 Partner Operators를 사용하여 OpenShift는 Day-1 및 Day-2 관리를 데이터 서비스로 제공합니다.
이 블로그 게시물을 읽어 주셔서 감사합니다, 다음에 YA를 참조하십시오 🙂