
ATP 테니스 클러스터 분석
클러스터 분석을 사용하여 테니스 경기 스타일 분할
최근 몇 년 동안 거의 모든 스포츠가 분석 혁명의 일부였습니다.publi로 밀어씨스카우트에 대한 수학 접근 방식을 개척 한 오클랜드 A의 GM 빌리 빈의 이야기 인 ‘머니 볼’과 함께 분석은 모든 종류의 스포츠에 널리 퍼져 있습니다. 3 점 혁명의 농구, ” BigData Bowl “은 Michael Lopez가 운영하고 있으며 리버풀이 분석 분야에서 리그 리더가되어 리그 우승을 지원 한 프리미어 리그까지도 이어졌습니다 .¹ 야구는 1 대 1 매치업, 투수 대 타자, 개별 가치를 정량화하고 팀원의 긍정적 인 영향과 부정적인 영향을 분리하는 것이 더 쉽습니다. 1 대 1 상호 작용을 특징으로하는 또 다른 게임 인 테니스에서도 유사한 혁신이 일어났다 고 생각할 수 있지만, 테니스는 분석에서 다른 스포츠보다 훨씬 뒤처졌습니다. 최근 테니스 팬들이 노출 된 유일한 고급 분석 측정은 나무 기반 접근 방식에서 승리를 확보하기 위해 각 선수에게 가장 중요한 통계 인 IBM Watson의 ‘경기의 핵심’입니다. 퍼블릭 도메인에서 테니스 분석의 발전은 전적으로 테니스 분석의 Bill James 인 Jeff Sackman에게 기인 할 수 있습니다.
Sackman은 끊임없이 경기 통계를 수집하고 사용자 지정 코딩 절차를 사용하여 경기를 차트로 작성하고 GitHub와 그의 사이트 Tennis Abstract에서 수년간 데이터 세트를 공개했습니다 .² 또한 Novak Djokovic이 그의 팀에 Craig O’Shaughnessy를 설교하는 전략 코치를 추가했을 때 그는 과거에 테니스 분석 열정 프로젝트를 추구 한 사람들에게 스포츠 데이터의 가치를 상징적으로 부양했습니다. 일대일 매치업이 포함 된 다른 게임과 마찬가지로 ELO 점수는 선수의 상대적인 힘을 찾는 데 사용되었습니다 .³ 그러나 테니스를 치른 많은 사람들이 알고 있듯이 테니스는 매치업의 영향을받는 독특한 게임입니다. 6 피트 7 인치의 빅 서버로 대학에서 테니스를 쳤기 때문에,베이스 라인 뒤에 서서 승자가되지 않고 많은 볼을 플레이하는 작은 ‘그라인더’를 상대하는 것이 싫었습니다. 나는 Sackman의 데이터 세트와 K-Means 클러스터 분석을 통해 테니스를 특징 짓는 다양한 플레이 스타일의 패턴을 찾을 수 있고 궁극적으로 어떤 클러스터가 상대방보다 이점이 있는지 결론을 내릴 수 있다고 가정했습니다.
Sackman의 기본 ‘박스 스코어’데이터 세트1968 년까지 거슬러 올라가는 각 경기에 대해 단일 행을 제공합니다. 저는 2011 년부터 파일을 비교적 임의의 시작점으로 분석하기로 선택했지만, 지난 게임이 크게 바뀌었기 때문에 분석 관련성을 유지하기로했습니다. 20 년. 통계는 에이스, 1 차 서브 인, 더블 폴트 등과 같은 메트릭을 사용하여 각 경기에 대한 기본 정보를 제공합니다. 데이터 세트는 포인트가 승자, 강제 또는 비 강제에서 획득 한 경우 랠리 길이와 같은 랠리 메트릭을 제공하지 않습니다. 오류 또는 인터넷에서 이겼는지 여부. 그러나 첫 번째 서브 비율, 획득 한 서비스 포인트 비율, 획득 한 리턴 포인트 비율과 같은 기본 통계는 각 플레이어의 플레이 스타일과 상대적 강점에 대한 통찰력을 제공합니다. 데이터를 Python으로로드 한 후 관련 통계에 대해 null 값이있는 행을 삭제했습니다. 다음으로 각 일치 항목에 대해 두 개의 행을 만들었습니다. 첫 번째 행은 Sackman이 승리 한 플레이어에게 제공하는 고유 ID가있는 승자의 통계로 구성되며 두 번째 행은 패자에 대해 동일한 프로세스를 따릅니다. 이 단계는 두 가지 이유로 필요했습니다. 먼저 통계는 승자와 패자로 구성됩니다 (예 : w_ace는 승자 에이스 열이고 l_ace는 패자 에이스 열). 따라서 각 플레이어에 대한 통계를 도출하기 위해 별도의 매핑을 만들어야했습니다. 결과에 관계없이 경기에 대한 통계와 일치합니다. 둘째, 각 경기 후 첫 번째 서빙 비율과 같은 통계를 계산하는 데 사용할 누계를 계산하기 위해 각 플레이어의 날짜와 ID로 정렬해야했습니다. 데이터에 대한 느낌을 드리기 위해 아래는 ATP 투어 파이널에서 Dominic Thiem과의 마지막 경기 이후 Djokovic의 커리어 서비스 통계 스크린 샷입니다.

각 플레이어의 복귀 게임에 대해 동일한 통계를 계산했습니다. 또한 모든 점수의 퍼센트 및 분당 점수와 같은 일반적인 통계를 계산했습니다. 랠리 길이와 상관 관계가있을 것이라고 생각했기 때문입니다 (위에서 언급했듯이데이터).놀랍게도 노박 조코비치와 같은 선수조차도 점수의 50 %를 이길 수있는 최고 선수와 평균적인 선수 사이에 상대적으로 낮은 분포를 나타내는 55 %의 점수 만 얻습니다.이것은 1 % 개선이 많은 플레이어에게 수십만 달러의 차이가 될 수 있음을 의미합니다.
다음으로 데이터를 표준화하기 위해 Scikit-Learn의 전처리 라이브러리를 활용 한 다음 Scikit-Learn에서 사용할 수있는 미니 배치 클러스터링 기능에 제공했습니다.그래프에서 ‘팔꿈치’를 찾는 동안 2 ~ 10 범위의 다양한 클러스터 크기를 시도했습니다 (4 개의 클러스터에있는 것처럼 보임).’elbow’방법은 최적의 클러스터에 대한 매우 주관적인 측정이지만 내 분석에는 충분했습니다 (클러스터링 검사에 대한 조정이 필요한 경우여기).
클러스터링의 마법은 다시금 성과를 거두었으며 데이터 내에서 네 가지 뚜렷한 연주 스타일을 찾을 수있었습니다. 첫 번째 클러스터는 가장 높은 에이스 비율, 가장 키가 큰 개인 및 가장 높은 첫 번째 서브 승리 확률로 특징 지워졌습니다. 그들은 그들의 점수의 약 50 %를 얻었고 예상되는 하드와 잔디 코트에서 가장 많은 양을 뛰었습니다. 다음 클러스터는 평범한 플레이어를 모으는 것처럼 보였습니다. 백분율로 보면, 그들은 가장 적은 점수를 얻었고, 모든 표면에 약간 균등하게 경기를 펼쳤으며, 가장 적은 수의 경기를 이겼습니다 (38 %). 이 그룹이 가장 큰 그룹 이었지만, 플레이어는 데이터 세트에서 가장 적은 수의 경기를 평균하고 있었는데, 이는 이들이 도전자 투어와 프로 투어 사이를 오가는 플레이어였으며,이를 크게 만들기 위해 고군분투하고 있었음을 의미합니다. 클러스터 크기를 늘리기로 선택하면이 그룹이 더 세분화 된 수준으로 분류 될 것이라고 생각합니다. 다음으로 우리는 테니스 세계에서 최고의 개인 선수를 말하는 또 다른 방법 인 ‘올 코터’를 가지고 있습니다. Federer, Nadal, Djokovic과 같은 플레이어는 클러스터가 총점의 53 %를 획득하고 게임당 최소 브레이크 포인트 기회를 포기하고 두 번째 서브에서 가장 많은 포인트를 획득하기 때문에이 그룹에 속할 가능성이 높습니다. 마지막으로 클레이 코트 그라인더가 있습니다. 그들은 경기의 37 %를 클레이로 플레이하는데 5 %가 가장 높고 첫 서브 비율이 가장 낮고 첫 서브에서 포인트를 얻었지만 게임당 가장 많은 브레이크 포인트를 만들어서 보상합니다. 다음은 각 클러스터에 대한 다양한 요약 통계의 자세한 차트입니다.
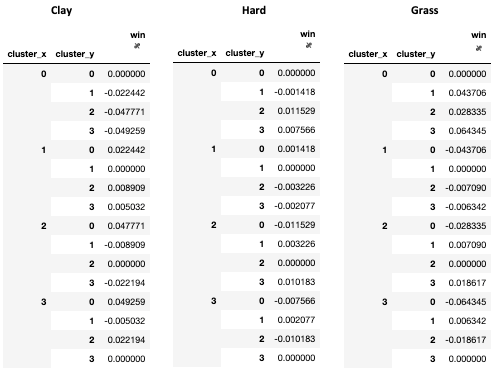
다음으로, 각 코호트별로 서로에 대한 다양한 승률과 다양한 표면을 조사했습니다.
클러스터 2, ‘모든 구애 자’는 관련된 모든 사람과 가장 잘 맞았고 그라인더 게임에 대한 나의 두려움은 실제로 큰 서버가 클러스터 3 서버와의 경기에서 56 %를 이겼 기 때문에 비합리적이었습니다.또한 흥미로운 점은 클러스터 0에있는 사람들이었습니다. ‘빅 히터’는 다른 코호트보다 클러스터 2를 혼란스럽게 할 가능성이 더 큽니다.직관적으로, John Isner 또는 Kevin Anderson과 같은 선수가 자신의 힘이 누구에게도 너무 큰 것처럼 보이는 토너먼트에서 ‘핫’한 것을 보았 기 때문에 이것은 의미가 있습니다.일반적으로 상대를 압도 할 수없고 전술에 의존해야하는 스펙트럼 그라인더의 다른 쪽에서는 결과가 훨씬 더 일관 적입니다.아래는 하드, 클레이 및 잔디에 해당하는 그래프이며, 총 승률 (코트 별 승률 %-총 승률)에 대한 각 그룹의 상대적 우위는 하드 및 잔디 코트에 대한 대형 서버 전문 지식과 클레이에 대한 그라인더 숙련도를 더욱 잘 보여줍니다..
이것이 시작점 역할을하는 동안 Jeff Sackman은 2011 년까지 거슬러 올라가는 그랜드 슬램의 포인트 별 데이터를 발표했습니다.이 데이터는 랠리 메트릭스에 대한 추가 통찰력을 제공 할 것입니다.이 데이터는 클러스터를 더 공격적이고 순 마음이있는 그룹별로 그룹화 할 수 있습니다.베이스 라인에서 10 개 이상의 샷을 랠리하는 콘텐츠.앞으로 몇 주 안에 파트 2에서 찾아보세요.
- Schoenfeld, Bruce.데이터 (및 일부 숨막히는 축구)가 리버풀을 영광의 끝으로 가져온 방법.https://www.nytimes.com/2019/05/22/magazine/soccer-data-liverpool.html
- Sackman, Jeff.Gitbub 홈페이지.https://github.com/JeffSackmann
- 테니스 추상 Elo 등급.http://tennisabstract.com/reports/atp_elo_ratings.html
- Sackman, Jeff.중단 점의 영향 측정.http://www.tennisabstract.com/blog/2019/01/04/measuring-the-impact-of-break-points/