이 기사는 공동 작성되었습니다모세, CEO 및 공동 창업자몬테 카를로, 그리고jit papneja., 글로벌 통찰력 및 amp;코카콜라 회사 인 Johnson & AMP를 포함한 여러 Fortune 100 회사의 분석 리더존슨, 네슬레.
당신은 눈송이와 보더에 있니?큰.그러나 대부분의 회사에서는 클라우드 데이터 스택을 갖는 대부분의 회사에서는 데이터 및 분석을 규모의 데이터와 분석을 작동 할 때 빙산의 일각에 불과합니다.우리는 나눈다5 개의 분명하지 않은로드 블록기업은 데이터가 주도되면 직면하고 업계 최고의 데이터 엔지니어링 및 분석 팀 중 일부가이를 극복하기 위해 수행하는 작업을 강조합니다.
에2021, “데이터 기반”또는 “데이터 먼저”로 여겨지는 회사를 찾으려면 어려워집니다.그러나 대부분의 경우 데이터 분석은 중요한 비즈니스 가치의 혁신적인 원인이 아닌 Buzzword입니다.
비즈니스의 데이터 분석 전략이 완전한 잠재력에 도달하기 위해서는 전체 조직 전체에서 데이터 감사의 문화 및 채택 문화를 구축해야합니다.우리는 분석적 우수성의 방식에 서있는 가장 흔한 도전 중 5 가지를 공유합니다. 그리고 어떻게 그들을 태클 할 수 있는지.
도전 # 1 : 너무 많은 조종사, 너무 적은 이니셔티브가 너무 적습니다.
여러 번, 데이터는 완전히 생산되는 프로젝트가 아닌 조종사 및 실험의 맥락에서 실리콘 문제를 해결하는 데 사용됩니다.이것은 특히 데이터 중심 엔터프라이즈를 구축하는 초기 단계에서는 일반적이지만 나중에보다는 더 빨리 주소 해야하는 지뢰입니다.
너무 많은 조종사는 나머지 회사에서 오해가 발생합니다.이 데이터는 실험을 위해 비즈니스 가치를 창출하지 않습니다.이 지각은 바이 인을 건설하기가 어렵고 데이터 및 분석의 가능한 가치에 대한 공유를 이해하기가 어렵습니다.
가능한 한 신속하게 데이터 및 분석 비전을 전반적인 비즈니스 전략으로 정렬하여 전략적 위치로 이동하십시오.데이터 및 분석 솔루션이 가장 중요한 요소에서 명시 적으로 명시 적으로 전달할 수있는 우선 순위를 식별하고 갇힌 가치를 신속하게 생산하는 것으로 신속하게 이동하여 갇힌 가치를 잠금 해제하는 작업을 수행 할 수 있습니다.
핵심 우선 순위를 확인하면 스스로에게 물어보십시오.데이터 및 분석 솔루션의 목표는 무엇입니까?어떤 비즈니스 질문에 대답하려고합니까?그리고 비즈니스 리더가 귀하의 업무를 기반으로하는 행동을하는 어떤 행동은 무엇입니까?이러한 이니셔티브가 어떤 가치를 창출합니까?
Challenge #2: Organizational bottlenecks
구조화 된 데이터가 잘 갖추어져 있더라도 올바른 팀에 적합한 스킬 세트를 사용하여 올바른 팀을 사용해야합니다.문제를 해결하기 위해 데이터를 해결하기 위해 데이터를 활용하는 방법에 대한 화려한 아이디어를 개발하는 것과 동일한 팀은 해결책을 테스트하고 확장하고 병목 현상을 만들고 데이터 백업 이니셔티브에 대한 신뢰를 침식 할 수 있도록 장비가 없습니다.
이 과제를 해결하기위한 검증 된 접근법은 전용 허브가 전략 및 거버넌스, 인재 관리를 소유하고 있으며 전체 조직 전체가 레버리지를위한 전사적 인 데이터 및 분석 서비스를 제공하는 전용 허브와 함께 “허브 / 스포크”모델을 채택하는 것입니다.
“허브”는 기업에 적합한 기능을 통해 중요한 서비스를 제공하여 비즈니스 가치를 가속화합니다.”Spoke”팀은 기능적 인도 지식, 기능별 기술을 설정하고 기능적 요구와 프로세스를 더 잘 이해할 때 기능 데이터 및 분석 이니셔티브를 기능적으로 실행하고 기능 데이터 및 분석 이니셔티브를 실행합니다.”Spokes”는 “허브”가 설정 한 공통 지침과 원칙을 따르며 “허브”가 챔피언을받은 교차 기능적 엔터프라이즈 넓은 이니셔티브의 채택 및 가치 실현에 대해 책임을집니다.또한 자율적으로 일하는 자신의 정의 된 목표를 가진 자체적으로 일하는 팀의 교차 기능 팀 인 민첩한 배달 분대를 형성해야합니다.각 분대에는 ‘제품 소유자’가 있으며 작업을 완전 순위 지정합니다.
단계를 찍어 조직 구조를 조사하십시오.올바른 도구로 재능이 올바른 믹스와 아이디어를 완전한 생산에 대한 보증을 받기 위해 액세스 할 수 있습니까?분명히 역할과 책임과 일하는 방법을 명확하게 정의 했습니까?팀은 한 팀, 한 팀, 한 목소리로, 한 팀으로 기능합니까?
Challenge #3: Lots of data but little insight
회사는 분석에서 ROI를 향상 시키려고 할 때 데이터 자체는 거의 도움이되지 않습니다. 직원들이 많은 양의 데이터로 인해 의미있는 통찰력을 활용할 수있는 능력입니다.팀은 어떤 목적을 찾을 수 있는지, 어디에서 액세스 할 수 있는지에 사용되는 데이터를 알아야합니다.우리는이 데이터 민주화를 호출합니다.
이 과제를 해결하기 위해 두 가지 주요 최종 목표 직원이 데이터에 대한 단일 진리의 원인을 가져야하며 조직은 오용되거나 낭비되어서는 안되는 전략적, 가치있는 자산으로 데이터를 처리해야합니다.
이것은 간단한 작업이 아닙니다.팀 팀은 공통 데이터 수집 프레임 워크를 구현하고 표준 데이터 거버넌스 프로그램을 도입함으로써 여러 가지 교차 기능 팀을 여러 개를 수행해야합니다.검증 된 데이터 카탈로그 시스템을 구현해야하므로 직원들이 전체 조직에서 공유되는 데이터 세트를 찾고 액세스 할 수 있으며 일상 업무에서 사용할 수있는 신뢰할 수있는 데이터가 있음을 신뢰할 수 있습니다.
큰 업적은 밤새도록 일어나지 않지만 지도자들은 당신의 팀을 보여주는 정보 세션이나 ‘점심 식사’를 호스팅하여 모멘텀을 시작할 수 있습니다.
데이터 민주화로 이동하면서 자신에게 물어보십시오.명확하게 정의 된 데이터 전략이 있습니까?전략을 어떻게 전달하고 전체 조직 내에서 식욕을 구축하여 데이터 및 분석에 대한 공유 접근 방식을 채택 할 수 있습니까?
Challenge #4: Trying to be everything for everyone
기계 학습 및 기타 AI 분야에서는 분석을 생성하고 확장하는 동안 수익성 높은 성장을 위해 강력한 솔루션으로 부상했습니다.그러나 ML과 AI를 채택하기 위해 많은 회사가 서두르므로 데이터 및 분석 리더는 모든 사람을위한 모든 것으로 간주하는 도전과 직면합니다. 새로운 기술과 방법론을 적용 할 수 있는지 여부를 결정하기 위해 멈추지 않아도됩니다.
첫 번째 도전과 비슷합니다.데이터 프로그램에 AI를 소개합니다, 기계 학습 및 기타 자동화 된 솔루션이 가장 효과적 일 수있는 문제를 확인하여 의미있는 비즈니스 성과를 유도합니다.
예를 들어, 심각한 데이터 전략의 필요한 데이터 품질 관리는 종종 상당한 수동 임계 값 설정 및 메타 데이터 항목이 필요합니다.ML-first 접근법엔드 투 엔드 데이터 관찰 가능성,데이터 엔지니어 및 분석가가 Ad Hoc Firefighting 또는 수동 수고와는 달리 실제로 바늘을 움직이는 프로젝트에 집중할 수 있습니다.데이터 팀과 함께 지출그들의 시간의 80 %기업매년 1,500 만 달러 낭비데이터 품질 문제에 따라 데이터 관찰 가능성을 통해 팀은 전체 조직에 데이터를 적용 할 때 거의 데이터 정확성을 높일 수 있습니다.
ML은 또한 우버와 같은 예측을하는 데 사용됩니다.그 드라이버를 지시합니다수요가 급증하거나 Airbnb의 방법에 관한 지역으로수익을 극대화 할 수있는 가격을 추천합니다동적 시장에서.모든 경우에, 예측의 품질은 기계 학습 모델을 훈련시키는 데 사용되는 데이터의 품질에 전적으로 의존합니다.
사용자 정의 모델을 작성하려는 경우 먼저 프로젝트 정의를 수행 할 수있는 충분한 데이터가 있는지 확인하고 재생할 가능성이있는 잠재적 인 편향을 알고 있어야합니다.
AI와 ML을 활용하기 전에 다음과 같이 답하십시오.우리의 데이터 세트는 수동 감독을 제거하기에 충분하고 정확하게 정확합니까?바이어스가 연주 될 수있는 점을 확인 했습니까?감지하고 수정하는 방법그들?다시 말하지만, 이것은 데이터 관찰 가능성에 대한 강력한 접근 방식이 도움이 될 수있는 곳입니다.
Challenge #5: Security, privacy, and governance
항상 그렇듯이 보안 및 개인 정보는 데이터 프로그램의 성공에 영향을 미치는 영향을 미칩니다.사일로를 분해하고 데이터에 대한 액세스를 늘리기 위해 작업하는 경우 모든 액세스 포인트 및 파이프 라인을 포함한 데이터가 안전하게 해당 데이터가 안전합니다.
오른쪽 데이터 거버넌스 접근 방식을 일찍 켜고 장기적인 목표와 결과를 염두에두고 시간이 지남에 따라 분석을보다 쉽게 구현하고 확장하는 데 도움이됩니다.전체 데이터 스택을 포함하여야합니다창고,카탈로그및 BI 플랫폼은 데이터 거버넌스를 준수합니다.가이드 라인귀하의 회사, 산업 및 지역.
이러한 모든 과제는 모두 중요하지만, 범위가 아닙니다.이러한 모범 사례, 전략적 비전 및 올바른 기술을 통해 데이터 분석 프로그램은 모든 비즈니스 단위에서 의미있는 변화를 주도 할 수 있으며 수년간 힘 곱셈기가됩니다.
귀하의 회사에서 데이터 분석 전략을 구현 하시겠습니까?우리는 모두 귀입니다!도달하다모세또는jit papneja.…에
우리가 무엇을 위해 우리가 무엇인지에 대해 자세히 알아 보려면몬테 카를로회사가 이러한 병목 현상을 극복하고 신뢰할 수있는 데이터를 달성하도록 돕기 위해,우리를 확인하십시오…에!
내에서다른 게시물ABN AMRO가 데이터 메쉬 스타일 아키텍처에서 데이터를 사용할 수있는 방법을 배웠습니다.이 blogpost에서는 큰 데이터 모노리스를 분해하는 방법에 대해 배웁니다.
데이터 중심 의사 결정 시프트
데이터웨어 하우스가 상품이 되었기 때문에 수년 동안 많은 경우 C가 많이 있습니다.하류영양.분산 시스템은 큰 인기를 얻었으며, 데이터는 더 크고 다양하고 다양한 데이터베이스 디자인이 튀어 나와 구름의 출현이 확장 성과 탄력을 증가시키기 위해 계산 및 저장을 분리했습니다.이러한 추세를 중앙 집중식에서 도메인 중심의 데이터 소유권으로 결합하면 데이터 집약적 인 응용 프로그램을 디자인 해야하는 방식을 변경하는 것의 중요성을 즉시 이해할 수 있습니다.
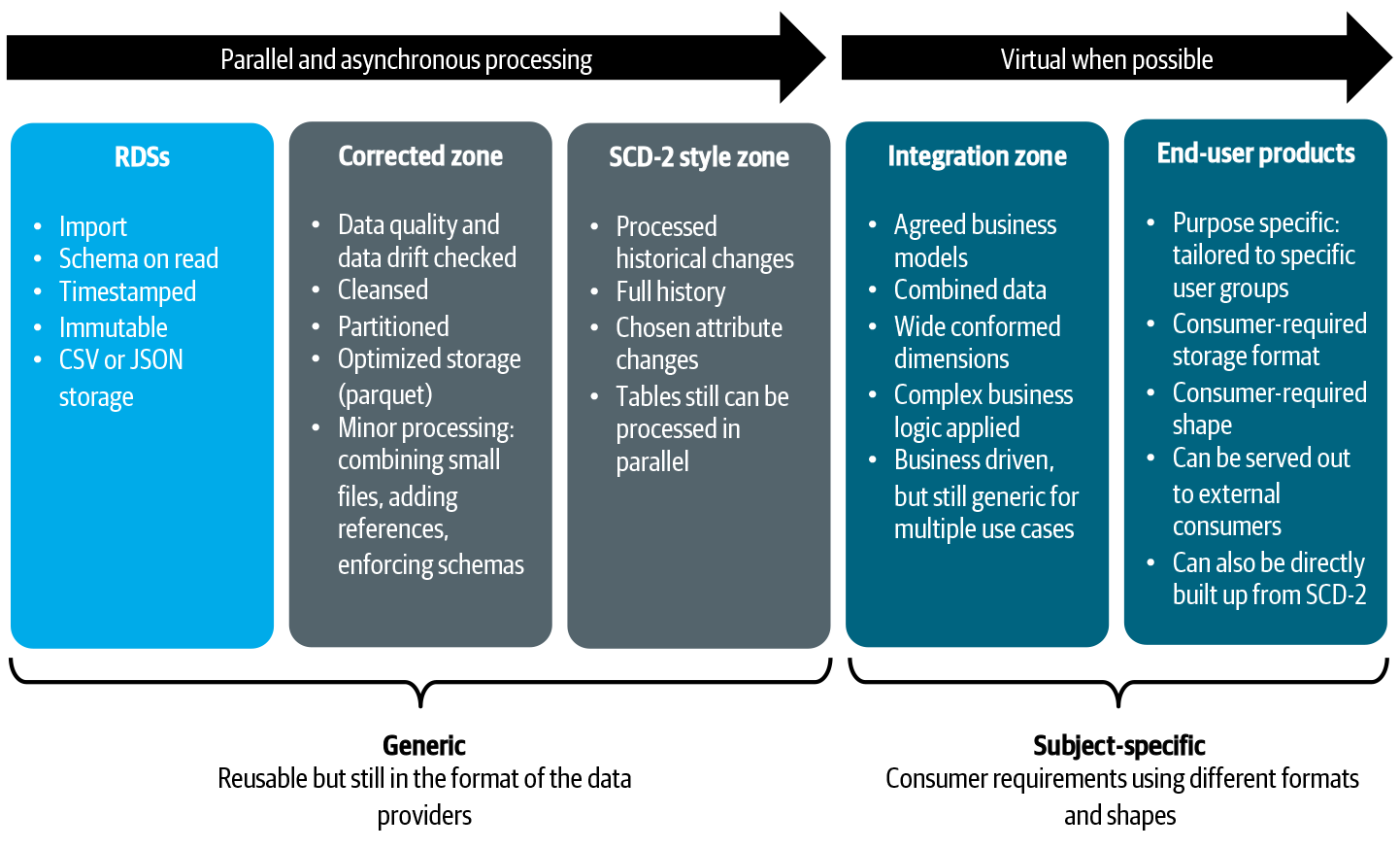
우리의 데이터 아키텍처에서 우리는 직접 데이터 소비와 새로운 데이터 생성 사이의 명확한 분할을했습니다.데이터 배포 아키텍처에서 읽을 수 있으므로여기과여기또한 데이터 저장소 (RDS)를 캡처하여 소비자에게 반복적으로 부족한 데이터를 반복적으로 제공하고 제공합니다.이 패턴에서는 데이터가 읽혀 지지만 새 데이터가 생성되지 않습니다.응용 프로그램이나 사용자가 소비하는 RDSS를 데이터 소스로 직접 사용하고 유사한 데이터 요소 간의 매핑을 기반으로 경량 통합을 수행 할 수 있습니다.이 모델의 큰 이점은 데이터 엔지니어링 팀이 새로운 데이터 모델을 생성하고 유지 관리 할 필요가 없습니다.새 데이터베이스로 데이터를 추출, 변환 및로드하지 않습니다.변화는 날아 오르지 만 이러한 결과는 영구적 인 새 집이 필요하지 않습니다.이 접근법은 복잡한 데이터 변환이 필요없는 데이터 탐색, 경량보고 및 간단한 분석 모델에 특히 유용합니다.
그러나 문제는 소비자의 요구가 RDSS가 제공하는 것을 초과 할 수 있다는 것입니다. 경우에 따라 새로운 데이터 생성에 대한 명확한 필요가 있습니다. 예를 들어 복잡한 비즈니스 로직과 새로운 비즈니스 통찰력을 창출하는 분석 모델이옵니다. 나중에 분석을 위해 이러한 통찰력을 보존하려면 예를 들어 데이터베이스 에서이 정보를 어딘가에 유지해야합니다. 또 다른 상황은 처리 될 필요가있는 데이터의 양이 RDS 플랫폼이 처리 할 수있는 것을 초과 할 수 있습니다. 이러한 경우에, 데이터 처리량; 예를 들어, 과거 데이터의 경우 데이터를 점진적으로 새로운 위치로 가져오고, 처리하고,이를 처리하고, 나중에 소비를 위해 사전 최적화하는 데 정당화 될 수 있습니다. 여러 가지 상황이 여러 가지 RDS가 결합되고 조화 될 필요가있을 때 일 것입니다. 일반적으로 많은 작업을 오케스트레이션하고 데이터를 함께 가져 오는 데 필요합니다. 사용자가 이러한 모든 작업이 완료 될 때까지 사용자를 기다리는 것은 사용자 환경에 부정적인 영향을 미칩니다. 이러한 영향은 우리에게 데이터 소비의 두 번째 패턴으로 이어집니다.도메인 데이터 저장소 (DDS)…에
도메인 데이터 저장소
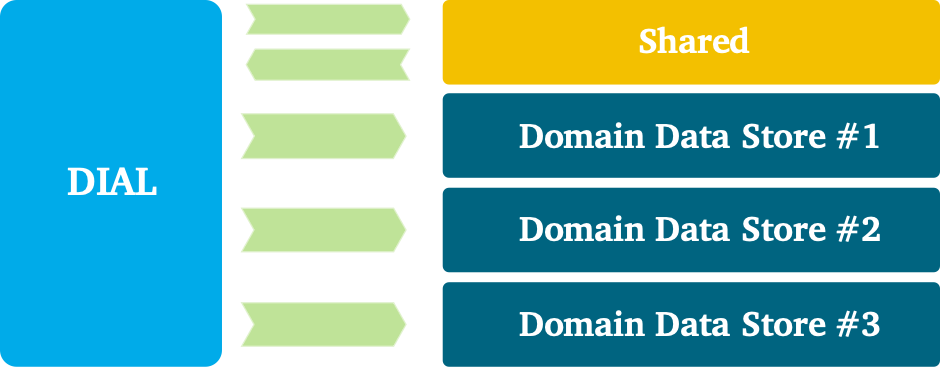
우리는 동시에 민첩성이 증가하는 동안 새로 생성 된 데이터를보다 신중하게 관리하려고합니다.이것은 DDS가있는 것입니다.이러한 유형의 응용 프로그램은 데이터를 집중적으로 처리하고 새로 생성 된 데이터를 저장하고 소비자의 유스 케이스를 용이하게하는 역할을합니다.대규모로 가치를 잠금 해제하려면 데이터 엔지니어링 팀을위한 플랫폼이 포함 된 새로운 아키텍처를 설계했습니다.편면을보고 특성을 평가합시다.
우리가 상상하는 것은 새로운 데이터 기반 의사 사용 사례를 신속하게 전달할 수있는 생태계입니다.그것은 데이터 공학 및 집중적 인 처리를 용이하게하고, 통제력을 유지하고 기술의 확산을 보지 못하고는 아닙니다.우리는 비즈니스 특정 데이터 생성을 향한 일반 (Enterprise) 데이터 통합에서 전환을 예측합니다.통합 전문가에서 지역 사회 건물 및 원활한 협업을 전환합니다.및 단단한 데이터 모델에서보다 유연한 또는 “스키마 – 라이트”접근 방향으로의 시프트.
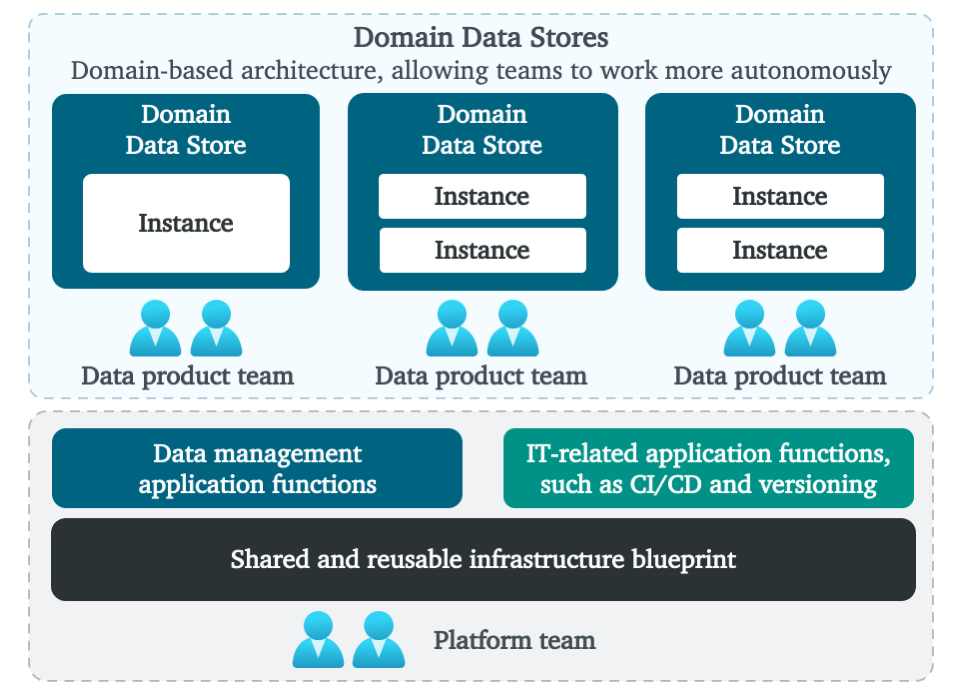
높은 수준의 생태계는 위 그림 1과 같습니다.빠른 데이터 섭취, 변환 및 사용을 허용하는 완전히 관리되는 플랫폼.하단에서 모든 데이터 엔지니어링 팀에서 복잡성을 숨기는 주된 목표는 관리되는 인프라를 볼 수 있습니다.셀프 서비스 방식으로 데이터 엔지니어링 팀을 지원하는 재사용 가능한 기능이 있습니다.여기에는 재사용 가능하고 관리되는 데이터베이스 기술, 중앙 모니터링 및 로깅, 계보, ID 및 액세스 관리, 오케스트레이션, CI / CD, 데이터 및 스키마 버전 관리, 배치, API 및 이벤트 기반 섭취를위한 패턴, 비즈니스 인텔리전스와의 통합 및 고급분석 기능 등등.underpinning 플랫폼은 팀 토폴로지 방식을 사용하여 관리됩니다. 중앙 플랫폼 팀은 다른 모든 팀을 지원하면서 기본 플랫폼을 관리합니다.주요 목적은 모든 서비스를 단순화하고 플랫폼을 관리하고 확보하고 데이터 엔지니어링 팀의 오버 헤드를 줄이는 것입니다.
위에는 데이터 엔지니어링 팀에서 데이터를 관리하는 DDS가 표시됩니다.이 도메인 팀은 데이터 제품, 고객 여정 또는 비즈니스 사용 사례에 중점을 둡니다.DDS 주변의 경계는 또한 데이터 책임을 결정합니다.여기에는 데이터 품질, 소유권, 통합 및 배포, 메타 데이터 등록, 모델링 및 보안이 포함됩니다.나중에 세분화와 도메인 경계로 돌아올 것입니다.
기능 요구 사항을 위해 우리는 비즈니스 목표와 목표가 잘 정의되고 자세한 및 완료되도록합니다.그들을 이해하는 것은 솔루션의 토대이며 해결해야 할 비즈니스 문제, 필요한 데이터 소스, 작동해야 할 솔루션, 실시간 또는 오프라인으로 데이터 처리를 수행 해야하는 경우, 무엇을 수행해야합니다.무결성과 요구 사항은 다른 도메인에서 재사용 할 수있는 것입니다.
비 기능 요구 사항의 경우, 우리는 어떤 종류의 데이터 저장소 기술 유형을 제공하는지 선택했습니다.각 데이터 저장소의 강도를 활용하기 위해 재사용 가능한 데이터베이스 기술이나 데이터 저장소 및 패턴 세트를 생각할 수 있습니다.예를 들어, 미션 크리티컬 및 전환 응용 프로그램은 강력한 일관성 모델을 사용하거나 비즈니스 인텔리전스와보고가 빠른 SQL 액세스를 제공하는 상점에서만 허용 될 수 있습니다.
다른 데이터 저장소는 데이터를 내부적으로 관리하고 구성합니다.하나의 일반적인 구성은 섭취, 정화, 큐어 처리, 조화, 서빙 등의 우려를 분리하는 것입니다.우리의 도메인 데이터 저장소에서는 폴더, 버킷, 데이터베이스 등과 같은 다양한 저장 기술을 가진 다양한 영역을 사용하는 것이 좋습니다.존은 또한 우리가 목적을 결합 할 수 있으므로 상점을 사용하여 동시에 운영 및 분석을 용이하게 할 수 있습니다.모든 상점과 구역에 대해 범위는 매우 명확해야합니다.
데이터 모델의 경우 리지드 데이터 모델에서 더 많은 “스키마 라이트”접근 방식으로 이동하도록 권장합니다.그러나 아키텍처 스타일은 허용됩니다.팀이 스키마를 읽거나 직접적으로 단순한 차원 모델을 구축하는 것을 선호하는 경우, 우리는 그들이 그렇게 할 것을 권장합니다.Kimball 또는 데이터 볼트 모델링도 적용 할 수 있습니다.그것은 모두 사용 사례의 요구와 크기에 달려 있으며, 이는 다음 주제로 가져옵니다.
도메인 데이터 저장소 세분화
우리가 엔터프라이즈 데이터웨어 하우스에서보다 세밀한 DDS 설계로 전환 할 때 우리는 세분화를 고려하고 데이터를 논리적으로 세그먼트해야합니다.논리 DDS 경계의 범위, 크기 및 배치를 결정하는 것은 어렵고 도메인간에 데이터를 배포 할 때 어려움을 유발합니다.일반적으로 경계는 주제 지향적이며 비즈니스 기능과 정렬됩니다.도메인의 논리적 경계를 정의 할 때 데이터 모델링 활동 및 도메인 내의 내부 데이터 배포를 용이하게하도록 하위 도메인으로 분해하는 값이 있습니다.
중요한 작업은 DDS의 논리적 역할에 대해 신중하게 생각하는 것입니다.이 덮개도 덮습니다비즈니스 입도과기술적 세분화:
비즈니스 입도는 최고 수준의 기능적 컨텍스트, 범위 (즉, ‘경계 컨텍스트’) 및 활동의 분석을 비즈니스 문제의 하향식 분해로 시작합니다.이들은 더 작은 ‘영역’, 사용 사례 및 비즈니스 목표로 나누어야합니다.이 연습에서는 효율적인 비즈니스 프로세스, 도메인, 기능 등을 나누는 방법에 대한 좋은 비즈니스 지식과 전문 지식을 필요로합니다. 모범 사례는 비즈니스 기능을 참조 모델로 사용하고 일반적인 용어 (유비쿼터스 언어) 및 중복 데이터 요구 사항을 연구하는 것입니다.
기술적 세분화는 재사용 성, 유연성 (자주 기능적 변경에 대한 쉬운 적응), 성능, 보안 및 확장 성과 같은 특정 목표를 향한 수행됩니다.핵심 균형은 올바른 절충을하는 것입니다.비즈니스 도메인은 동일한 데이터를 사용할 수 있지만 기술적 요구 사항이 서로 충돌하는 경우 문제를 분리하는 것이 좋습니다.예를 들어 특정 비즈니스 작업이 데이터를 집중적으로 집계해야하며 다른 하나는 개별 레코드 만 빠르게 선택 해야하는 경우 우려를 분리하는 것이 좋습니다.유연성에 대해서도 동일하게 적용될 수 있습니다.하나의 사용 사례는 일상적인 변화가 필요할 수 있으며, 다른 하나는 적어도 1/4 이상 안정적으로 유지되어야합니다.다시 말하지만, 당신은 문제를 분리하는 것을 고려해야합니다.따라서 DDS 경계 내에서 인스턴스가 허용되는 방식으로 DDS를 분리했습니다.
내부적으로 데이터 조직의 이야기는 도메인이 더 크고 여러 하위 도메인으로 구성 될 때 더 복잡해질 수 있습니다. 이보기의 DDS는 더 많은 초록입니다. 인스턴스 및 영역은 여러 하위 도메인간에 공유 될 수 있으며 영역은 독점적 일 수 있습니다. 이 콘크리트를 예로 만들어 보겠습니다. 큰 도메인의 경우 하나의 DDS의 모든 다양한 영역 주위에 경계를 줄 수 있습니다. 예를 들어,이 DDS 내에서 첫 번째 두 영역은 여러 하위 도메인간에 공유 될 수 있습니다. 그러므로 모든 하위 도메인에 대해 닦고, 수정하고, 과거 데이터를 빌드하는 것은 일반적으로 수행됩니다. 변형을 위해서는 데이터가 하위 도메인 또는 유스 케이스에 특정되어야하기 때문에 이야기가 더욱 복잡 해집니다. 그래서 하나의 사용 사례에만 해당하는 공유 및 파이프 라인이있는 파이프 라인이있을 수 있습니다. 모든 파이프 라인을 포함하여 전체 데이터 체인은 함께 속하므로 하나의 거대한 DDS 구현으로 볼 수 있습니다. 이 거대한 DDS 구현 내부에서 방금 배운 것처럼 다른 경계 : 모든 하위 도메인 및 특정 경계에 대한 일반적인 경계를 볼 수 있습니다.
도메인을 분해하는 것은 도메인이 더 크거나 하위 도메인이 일반 반복 가능 – 통합 로직을 요구할 때 특히 중요합니다.이러한 상황에서는 다른 하위 도메인을 표준화하고 이익을 얻을 수있는 방식으로 통합 논리를 제공하는 일반적인 하위 도메인을 가질 수 있습니다.지상 규칙은 서브 도메인간에 공유 모델을 소형화하고 항상 유비쿼터스 언어로 정렬하는 것입니다.겹침에 대해서는 도메인 중심 디자인에서 다른 패턴을 사용합니다.
데이터 요구 사항이 겹치는 세 가지 예시적인 사용 사례를 상상해보십시오.다른 통합 및 배포 패턴은 다른 팀 내에 적용될 수 있습니다.적용 할 수있는 다른 접근 방식을 탐험 해보자.
그만큼별도의 방법패턴은 재사용 가능성보다 복제 비용이 선호되는 경우에 사용할 수 있습니다.이 패턴은 일반적으로 높은 유연성과 민첩성이 필요할 때 선택입니다.모델링 관점에서 공통적이거나 아무 것도 공통적으로있을 때도 선택할 수 있습니다.
팀은 사용을 사용할 수 있습니다협력 관계겹치는 모든 당사자의 공유 개발 요구 사항을 수용 할 수있는 패턴은 큽니다.모든 팀은 서로 협조하고 서로의 요구를 고려해야합니다.각자는 공유 로직을 자유롭게 변경할 수 없기 때문에 모든 사람들에게 큰 공약이 필요합니다.이 접근 방식에서 데이터 엔지니어링 팀은 데이터 소비자와 제공 업체 모두 데이터 저장소에 캡처, 추출 및로드 및 다시 게시하거나 배포합니다.
이 장에 건설 된 아키텍처는 데이터 집약적 인 응용 프로그램을 규모에서 관리하는 방법을 이해하는 데 도움이됩니다.가치가 빠른 시간을 달성하기 위해 도메인 경계를 사용하여 데이터를 분해하는 것이 중요합니다.사일로를 부수고 DDS간에 의존성을 최소한으로 유지함으로써 팀이 집중할 수 있습니다.
이 BlogPost에서 토론 한 아키텍처는 초정표에서 데이터를 관리하는 데 도움이됩니다.더 많은 것을 배우고 싶다면, 나는 당신에게 책을 살펴 보도록 참여시킵니다.저울 데이터 관리…에
모든 작가가 알고 있기 때문에 그림은 천 단어의 가치가 있습니다.그리고 데이터 과학 분야에서, 좋은시각화는 금의 무게 가치가 있습니다.이 업계와 스킬 셋의 새로운 사람이 아직도, 나는 전문성의 장소에서 말할 수 없지만 신생아 데이터 엔지니어로서, 나는 내 주머니에있는 팬더와 내 눈에 밝은 도시의 불빛을 가진 새로운 회사에 도착했습니다.우리 팀은 환상적인 환상적인, 주로 깨끗한 데이터를 수집하고 있었지만 아무도 그것을 실행 가능한 무언가로 변화시키는 시간이나 전문 지식이 없었습니다.그들이 이해하는 것에 대한 그들이 발견 한 것은 아마도 데이터 와학자들을 늘릴 수있는 가장 큰 도구 일 것입니다 : Google Data Studio.
내가 처음으로 인터페이스로 놀기 시작했을 때, 나는 scoffed와 phughed.그것은 팬지가 아니 었습니다. 그것은 기초가 아니 었습니다. 그래서 내가 그렇게하기로 결심 한 새로운 파이썬 기술을 사용하는 방법을 배우는 방법을 배우는 몇 시간을 보냈습니다.그게 더 많은 일을할수록 Google Data Studio 또는 GDS의 진정한 강력한 성격을 더 많이 이해하기 위해 더 많은 것을 더 많이 알게 될수록 멋진 아이들이 전화를 겁니다.
누구나 그래프를 좋아합니다.진지하게, 그들은 그렇습니다.좋은 그래프처럼 데이터를 싫어하는 사람들조차도.라인이 올라가는가?얼마나 예쁘가?가장 중요한 것은 라인이 올라 갔습니까?
나는 농담 (주로) 농담하지만 비즈니스 세계에서 우리의 직업은 데이터로 노는 것이 아니라, 그렇지 않은 사람들을 위해 그것을 번역하는 것이 아닙니다.시간과 시간이 다시, 예쁜 그래프가 언제든지 숫자를 이길 것임을 알 수 있습니다.뿐만 아니라 캔디와 같은 메트릭을 위로하는 팀과 함께 일할 때 가능한 한 빨리 여러 가지 그래프를 제공해야합니다.이 때문에 Google Data Studio는 금요일 금요일입니다.
우리 가이 프로그램의 힘을 얻기 전에 모든 사람을위한 것이 아니라는 것을 아는 것이 중요합니다.데이터 초보자와 데이터 과학자 간의 갭을 끼워 넣는 도구입니다.기계 학습을 할 수 있습니까?아닙니다. 데이터 청소를 위해 사용해야합니까?친애하는 하나님, 아니.병합조차도 한계가 있습니다.그러나 처음부터 쌓은 막대 차트를 코딩 한 사람은 거의 계란을 튀기는 것보다 짧은 시간에 아름답고 정확한 차트를 보고서로 덤프하는 것이 얼마나 쉬운 지 알 수 있습니다 (데이터 청결한 경우, 물론!)…에
Google Data Studio Excels가 데이터 조작의 완전히 가단적인 성격에있는 곳입니다.모든 숫자 열에 사용자 정의 할 수있는 기본 집계가 있으므로 자세한 행에서 그룹화 된 합계로 점프하는 것은 ‘Pivot Table, Schmivot Table’을 말하는 것보다 쉽습니다.뿐만 아니라 데이터 탐색을 드래그 앤 드롭 꿈으로 만듭니다.마지막으로, 가장 중요한 것은, 그것은 몇 명 중 하나입니다.비어 있는닫힌 액세스 웹 사이트에서 호스팅하지 않고도 팀과의 데이터를 개인적으로 공유 할 수있는 프로그램.나는힘과Streamlit의커스터마이즈을 충분히알고, 나는여전히미래에광범위하게이프로그램을사용하려면,하지만 내팀과민감한 데이터를공유하기 위해,GDS는신전송하고있다.나는 작은 조건이 없을 때 GDS가 내 팀이 일하는 방식을 변화 시켰습니다.하지만 왜 당신에게 말해 줄 수 있을까요?
처음에는 확인할 수있는 것이 얼마나 놀랍도록 쉽게 완전하게 인구 및 대화식 보고서를 몇 분 안에 만드는 것입니다.GDS는 집계 도구이므로 데이터가 깨끗하고 일관성이 있는지 확인하십시오.Adage가 진행됨에 따라 “쓰레기가 쓰레기통에 균등하게 튀어 나와”Google의 훌륭한 사람들이 실제 데이터 엔지니어링 작업을 수행 할 수 없어야합니다.
1 단계 : 데이터를로드하십시오
데이터를로드하기위한 몇 가지 옵션이 있습니다.GDS는 널 (NULL) 값을 꽤 잘 처리 할 수 있지만, 열의 의미 론적 구성뿐만 아니라 당신이하기 전에 당신의 null을 이해하는지 확인하십시오.시작할 때 가장 일반적인 좌절 중 하나는 구성이 모든 것이 있고 데이터가 이해되지 않을 때 데이터가 끊어지면 데이터가 끊어집니다.
GDS는 귀하의 데이터를 적재 할 수있는 몇 가지 편리한 옵션을 갖추고 있지만 찬사와 단점이 있습니다.당신이 너무 늦을 때까지 행 손실을 알지 못하기 때문에 데이터를 연결하기 전에 문서를 읽으십시오.데이터 커넥터에는 다음이 포함됩니다.
PostgreSQL / MySQL.(쿼리 당 100K 행의 제한)
Google 시트(프리미엄 계정이없는 데이터 제한)
CSV 파일 업로드(최대 데이터 집합 크기는 100MB입니다)
Google Big query.(나는 결코 사용한 적이 없다)
Google Analytics / Google 광고(유료 버전이없는 지난 3 개월로 제한됨)
그리고 몇 가지 더 많은 Google 제품
내 개인적인 즐겨 찾기는 Google 시트입니다.두 프로그램을 초 단위로 연결하고 GDS는 시트를 활성 데이터베이스로 처리하므로 보고서 페이지 상단의 새로 고침 버튼을 누르면 보고서에 반영됩니다.대부분의보고를 사용하면 100MB 제한에 가까워지지 않고 파일 업로드를 사용하여 많은 행과 열을 가질 수 있습니다.
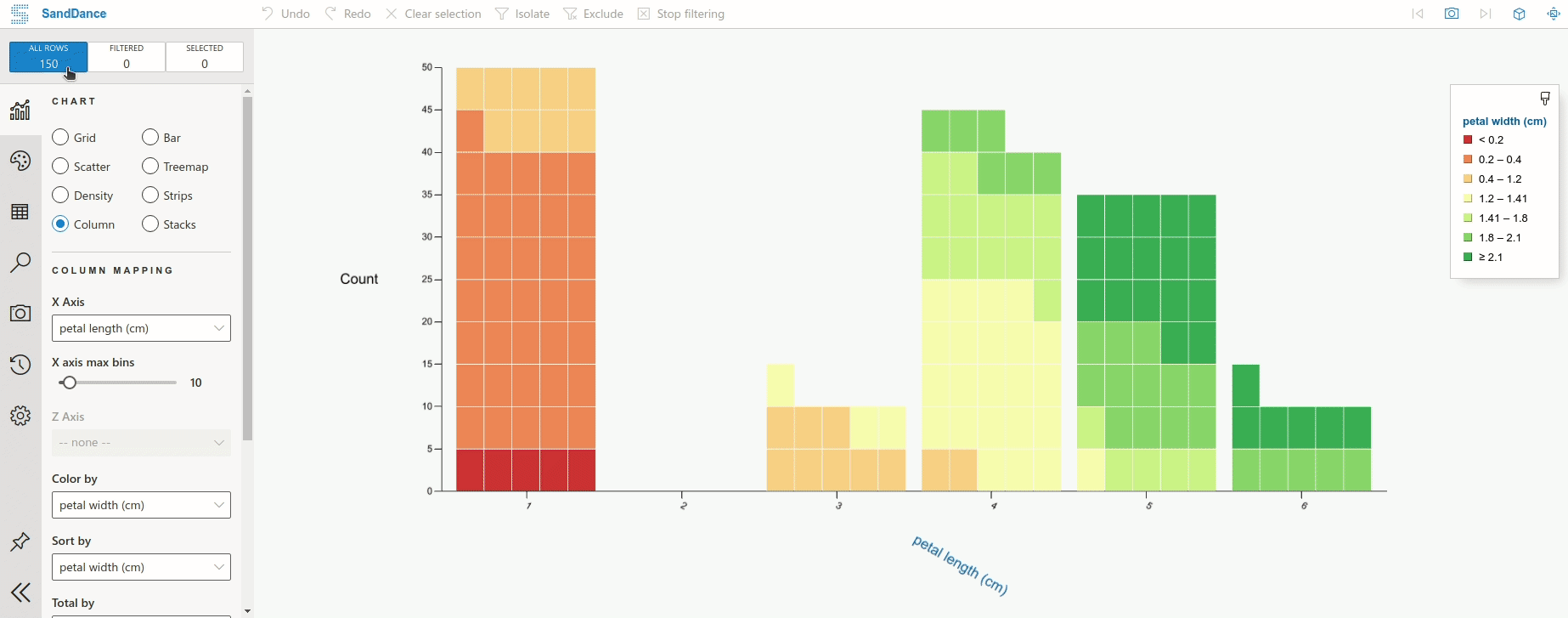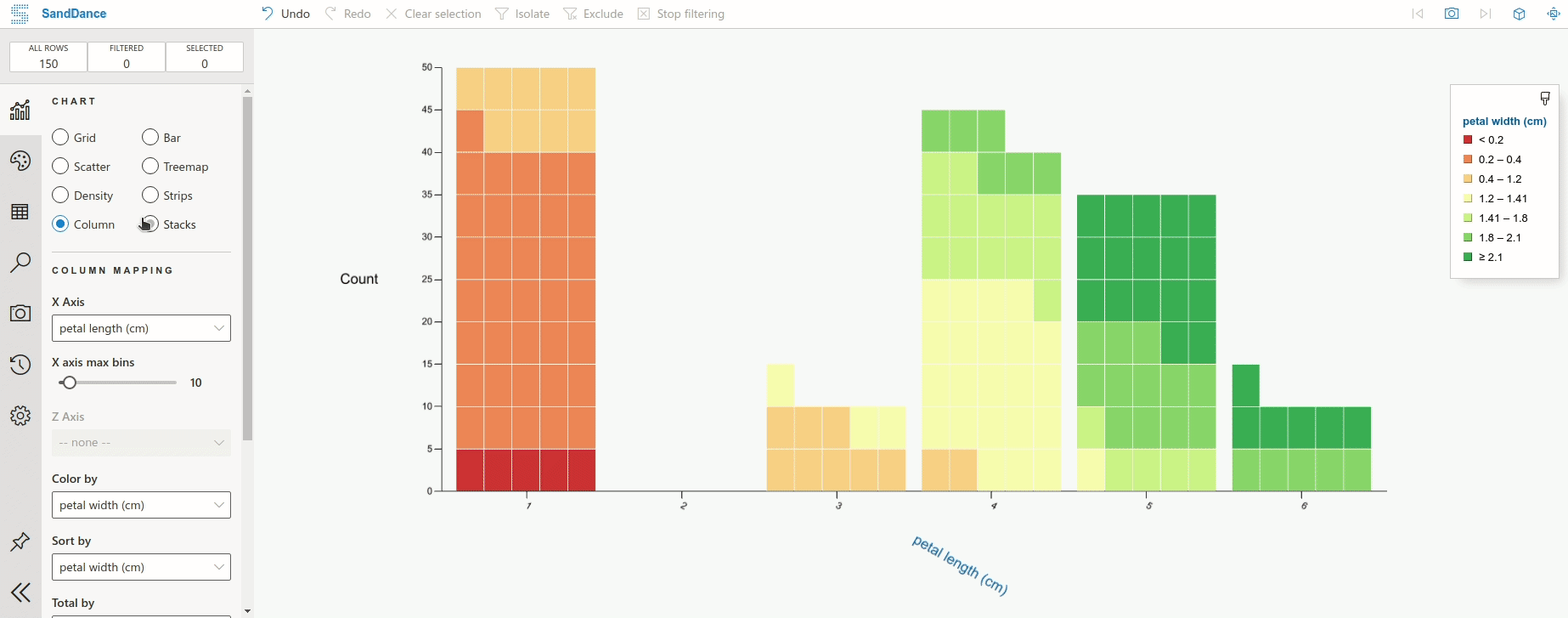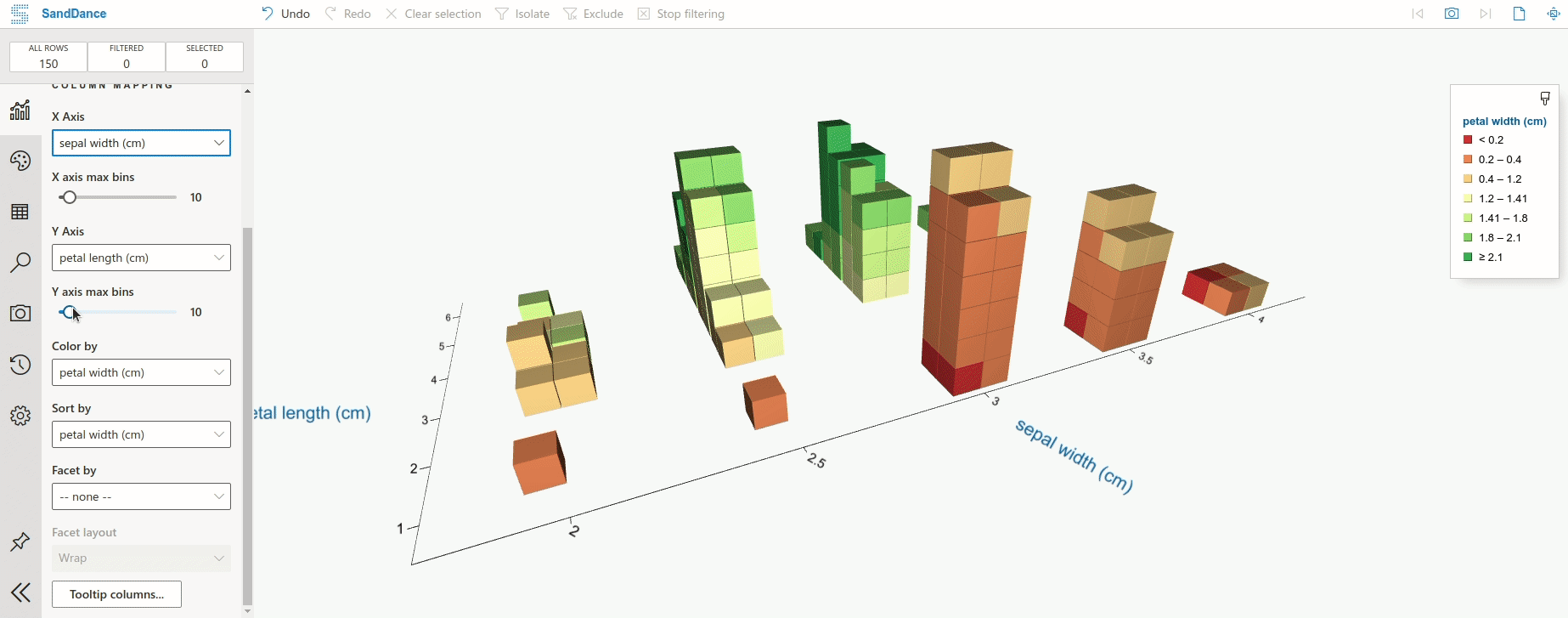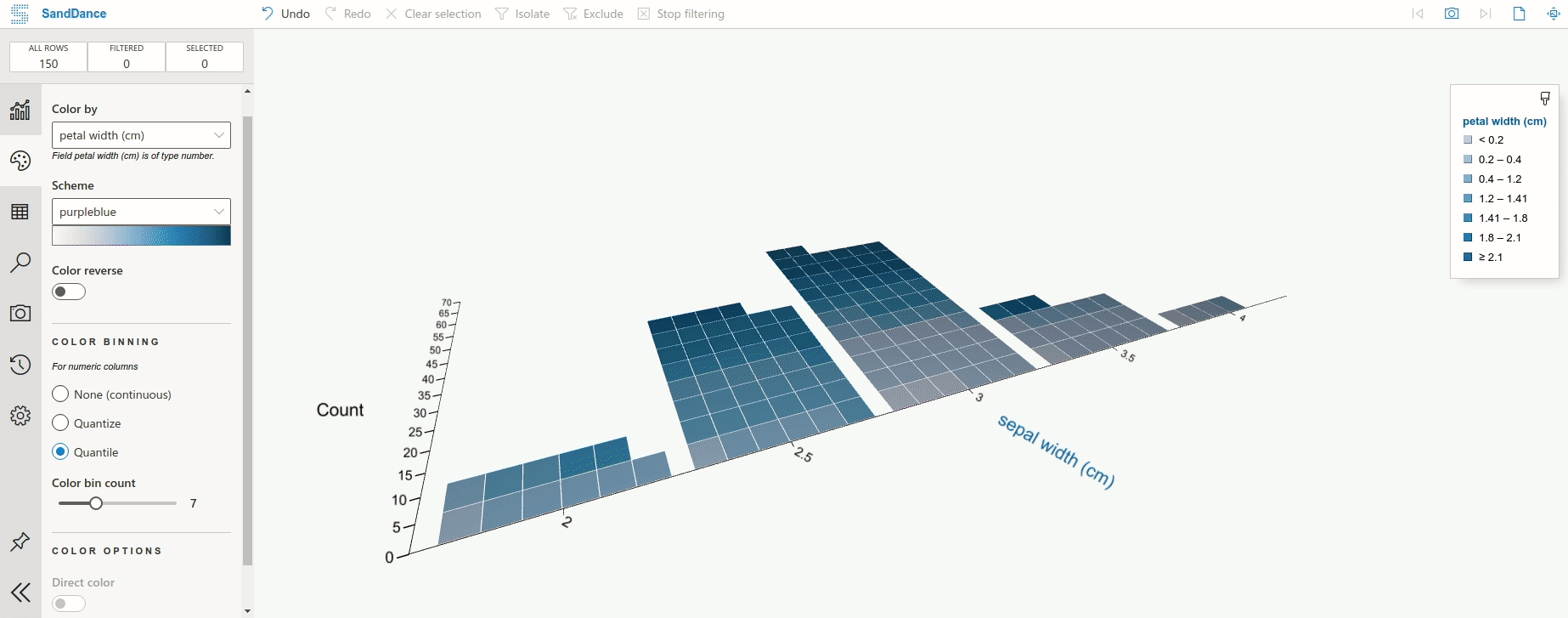
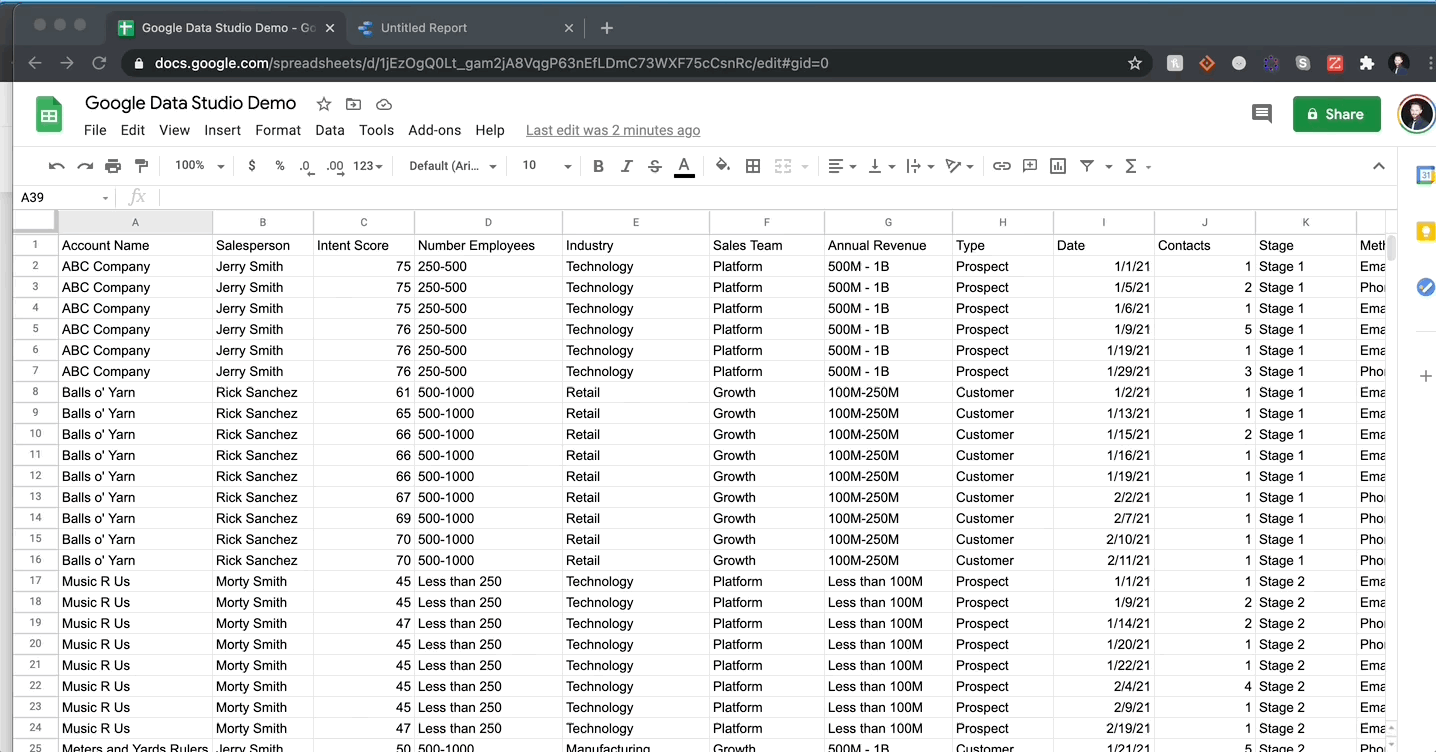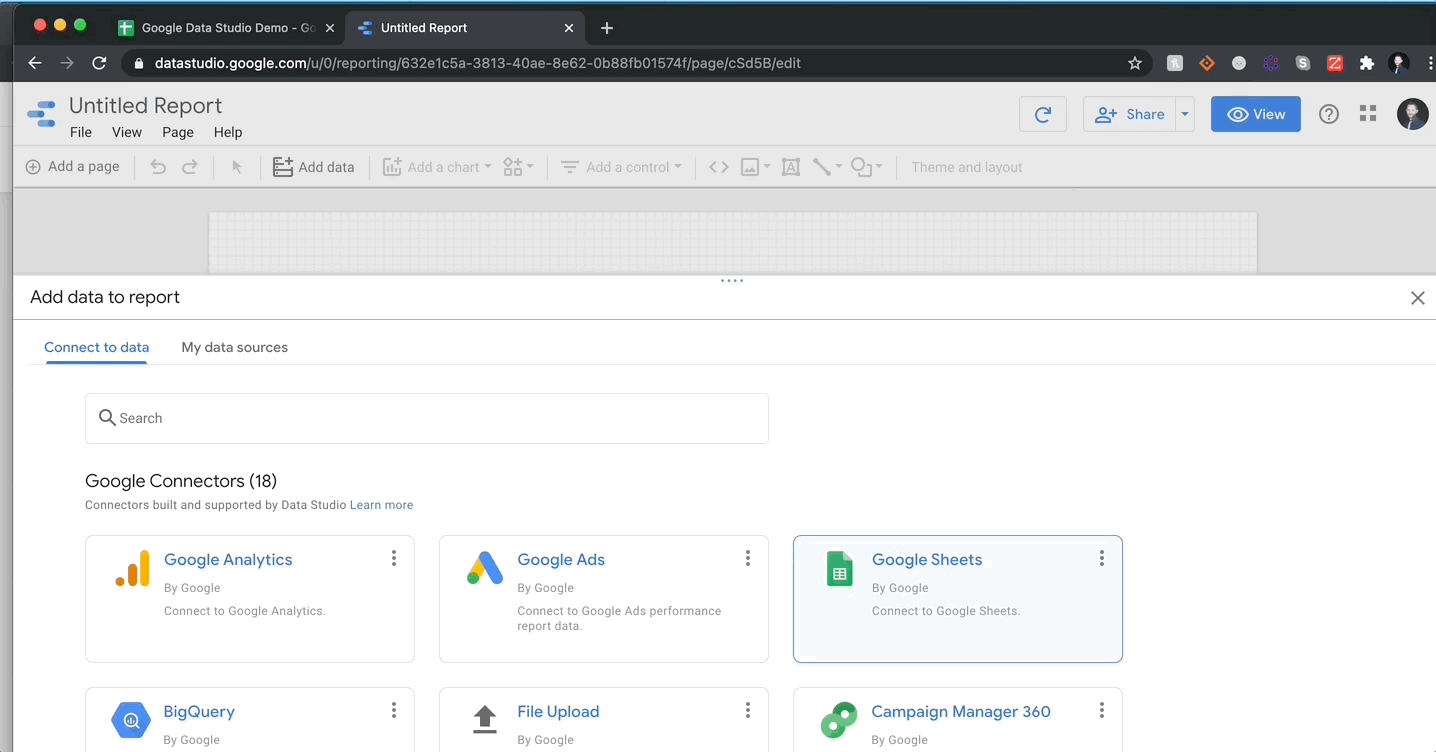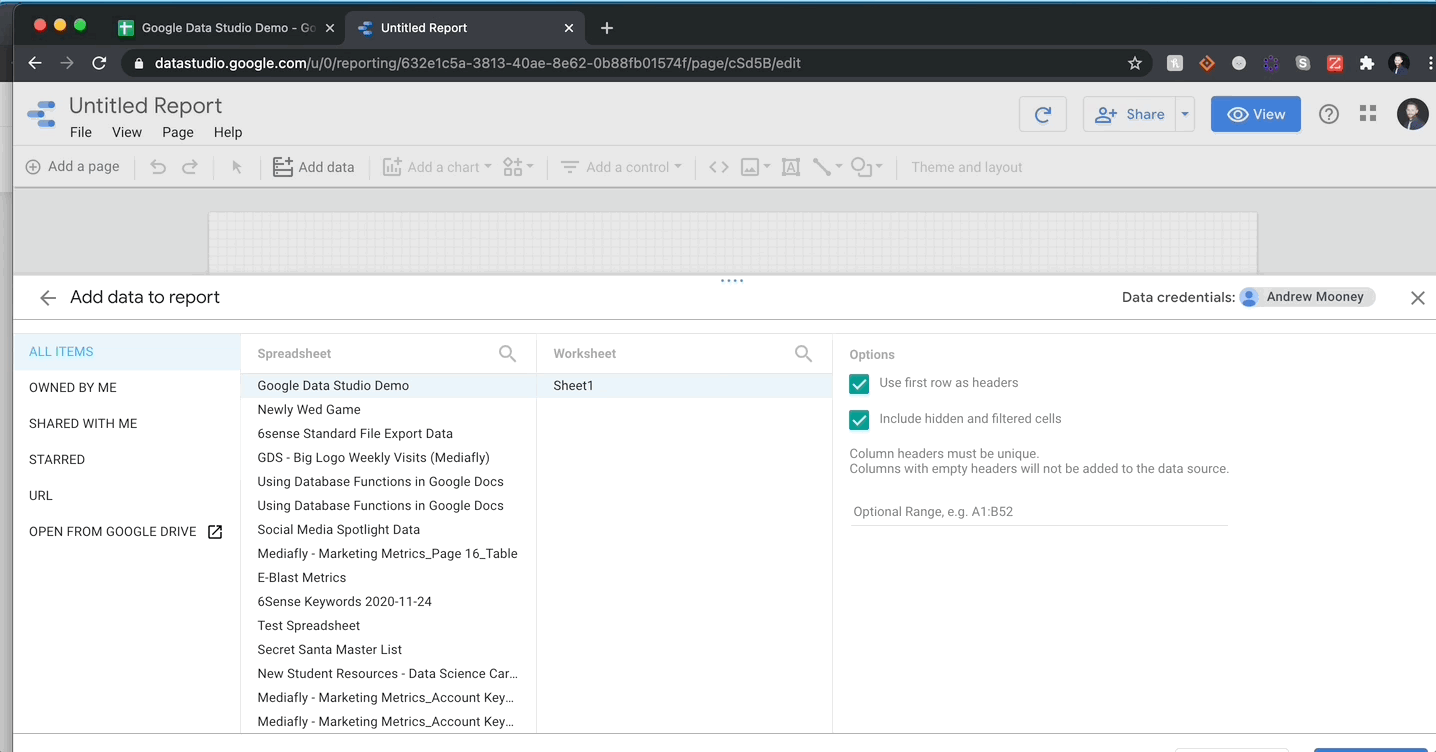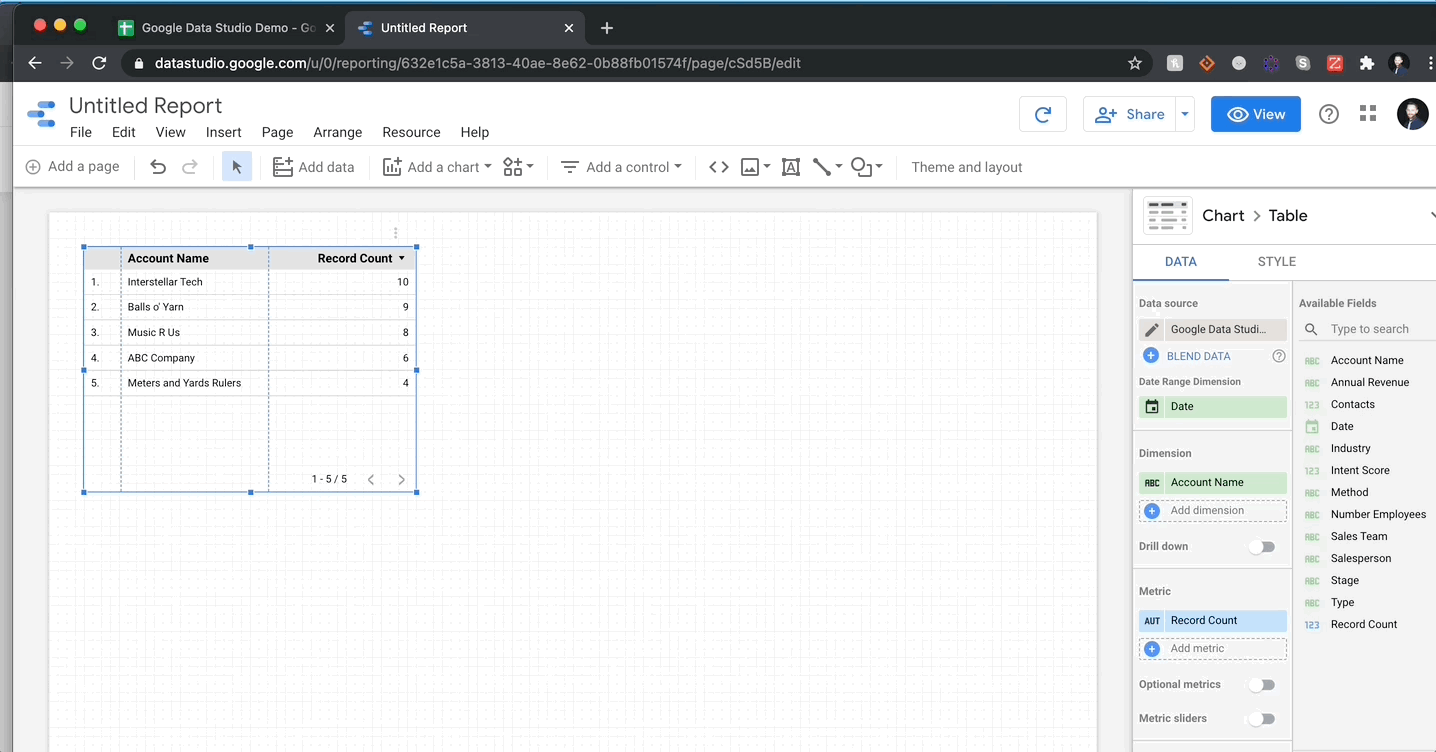
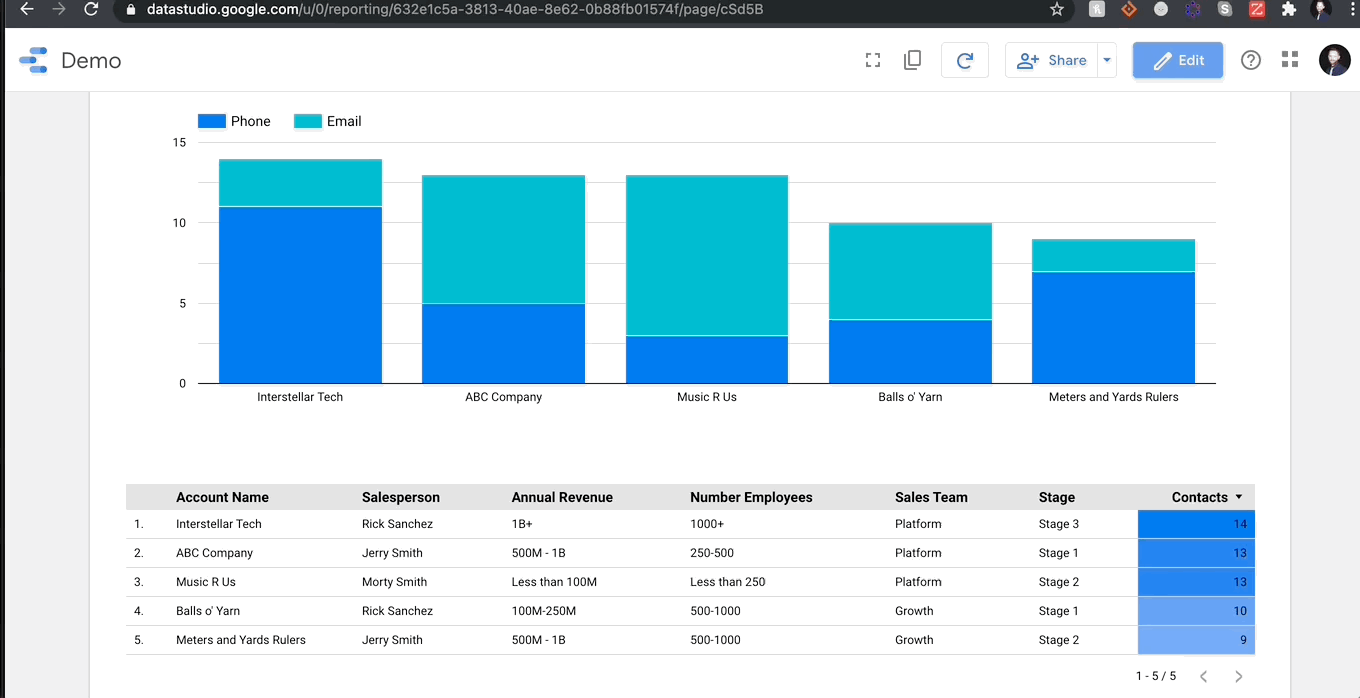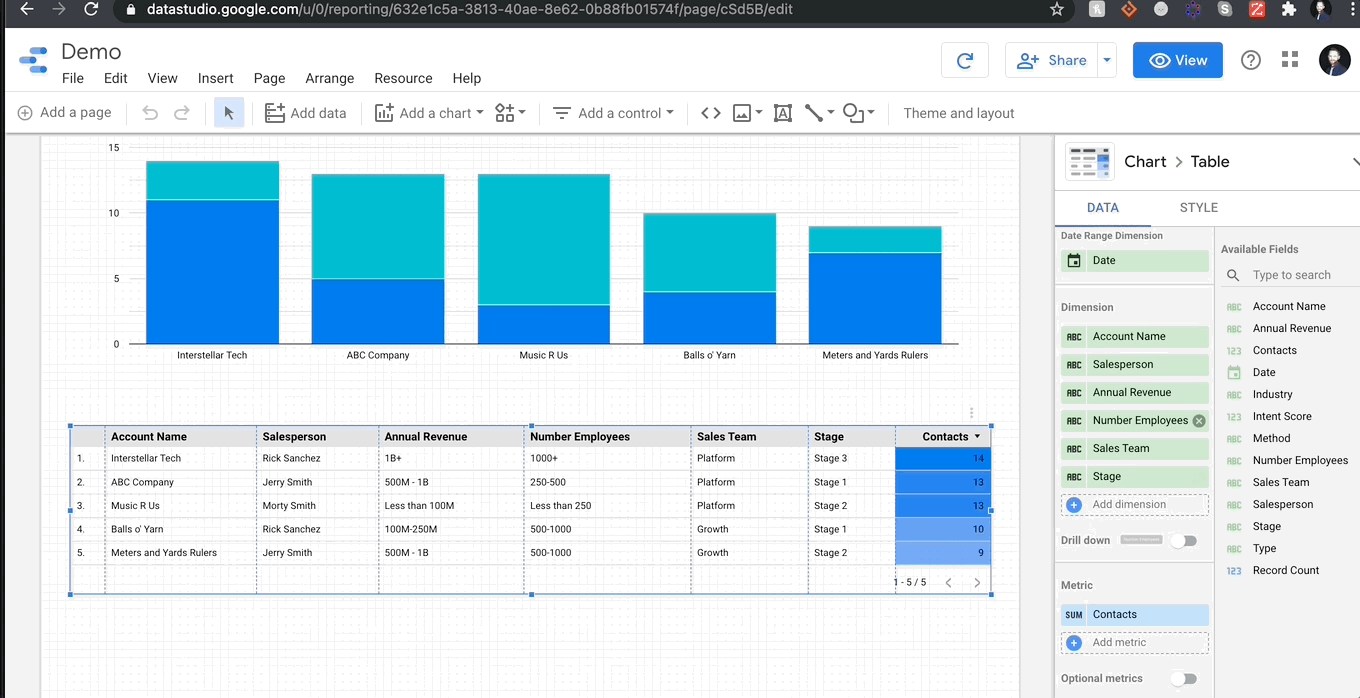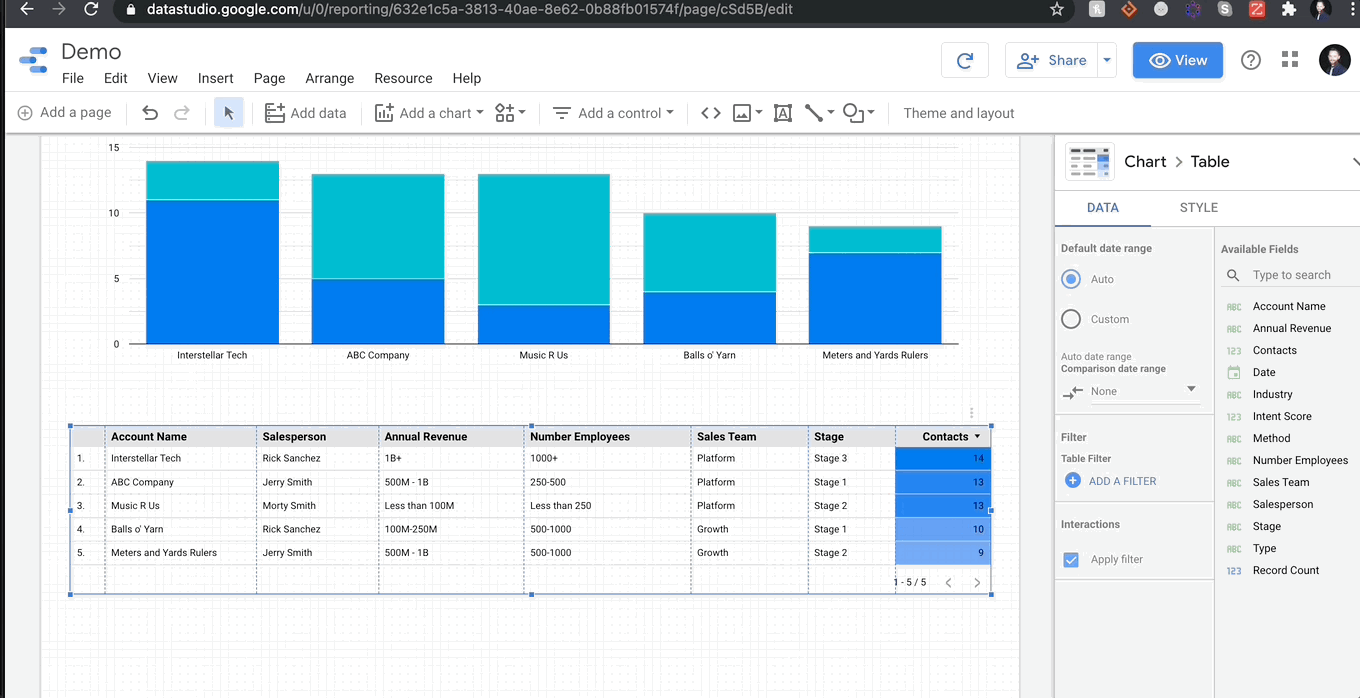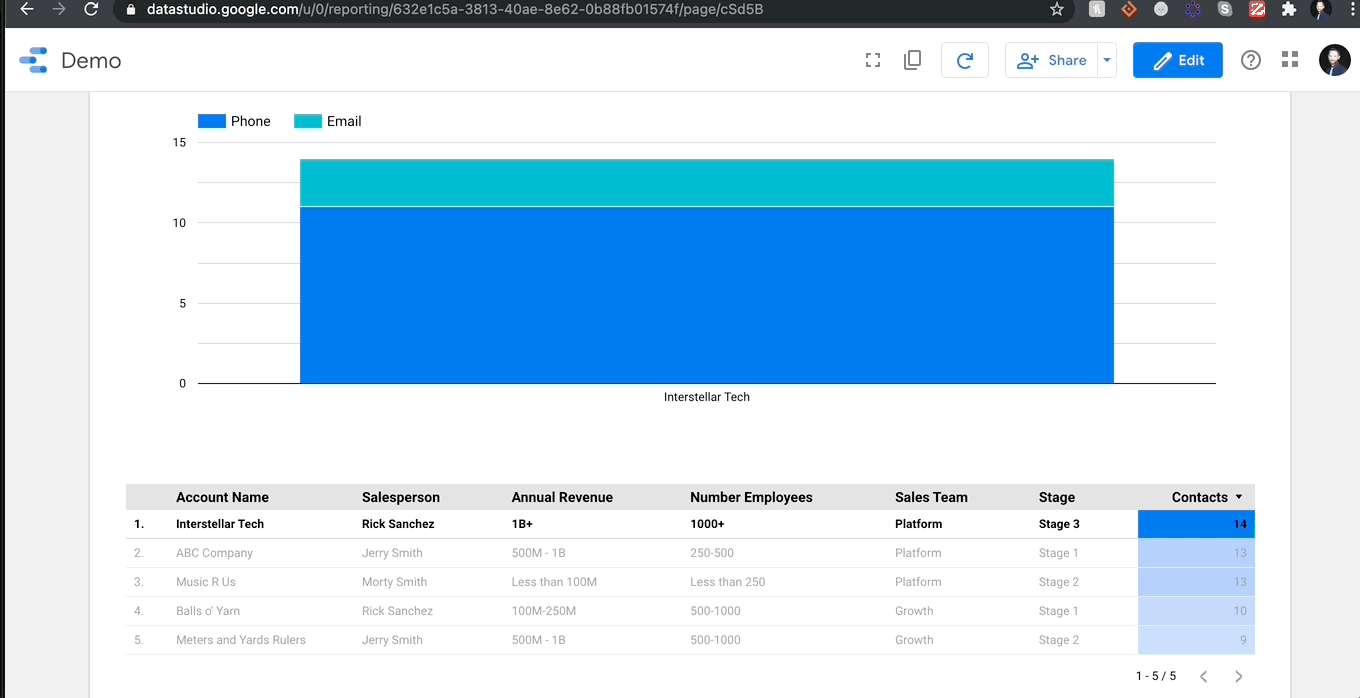
데이터를로드하고 시각화하는 것이 얼마나 쉬운 지 보여주는 가짜 데이터 집합을 만들었습니다.내 GDS 보고서 작성보다 가짜 회사 이름을 더 오랫동안 더 오랫동안 올리면 더 오래 걸렸다 고 말할 수 있습니다.내 데이터에는 카테고리 문자열, 정수 및 날짜의 데이터 유형의 조합이 포함됩니다.아래 에서이 데이터를 GDS에 연결하고 몇 초 안에 테이블을 만드는 것을 볼 수 있습니다.
그보다 더 많은 것이 없습니다.나는 데이터를 업로드 한 후에 내가 수행 한 조작하기 전에 항상 데이터의 시맨틱 구성을 항상 확인해야한다고 말할 것입니다.
2 단계 : 시각화
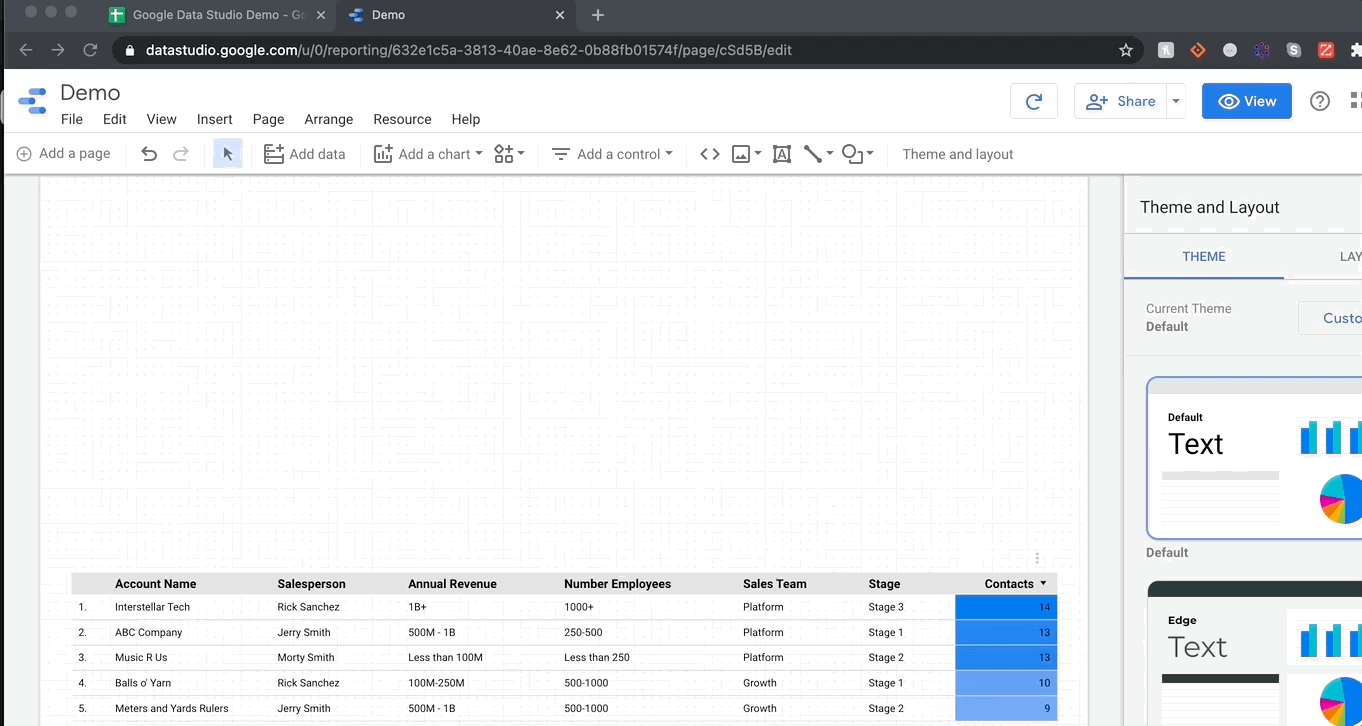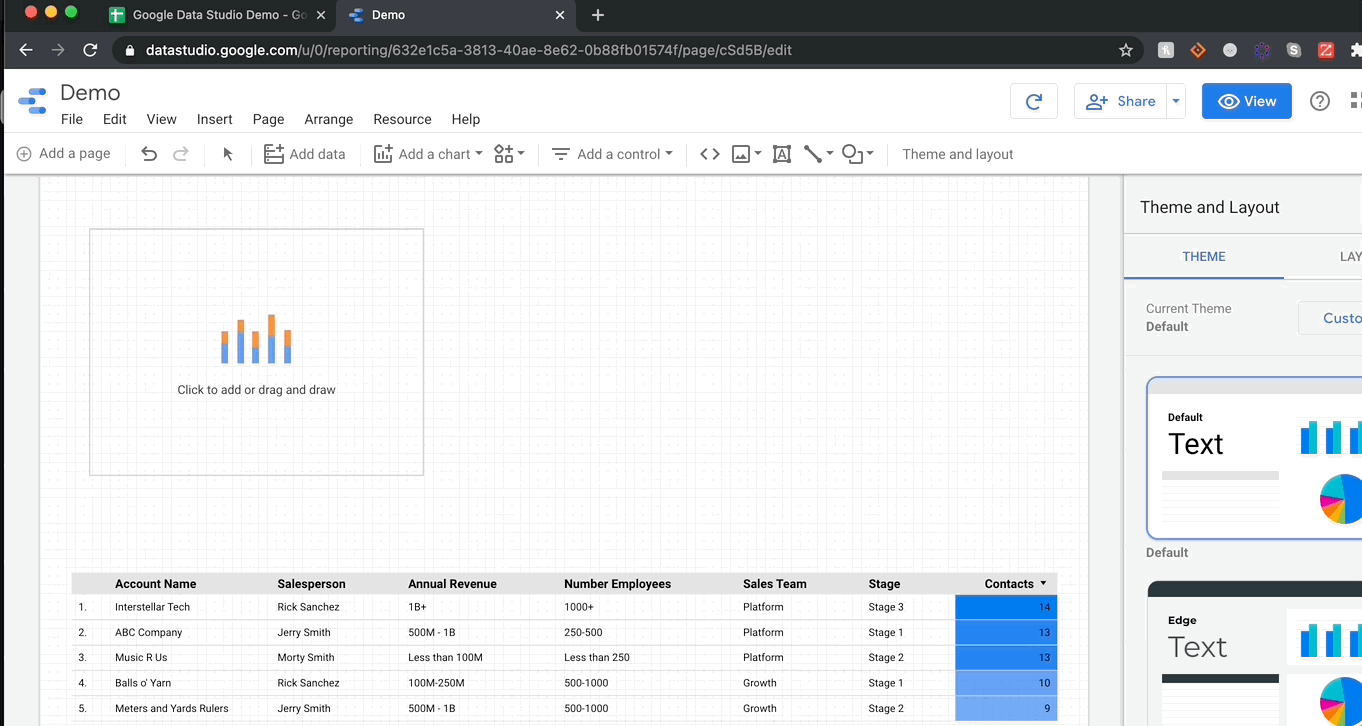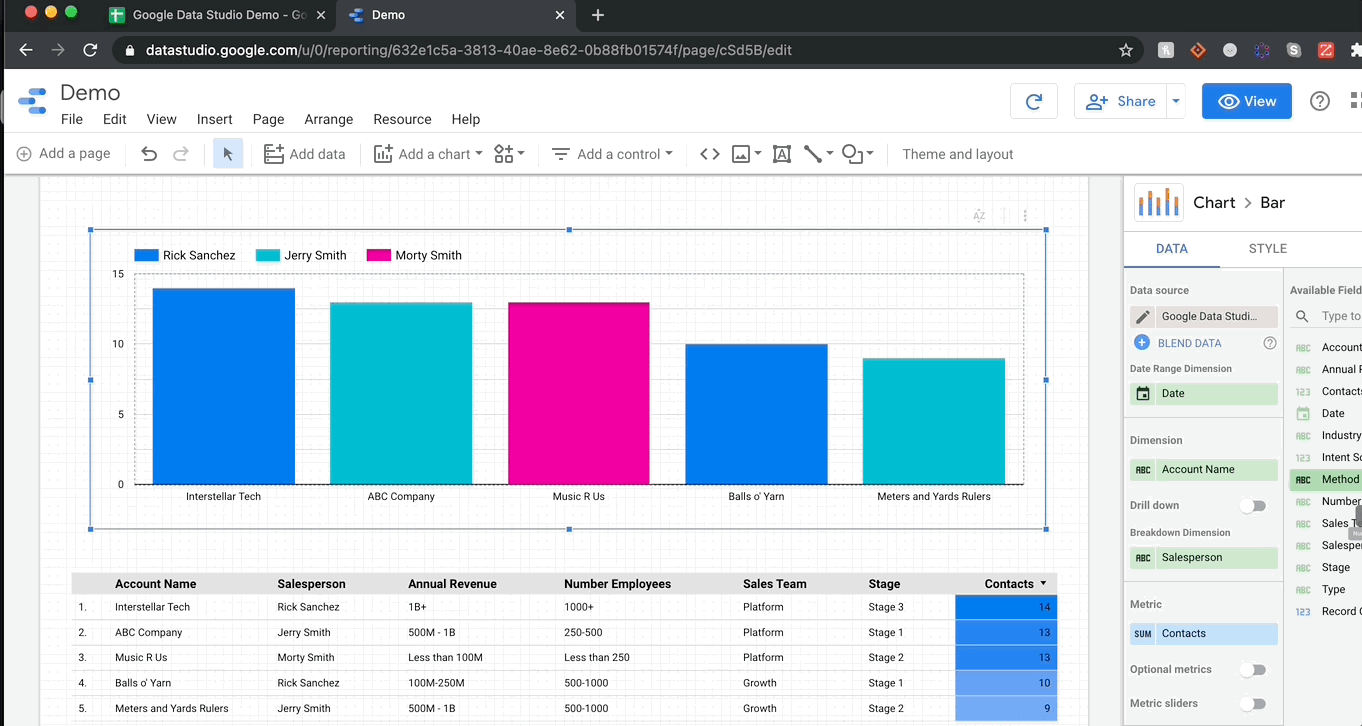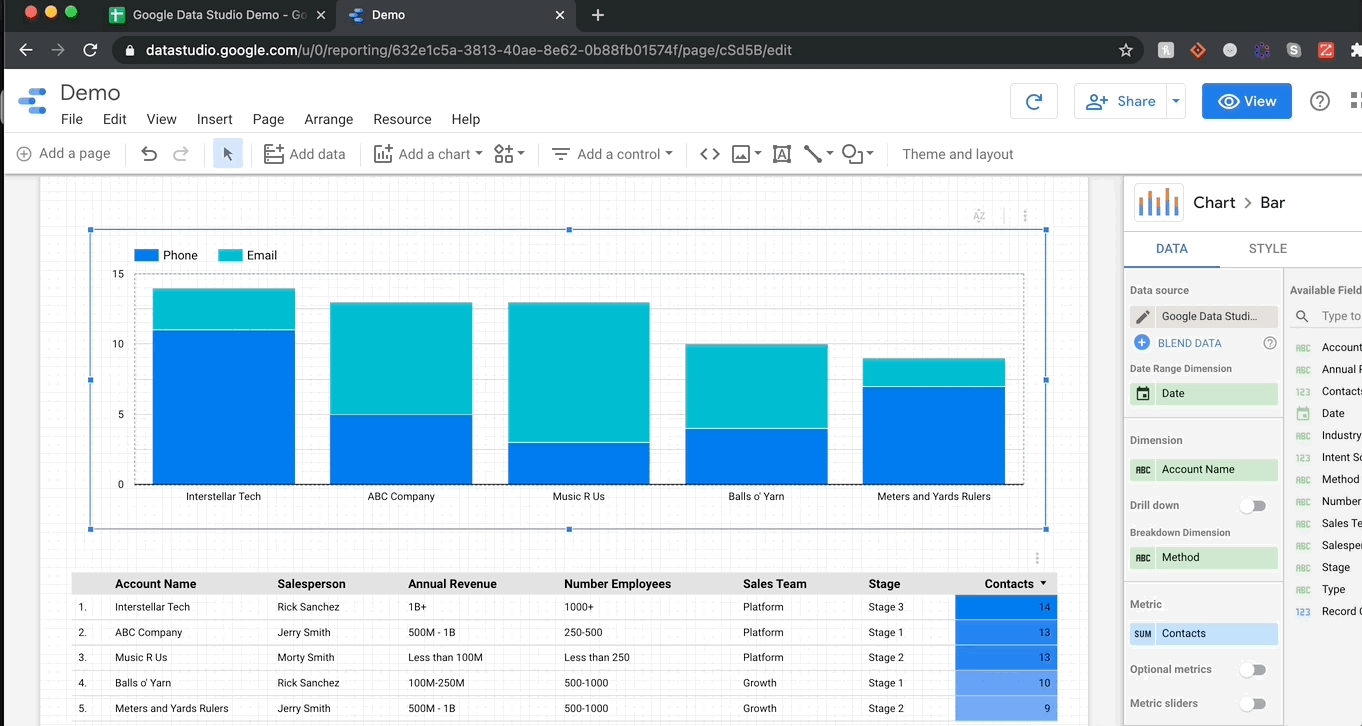
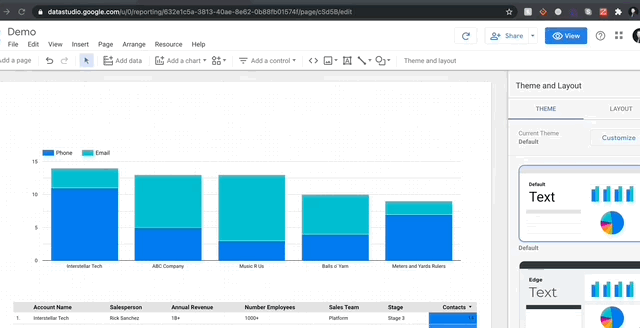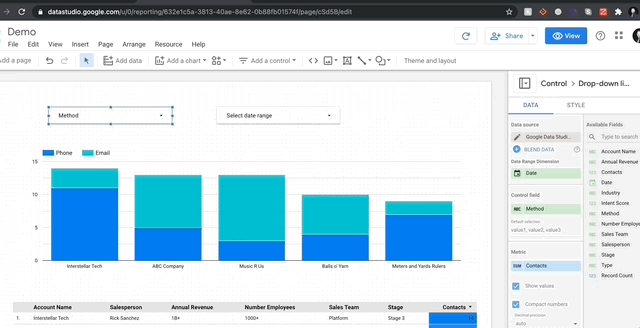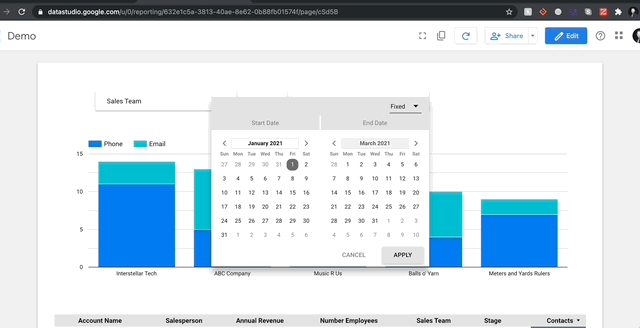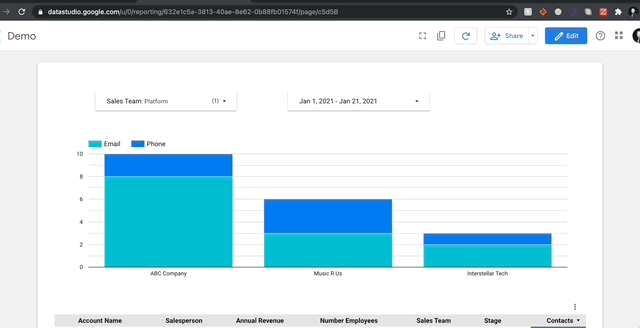
GDS에서 시각화하는 것이 얼마나 쉽게 가시적인지 당신에게 보여 드리겠습니다.여기에 누적 된 막대 차트를 내 보고서에 추가 한 다음 차원을 변경하여 계정 당 연락처 메소드의 분해를 볼 수 있도록 차원을 변경합니다.
그만큼 간단합니다!모든 차트는 메트릭 (파란색의 필드)을 통합하는 동안 열 (녹색의 필드)에서 데이터를 가져옵니다.숫자 열을 요약하려는 경우 메트릭으로 드래그하고 합계 (또는 평균, 중앙값, 최대 등)를 선택하십시오.오브젝트 열의 경우 셀 수 또는 계산 옵션이 있습니다.마지막으로 날짜 범위에 특별히 특정 차원이 있으며 GDS가 정말로 재미있는 곳입니다.
3 단계 : 필터
누구나 팀에게 기성품 그래프가있는 PowerPoint를 제공 할 수 있지만 GDS는 하나 더 나아갑니다.이 프로그램은 모든 팀원에게 완전히 대화식이되도록 설계되었으며 해당 상호 작용은 필터 형태를 취합니다.대부분의 프로그램에서 3 개의 영업 팀이있는 경우 각 팀에 대해 다른 보고서를 만들어야하지만 GDS에서는 단추 클릭시 보고서를 변경하기 위해 필터를 만들 수 있습니다.필터는 데이터의 모든 열을 제어 할 수 있습니다.
도 3a필터 제어 상자
왼쪽에서 사용할 수있는 기본 대화 형 필터를 볼 수 있습니다.나는 일반적으로 거의 모든 것을 위해 드롭 다운을 사용합니다. 나는 당신이 놀아주고 어떤 일을하는 것을 볼 것을 권장합니다.모든 필터에 대해 제어 할 열을 선택한 다음 원하는 메트릭을 선택하여 열을 차별화하는 것을 표시하도록 선택합니다.판매 팀의 계정 만 보려고하고 싶습니다.보고 싶은 메트릭은 해당 카테고리에있는 다른 계정이 얼마나 많은 다른 계정이 있는지입니다.해야 할 일은 메트릭으로 ‘계정 이름’을 선택한 다음 집계를 설정하여 뚜렷하게 계산됩니다.그리고 그게 다야!다음은 다음을 수행하는 방법입니다.
보고서 요소를 그룹화하여 차트에 어떤 영향을 미치는 필터를 제어 할 수도 있습니다.그룹화가 없으면 필터는 공유 데이터 소스가있는 모든 것에 영향을 미치지 만 그룹화를 사용하면 사용자 친화적 인 복잡한 보고서를 만들 수 있습니다.또한 적용 할 수있는 옵션이 있습니다고정 필터모든 보고서 객체 에서이 필터를 전체 그룹에 적용 할 수있는 옵션이 있습니다.
3b.날짜 제어
GDS의 가장 유용한 요소 중 하나는 라이브보고 기능입니다.Google Analytics 데이터 소스를 연결하면 웹 사이트에서 직접 라이브 데이터를 직접 가져 와서 보고서를 기반으로이를 집계합니다.부여 된 일부 데이터 커넥터는 다른 것보다 훨씬 빠릅니다 (CSV 파일 업로드는 내 경험에서 가장 빠른 경향이 있지만 데이터 업데이트는 수동입니다).즉, 종단 데이터를 주시하면 날짜 범위가 중요 할 수 있습니다.GDS는 날짜 컬럼을 자동으로 자동으로 숙달하지만 열에도 문제가 해결 되더라도 ParsEdate () 함수를 사용하여 항상 사용자 정의 필드를 만들 수 있습니다.나는 다른 게시물을위한 이제 사용자 정의 필드에 들어 가지 않을 것입니다.하지만 DateTime 열이나 ‘yyyy-mm-dd’gds 형식의 객체 열을 전달하면이 글을 괜찮습니다.NULL이있는 경우.
날짜 제어는 모든 차트 및 필드의 특정 데이터 필드에 영향을줍니다.귀하의 보고서에 어떤 물체에 상관없이, 모두 ‘날짜 범위’옵션이 있습니다.기간도 그룹에 적용 할 수도 있습니다.거기에서 지난 주 또는 지난 수요일 47 일 전에 복잡 할 수있는 기본 날짜 범위를 설정할 수 있습니다.
3C.필터 적용
내 마지막 작은 필터 피치는 모든 차트 개체에 ‘필터 적용’으로 표시된 Genius 버튼입니다.이 버튼을 켤 때 표 또는 차트의 열에서 행을 클릭하면 보고서가 해당 개체를 기반으로 자동으로 필터링됩니다.확인 해봐:
그것은 쉽습니다!바라건대 당신은이 무료,이 무료로 사용할 수있는 도구가 얼마나 많은 도구가 있는지를 볼 수 있습니다.
결론
Google Data Studio는 내 삶을 내 팀의 유일한 데이터 녀석으로 변경했지만 확실히 한계가 있습니다.저는 강점과 단점에 대해 훨씬 더 많이 쓰는 것을 계획하고 있으며, 데이터를 혼합하는 동안 발견 된 도움이되는 How-TOS에 대해 훨씬 더 많이 쓰고 있습니다.다음은 GDS를 강력하게 만드는 것에 대한 간략한 개요입니다.
전문가
믿을 수 없을만큼 사용하기 쉽습니다 (비 데이터 사람들에게도)
견고한 문서가있는 다양한 데이터 커넥터
비어 있는
팀 내에서 개인 데이터 공유를 위해 우수합니다
매우 사용자 정의 할 수있는 대화 형 보고서
동일한 필드 기능을 Google Sheet / Excel로 사용하고 쉽게 참조 할 수 있도록 DocStrings를 제공합니다.
아름다운 동적 차트
필터는 입학 가격의 가격에 가치가 있습니다
코딩 필요 없음
단점들
보고서에 강제로 강요하기 전에 데이터를 알아야합니다.
Google 360으로 업그레이드하지 않고 업로드 크기에 대한 제한 사항이 있습니다 (1 년에 150k 달러 비용이 듭니다!)
문서 및 포럼 외부의 기술 지원 없음
데이터 소스를 병합하는 것은 극단적 인 제한 사항 (즉, 여러 조인 키를 사용하는 여러 데이터 소스에 가입 할 수 없습니다. 모든 테이블에는 공통 조인 열이 있어야 함).
때로는 휴식을 취하고 오류 메시지는 최고로 암호입니다.
전반적으로 Google Data Studio는 Data Science-Lite와 같은 느낌이지만 팀 (Beta에있는 팀을위한 팀 외부) 나는 비 데이터 팀 동료를 사용하여 아름답고 복잡한 대화 형 보고서를 공유하기위한 더 쉽고 쉬운 옵션을 찾지 못했습니다.
COSMOS는 비동기 워크 플로우 및 서버리스 함수로 MicroServices의 최상의 측면을 결합한 컴퓨팅 플랫폼입니다.그것의 달콤한 지점은 복잡한, 복잡한 계층 적 워크 플로우를 통해 조정 된 리소스 집약적 인 알고리즘을 분량에서 몇 년 사이에 포함하는 응용 프로그램입니다.그것은 한 번에 수십만 개의 CPU를 소비하는 높은 처리량 서비스와 인간이 계산 결과를 기다리고있는 대기 시간에 민감한 작업 부하를 모두 지원합니다.
코스모스 서비스
이 기사에서는 우리가 코스모스를 지은 이유, 어떻게 작동하는지, 우리가 방해받은 것들 중 일부를 공유하는 이유를 설명합니다.
배경
Netflix의 미디어 클라우드 엔지니어링 및 인코딩 기술 팀은 시스템을 공동으로 운영하여 수신 미디어 파일을 파트너와 스튜디오에서그들을 놀아 라모든 장치에서.이 시스템의 첫 번째 세대는 2007 년 스트리밍 출시와 함께 살아갔습니다. 2 세대 추가 된 규모는 작동하기가 매우 어렵습니다.세 번째 세대,다시로드되었습니다, 약 7 년 동안 온라인이었으며 안정적이지 않은 것으로 입증되었습니다.대규모 확장 가능…에
리로드가 설계되었을 때 우리는 제한된 컴퓨팅 클러스터를 운영하는 소규모 개발자 팀이었고 하나의 사용 사례에 중점을 둡니다 : 비디오 / 오디오 처리 파이프 라인.시간이 3 배 이상의 개발자의 수를 통과 할 때, 우리의 사용 사례의 폭과 깊이가 확장되었고, 우리의 규모는 10 배 이상 증가했습니다.모 놀리 식 아키텍처는 새로운 기능의 전달을 크게 느려졌습니다.우리는 더 이상 모든 사람들이 새로운 기능을 구축하고 배포하는 데 필요한 전문 지식을 소유 할 것을 기대할 수 없었습니다.생산 문제를 다루는 것은 인프라 코드가 모두 응용 프로그램 코드와 섞여 있기 때문에 모든 개발자에게 세금을 쌓은 값 비싼 잡초가되었습니다.우리가 소규모 팀이었을 때 우리를 잘 게재 한 중앙 집중식 데이터 모델은 책임이되었습니다.
우리의 대응은 워크 플로우 중심 마이크로 서비스를위한 플랫폼 인 Cosmos를 만드는 것이 었습니다.1 차 목표는 우리의 현재의 역량을 보존하는 것이 었습니다.
관측 가능 – 내장 로깅, 추적, 모니터링, 경고 및 오류 분류를 통해.
모듈성 – 서비스를 구성하고 컴파일 타임 및 런타임 모듈성을 모두 사용하는 의견이있는 프레임 워크입니다.
생산성 – 전문화 된 테스트 러너, 코드 생성기 및 명령 줄 인터페이스를 포함한 로컬 개발 도구.
배달 – 파이프 라인의 완전 관리 된 연속 배달 시스템, 지속적인 통합 작업 및 종료 테스트 종료 시스템.끌어 오기 요청을 합병하면 수동 개입 없이는 생산할 수 있습니다.
우리는 그것이 있었지만, 우리는 또한 확장 성, 신뢰성, 보안 및 기타 시스템 자질을 개선했습니다.
개요
코스모스 서비스는 마이크로 서비스가 아니지만 유사점이 있습니다.전형적인 마이크로 서비스는 요청 부하를 기반으로 자동 입학을 기반으로하는 상태 비 저장 비즈니스 로직이있는 API입니다.API는 다른 시스템에서 응용 프로그램 데이터 및 이진 종속성을 분리하면서 동료와 강력한 계약을 제공합니다.
전형적인 마이크로 서비스
코스모스 서비스는 마이크로 서비스의 강력한 계약 및 분리 된 데이터 / 종속성을 유지하지만 다단 워크 플로우 및 계산식 집약적 인 비동기식 서버가없는 기능을 추가합니다.일반적인 Cosmos 서비스의 아래 다이어그램에서 클라이언트는 비디오 인코더 서비스 API 레이어에 요청을 전송합니다.일련의 규칙은 워크 플로 단계 단계와 서버가없는 함수 집합 전원 특정 알고리즘을 조정합니다.기능은 Docker 이미지로 패키지화되어 있으며 자체 미디어 특정 이진 종속성 (예 : 데비안 패키지)을 가져옵니다.큐 크기에 따라 크기가 조정되며 수만 개의 다른 용기를 사용할 수 있습니다.요청은 몇 시간 또는 며칠이 걸릴 수 있습니다.
전형적인 코스모스 서비스
우려의 분리
코스모스에는 두 가지 분리가 있습니다.한편으로는 API, Workflow 및 Serverless 함수간에 논리가 나뉩니다.반면에 논리는 응용 프로그램과 플랫폼간에 분리됩니다.플랫폼 API는 분산 컴퓨팅의 세부 사항을 숨기면서 응용 프로그램 개발자에게 미디어 특정 추상화를 제공합니다.예를 들어, 비디오 인코딩 서비스는 API, 워크 플로 및 함수의 scale-agnostic 인 구성 요소로 구성됩니다.그들이 달리는 규모에 대한 특별한 지식은 없습니다.이러한 도메인 별 특정 스케일 – 불가지론 구성 요소는 3 개의 맨 위에 구축됩니다.규모 인식작업 분배의 세부 사항을 처리하는 Cosmos 서브 시스템 :
서브 시스템은 모두 타임 스톤을 통해 서로 비동기 적으로 서로 통신하며, 하이 스케일, 낮은 대기 시간 우선 순위 큐 시스템.각 하위 시스템은 서비스의 다른 관심사를 해결하고 목적으로 구축 된 관리 지속적인 전달 프로세스를 통해 독립적으로 배포 할 수 있습니다.이러한 우려를 분리하면 Cosmos 서비스를 작성, 테스트 및 운영하기가 더 쉽습니다.
플랫폼 및 응용 프로그램의 분리
코스모스 서비스 요청
Cosmos 서비스 요청의 추적 그래프
위의 그림은 Nirvana의 스크린 샷, 우리의 관찰 능력 포털입니다.그것은 Cosmos (이 경우 비디오 인코더 서비스)에서 일반적인 서비스 요청을 보여줍니다.
인코딩에 대한 하나의 API 호출이 있으며, 비디오 소스와 레시피가 포함되어 있습니다.
비디오는 31 덩어리로 나뉩니다. 31 개의 인코딩 기능이 병렬로 실행됩니다.
어셈블 함수가 한 번 호출됩니다
인덱스 기능이 한 번 호출됩니다
워크 플로가 8 분 후에 완료됩니다
서비스 레이어징
Cosmos는 서비스의 분해 및 레이어징을 지원합니다.결과적으로 모듈 식 아키텍처를 통해 팀은 전문 분야에 집중하고 API를 방출하고주기를 방출 할 수 있습니다.
예를 들어, 위에서 언급 한 비디오 서비스는 장치에서 재생할 수있는 스트림을 만드는 데 사용되는 많은 것 중 하나 일뿐입니다.이러한 서비스는 검사, 오디오, 텍스트 및 패키징을 포함하여 상위 수준의 서비스를 사용하여 조율됩니다.이들 중 가장 크고 가장 복잡하고 이들은 스튜디오에서 출처를 가져 와서 Netflix 서비스에서 재생할 수있는 Tapas입니다.또 다른 높은 수준의 서비스는 마케팅 클립이나 일일 생산 편집 프록시와 같은 스튜디오 운영에 사용되는 Sagan입니다.
코스모스 서비스의 레이어링
프로덕션 스튜디오에서 새 제목이 도착하면 검사를 수행하고 비디오를 인코딩하는 요청 (여러 해상도, 자질 및 비디오 코덱), 오디오 (여러 자질 및 코덱)를 인코딩하고 자막 (많은 언어)을 생성하는 요청을 조정하는 타파스 워크 플로를 트리거합니다.및 패키지 결과 출력 (다중 플레이어 형식).따라서 TAPAS에 대한 단일 요청은 다른 코스모스 서비스와 수천 개의 계층 기능 호출에 수백 가지의 요청을 초래할 수 있습니다.
아래 추적은 최상위 서비스의 요청이 낮은 수준의 서비스로 내려갈 수있는 방법의 예를 보여줍니다.이 경우 요청은 8 가지 다른 코스모스 서비스와 9 가지의 계층 기능을 포함하는 수백 가지의 다른 조치가 완료 될 때 24 분이 걸렸습니다.
여러 레이어를 통해 서비스 요청의 추적 그래프
워크 플로우 규칙!
또는 우리는 말해야합니까?워크 플로우 규칙~을 빼앗아가는 것플라톤은 서비스 개발자가 도메인 논리를 정의하고 상태 비 저장 함수 / 서비스를 조정할 수있는 프레임 워크를 제공하여 Cosmos에서 모든 것을 함께 묶는 접착제입니다.Optimus API 레이어에는 워크 플로를 호출하고 상태를 검사하는 기본 기능이 내장되어 있습니다.Stratum Serverless Layer는 서버없는 함수를 쉽고 직관적으로 호출하기 위해 강력한 유형의 RPC 클라이언트를 생성합니다.
Plato는 우리의 알고리즘의 비동기적이고 계산 된 집중적 인 성격을 빌려하는 전방 체인 규칙 엔진입니다.절차 워크 플로우 엔진과 달리Netflix의 도체Plato를 사용하면 “항상 켜짐”인 워크 플로를 쉽게 만들 수 있습니다.예를 들어,보다 나은 인코딩 알고리즘을 개발할 때, 규칙 기반 워크 플로는 새로운 워크 플로를 트리거하고 관리 할 필요없이 기존 비디오 업데이트를 자동으로 관리합니다.또한 워크 플로가 다른 서비스를 호출 할 수 있으므로 위에서 언급 한 서비스 레이어를 사용할 수 있습니다.
플라톤은 다단계 시스템입니다 (사용법Apache Karaf.), 워크 플로우 운영의 운영 부담을 크게 줄입니다.사용자는 자신의 규칙을 자신의 소스 코드 저장소로 쓰고 테스트 한 다음 컴파일 된 코드를 플라톤 서버에 업로드하여 워크 플로를 배포합니다.
개발자는 EmiRax로 작성된 일련의 워크 플로우 인 Emirax로 작성된 도메인 특정 언어 인 워크 플로를 지정합니다.각 규칙에는 4 개의 섹션이 있습니다.
일치 :이 규칙에 대해 만족 해야하는 조건을 트리거합니다.
조치 :이 규칙이 트리거 될 때 실행될 코드를 지정합니다.이는 요청을 처리하기 위해 계층화 함수를 호출하는 위치입니다.
반응 : 조치 코드가 성공적으로 완료 될 때 실행될 코드를 지정합니다.
오류 : 오류가 발생했을 때 실행할 코드를 지정합니다.
이러한 각 섹션에서 일반적으로 먼저 워크 플로우의 변경 사항을 기록한 다음 워크 플로우를 실행하거나 실행 결과를 반환하는 것과 같이 워크 플로를 전달하는 단계를 수행합니다 (자세한 내용은이 프리젠 테이션짐마자
대기 시간에 민감한 응용 프로그램
Sagan과 같은 코스모스 서비스는 사용자가 직면하기 때문에 대기 시간에 민감합니다.예를 들어, 소셜 미디어 게시물에서 일하는 아티스트는의 최신 시즌에서 비디오를 클리핑 할 때 오랜 시간을 기다리고 싶지 않습니다.돈을 강조하고…에계층의 경우, 대기 시간은작업을 수행 할 시간더하기컴퓨팅 리소스를 얻는 시간…에일이 매우 파열되면 (종종 사례), “리소스를 얻는 시간“구성 요소가 중요한 요소가됩니다.일러스트레이션을 위해 쇼핑을 할 때 일반적으로 구매할 것들 중 하나가 화장지입니다.일반적으로 장바구니에 문제가없고 체크 아웃 라인을 통과하는 데 아무런 문제가 없으며 전체 프로세스가 30 분이 걸립니다.
자원 희소성
그런 다음 어느 날 나쁜 바이러스 일이 일어납니다여러분동시에 더 많은 화장지가 필요합니다.너의화장지 대기 시간전반적인 수요가 사용 가능한 용량을 초과했기 때문에 30 분에서 2 주간의 경우코스모스 어플리케이션 (특히 층수 함수)은 파열 및 예측 불가능한 수요에 직면하여 동일한 문제가 있습니다.stratum 관리기능 실행 대기 시간몇 가지 방법으로 :
자원 풀.최종 사용자는 자신의 비즈니스 유스 케이스에 대해 계층 컴퓨팅 리소스를 예약 할 수 있으며, 사용자 그룹이 리소스를 공유 할 수 있도록 클립 풀이 계층 적입니다.
따뜻한 용량…에최종 사용자는 계층에서 시동 대기 시간을 줄이기 위해 수요가 발생하기 위해 컴퓨팅 리소스 (예 : 컨테이너)를 요청할 수 있습니다.
마이크로 배치…에Stratum은 또한 시동 대기 시간을 줄이기 위해 Apache Spark와 같은 플랫폼에서 발견되는 트릭 인 마이크로 배치를 사용합니다.아이디어는 많은 기능 호출에 대한 시작 비용을 전파하는 것입니다.기능을 10,000 번 입력하면 10,000 개의 컨테이너에서 한 번 실행되거나 1000 개의 컨테이너에서 각각 10 배로 실행될 수 있습니다.
우선 순위.대기 시간 저 대기 시간에 대한 욕구로 비용을 균형을 조정할 때, 보통 중간 어딘가에 착륙하는 것이 일반적으로 전형적인 버스트를 다루는 충분한 자원이지만 가장 낮은 대기 시간으로 가장 큰 버스트를 처리하기에 충분하지 않습니다.업무의 우선 순위를 지정함으로써 응용 프로그램은 자원이 부족한 경우에도 가장 중요한 작업이 낮은 대기 시간으로 가장 중요한 작업을 처리 할 수 있습니다.Cosmos 서비스 소유자는 최종 사용자가 우선 순위를 설정하거나 API 계층 또는 워크 플로에서 스스로 설정할 수 있습니다.
처리 민감한 응용 프로그램
Tapas와 같은 서비스는 많은 양의 컴퓨팅 리소스 (예 : 하루 당 수백만의 CPU 시간)를 소비하고 개별 작업을 완료하는 데 시간이 아닌 시간 또는 며칠 동안 작업 완료와 관련하여 더 관련이 있습니다….에즉, 서비스 수준 목표 (SLO)는하루에 작업과작업 당 비용대신초당 작업…에
처리량에 민감한 작업 부하의 경우 가장 중요한 SLO는 Stratum Serverless Layer에서 제공하는 것입니다.Stratum, 그 꼭대기에 지어졌습니다Titus 컨테이너 플랫폼이를 위해 민감한 작업 부하가 유연한 자원 스케줄링을 통해 “기회 주의적”계산 리소스를 사용할 수 있습니다.예를 들어, 서버가없는 함수 호출 비용은 최대 1 시간까지 기다릴 수있는 경우가 낮아질 수 있습니다.
strangler 그림
우리는 레거시 시스템을 재 장전하는 것처럼 크고 복잡한 것처럼 유산 시스템을 움직이는 것으로 알고 있었지만, 실패한 재 공학 프로젝트의 파편이 흩어져있는 위험한 틈에 큰 도약이 될 것이라는 것을 알고 있었지만, 우리가 뛰어 내려야하는 질문은 없었습니다.위험을 줄이려면 우리는 그를 채택했습니다strangler 무화과 패턴새로운 시스템이 오래된 시스템을 돌아서 결국 완전히 대체 할 수 있습니다.
아직도 배우는 것
우리는 2018 년에 코스모스를 건설하기 시작했으며 2019 년 초부터 생산 중이 었습니다. 오늘날 약 40 개의 코스모스 서비스가 있으며 더 많은 성장이 올 것으로 예상됩니다.우리는 여전히 중간 여정에 있지만 지금까지 우리가 배웠던 것의 몇 가지 주요 조명을 공유 할 수 있습니다.
Netflix 엔지니어링 문화는 유명하게 하향식 제어가 아닌 개인적인 판단을 유의합니다.소프트웨어 개발자는 위험을 감수하고 의사 결정을 내리는 자유와 책임을 모두 가지고 있습니다.우리 중 누구도 소프트웨어 설계자의 제목이 없습니다.우리 모두는 그 역할을합니다.이러한 맥락에서 우주가 적합하게 등장하고 현지 최적화 시점에서의 다른 시도에서 시작합니다.Optimus, Plato 및 Stratum은 독립적으로 잉태하여 결국 단일 플랫폼의 비전으로 합쳐졌습니다.팀의 응용 프로그램 개발자는 사용자 친화적 인 API 및 개발자 생산성에 중점을 둡니다.인프라와 미디어 알고리즘 개발자 간의 강력한 파트너십을 현실로 전환시킵니다.우리는 하향식 엔지니어링 환경에서 그것을 할 수 없었습니다.
microservice + workflow + serverless
우리는 “프로그래밍 모델”서버가없는 기능을 조정하는 워크 플로를 트리거하는 MicroServices“강력한 패러다임이 될 것입니다.대부분의 사용 사례에서 잘 작동하지만 일부 응용 프로그램은 추가 된 복잡성이 이점의 가치가없는 것으로 간단합니다.
플랫폼 사고 방식
대형 분산 응용 프로그램에서 “플랫폼 플러스 응용 프로그램”으로 이동하는 것은 주요 패러다임 변화였습니다.모두가 그들의 사고 방식을 바꾸어야했습니다.응용 프로그램 개발자는 일관성, 신뢰성 등을 대가로 일정량의 유연성을 포기해야했습니다. 플랫폼 개발자는 더 많은 공감을 개발하고 고객 서비스, 사용자 생산성 및 서비스 수준을 우선 순위를 지정해야했습니다.애플리케이션 개발자가 플랫폼 팀이 자신의 필요에 따라 적절하게 집중하지 않고 플랫폼 팀이 사용자 요구에 의해 지나치게 느껴지는 기타 시간을 느꼈던 순간이있었습니다.우리는 서로 열려 있고 정직하게함으로써 이러한 어려운 반점을 겪었습니다.예를 들어 최근의 회고전 이후, 우리는 개발자 경험, 신뢰성, 관찰 가능성 및 보안과 같은 크로스 커팅 시스템 특성에 대한 개발 트랙을 강화했습니다.
플랫폼이 승리합니다
우리는 개발자가 비즈니스 문제에 더 많은 시간을 보내고 인프라를 다루는 데 더 많은 시간을 보내고 개발자가 더 효과적이고 더 빠르고 더 빨리 일할 수 있도록하는 목표로 코스모스를 시작했습니다.때때로 목표는 어려운 것처럼 보였지만 우리는 우리가 희망 한 이득을보기 시작했습니다.개발자가 코스모스에서 가장 좋아하는 시스템 특성 중 일부는 전달, 모듈성 및 관찰 가능성 및 개발자 지원을 관리합니다.우리는 이러한 자질을 더 잘 만들기 위해 노력하고 있으며 현지 개발, 탄력성 및 테스트 가능성과 같은 약한 영역에서 일하고 있습니다.
미래의 계획
2021은 대다수의 일을 우주로 재로드 한 것으로, 더 많은 개발자와 훨씬 더 높은 부하로 옮겨가는 것처럼 Cosmos의 큰 해가 될 것입니다.우리는 새로운 유스 케이스를 수용하기 위해 프로그래밍 모델을 발전시킬 계획입니다.우리의 목표는 코스모스를 사용하기 쉽고,보다 탄력적이며 더 효율적이고 효율적으로 더욱 쉽게 사용할 수있는 것입니다.Cosmos가 작동하는 방법과 우리가 어떻게 사용하는 방법에 대한 자세한 내용은 자세한 내용을 알아보십시오.
Pandas는 표 형식의 중소 규모 데이터로 데이터 분석 및 조작 작업을 지배하고 있습니다.데이터 과학 생태계에서 가장 인기있는 라이브러리입니다.
저는 Pandas의 열렬한 팬이며 데이터 과학 여정을 시작한 이래로 Pandas를 사용해 왔습니다.나는 지금까지 그것을 좋아하지만 Pandas에 대한 나의 열정은 내가 다른 도구를 시도하는 것을 방해하지 않아야합니다.
나는 다른 것을 비교하는 것을 좋아한다도구 및 라이브러리.내 비교 방법은 둘 다에 대해 동일한 작업을 수행하는 것입니다.나는 보통 내가 이미 알고있는 것을 내가 배우고 싶은 새로운 것과 비교한다.새로운 도구를 배우게 할뿐만 아니라 이미 알고있는 것을 연습하는데도 도움이됩니다.
제 동료 중 한 명이 저에게 R 용 “data.table”패키지를 사용해 보라고했습니다. 그는 데이터 분석 및 조작 작업에 대해 Pandas보다 더 효율적이라고 주장했습니다.그래서 나는 그것을 시도했습니다.”data.table”을 사용하여 특정 작업을 수행하는 것이 얼마나 간단한 지 감명을 받았습니다.
이 기사에서는 Pandas와 data.table을 비교하기 위해 몇 가지 예를 살펴 보겠습니다.데이터 분석 라이브러리의 기본 선택을 Pandas에서 data.table로 변경해야하는지 여전히 논쟁 중입니다.그러나 data.table이 Pandas를 대체하는 첫 번째 후보라고 말할 수 있습니다.
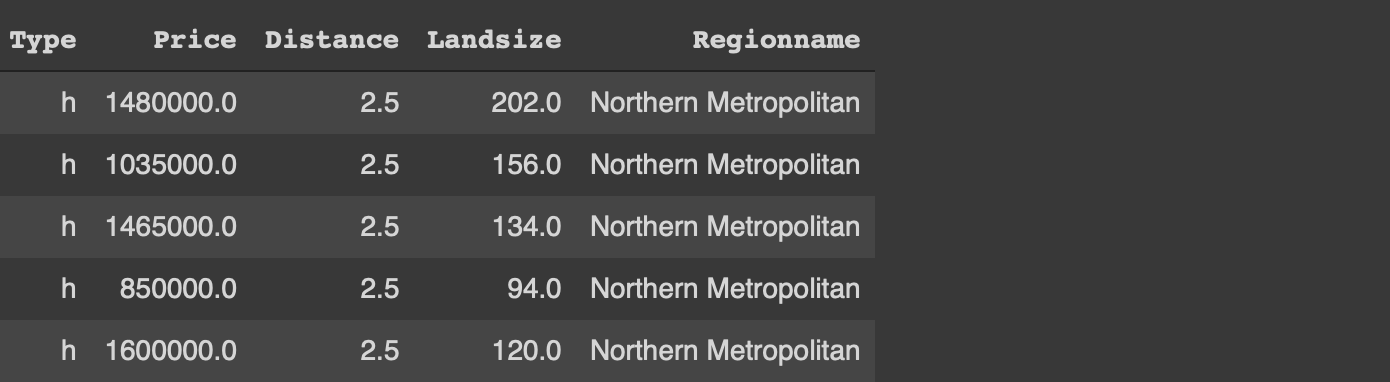
더 이상 고민하지 않고 예제부터 시작하겠습니다.멜버른 주택의 작은 샘플을 사용합니다.데이터 세트예제는 Kaggle에서 사용할 수 있습니다.
첫 번째 단계는 각각 Pandas 및 data.table에 대한 read_csv 및 fread 함수에 의해 수행되는 데이터 세트를 읽는 것입니다.구문은 거의 동일합니다.
필터링 구성 요소는 data.table과 동일한 대괄호로 지정됩니다.반면에 Pandas의 다른 모든 작업보다 먼저 필터링을 수행해야합니다.
결론
이 기사에서 다루는 내용은 일반적인 데이터 분석 프로세스에서 수행되는 일반적인 작업입니다.물론이 두 라이브러리가 제공하는 더 많은 기능이 있습니다.따라서이 기사는 포괄적 인 비교가 아닙니다.그러나 두 가지 모두에서 작업을 처리하는 방법에 대한 일부 정보를 제공합니다.
특정 작업을 완료하기위한 구문과 접근 방식에만 집중했습니다.메모리 및 속도와 같은 성능 관련 문제는 아직 발견되지 않았습니다.
요약하면 data.table은 나를 위해 Pandas를 대체 할 수있는 강력한 후보라고 생각합니다.또한 자주 사용하는 다른 라이브러리에 따라 다릅니다.Python 라이브러리를 많이 사용하는 경우 Pandas를 고수하는 것이 좋습니다.그러나 data.table은 확실히 시도해 볼 가치가 있습니다.
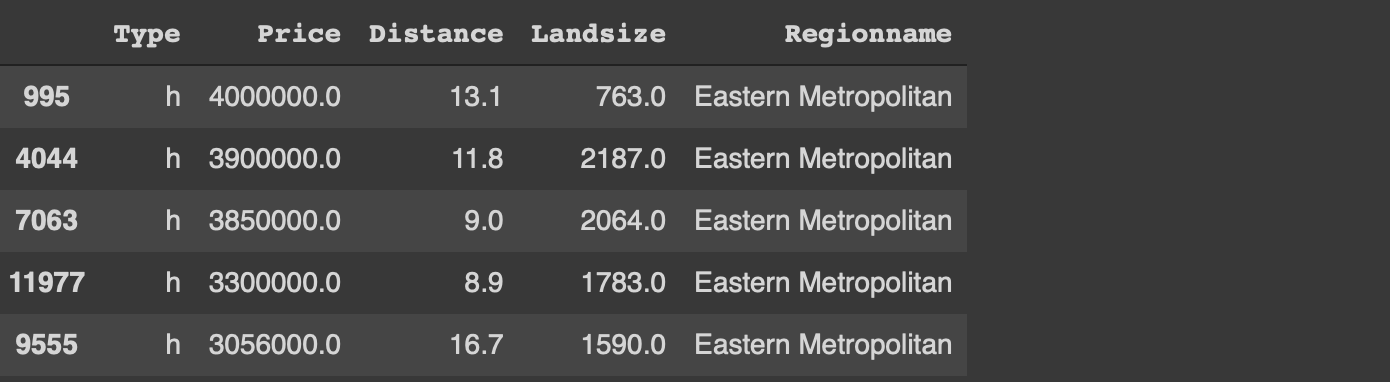
원본의 일부만 읽었습니다.데이터 세트.read_csv 함수의 usecols 매개 변수를 사용하면 csv 파일의 지정된 열만 읽을 수 있습니다.또한 가격 및 토지 크기와 관련하여 이상 값을 필터링했습니다.마지막으로 sample 함수를 사용하여 1000 개의 관측치 (즉, 행)의 무작위 표본을 선택합니다.
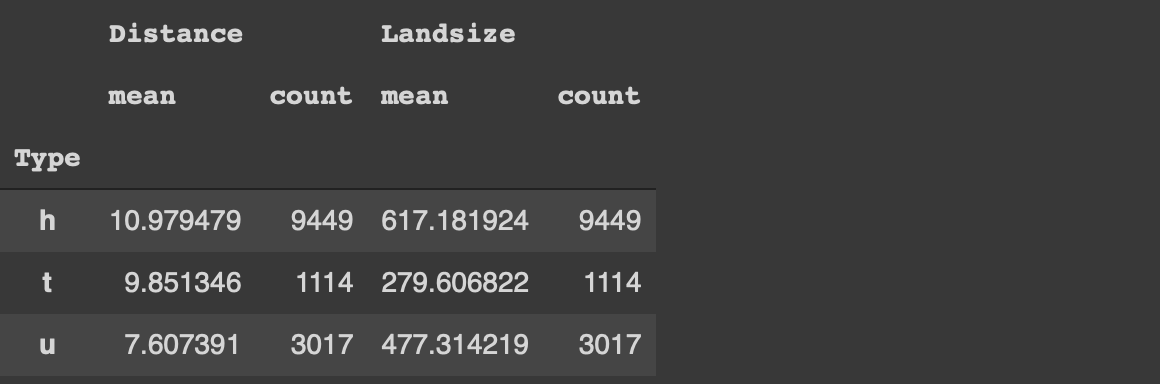
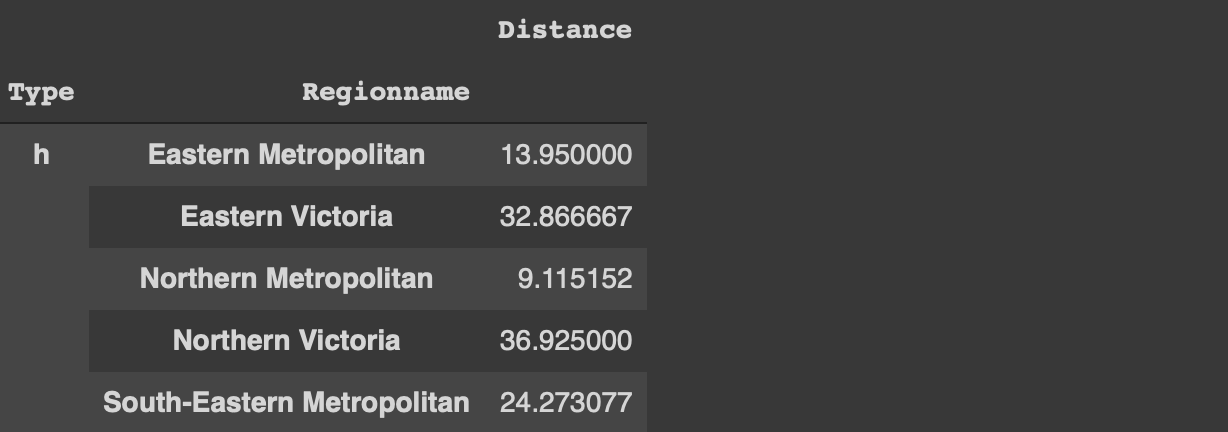
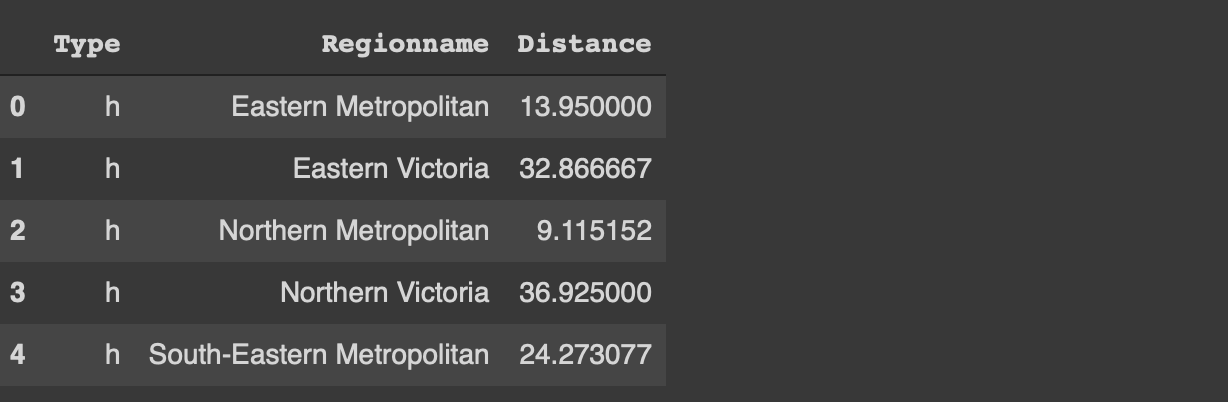
팁을 시작하기 전에 유형 열의 각 범주에 대한 평균 거리를 수행하는 간단한 groupby 함수를 구현해 보겠습니다.
df [[ 'Type', 'Distance']]. groupby ( 'Type'). mean ()
(image by author)
주택 (h)은 평균적으로 다른 두 유형보다 중앙 비즈니스 지구에서 더 멀리 떨어져 있습니다.
이제 groupby 기능을보다 효과적으로 사용하기위한 팁부터 시작할 수 있습니다.
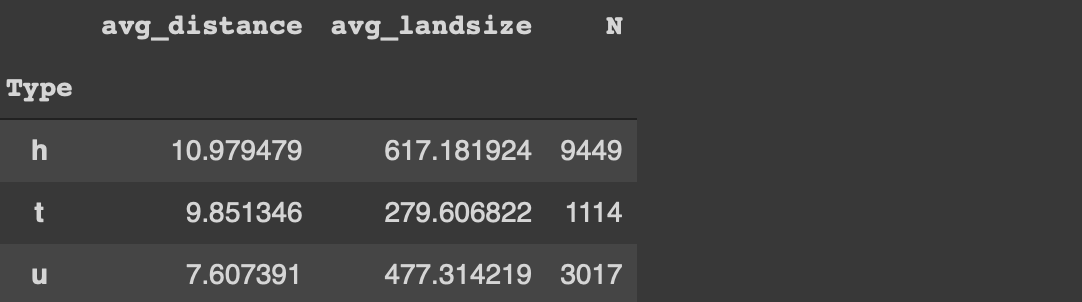
1. 열 이름 사용자 지정
groupby 함수는 열 이름을 변경하거나 사용자 지정하지 않으므로 집계 된 값이 무엇을 나타내는 지 실제로 알 수 없습니다.예를 들어, 이전 예에서는 열 이름을 “distance”에서 “avg_distance”로 변경하는 것이 더 유익합니다.
노트북은 항상 소프트웨어 아이디어의 점진적 개발을위한 도구였습니다.데이터 과학자는 Jupyter를 사용하여 작업을 저널링하고, 새로운 알고리즘을 탐색 및 실험하고, 새로운 접근 방식을 빠르게 스케치하고, 결과를 즉시 관찰합니다.
이러한 상호 작용이 Jupyter를 매력적으로 만드는 이유입니다.한 단계 더 나아가 데이터 과학자는 Jupyter 위젯을 사용하여 결과를 시각화하거나 콘텐츠 탐색을 용이하게하거나 사용자 상호 작용을 장려하는 미니 웹 앱을 만듭니다.
하나,IPyWidgets아니티항상 작업하기 쉽습니다.이들은 프런트 엔드 개발자가 개척 한 선언적 디자인 원칙을 따르지 않으며 결과 구성 요소는 브라우저 환경에서 그대로 전송할 수 없습니다.또한 개발자는 대부분 데이터 과학자의 시각화 요구 사항을 충족하기 위해 이러한 라이브러리를 만들었습니다.따라서 React 및 Vue와 같은 인기있는 프런트 엔드 프레임 워크가 제공하는 기능이 부족합니다.
다음 단계를 밟아야 할 때입니다.이 스토리에서는 대화 형 웹 페이지를 정의 및 제어하거나 시각적 Jupyter 구성 요소를 만들기위한 라이브러리 집합 인 IDIOM을 소개합니다.후자에 대해 논의 할 것입니다.
학습률AI와 MLOps의 세계에 대해 궁금한 사람들을위한 뉴스 레터입니다.매주 금요일 최신 AI 뉴스 및 기사에 대한 업데이트와 의견을 들으실 수 있습니다. ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ구독여기!
IDOM : Python의 React 디자인 패턴
이제 IDOM을 시작하겠습니다.React에 익숙한 사람들은 IDOM이 작업하는 방식에서 많은 유사점을 찾을 수 있습니다.
Jupyter 내에서 간단한 TODO 애플리케이션을 만들 것입니다.예, 이것이 데이터 과학자에게 어떻게 도움이 될지 모르겠습니다.하지만 제가하려는 것은 IDOM의 능력을 보여주는 것입니다. ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ ㅇㅇㅇ데이터 과학 사용 사례를 찾으면 댓글에 남겨주세요!
첫째, 코드입니다.그런 다음 작동 방식을 이해하기 위해 한 번에 한 줄씩 살펴 보겠습니다.
그만큼idom.component데코레이터는구성 요소건설자.이 구성 요소는 그 아래에있는 함수를 사용하여 화면에서 렌더링됩니다 (예 :할 것()).그런 다음이를 표시하려면이 함수를 호출하고 끝에이 구성 요소의 인스턴스를 만들어야합니다.
이제이 함수의 기능에 대해 알아 보겠습니다.첫째,use_state ()기능은훅.이 메서드를 호출하면 현재 상태 값과이 상태를 업데이트하는 데 사용할 수있는 함수의 두 가지가 반환됩니다.우리의 경우 현재 상태는 빈 목록 일뿐입니다.
그런 다음 내부에서 업데이트 기능을 사용할 수 있습니다.add_new_task ()우리가 원하는 것을 할 수있는 방법.이 함수는 이벤트를 가져 와서 키보드를 눌러 이벤트가 생성되었는지 확인합니다.시작하다키.사실이면 이벤트 값을 검색하여 작업 목록에 추가합니다.
사용자가 생성 한 작업을 저장하기 위해 별도의작업간단한 삭제 버튼과 함께 Python 목록.삭제 버튼을 누르면remove_task ()함수는 다음과 같이 상태를 업데이트합니다.add_new_task ()함수.그러나 현재 상태에 새 항목을 추가하는 대신 선택한 항목을 제거합니다.
마지막으로 TODO 작업을 생성하기위한 input 요소와이를 보유 할 HTML 테이블 요소를 생성합니다.마지막 단계에서는divHTML 태그.
좋아진다
여태까지는 그런대로 잘됐다.그러나 IDOM이 제공하는 힘은 HTML 요소를 표시하는 데 국한되지 않습니다.IDOM의 진정한 힘은 모든 React 생태계 구성 요소를 원활하게 설치하고 사용할 수있는 능력에서 비롯됩니다.
이 예에서는승리, 모듈 식 차트 및 데이터 시각화를위한 일련의 React 구성 요소입니다.승리를 설치하기 위해 IDOM CLI를 사용할 수 있습니다.
! idom 설치 승리
그런 다음 코드에서 사용하겠습니다.
축하합니다!방금 다음을 사용하여 원형 차트를 만들었습니다.승리Jupyter 노트북에서!물론 기존 JavaScript 모듈을 가져 와서 사용하는 것도 간단합니다.방법보기선적 서류 비치.
결론
데이터 과학자는 Jupyter 위젯을 사용하여 결과를 시각화하거나 콘텐츠 탐색을 용이하게하거나 사용자 상호 작용을 장려하는 미니 웹 앱을 만듭니다.
하나,IPyWidgets작업하기가 항상 쉬운 것은 아닙니다.또한 몇 가지 단점이 있습니다. 선언적 설계 원칙을 따르지 않고 결과 구성 요소를 브라우저 환경에서 그대로 전송할 수 없습니다.
다음 단계를 밟아야 할 때입니다.이 스토리에서는 대화 형 웹 페이지를 정의 및 제어하거나 시각적 Jupyter 구성 요소를 만들기위한 라이브러리 집합 인 IDIOM을 살펴 보았습니다.
내 이름은디미트리 스 풀로 풀 로스, 저는 기계 학습 엔지니어로Arrikto.저는 European Commission, Eurostat, IMF, European Central Bank, OECD 및 IKEA와 같은 주요 고객을 위해 AI 및 소프트웨어 솔루션을 설계하고 구현했습니다.
Machine Learning, Deep Learning, Data Science 및 DataOps에 대한 더 많은 게시물을 읽고 싶다면 저를 팔로우하십시오.매질,LinkedIn, 또는뿡뿡트위터에서.또한자원내 웹 사이트의 페이지, 훌륭한 책과 최고 등급의 코스를위한 곳으로, 자신 만의 데이터 과학 커리큘럼을 구축하기 시작하세요!
조건부 확률 이론은 종종 특정 수학적 문제에 대한 독특하고 흥미로운 솔루션으로 이어집니다.복잡한 확률 문제를 비교적 간단하게 해결할 수있을 때 흥분과 불신이 섞여 있습니다.조건부 확률과 실험 결과를 중심으로 한 유명한 통계 시나리오 인 Gambler ‘s Ruin Problem의 경우는 확실히 해당됩니다.이 문제에 대해 훨씬 더 매력적인 것은 그 구조가 조건부 확률을 넘어 무작위 변수 및 분포로 확장된다는 것입니다. 특히 흥미로운 특성을 가진 고유 한 마르코프 체인의 적용으로 확장됩니다.
초등학교피강도 문제는 불확실한 결과에 대한 수학적 설명을 기반으로합니다.초등학교 통계는 복잡한 시나리오를 이해하고 정리를 사용하여 불확실한 결과의 확률을 결정하는 데 사용할 수있는 도구 세트를 제공합니다.도박꾼의 파멸 문제를 해결하는 것은 우리가 매일해야하는 일이 아니지만, 그 구조를 이해하면 불확실성에 뿌리를 둔 상황에 접근 할 때 비판적이고 수학적 사고 방식을 개발하는 데 도움이됩니다.
엔ote :이 게시물은 독자가 미적분과 선형 대수에 대한 노출을 필요로하는 기초 확률과 통계 이론을 이해해야합니다.또한 독자가 Markov 체인에 대한 몇 가지 기본 지식을 가지고 있다고 가정합니다.
문제 설명
가장 기본적인 형태의 Gambler ‘s Ruin Problem은 두 명의 도박꾼으로 구성됩니다.ㅏ과비확률 론적 게임을 여러 번하고 있습니다.게임을 할 때마다 확률이 있습니다피(0 & lt;피& lt;1) 그 도박꾼ㅏ도박꾼에게 이길 것이다비.마찬가지로 기본 확률 공리를 사용하여 도박꾼이비이길 것입니다 1-피.각 도박꾼은 또한 베팅 할 수있는 금액을 제한하는 초기 자산을 가지고 있습니다.총 결합 부는 다음과 같이 표시됩니다.케이그리고 도박꾼ㅏ초기 재산은나는, 이는 도박꾼이비초기 재산이k-나.부는 긍정적이어야합니다.이 문제에 적용하는 마지막 조건은 두 도박꾼이 둘 중 한 명이 초기 재산을 모두 잃어 더 이상 플레이 할 수 없을 때까지 무기한 플레이한다는 것입니다.
그 도박꾼을 상상해보십시오ㅏ의 초기 재산나는정수 달러 금액이며 각 게임은 1 달러로 진행됩니다.그건 도박꾼이ㅏ적어도 플레이해야 할 것입니다나는그들의 부를 0으로 떨어 뜨리는 게임.그들이 각 게임에서 1 달러를 이길 확률은피, 게임이 두 도박꾼 모두에게 공평하다면 1/2이됩니다.만약피& gt;1/2, 도박꾼ㅏ체계적인 이점이 있고피& lt;1/2 이후 도박꾼ㅏ체계적인 단점이 있습니다.일련의 게임은 두 가지 결과로만 끝날 수 있습니다. 도박꾼ㅏ풍부한케이달러 (도박꾼비모든 돈을 잃었습니다) 또는 도박꾼ㅏ0 달러의 부 (도박꾼비모든 부가 있습니다).분석의 주요 초점은 도박꾼이ㅏ풍부한으로 끝날 것입니다케이0 달러 대신 달러.결과에 관계없이 도박꾼 중 한 명이 재정적으로파멸, 따라서 이름도박꾼의 폐허.
문제 해결책
위에서 설명한 동일한 구조를 계속 사용하여 이제 확률을 결정하려고합니다.aᵢ그 도박꾼ㅏ끝날 것이다케이그들이 시작한 것을 감안할 때 달러나는불화.단순함을 위해 여기에 추가 가정을 추가하겠습니다. 모든 게임은 동일하고 독립적입니다.도박꾼이 새로운 게임을 할 때마다 가장 최근 게임의 결과에 따라 각 도박꾼의 초기 재산이 다른 Gambler ‘s Ruin 문제의 새로운 반복으로 해석 될 수 있습니다.수학적으로 우리는 도박꾼으로 끝나는 게임의 각 순서를 생각할 수 있습니다.ㅏ갖는제이어디 달러제이= 0,…,케이.확률 도박꾼ㅏ특정 시퀀스가 발생하면 승리합니다.aⱼ.도박꾼으로 끝나는 모든 시퀀스ㅏ갖는케이달러는 그들이 이겼 음을 의미하므로aₖ= 1.마찬가지로 도박꾼으로 끝나는 모든 시퀀스ㅏ0 달러는 그들이 파멸에 빠졌다는 것을 의미하므로ㅏ₀ = 0.우리는 모든 값에 대한 확률을 결정하는 데 관심이 있습니다.i = 1,…, k-1.
이벤트 표기법을 사용하여ㅏ₁ 도박꾼이ㅏ게임 1에서 승리합니다.비₁은 도박꾼이비게임 1에서 승리합니다. 이벤트W도박꾼이ㅏ결국케이0 달러로 끝나기 전에 달러.이 이벤트가 발생할 확률은 조건부 확률의 속성을 사용하여 도출 할 수 있습니다.
조건부 확률을 사용한 승리 확률
그 도박꾼을 감안할 때ㅏ로 시작나는그들이 이길 확률은P (W) = aᵢ.도박꾼이라면ㅏ첫 번째 게임에서 1 달러를 획득하면 재산이i +1. 첫 게임에서 1 달러를 잃으면 재산은나는-1. 전체 시퀀스에서 이길 확률은 첫 번째 게임에서 이겼는지 여부에 따라 달라집니다.이 논리를 이전 방정식에 적용하면 게임마다 1 달러를 이길 확률과 도박꾼의 재산이 주어진 시퀀스에서 이길 조건부 확률에 의존하는 전체 게임 시퀀스에서 이길 확률의 표현을 알 수 있습니다.
문제 표기법을 사용한 승리 확률
도박꾼의 부ㅏ주어진 시점에서 도박꾼의 총 초기 자산과 0 사이에 차이가 있습니다.즉, 주어진i =1, … ,k-1, 우리는 모든 가능한 값을 연결할 수 있습니다나는구하기 위해 위의 방정식에k-인접한 값을 기반으로 승리 확률을 결정하는 1 방정식나는.기초 대수를 사용하여 이러한 방정식을 단일 공식으로 단순화 할 수있는 표준화 된 형식으로 집계 할 수 있습니다.이 공식은 각 게임에서 승리 할 확률 간의 근본적인 관계를 지정합니다.피, 두 도박꾼의 총 초기 자산케이, 그리고 1 달러의 재산이 주어질 때 이길 확률ㅏ₁.일단 우리가 결정하면ㅏ₁, 우리는 모든 것을 반복적으로 반복 할 수 있습니다.k-확률을 도출하려면 1aᵢ가능한 모든 값에 대해나는.
Fundamental relation
이제 우리는 두 가지 가능성을 고려할 것입니다 : 공정한 게임과 불공정 한 게임,피위의 방정식에 연결합니다.공정한 게임에서피= 1 / 2, 방정식의 오른쪽에있는 지수의 밑은 (1-피) /피= 1.그런 다음 전체 방정식을 다음과 같이 단순화 할 수 있습니다. 1-ㅏ₁ = (케이– 1)ㅏ₁, 재정렬 가능ㅏ₁ = 1 /케이.다른 값에 대한 승리 확률을 결정하는 모든 이전 방정식을 반복하면나는,공정한 게임을위한 일반적인 해결책에 도달했습니다.
공정한 게임을위한 솔루션
위의 방정식은 놀라운 결과입니다. 게임이 공정하다는 점을 감안할 때 도박꾼이ㅏ끝날 것이다케이0 달러로 끝나기 전의 달러는 초기 자산과 같습니다.나는두 도박꾼의 총 재산으로 나눈케이.
만약피두 명의 도박꾼 중 한 명이 체계적인 이점을 가지고 있기 때문에 게임이 불공평합니다.우리는 유사하게 가치에 의존하는 일반적인 해결책을 도출 할 수 있습니다.피그리고 부 매개 변수.
불공정 한 게임에 대한 해결책
노트: 독자가 일반적인 솔루션에 도달하기 위해 수학적 증명을 배우는 데 관심이 있다면 마지막에있는 참고 문헌을 참조하십시오.
랜덤 변수의 시퀀스엑스이산 시간 간격에 의해 정의 된 다른 시점을 나타내는 것은 확률 적 프로세스라고 할 수 있습니다.프로세스의 첫 번째 랜덤 변수는초기 상태,프로세스의 나머지 랜덤 변수는 시간에 각 프로세스의 상태를 정의합니다.엔.마르코프 체인은 미래 상태의 조건부 분포가 현재 상태에만 의존하는 특정 종류의 확률 적 프로세스입니다.즉, 조건부 분포엑스시간에n + j…에 대한j & gt;0시간의 프로세스 상태에만 의존엔, 이전 상태가 아닌엔– 1.다음 표기법을 사용하여이를 수학적으로 표현할 수 있습니다.
마르코프 사슬
마르코프 사슬은한정된특정 시점에 발생할 수있는 상태 수가 무한이 아닌 경우체인을 고려하십시오케이상태.시간에서의 상태 확률 분포n + 1특정 값을 취하는제이당시의 상태로엔로 알려져 있습니다전환 분포마르코프 사슬의.분포가 매번 동일한 경우 이러한 분포는 고정 된 것으로 간주됩니다.엔.표기법을 사용할 수 있습니다.pᵢⱼ이러한 분포를 나타냅니다.
고정 전이 분포
서로 다른 값의 총 수pᵢⱼ가능한 상태의 총 수에 따라 걸릴 수 있습니다.케이, 우리는케이으로케이매트릭스피마르코프 사슬의 전이 행렬로 알려져 있습니다.
전환 매트릭스
전이 행렬에는 고유하게 만드는 중요한 속성이 있습니다.행렬의 모든 요소는 확률을 나타내므로 모든 요소는 양수입니다.각 행은 이전 상태의 값이 주어 졌을 때 다음 상태의 전체 조건부 분포를 나타내므로 각 행의 값은 1이됩니다. 전이 행렬을 사용하여 확률 계산을 간단한 방법으로 여러 단계로 확장 할 수 있습니다.즉, 우리는 Markov 체인이 상태에서 이동할 확률을 계산할 수 있습니다.나는상태로제이여러 단계로미디엄전환 매트릭스를 취함으로써피의 힘에미디엄.즉,m 단계 전이 행렬피ᵐ는 체인의 모든 단계 범위 사이에서 특정 상태의 확률을 계산하는 데 사용할 수 있습니다.
대각선이있는 전이 행렬이있는 경우pᵢᵢ1과 같으면 상태나는간주됩니다흡수 상태.마르코프 사슬이 흡수 상태가되면 그 후에는 다른 상태로 들어갈 수 없습니다.또 다른 흥미로운 특성은 Markov 체인에 하나 이상의 흡수 상태가있는 경우 체인이 결국 이러한 상태 중 하나로 흡수된다는 것입니다.
시간 1에서 Markov 체인의 시작 부분에서 요소가 체인이 각 상태에있을 확률을 나타내는 벡터를 지정할 수 있습니다.이것은초기 확률 벡터V. We can determine the marginal distribution of the chain at any time 엔초기 확률 벡터를 곱하여V전환 매트릭스에 의해피의 힘에엔-1. 예를 들어, 우리는 다음 식으로 시간 2에서 체인의 한계 분포를 찾을 수 있습니다.vP.
A special case occurs when a probability vector multiplied by the transition matrix is equal to itself: vP=V.이것이 발생하면 확률 벡터를고정 분포마르코프 체인을 위해.
도박꾼의 폐허 마르코프 사슬
Markov 체인의 이론적 프레임 워크를 사용하여 이제 이러한 개념을 Gambler ‘s Ruin 문제에 적용 할 수 있습니다.우리가 이것을 할 수 있다는 사실은 확률과 통계 이론이 얼마나 얽혀 있는지 보여줍니다.처음에는 기본 확률 공리에서 파생 된 조건부 확률 정리만을 사용하여 문제를 구성했습니다.이제 문제를 더욱 공식화하고 Markov 체인을 사용하여 더 많은 구조를 제공 할 수 있습니다.추상적 개념을 취하고 다양한 도구를 사용하여 분석하고 확장하는 과정은 통계의 마법을 강조합니다.
갬블러의 파멸 문제는 본질적으로 갬블러가A 어떤 시점에서든 기본 구조를 결정합니다.즉, 언제든지엔, 도박꾼ㅏ가질 수있다i wealth, where i 또한 시간의 체인 상태를 나타냅니다.엔. When the gambler reaches either 0 wealth or k 부, 체인은 흡수 상태로 이동하고 더 이상 게임을하지 않습니다.
If the chain moves into any of the remaining k – 1 states 1, … , k – 1, a game is played again where the probability that gambler ㅏ이길거야피determines the marginal distribution of the state at that specific point in time. The transition matrix has two absorbing states. The first row corresponds to the scenario when gambler ㅏhas 0 wealth and the elements of the row are (1, 0, … , 0). Likewise, the last row of the transition matrix corresponds to the scenario when gambler ㅏhas reached 케이부와 요소는 (0,…, 1)입니다.다른 모든 행에 대해i, 요소는 좌표가있는 항에 대해 모두 0입니다.i – 1 and i + 1, which have values 1 – p and 피 respectively.
Gambler’s Ruin transition matrix
We can also determine the probabilities of states in multiple steps using the m-step transition matrixPᵐ. As 미디엄goes to infinity, the m-step matrix converges but the stationary distributions are not unique. The limit matrix of 피ᵐ에는 첫 번째 및 마지막 열을 제외하고 모두 0이 있습니다.마지막 열에는 모든 확률이 포함됩니다.aᵢ that gambler A 끝날 것이다케이그들이 시작한 것을 감안할 때 달러i dollars, while the first column contains all the respective complements of aᵢ.Since the stationary distributions are not unique, that means that all of the probabilities belong to the absorbing states.
Gambler’s Ruin limit matrix
This last point is especially important because it confirms our initial logical sequence of steps when deriving the solution formulas to the Gambler’s Ruin. In other words, we are able to derive a general formula for the problem as a whole because the stochastic processes (sequence of games) that occur in the problem converge to one of two absorbing states: gambler A 멀리 걸어케이dollars or gamblerㅏwalks away with 0 dollars. 무한히 많은 게임을 할 수 있지만 Markov 체인의 전이 행렬이 두 고정 분포로 수렴하기 때문에이 두 이벤트 중 하나가 발생할 확률을 결정할 수 있습니다.
결론
The Gambler’s Ruin Problem is a great example of how you can take a complex situation and derive a simple general structure from it using statistical tools. It might be difficult to believe that, given a fair game, the probability that someone will win enough games to claim the total wealth of both players is determined by their initial wealth and the total wealth. This is known not only at the beginning of the sequence, but also at each step. Using Markov chains, we can determine the same probabilities between any sequences of games using the transition matrix and the probability vector at the initial state. Consider this, the conclusion that we came to in the first section of this post was enhanced by use of an additional concept. Applying different perspectives to the same problem can open the door to insightful analysis. This is the power of theoretical statistical thinking.