
아무 것도 없
DataAnalytics(ko)
How to efficiently re-partition Spark DataFrames -번역
Spark DataFrames를 효율적으로 다시 파티션하는 방법
스파크 데이터 프레임의 수를 늘리거나 줄이는 방법
Apache Spark는 합리적인 시간에 엄청난 양의 데이터를 사용할 수있는 프레임 워크입니다.이 통합 엔진의 효율성은 데이터 컬렉션을 통해 수행 된 작업을 배포하고 평행하는 기능에 대단히 의존합니다.
이 기사에서는 스파크로 파티션을 도입하고 데이터 프레임을 다시 파티션하는 방법을 설명합니다.또한 실행 시간을 최대한 많이 최적화하기 위해 스파크 데이터 프레임의 파티션 수를 증가 시키거나 감소시킬 가치가있는 경우에도 논의 할 것입니다.
간단한 분할 분할
순서대로 순서대로 높은 병렬 처리를 달성하기 위해 스파크는 스파크 클러스터의 다른 노드에 분산 된 파티션이라는 파티션이라는 작은 청크로 데이터를 분리합니다.모든 노드는 두 가지 이상의 실행 프로그램이 작업을 실행할 수 있습니다.
여러 실행 업체에 대한 작업 분포는 특정 작업에 대한 데이터 처리를 최적화하기 위해 데이터 처리를 병렬로 수행 할 수 있도록 데이터를 병렬로 수행 할 수 있도록 데이터를 병렬로 수행 할 수 있습니다.
현재 파티션 수를 얻는 방법
다시 파티셔닝으로 점프하기 전에 스파크 데이터 프레임의 현재 파티션 수를 얻는 데 사용할 수있는 방법을 설명 할 가치가 있습니다.예를 들어, 우리가 다음과 같은 최소한의 점화 데이터를 가지고 있다고 가정 해 봅시다.
위의 데이터 프레임의 파티션 수를 얻으려면 다음을 수행해야합니다.
출력은 현재 설정 및 구성에 의존하여 다른 출력을 볼 수 있습니다.
파티션 수를 늘리는 방법
데이터 프레임의 파티션을 늘리려면 다음을 수행해야합니다.재진입 ()함수.
새로운 것을 반환합니다
데이터 프레임지정된 분할 식별로 분할됩니다.결과 데이터 프레임은 해시 분할됩니다.
아래 코드는 파티션 수를 1000으로 증가시킵니다.
파티션 수를 줄이는 방법
이제 파티션이 줄어들 수 있도록 Spark DataFrame을 다시 확인하려면 여전히 사용할 수 있습니다.재진입 ()하나,그렇게 할 수있는보다 효율적인 방법이 있습니다.
합병 ()좁은 의존성이 좁아 지므로 파티션 수를 줄이는 데 사용될 때는셔플 없음,아마도 아마도 스파크에서 가장 비용이 많이 드는 작업 중 하나 일 것입니다.
새로운 것을 반환합니다
데이터 프레임그건 정확히 n 개의 파티션이 있습니다.
아래 예에서 우리는 파티션을 100으로 제한합니다. 원래 1000 개의 파티션이있는 Spark DataFrame은 셔플없이 100 개의 파티션으로 해결됩니다.우리는 그것을 의미하지 않습니다각 100 개의 새로운 파티션이 10 개의 기존 파티션에 할당됩니다.…에그러므로 그것은 더 효율적으로 전화하는 것이 더 효율적입니다합병 ()하나가 Spark DataFrame의 파티션 수를 줄이려면.
결론
이 기사에서는 스파크 클러스터의 실행 업체에 작업을 수행 할 수있는 파티션을 통해 데이터 처리가 어떻게 최적화되는지 논의했습니다.또한 데이터 프레임의 파티션 수를 늘리거나 줄이기 위해 사용할 수있는 두 가지 가능한 방법을 탐색했습니다.
재진입 ()Spark DataFrame의 파티션 수를 증가 또는 감소시키는 데 사용할 수 있습니다.하나,재진입 ()비용이 많이 드는 작업 인 셔플 링이 포함됩니다.
다른 한편으로,합병 ()이 메소드가 스파크 클러스터의 노드를 가로 질러 데이터를 섞지 않을 것이라는 사실 때문에이 방법으로 인해 파티션 수를 줄이려면 사용할 수 있습니다.
My Favorite Mac Utilities -번역
내가 좋아하는 MAC 유틸리티
내 맥을 훨씬 더 잘 만드는 다섯 가지 간단한 유틸리티.
저는 노트북, 헤드폰 또는 펜 및 노트북과 같은 하드웨어에 대해 쓸 수 있습니다.내가 충분히 말하지 않는 것은 해당 하드웨어에 사용하는 응용 프로그램이나 도구입니다.
나는 이제 iPads를 풀 타임으로 사용하는 시간 외에도 거의 10 년 동안 Mac을 사용 해왔다.그 당시, 나는 몇 가지 도구, 유틸리티 및 정기적으로 사용하기를 원하는 앱을 집어 들었습니다.
이 게시물을 위해서, 나는 그것을 원합니다이자형내가 사용하는 유틸리티를 넘겨주는 것.새로운 MacBook에서 즉시 다시 설치된 것들.이들 중 일부는 응용 프로그램으로 간주 될 수 있지만, 나를 필요로하지 않고 백그라운드에서 실행되는 것을 설정하는 곳으로 나를 데리고 나가는 도구로 볼 수 있습니다.
응용 프로그램 및 다른 프로세스 및 도구를 사용하여 더 많은 게시물을 계속 지켜 보지만, 지금은 간단하게 시작하고 싶었습니다.그래서 내가 가장 좋아하는 유틸리티가 내 맥에서 끊임없이 사용하는 것입니다.
바텐더 4.($ 15)
이 유틸리티는 연령대를 위해 주변에있었습니다.나는 심지어 Mac을 사용하여 선택의 컴퓨터를 사용하기 전에였습니다.이 유틸리티는 정확하게 그 이름이 말하는 것입니다.그것은 메뉴 “바”의 “입찰”입니다.
내 MAC의 앱 또는 기타 유틸리티를위한 모든 메뉴 표시 줄 아이콘.한 번 이처럼 보였던 것은 무엇입니까?
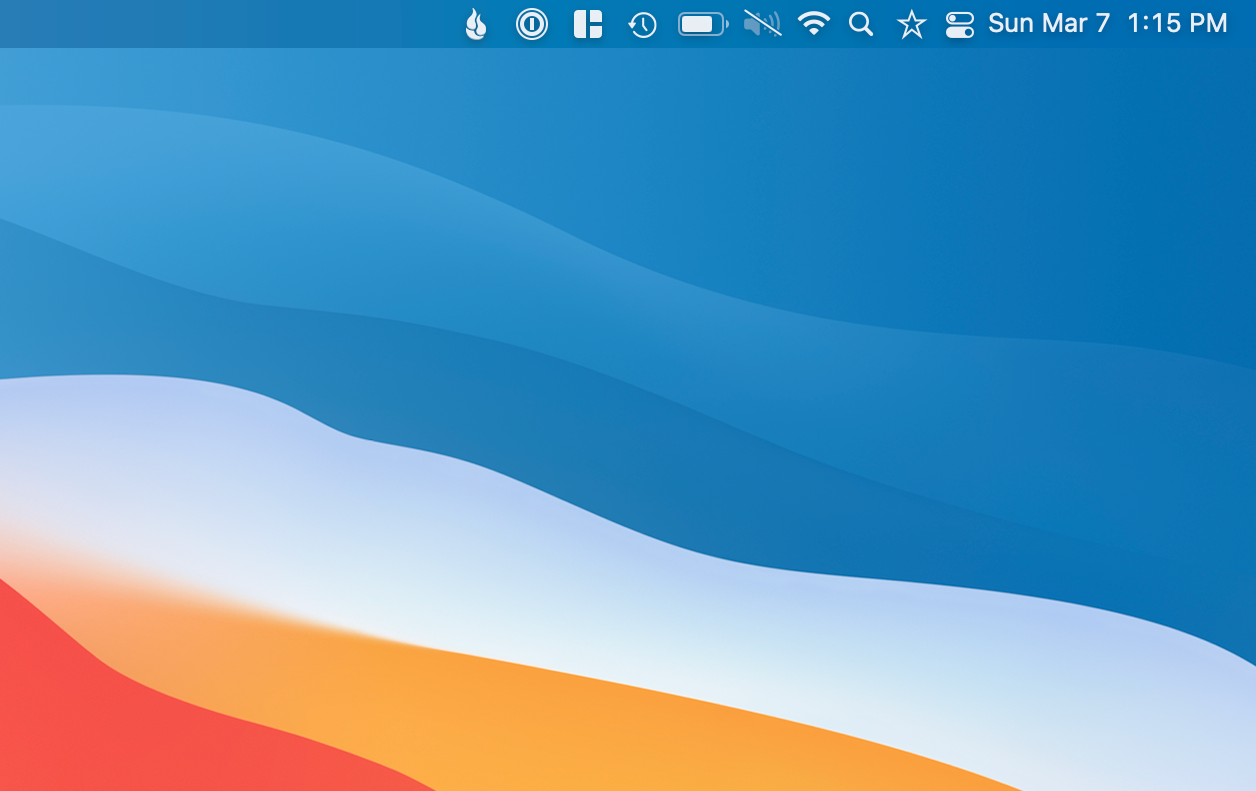
이제는 다음과 같습니다.

내가 전에 말했듯이, 이것은 잠시 동안 주변에있었습니다.간단한 기능은 모든 메뉴 항목을 숨기기 위해 모든 메뉴 항목을 숨기면 청결한 메뉴 모음을 제공합니다.선글라스, 3 개의 점 또는 별의 한 쌍과 같이 주요 아이콘을 원하는 것에 대해 몇 가지 옵션이 있습니다.
바텐더는 거기에서 멈추지 않습니다.또한 각 메뉴 아이콘을 원하는 방식에서 선택할 수있는 다양한 옵션이 제공됩니다.Bartender의 특정 메뉴 아이콘을 숨길 수 있으며, 전혀 볼 수 없거나 항상 볼 수 있습니다.
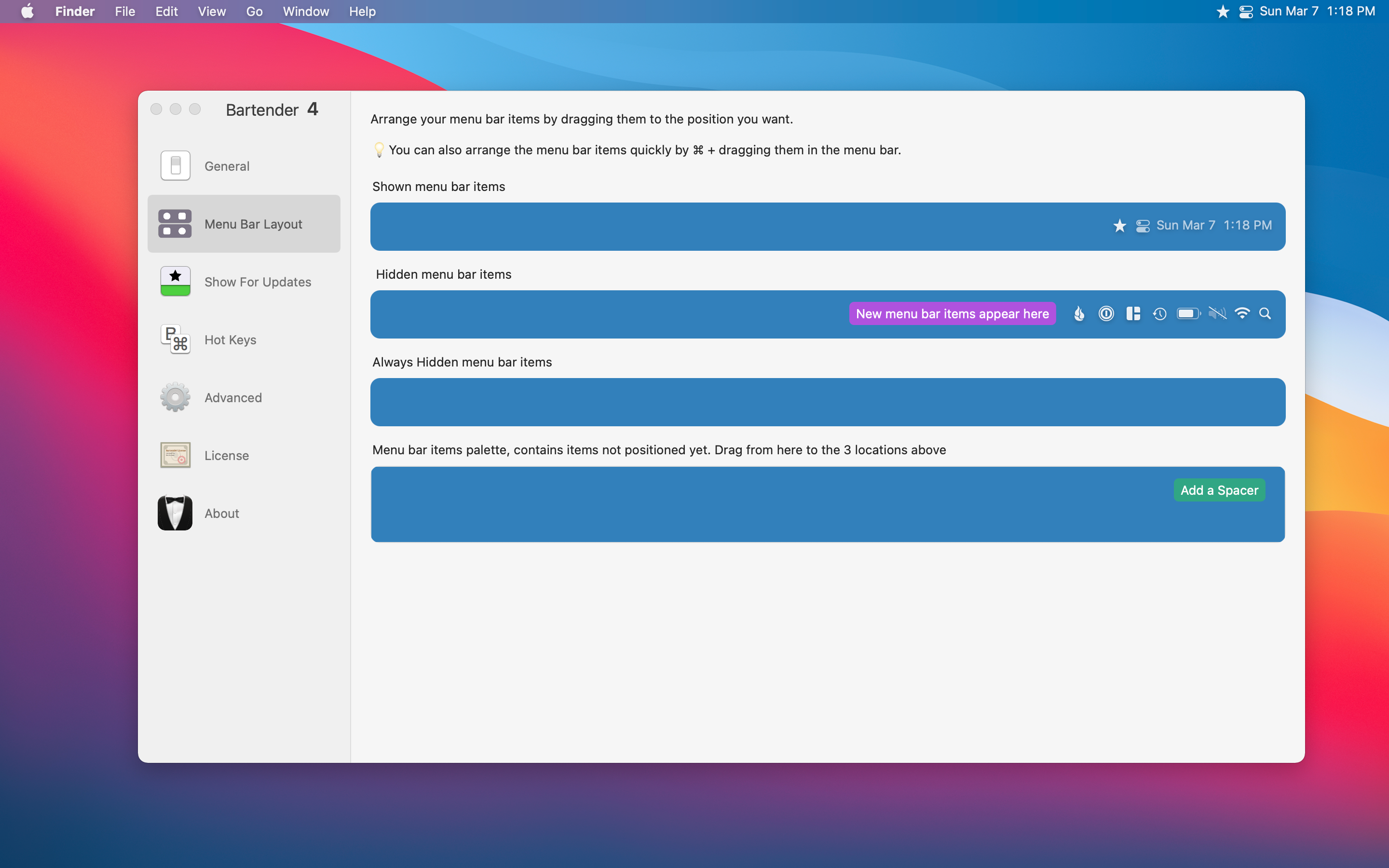
Bartender 4는 MacOS Big Sur에서 사용할 수 있으며 현재 공개 베타 속에 있으므로 베타에서는 여전히 무료입니다.베타가 더 이상 활성화되지 않은 경우 15 달러의 비용이 듭니다.이전 매크로 버전을 사용하는 모든 사용자를 위해바텐더 3.여전히 구매할 수 있습니다.
메뉴 바를 분명히 유지하는 간단한 솔루션을 제공하는 간단한 도구입니다.나는 많은 사람들이 톤의 메뉴 아이콘을 가지고 있고 바텐더를 관리하고 유지하는 데 더 유용한 바텐더를 찾는다는 것을 알고 있습니다.
자석($ 7.99)
Mac의 창 관리는 당신이 사랑하거나 싫어하는 것입니다.창 관리가 매우 구조화되고 제한되므로 많은 사랑 iPados가 있습니다.Mac에서는 일부를 위해 ChaOS를 만들 수있는 Windows를 겹칠 수 있습니다.
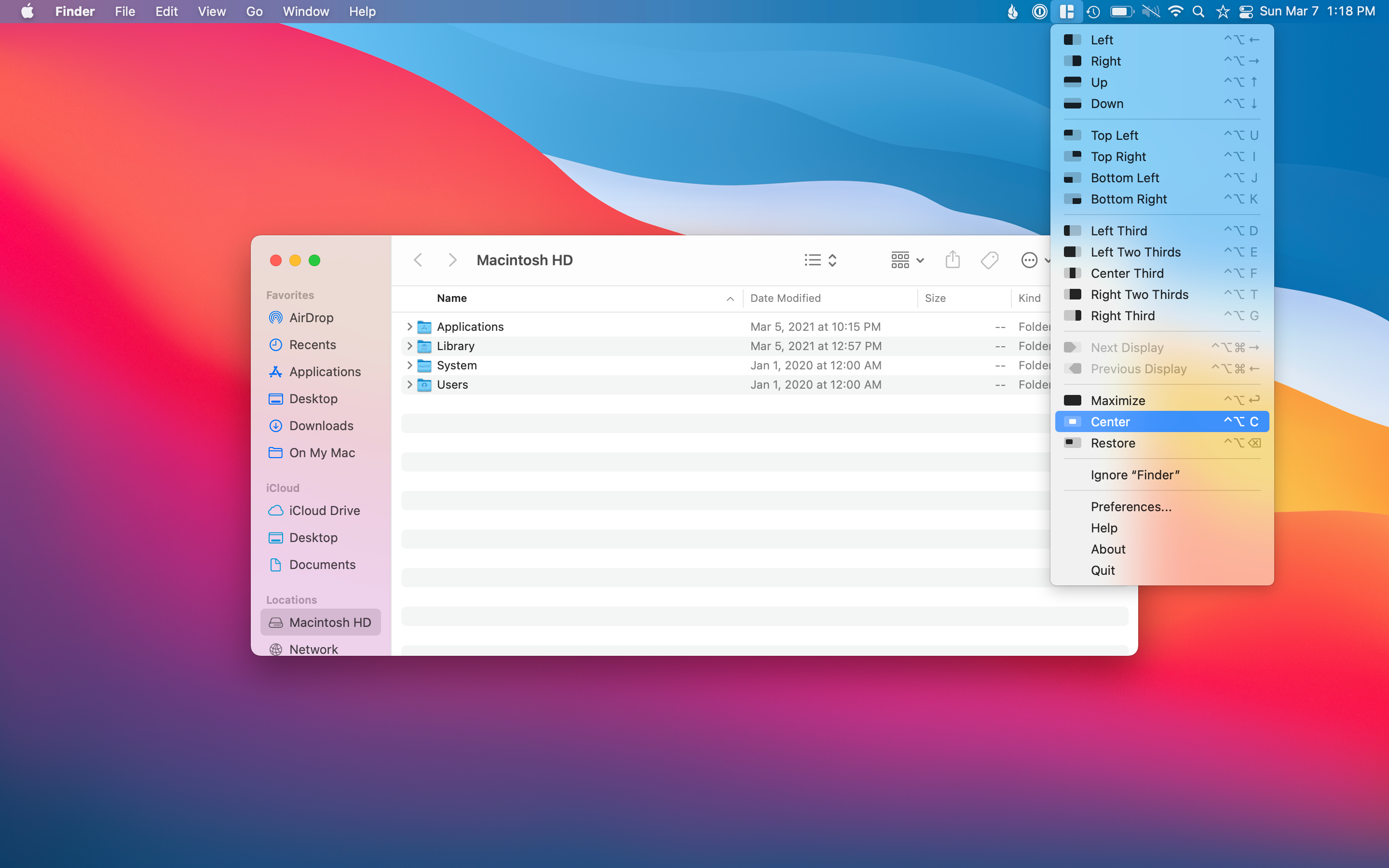
자석은 간단한 클릭으로 Windows를 이동하고 크기를 조정할 수있는 옵션을 제공하여 Mac에서 Window Management를 돕고 있습니다.Magnet을 사용하고 싶은 방법의 몇 가지 예제는 바탕 화면에서 무언가를 중심적으로 가운데 전체 화면 모드로 들어 가지 않고 풀 크기로 설정하고 싶습니다.
나는 전체 화면으로가는 대신 ulysses를 최대화하고 싶습니다. 그래서 나는 항상 나에게 항상 볼 수있는 메뉴 바가 있습니다.앱을 열고 Magnet에서 최대화 옵션을 클릭하는 것입니다.별도의 데스크톱에서 나는 트위터를 화면의 3 분의 1을 차지하고 이메일을 보내고 화면의 다른 2/3을 차지합니다.
자석은 창을 수동으로 끌 필요없이 많은 창을 가지고 있지 않아도 정리 또는 크기 조정을 원하면 자석이 우수합니다.
스포트라이트(수은)
일단 스포트라이트를 불러 오는 명령 + 스페이스 바 키보드 바로 가기를 암기했을 때, 나는이 방법으로 앱 만 출시하고 내 도킹을 자동 숨기기 위해 설정했습니다.나는 스포트라이트가 잠시 동안 주변에 있었다는 것을 알고 있지만, 나는 그것을 더 많이 사용하기 시작했던 단지 몇 년이 아니 었습니다.
Spotlight에 대한 훌륭한 것은 앱을 검색하고 출시하는 것 이상을 수행 할 수 있다는 것입니다.문서, 이메일, 음악을 검색 할 수 있으며 웹에서 텍스트 상자에서 똑바로 항목을 검색 할 수 있습니다.
수년 동안 Spotlight는 제공되는 기능이 제한되어 있으며, 지역 사물을 검색 할 수 있습니다.그러나 시간이 지남에 따라 퀵실버가 수년 동안 퀵실버가 수행 한 많은 것들을 제공합니다.QuickSilver는 자동화 및 기타 기능을 제공하지만 Mac의 모든 것에 대한 간단한 검색 도구를 위해 스포트라이트는 잘 작동합니다.
1password.(매월 6.99 달러, 매년 $ 59.99)
암호는 특히 온라인 서비스 중 하나에 대해 안전한 암호를 갖고 싶을 때 추적하는 통증입니다.애플의 iCloud 키 체인은 훌륭하지만, 제 아내와 공유 할 수있는 것을 원했습니다.
너무 어두워지지 않고이 유용성과 다음은 내 장치가 깨지는 경우뿐만 아니라 어떻게 든 사라질 경우에뿐만 아니라 마음의 평화를주는 것들입니다.죽음은 결코 생각하고 싶은 것이 아닙니다. 그러나 저를 위해, 나는 조금 더 쉽게 가치가있는 어려운 상황을 다루기 위해 아내가 어려운 상황을 처리 할 수 있도록 설립 된 특정 일이 있음을 알고 있습니다.
1Password는 내가 생각할 수있는 모든 기록을 추적 할 수있는 개인용 금고를 제공합니다.심지어 iPhone 및 iPad에서 1Password를 사용할 때 설정 한 로그인에 대해 2 인증을 설정하고 해당 로그인을 복사 할 수 있습니다.
가장 좋은 부분은 공유 금고입니다.제 아내와 저는이 공유 금고에서 우리 모두가 더 중요한 로그인이 너무 유용합니다. 우리 중 한 사람에게 일어나는 경우뿐만 아니라 우리 중 하나가있는 경우에만 로그인 할 필요가있을뿐만 아니라 뭔가에 로그인해야합니다.그녀가 자신을 로그인 할 수 없을 때 자신의 간단한 클릭으로 액세스 할 수 있습니다.
뒤판책(한 달에 6 달러)
이 유틸리티는 순전히 마음의 평화입니다.나는 몇 년 전에 그 존재에 대해 배웠던 즉시 항상 내 아내의 맥북에 항상 갔다.그것은 단지 작동하는 저렴한 오프 사이트 백업 서비스입니다.
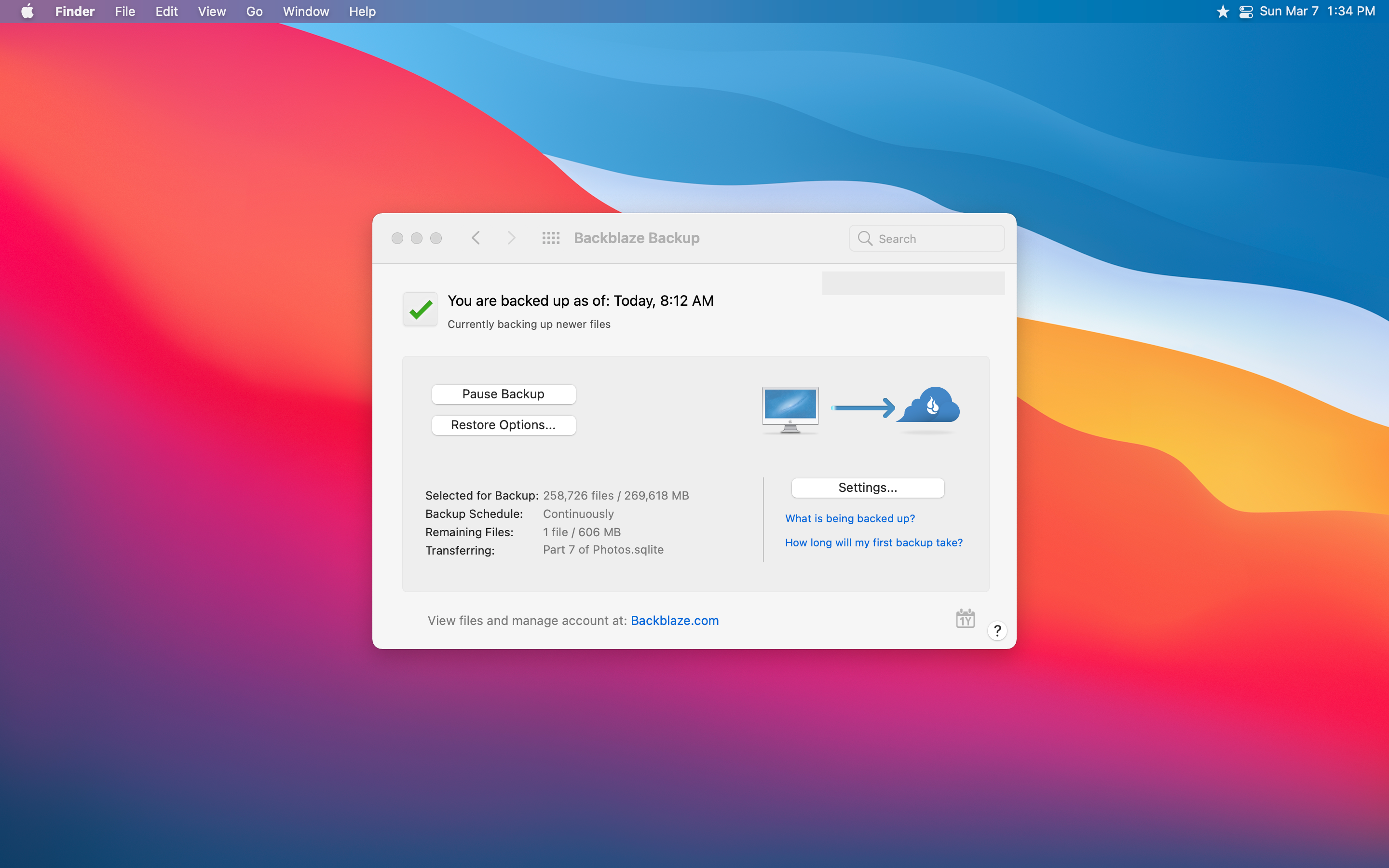
수년 동안 단일 컴퓨터 및 한 달에 5 달러에 연결된 외부 드라이브에 무제한 백업을 제공했습니다.최근에 그 가격이 6 달러로 확대되었지만 여전히 살인자 거래라고 생각합니다.MacBook Air가 백업 된 300GB 이상의 데이터뿐만 아니라 외부 하드 드라이브에도 2TB의 데이터도 백업했습니다.나에게서 6 달러에 불과합니다.
사실, 제가하는 일에 대해 6 달러를 지불 할 수 있지만 최근에 추가로 2 달러의 추가로 Backblaze Affber를 제공하는 또 다른 새로운 기능을 선택했습니다.이 추가 기능은 1 년 동안 삭제 된 데이터를 보호하는 1 년 버전의 기록입니다.
그래서 실수로 오늘날 파일을 삭제하고 6 개월 만에 파일이 필요했습니다. Backblaze는 여전히 백업에서 회복하기 위해 여전히 사용할 수 있습니다.또한 영원히 버전 기록을 제공합니다. 즉, 여전히 고객이있는 한 삭제 된 파일을 복구 할 수 있습니다.
영원히 버전의 역사는 2 달에 2 달러이며, 한 달에 GB 당 $ .005를 청구합니다.제가 아내와 나에게 영원히 옵션을 선택해야한다면, 총계는 표준 기반 비용에 대해 약 12 달러, $ 4 + $ 13.05 (2.7 TB가 $ 0.005를 곱한 총 비용이 약 30 달러)입니다.
2.7 테라 바이트의 데이터와 버전 기록의 2.7 terabytes for Sourcore는 영원히 그렇게 나쁘지는 않지만, 우리를 위해 조금 overboard입니다.우리가 랩톱과 1 년 버전의 역사를 위해 지금 지불하는 한 달에 16 달러는 충분합니다.
그러나 많은 양의 데이터가 있거나 장기간의 데이터 복구의 이점을 누릴 수있는 많은 가족 구성원이있는 경우 알아야 할 훌륭한 옵션입니다.수년 동안 일한 책의 원고와 마찬가지로 매우 민감한 데이터를 가진 일부와 마찬가지로 무엇이든 잃지 않도록하고 싶습니다.
나는 많은 다른 유틸리티를 가지고 있으며, 주로 매크로와 함께있는 것들이 있지만, 이것들은 내가 실제로 살 수없는 것들입니다.내 마음은 이러한 유틸리티가 제공하는 내 기본 요구 사항이므로 이러한 특정 버전에서는 죽지 않았습니다.
My Menu Bar를 구성하고 Windows 관리를 유지하면서 간단한 키보드 명령, 암호 관리자 및 신뢰할 수있는 오프 사이트 백업 소프트웨어가있는 내 Mac에서 검색 할 수있는 기능은 Mac이 최상의 Mac을 가장 잘 만드는 것들입니다.
비슷한 일을 할 수있는 다른 유틸리티가 있지만, 이들은 지속적으로 우리를 위해 일을 위해 일한 것들입니다.Mac에 유틸리티를 갖는 궁극적 인 목표는 컴퓨터가 당신을 위해 일하고 다른 방향으로 작동하지 않도록 더 잘 만들어야합니다.
따라서 Mac을보다 유용하게 만들려면 위 또는 귀하의 필요에 맞는 다른 도구 중 일부를 확인해 보겠습니다.가장 중요한 부분은 당신의 방식으로 들어 가지 않지만 당신을 위해 일하는 것입니다.
Multivariate Outlier Detection in Python -번역
파이썬에서 다 변수 이상 탐지
다 변수 아웃리어와 파이썬에서 Mahalanobis 거리
다 변수 데이터의 특이점을 감지하면 종종 데이터 전처리의 문제 중 하나 일 수 있습니다. 단계.특이점을 감지하는 다양한 거리 메트릭, 점수 및 기술이 있습니다.유클리드 거리는 중심점까지의 거리를 기반으로 한 이상을 식별하는 가장 알려진 거리 메트릭 중 하나입니다.또한 단일 숫자 변수에 대한 이상을 정의하는 z 점수가 있습니다.경우에 따라 클러스터링 알고리즘도 선호 될 수 있습니다.이러한 모든 방법은 다른 관점에서 이상 치를 고려합니다.하나의 방법을 기반으로 한 이상이 다른 방법으로 발견되지 않을 수 있습니다.따라서 이러한 방법 및 메트릭은 변수의 배포를 고려하여 선택해야합니다.그러나 이것은 다른 메트릭의 요구도 가져옵니다.이 기사에서는 MahalAnobis 거리라는 거리 메트릭을 다 변수 할 수있는 데이터의 특이점을 감지하기 위해 논의 할 것입니다.
Mahalanobis 거리
Mahalanobis 거리 (MD)는 점과 분포 사이의 거리를 찾는 유효 거리 측정 기준입니다 (또한보십시오짐마자데이터 포인트와 중심 간의 거리를 찾기 위해 변수의 공분산 행렬을 사용하기 때문에 다 변수 데이터에 매우 효과적으로 작동합니다 (공식 1 참조).즉, EUCLIDEAN 거리와 달리 데이터 포인트의 배포 패턴을 기반으로 한 이상을 감지 함을 의미합니다.그 차이를 이해하려면 그림 1을 참조하십시오.

그림 1에서 볼 수 있듯이 데이터 포인트는 특정 방향으로 흩어져 있습니다.유클리드의 거리는 그러한 분포의 이상 치명적인 지점을 할당 할 수 있지만 Mahalanobis 거리가 계속 유지 될 수 있습니다.이것은 그림 2에서 본 비선형 관계에도 동일합니다.
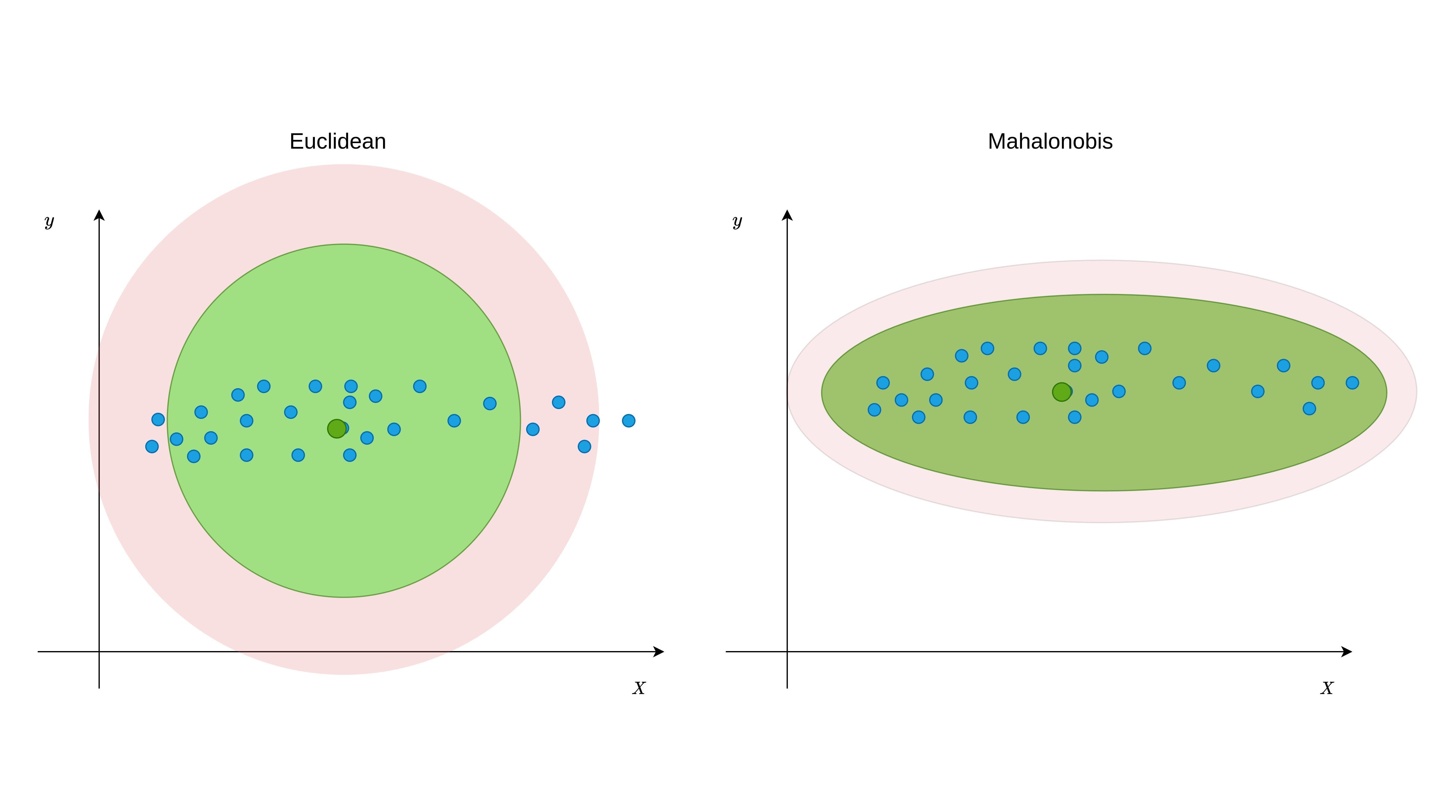
이 차이의 주된 이유는 공분산식이 변수가 어떻게 변화 하는지를 나타내기 때문에 공분산 행렬입니다.N 차원 공간의 중앙과 포인트 사이의 거리를 계산하는 동안 공분산을 사용하면 변화에 따라 진정한 임계 값 테두리를 찾는 기능이 있습니다.화학식 1에 도시 된 MD의 거리 공식으로부터 알 수있는 바와 같이, 공분산 매트릭스는 C로서 C이고 그것의 부정적인 제 1 능력이 취해졌다.벡터 XPI는 n 차원 공간에서 관측 좌표를 나타냅니다.예를 들어 세 가지 변수, 첫 번째 행이있는 데이터 세트가있는 경우 다음과 같이 두 번째 행을 나타낼 수 있습니다.XP1 : [13,15,23] 및 XP2 : [12,14,15]…에그러나 이상 치를 식별하는 동안, 각 포인트 사이의 거리를 찾는 대신 중심과 각 관찰 사이의 거리가 발견되어야합니다.중심점은 각 변수의 평균값을 취하여 얻을 수 있습니다.
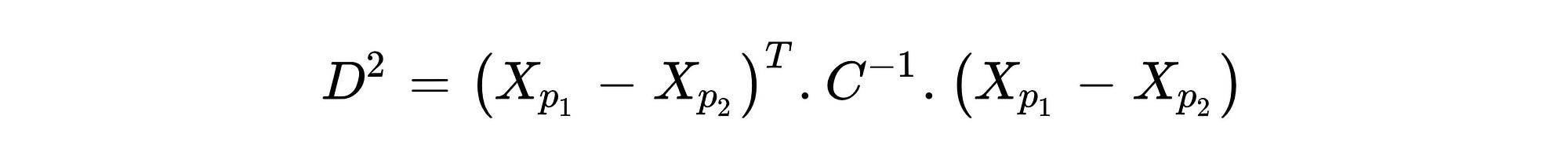
참고 : 그림 1과 2에 주어진 예제 데이터와 달리 변수가 원면에 대부분 흩어지면 유클리드 거리가 더 적합 할 수 있습니다.
파이썬과 Mahalanobis 거리
예, 파이썬을 사용하여 Mahalanobis 거리를 찾을 시간입니다.파이썬 대신 r에 관심이 있으시면 다른 기사를 살펴볼 수 있습니다.
‘scipy’라이브러리에서 Mahalanobis 거리가 있습니다.이 메서드에 액세스 할 수 있습니다scipy.spatial.distance.mahalanobis.또한 세부 사항을 볼 수 있습니다여기…에이 방법을 사용하는 대신, 다음 단계에서는 수식 1에서 주어진 공식을 사용하여 Mahalanobis 거리를 계산하는 자체 방법을 작성하게 될 것입니다.
“AirQuality”라는 데이터 세트를 사용하고 변수 “오존”및 “TEMP”를 사용하여 오위 이상을 감지합니다.이 데이터 세트를 다운로드 할 수 있습니다여기또는 데이터 세트를 사용하십시오.
첫째, 필요한 라이브러리와 데이터 세트를 가져와야합니다.데이터 세트를 계산을 준비하려면 “오존”및 “온도”변수 만 선택되어야합니다.게다가, 아무런 오류가 있지 않아야합니다.또한 Pandas 데이터 프레임을 사용하는 대신 numpy 배열을 사용하는 것을 선호합니다.그래서 내가이를 숫자 배열로 변환했습니다.
두 번째 단계에서는 센터와 포인트 사이의 거리를 계산하기 위해 필요한 값을 얻어야합니다.따라서 “오존”과 “온도”변수 사이의 중심점과 공분산 매트릭스입니다.
세 번째 단계의 경우 데이터 세트의 중심점과 각 관측 (포인트) 사이의 거리를 찾을 준비가되었습니다.우리는 또한 Chi-square 배포에서 컷오프 값을 찾아야합니다.Chi-square가 컷오프 값을 찾는 데 사용되는 이유는 Mahalanobis 거리가 제곱 된 (d²)로 거리를 반환합니다.또한 0.95 (2 꼬리) 외부의 포인트가 이상으로 간주되므로 컷오프를 찾는 동안 컷오프를 찾아야합니다.짧은 양은 컷오프 값이 적습니다.우리는 또한 Chi-square에 대한 자유 값이 필요하며 데이터 세트의 변수 수와 동일합니다.
마지막으로, 우리는 [24, 35, 67, 81]의 인덱스에 4 가지 이상의 특이점이 있습니다.이제이 과정을 더 분명하게 이해하고 계획을 세우십시오.
그리고 여기서 우리는 그림 3에서 볼 수 있듯이, 포인트는 아웃리어로 탐지 된 타원 밖에서 머물러 있습니다.이 ellipse는 MD에 따라 아웃 리어 값을 래핑하는 영역을 나타냅니다.

다음은 무엇입니까?
이 기사에서는 Mahalanobis 거리와 유클리드 거리와의 차이가 논의되었습니다.우리는 또한 파이썬에서 Mahalanobis 거리 공식을 처음부터 적용했습니다.이전에 언급했듯이 데이터가 N 차원 공간에 흩어져있는 방법을 기반으로 거리 측정 항목을 선택하는 것이 중요합니다.다른 거리 메트릭을 살펴볼 수도 있습니다.요리 거리…에
질문이 있으시면 언제든지 코멘트를 남겨주세요.
사용을 따라 이상을 감지하는 방법에 관심이있는 경우 다른 기사를 확인할 수 있습니다.R.의 Mahalanobis 거리…에
Interoperable Python and SQL in Jupyter Notebooks -번역
Jupyter 노트북의 상호 운용 가능한 파이썬 및 SQL.
팬더, 스파크 및 마스크 맨 위에 SQL 사용
참고 : 대부분의 코드 스 니펫은 SQL 구문 강조 표시를 보존하는 유일한 방법 이었기 때문에 이미지입니다.대화식 코드 예제에서는 이것을 확인하십시오Kaggle 노트북…에
Motivation
FUGUSEQL의 목표는 데이터 전문가가 SQL과 같은 언어로 워크 플로를 계산하는 워크 플로를 수행하는 데 대한 향상된 SQL 인터페이스 (및 경험)를 제공하는 것입니다.FUGUSEQL을 사용하면 SQL 사용자는 Python 코드 및 Jupyter 노트북의 데이터 프레임에서 전체 추출, 변환,로드 (ETL) 워크 플로를 수행 할 수 있습니다.SQL은 해당 팬더, 스파크 또는 DASK 코드에 파싱되고 매핑됩니다.
이 Empowe.아르 자형S 무거운 SQL 사용자는 스파크와 마스크의 힘을 활용하여 원하는 언어를 사용하여 논리를 표현합니다.또한 분산 된 컴퓨팅 키워드가 다음과 같이 추가되었습니다.선다과지속하다표준 SQL을 초과하여 기능을 확장하기 위해
이 기사에서는 기본 fuguesql 기능을 지나서 실행 엔진을 지정하여 스파크 또는 Dask 위에 사용하는 방법을지나갑니다.
ANSI SQL을 통한 향상된 기능
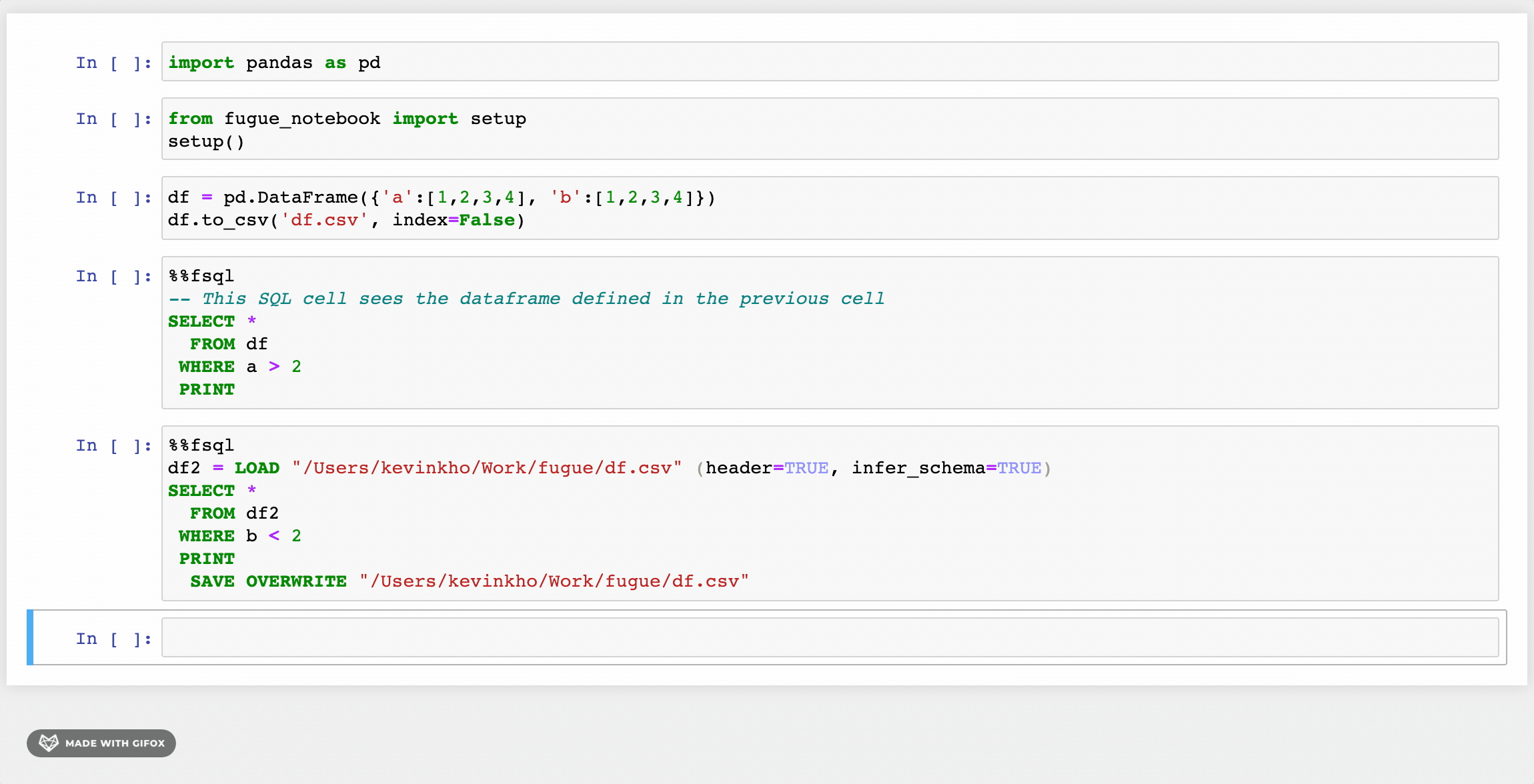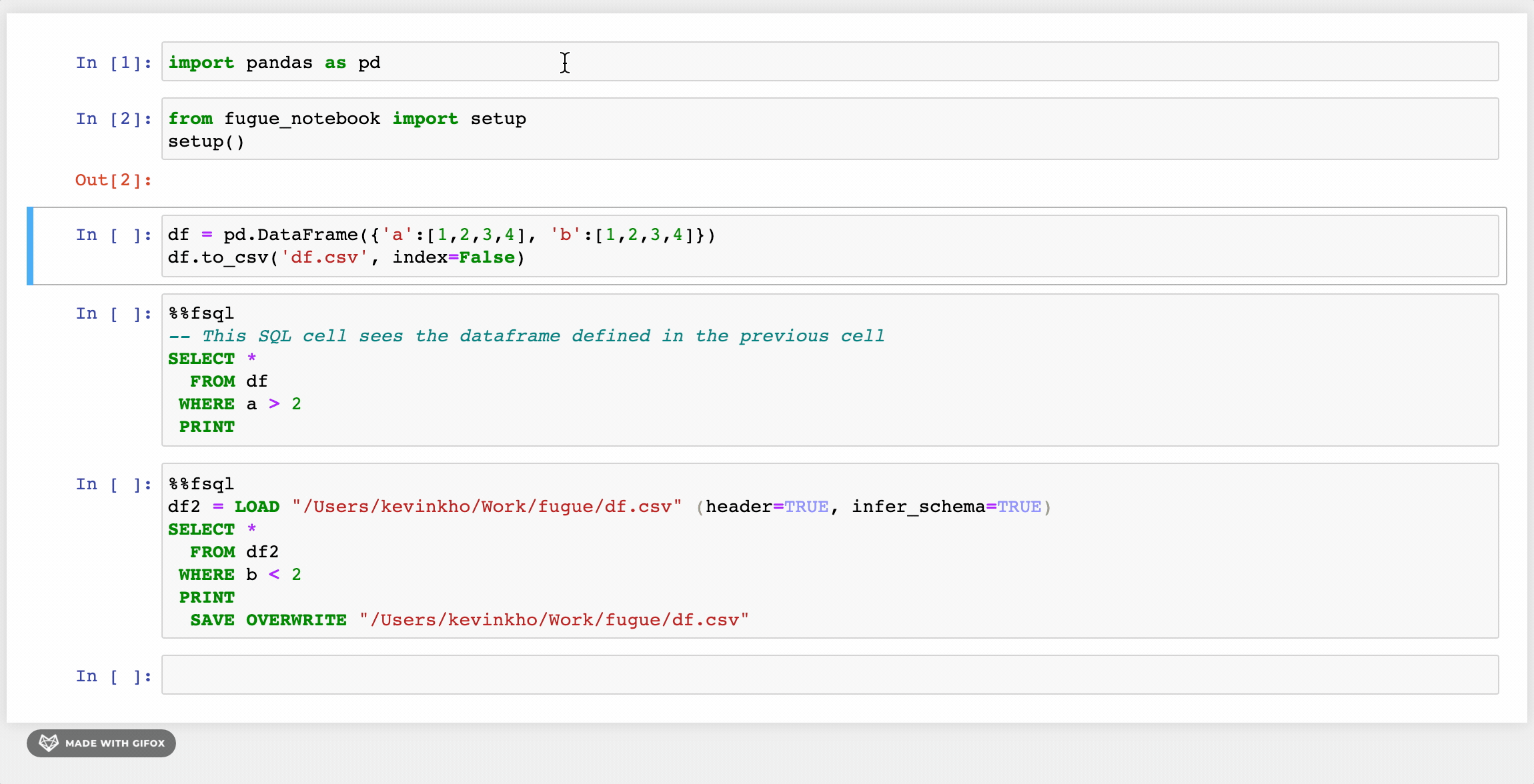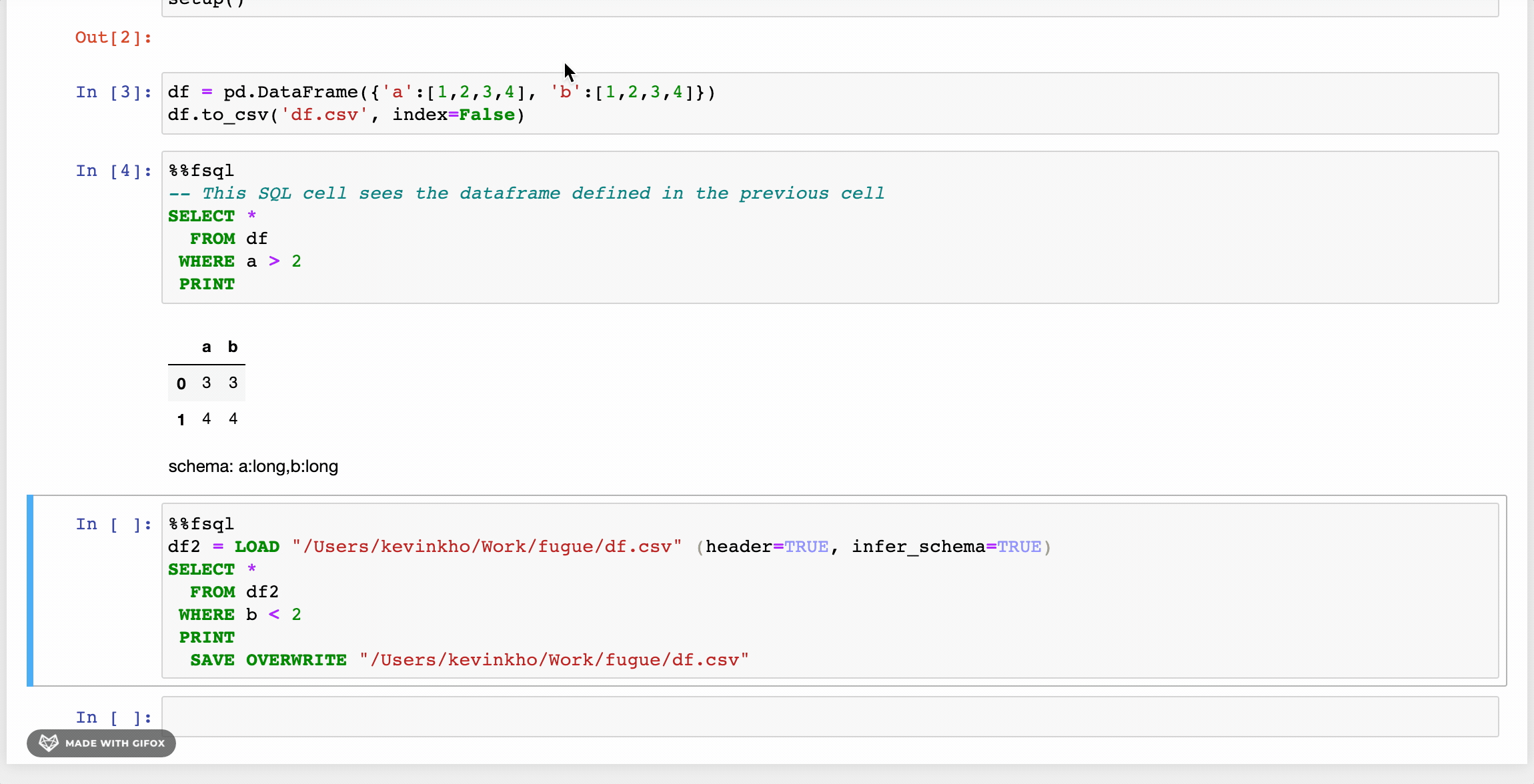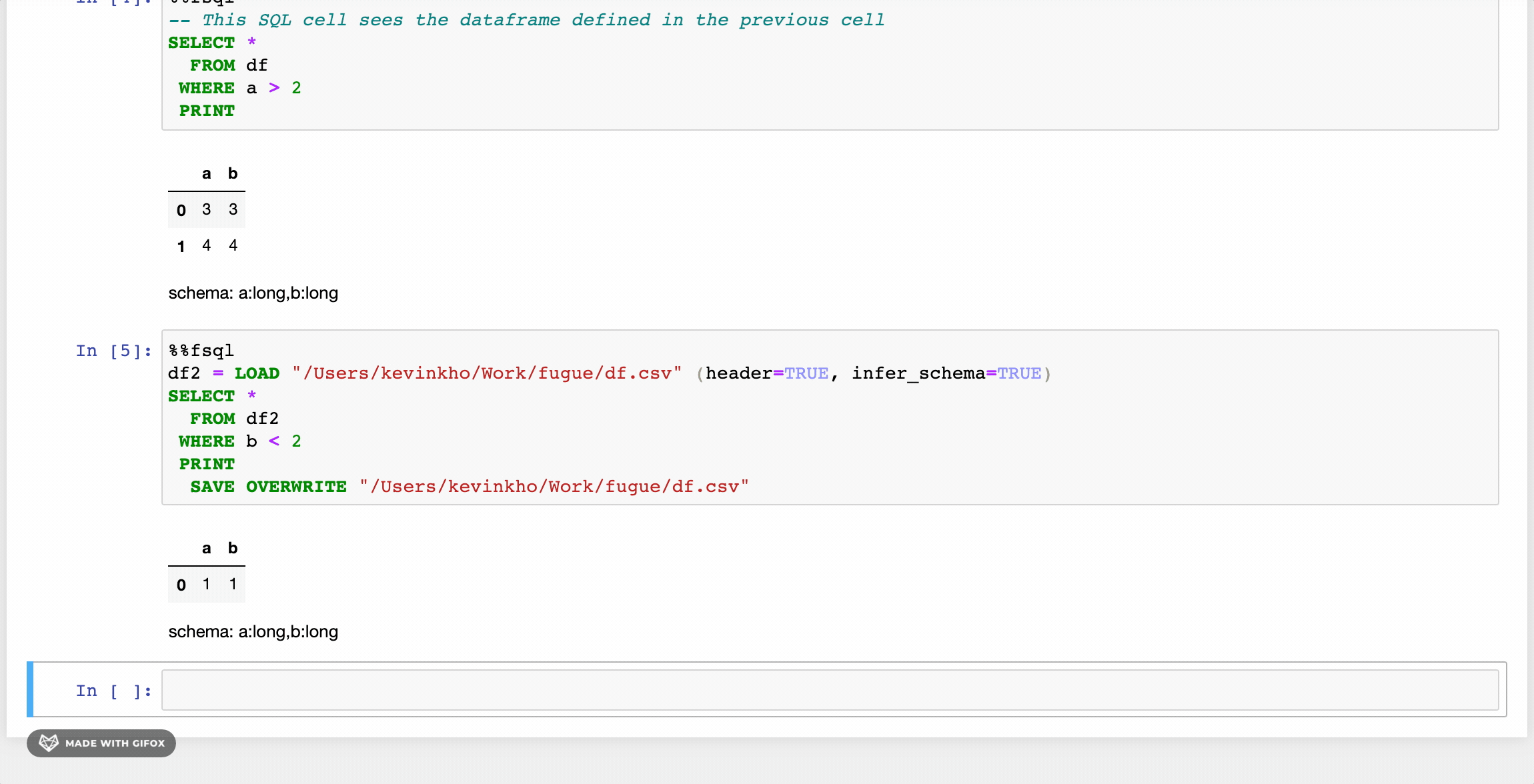
위의 GIF에서 본 첫 번째 변경 사항은하중과저장키워드.이를 넘어서, 더 친근한 구문을 제공하는 다른 개선 사항이 있습니다.또한 사용자는 Fuguesql에서 Python 함수를 사용하여 강력한 조합을 만듭니다.
FuguesQL 사용자는 노트북에 SQL 셀을 가질 수 있습니다 (나중에 더 많은 예제)%% FSQL.셀 마법.또한 Jupyter 노트북에서 구문 강조 표시를 제공합니다.여기서 시연되지는 않았지만 이러한 SQL 셀은 파이썬 코드에서 사용할 수 있습니다.fsql ()함수.
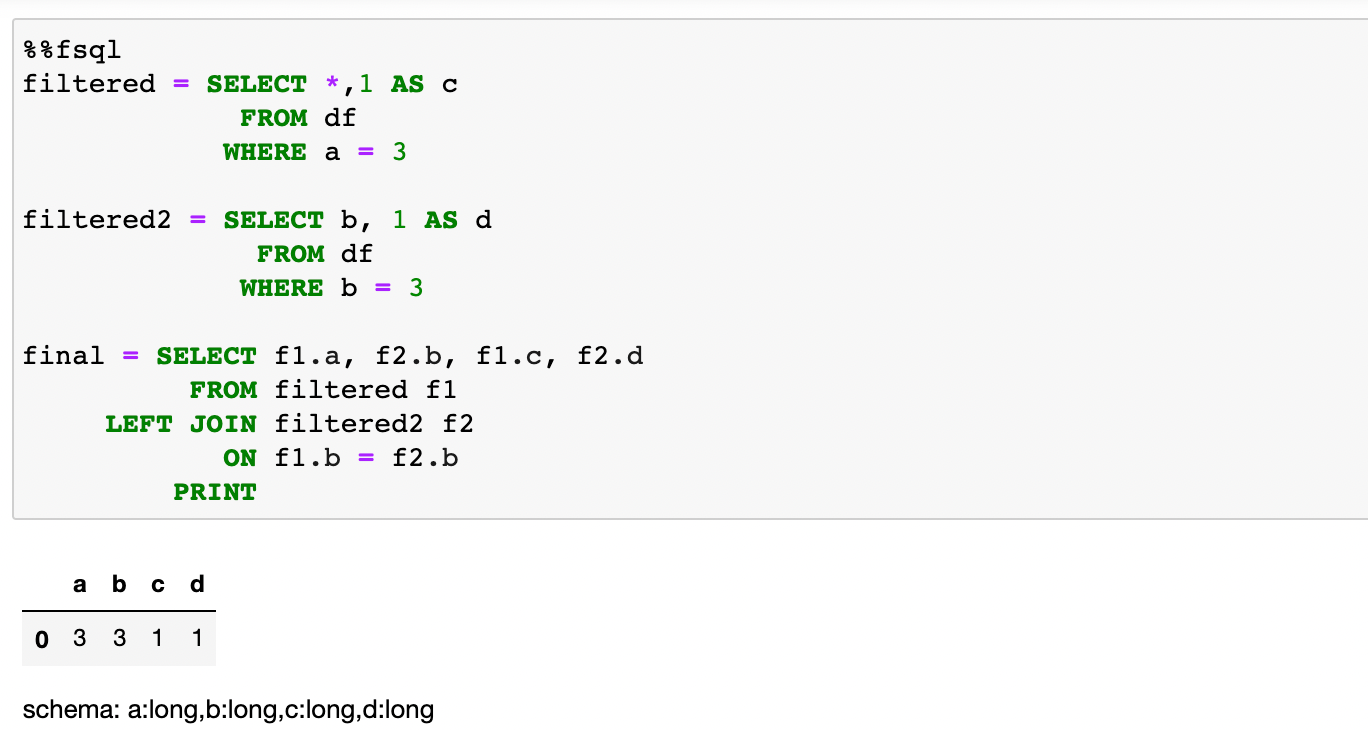
변수 할당
데이터 프레임은 변수에 할당 할 수 있습니다.이것은 SQL TEMP 테이블 또는 공통 테이블 표현식 (CTE)과 유사합니다.이 튜토리얼에서는이 데이터 프레임을 보여 주지만 SQL 셀에서 벗어나 파이썬 셀에서 사용될 수도 있습니다.아래 예제는 수정에서 나온 두 개의 새로운 데이터 프레임을 보여줍니다.Df.…에Df.파이썬 셀에서 팬더를 사용하여 생성되었습니다 (첫 번째 이미지와 동일한 DF).두 개의 새로운 데이터 프레임이 함께 가입되어 데이터 프레임이라는 데이터 프레임을 만듭니다.결정적인…에
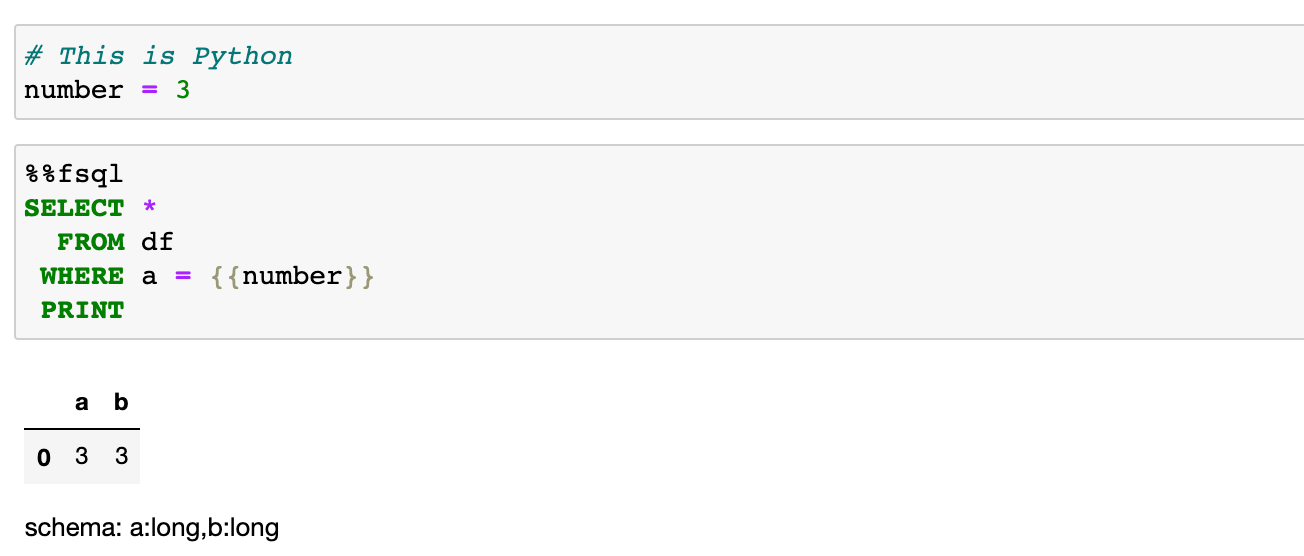
Jinja 템플릿
Fuguesql은 Jinja 템플릿을 통해 Python 변수와 상호 작용할 수 있습니다.이를 통해 Python Logic은 SQL의 매개 변수와 유사한 SQL 쿼리를 변경할 수 있습니다.
파이썬 기능
Fuguesql은 SQL 코드 블록 내에서 Python 함수를 사용하여 지원합니다.아래 예제에서는 우리가 사용합니다기분이 좋다데이터 프레임의 두 열을 줄입니다.우리는 그 기능을 사용하여 기능을 호출합니다산출SQL의 키워드.

Ipython-SQL과 비교합니다

FUGUSSQL은 이미 메모리에로드되는 데이터를 작동시키는 것을 의미합니다 (스토리지에서 데이터를 가져 오기 위해 데이터를 가져 오기 위해 사용하는 방법이있는 방법이 있습니다).프로젝트가 있습니다Ipython-SQL.그게 제시를 제공합니다%% SQL.셀 마술 명령.이 명령은 SQL을 사용하여 데이터를 데이터베이스에서 파이썬 환경에로드하는 것을 의미합니다.
Fuguesql의 보증은 코드 변경없이 팬더, 스파크 및 마스크에서 동일한 SQL 코드가 작동 할 것입니다.Fuguesql의 초점은 데이터베이스에서 데이터를 로딩하는 것과는 대조적으로 메모리가 메모리 계산입니다.
스파크와 마스크가있는 분산 계산
우리가 일하는 데이터의 양이 계속 증가함에 따라 스파크와 마스크와 같은 분산 계산 엔진이 데이터 팀에서보다 널리 채택되고 있습니다.Fuguesql을 사용하면 동일한 Profienant 엔진을 동일한 FuguesQL 코드를 사용할 수 있습니다.
아래 코드 스 니펫에서 우리는 방금 셀 마술을 변경했습니다.%% FSQL.…에%% fsql spark.그리고 이제 SQL 코드는 스파크 실행 엔진에서 실행됩니다.비슷하게,%% FSQL DASK.Dask 실행 엔진에서 SQL 코드를 실행합니다.

분산 된 컴퓨팅 환경으로 이사하는 것이 혜택을 누릴 수있는 공통된 작업 중 하나는 각 그룹의 중앙값을 얻고 있습니다.이 예제에서는 다음을 보여 드리겠습니다선다키워드 및 데이터의 각 파티션에 함수를 적용하는 방법.
첫째, 데이터 프레임을 가져 와서 출력하는 파이썬 함수를 정의합니다.user_id.그리고 중간측정…에이 기능은 단 하나만 작동하는 것을 의미합니다user_id.한 번에.기능이 팬더에서 정의 되더라도 스파크와 마스크에서 작동합니다.
그런 다음 그 다음에 사용할 수 있습니다선다우리의 데이터를 분할하는 키워드user_id.그를 적용하십시오get_median함수.

이 예에서는 각 사용자의 중앙값 측정을 얻습니다.데이터 크기가 커짐에 따라 병렬화에서 더 많은 이점이 나타납니다.an.예제 노트북우리는 팬더 엔진 이이 작업에 대해 약 520 초가 걸렸습니다.스파크 엔진 (4 코어 병렬)을 사용하여 320 백만 줄의 데이터 세트에는 약 70 초가 걸렸습니다.
실행 시간의 차이가 예상됩니다.FUGUSEQL을 사용하면 데이터가 팬더가 효과적으로 처리 할 때 너무 크면 워크 플로우가 워크 플로우를 확장하고 DASK로 워크 플로우를 확장합니다.
또 다른 공통 유스 케이스는 DASK가 메모리 파편을 처리하고 디스크에 데이터를 기록합니다.즉, 사용자는 메모리 부족 문제를 해결하기 전에 더 많은 데이터를 처리 할 수 있음을 의미합니다.
결론 및 더 많은 예
이 기사에서는 사용자가 JUPYTER 노트북의 SQL 셀을 통해 팬더, 스파크 및 DASK 데이터 프레임 상단에서 작업 할 수있게 해주는 FUGUSEQL의 기본 기능을 탐구했습니다.
Fugue는 논리 및 실행을 쉽게 실행하여 런타임 중에 실행 엔진을 쉽게 지정할 수 있습니다.이렇게하면 Compute Framework의 논리 indepedent를 표현할 수있게하여 무거운 SQL 사용자를 구축합니다.상황이 전화를 걸 때 워크 플로를 쉽게 이주하거나 스파크하거나 마그네트를 으납니다.
하나의 블로그 게시물에서 덮을 수없는 많은 세부 정보와 기능이 많이 있습니다.종단 간 예제의 경우Kaggle 노트북우리는 사상 적 데이터 분석가 부트 캠프 학생들을 위해 준비했습니다.
노트북의 설치
Pugue (및 Fuguesql)는 Pypi를 통해 사용할 수 있습니다.그들은 PIP를 사용하여 설치할 수 있습니다 (Dask 및 Spark 설치는 별도의 설치).
PIP 설치 Fugue
노트북 내부, Fuguesql 셀 마술%% FSQL.그를 실행 한 후에 사용할 수 있습니다설정함수.또한 SQL 명령에 대한 구문 강조 표시를 제공합니다.
Fugue_Notebook 가져 오기 설정에서
설정()
Contact Us
Fuguesql을 사용하는 데 관심이 있으시면, 우리에게 의견을 보내거나 질문이 있으시면, 우리는 여유로 채팅하게되어 기쁩니다!또한 데이터 워크 플로우에 Fuguesql (또는 Fugue)을 적용하는 데 관심이있는 데이터 팀에 워크샵을 제공하고 있습니다.
Fuguesql은 더 넓은 푸가 생태계의 한 부분 일뿐입니다.Fugue는 사용자가 기본 파이썬에 코드를 작성한 다음 런타임 중에 코드 변경없이 팬더, 스파크 또는 Dask에서 코드를 실행할 수있는 추상화 계층입니다.위의 Repo에서 자세한 정보를 찾을 수 있습니다.