
NLP를위한 세 가지 디코딩 방법
탐욕에서 빔 검색으로
영형자연어 처리 (NLP)에서 시퀀스 생성에서 자주 간과되는 부분 중 하나는 출력 토큰을 선택하는 방법입니다.디코딩.
당신은 생각할 수 있습니다-우리는 우리 모델에 의해 할당 된 각 토큰의 확률에 따라 토큰 / 단어 / 문자를 선택합니다.
이것은절반-true — 언어 기반 작업에서 일반적으로 확률 집합을 배열에 출력하는 모델을 구축합니다. 여기서 배열의 각 값은 특정 단어 / 토큰의 확률을 나타냅니다.
이 시점에서 migh확률이 가장 높은 토큰을 선택하는 것이 논리적으로 보입니까?글쎄요, 사실은 아닙니다. 이것은 우리가 곧 보게 될 예상치 못한 결과를 초래할 수 있습니다.
기계 생성 텍스트에서 토큰을 선택할 때이 디코딩을 수행하는 몇 가지 대체 방법과 정확한 동작을 수정하는 옵션도 있습니다.
이 기사에서는 출력 토큰을 선택하는 세 가지 방법을 살펴 보겠습니다.
& gt;탐욕스러운 디코딩& gt;랜덤 샘플링& gt;빔 검색
이러한 각각의 작동 방식을 이해하는 것은 매우 중요합니다. 종종 언어 응용 프로그램에서 출력 불량에 대한 해결책은이 네 가지 방법 사이의 간단한 전환이 될 수 있습니다.
비디오를 선호하는 경우 여기에서 세 가지 방법을 모두 다룹니다.
이러한 각 방법을 테스트 할 수 있도록 노트북을 포함했습니다.여기에 GPT-2.
탐욕스러운 디코딩
우리가 가진 가장 간단한 옵션은 탐욕스러운 디코딩입니다.이것은 우리의 잠재적 출력 목록과 이미 계산 된 확률 분포를 가져 와서 가장 높은 확률 (argmax)을 가진 옵션을 선택합니다.
이것은 완전히 논리적 인 것처럼 보이며 대부분의 경우 완벽하게 잘 작동합니다.그러나 더 긴 시퀀스의 경우 이로 인해 몇 가지 문제가 발생할 수 있습니다.
다음과 같은 출력을 본 적이 있다면 :
이것은 탐욕스러운 디코딩 방법이 특정 단어 또는 문장에 붙어 있고 이러한 단어 세트에 반복적으로 가장 높은 확률을 반복적으로 할당하기 때문일 가능성이 큽니다.
랜덤 샘플링
다음 옵션은 무작위 샘플링입니다.우리가 잠재적 인 산출물과 확률 분포를 얻기 전과 매우 유사합니다.
무작위 샘플링은 이러한 확률을 기반으로 다음 단어를 선택합니다. 따라서이 예에서는 다음과 같은 단어와 확률 분포가있을 수 있습니다.
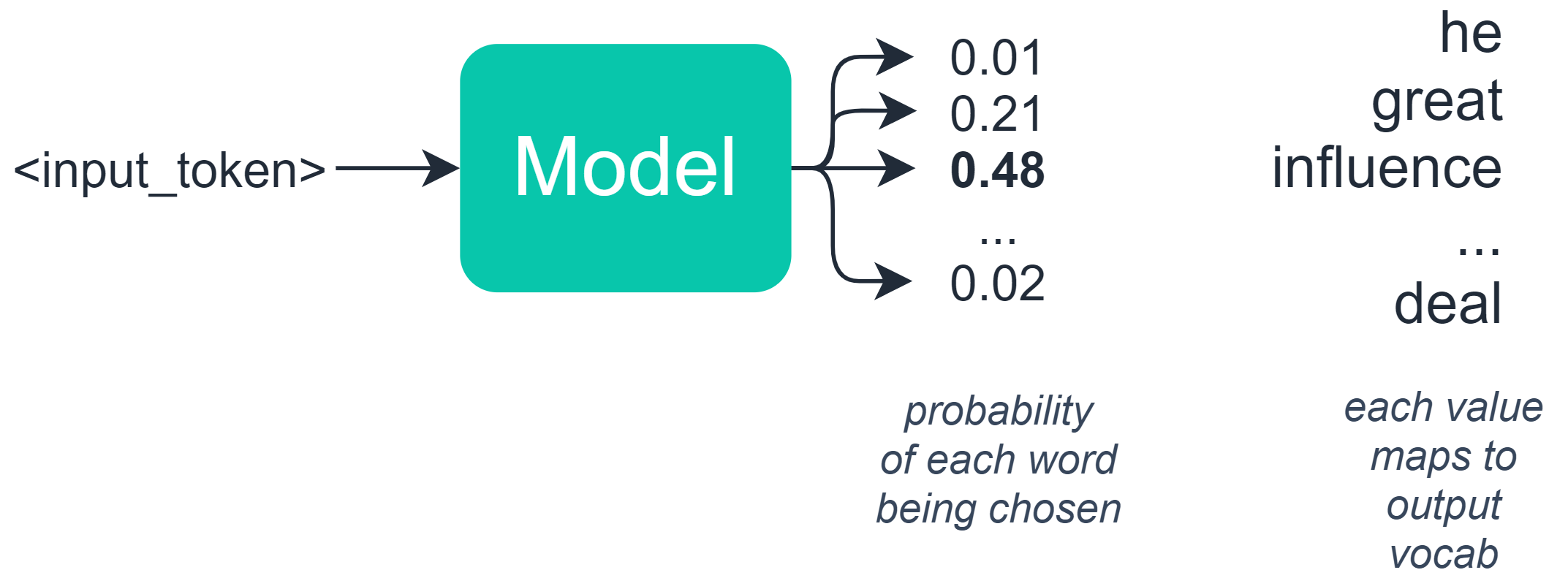
모델이 ‘영향력’을 선택할 확률은 48 %이고, ‘위대한’을 선택할 확률은 21 %입니다.
이것은 예측에 무작위성을 추가하기 때문에 같은 단어의 반복되는 루프에 갇히는 문제를 해결합니다.
그러나 이로 인해 다른 문제가 발생합니다. 이러한 접근 방식이 너무 무작위적이고 일관성이 부족할 수 있습니다.
그래서 한쪽에는탐욕스러운 검색텍스트를 생성하기에는 너무 엄격합니다. 다른 한편으로는무작위 샘플링멋진 횡설수설을 생성합니다.
우리는 두 가지 모두를 수행하는 무언가를 찾아야합니다.
빔 검색
빔 검색을 사용하면 최상의 옵션을 선택하기 전에 여러 수준의 출력을 탐색 할 수 있습니다.
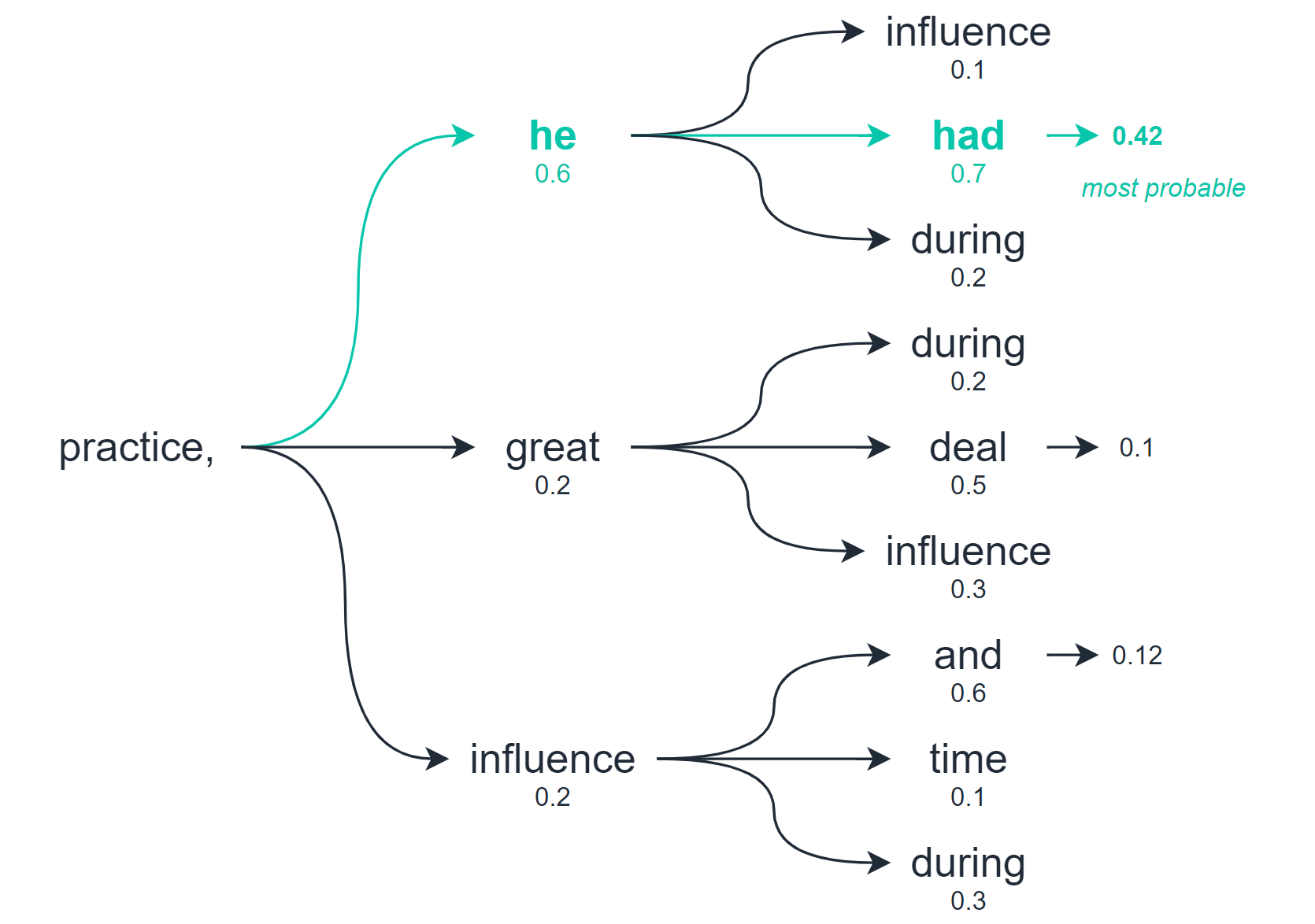
따라서 탐욕스러운 디코딩과 무작위 샘플링은 바로 다음 단어 / 토큰만을 기반으로 최상의 옵션을 계산하는 반면 빔 검색은 미래의 여러 단어 / 토큰을 확인하고 결합 된 모든 토큰의 품질을 평가합니다.
이 검색에서 여러 잠재적 인 출력 시퀀스를 반환합니다. 고려하는 옵션의 수는 검색 할 때 사용하는 ‘빔’의 수입니다.
그러나 이제 순서를 순위 지정하고 가장 가능성이 높은 순서를 선택하기 때문에 빔 검색으로 인해 텍스트 생성이 다시 반복되는 순서로 저하 될 수 있습니다.
따라서이를 방지하기 위해 디코딩을 늘립니다.온도— 출력의 임의성 정도를 제어합니다.기본값온도이다1.0—이 값을 약간 더 높은 값으로1.2큰 차이를 만듭니다.
이러한 수정으로 우리는 독특하지만 그럼에도 불구하고 일관된 결과를 얻었습니다.
이것으로 텍스트 생성 디코딩 방법에 대한 요약입니다!
기사를 즐겁게 읽으 셨기를 바랍니다. 질문이나 제안 사항이 있으면 알려주세요.트위터또는 아래 의견에.
읽어 주셔서 감사합니다!
Python에서 텍스트 생성 모델을 설정하는 방법에 관심이 있다면 여기에서 방법을 다루는이 짧은 기사를 작성했습니다.
* 달리 명시된 경우를 제외하고 모든 이미지는 작성자의 것입니다.