
Python을 사용하여 여러 Well Log LAS 파일로드
Pandas 데이터 프레임에 여러 LAS 파일 추가
Log ASCII Standard (LAS) 파일은 일반적인 Oil & amp;유정 로그 데이터를 저장하고 전송하기위한 가스 산업 형식.내부에 포함 된 데이터는 지하를 분석하고 이해하고 잠재적 인 탄화수소 매장량을 식별하는 데 사용됩니다.이전 기사에서 :웰 로그 데이터로드 및 표시, LASIO 라이브러리를 사용하여 단일 LAS 파일을로드하는 방법을 다루었습니다.
이 기사에서는 다음과 같이 확장합니다. 여러 개의 las 파일을 하위 폴더에서 단일로로드하는 방법을 보여줍니다.팬더 데이터 프레임.이렇게하면 여러 우물의 데이터로 작업하고 matplotlib를 사용하여 데이터를 빠르게 시각화 할 수 있습니다.또한 기계 학습 알고리즘을 실행하기에 적합한 단일 형식으로 데이터를 준비 할 수 있습니다.
이 기사는 내 Python & amp;Petrophysics 시리즈.전체 시리즈의 세부 정보를 찾을 수 있습니다.여기.다음 링크의 GitHub 저장소에서 내 Jupyter 노트북 및 데이터 세트를 찾을 수도 있습니다.
이 기사를 따르기 위해 Jupyter Notebook은 위의 링크에서 찾을 수 있으며이 기사의 데이터 파일은데이터 하위 폴더Python & amp;Petrophysics 저장소.
이 기사에 사용 된 데이터는 공개적으로 액세스 할 수있는네덜란드 NLOG 네덜란드 석유 및 가스 포털.
라이브러리 설정
첫 번째 단계는 우리가 작업 할 도서관을 가져 오는 것입니다.우리는 5 개의 라이브러리를 사용할 것입니다.판다,matplotlib,Seaborn,os, 및Lasio.
Pandas, os 및 lasio는 데이터를로드하고 저장하는 데 사용되는 반면 matplotlib 및 seaborn을 사용하면 우물의 내용을 시각화 할 수 있습니다.
다음으로 모든 las 파일 이름을 저장할 빈 목록을 설정합니다.
둘째,이 예에서는 Data / 15-LASFiles /라는 하위 폴더에 파일이 저장되어 있습니다.이것은 파일이 저장된 위치에 따라 변경됩니다.
이제 우리는os.listdir메서드를 사용하고 파일 경로를 전달합니다.이 코드를 실행하면 데이터 폴더에있는 모든 파일 목록을 볼 수 있습니다.
이 코드에서 폴더의 내용 목록을 얻습니다.
[ 'L05B03_comp.las',
'L0507_comp.las',
'L0506_comp.las',
'L0509_comp.las',
'WLC_PETRO_COMPUTED_1_INF_1.ASC']
Reading the LAS Files
위에서 볼 수 있듯이 4 개의 LAS 파일과 1 개의 ASC 파일을 반환했습니다.LAS 파일에만 관심이 있으므로 각 파일을 반복하고 확장자가 .las인지 확인해야합니다.또한 확장자가 대문자 인 경우 (.las 대신 .LAS)를 포착하려면 다음을 호출해야합니다..보다 낮은()파일 확장자 문자열을 소문자로 변환합니다.
파일이 .las로 끝나는지를 확인한 후 파일 이름에 경로 (‘Data / 15-LASFiles /’)를 추가 할 수 있습니다.이는 lasio가 파일을 올바르게 선택하는 데 필요합니다.파일 이름 만 전달하면 독자는 스크립트 또는 노트북과 동일한 디렉토리를보고 결과적으로 실패합니다.
우리가 전화 할 때las_file_list4 개의 LAS 파일 각각에 대한 전체 경로를 볼 수 있습니다.
[ 'Data / 15-LASFiles / L05B03_comp.las',
'Data / 15-LASFiles / L0507_comp.las',
'Data / 15-LASFiles / L0506_comp.las',
'Data / 15-LASFiles / L0509_comp.las']
Appending Individual LAS Files to a Pandas Dataframe
데이터 프레임에 데이터를 연결 및 / 또는 추가하는 방법에는 여러 가지가 있습니다.이 기사에서는 함께 연결할 데이터 프레임 목록을 만드는 간단한 방법을 사용합니다.
먼저 다음을 사용하여 빈 목록을 만듭니다.df_list = [].그런 다음 두 번째로 las_file_list를 반복하고 파일을 읽고 데이터 프레임으로 변환합니다.
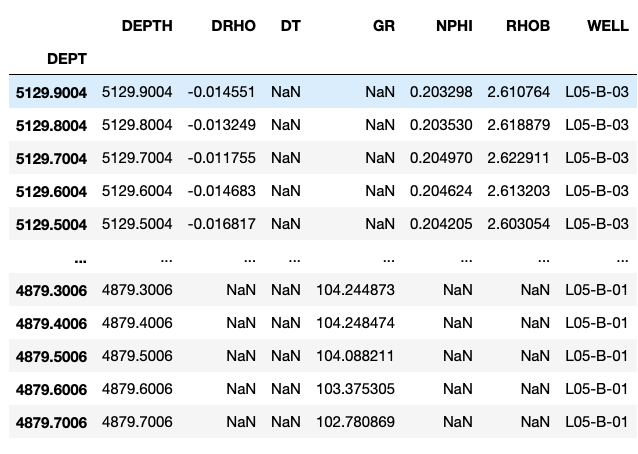
데이터의 출처를 아는 것이 유용합니다.이 정보를 보관하지 않으면 출처에 대한 정보가없는 데이터로 가득 찬 데이터 프레임이됩니다.이를 위해 새 열을 만들고 웰 이름 값을 할당 할 수 있습니다.lasdf [ 'WELL'] = las.well.WELL.value.이렇게하면 나중에 데이터를 쉽게 사용할 수 있습니다.
또한 lasio가 데이터 프레임 인덱스를 파일의 깊이 값으로 설정하면 다음과 같은 추가 열을 만들 수 있습니다.깊이.
이제 목록 객체를 연결하여 LAS 파일의 모든 데이터를 포함하는 작업 데이터 프레임을 만듭니다.
작동중인 데이터 프레임을 호출하면 동일한 데이터 프레임에있는 여러 웰의 데이터가 있음을 알 수 있습니다.
또한 웰 열 내의 고유 한 값을 확인하여 모든 웰이로드되었는지 확인할 수 있습니다.
고유 한 웰 이름의 배열을 반환합니다.
배열 ([ 'L05-B-03', 'L05-07', 'L05-06', 'L05-B-01'], dtype = object)LAS 파일에 다른 곡선 니모닉이 포함되어있는 경우 (대개 경우) 데이터 프레임에 아직없는 각각의 새 니모닉에 대해 새 열이 생성됩니다.
빠른 데이터 시각화 만들기
이제 데이터를 pandas 데이터 프레임 객체에로드 했으므로 간단하고 빠른 다중 플롯을 만들어 데이터에 대한 통찰력을 얻을 수 있습니다.교차 플롯 / 산점도, 상자 플롯 및 KDE (Kernel Density Estimate) 플롯을 사용하여이를 수행합니다.
이를 시작하려면 먼저 다음을 사용하여 웰 이름별로 데이터 프레임을 그룹화해야합니다.
웰당 교차도 / 산점도
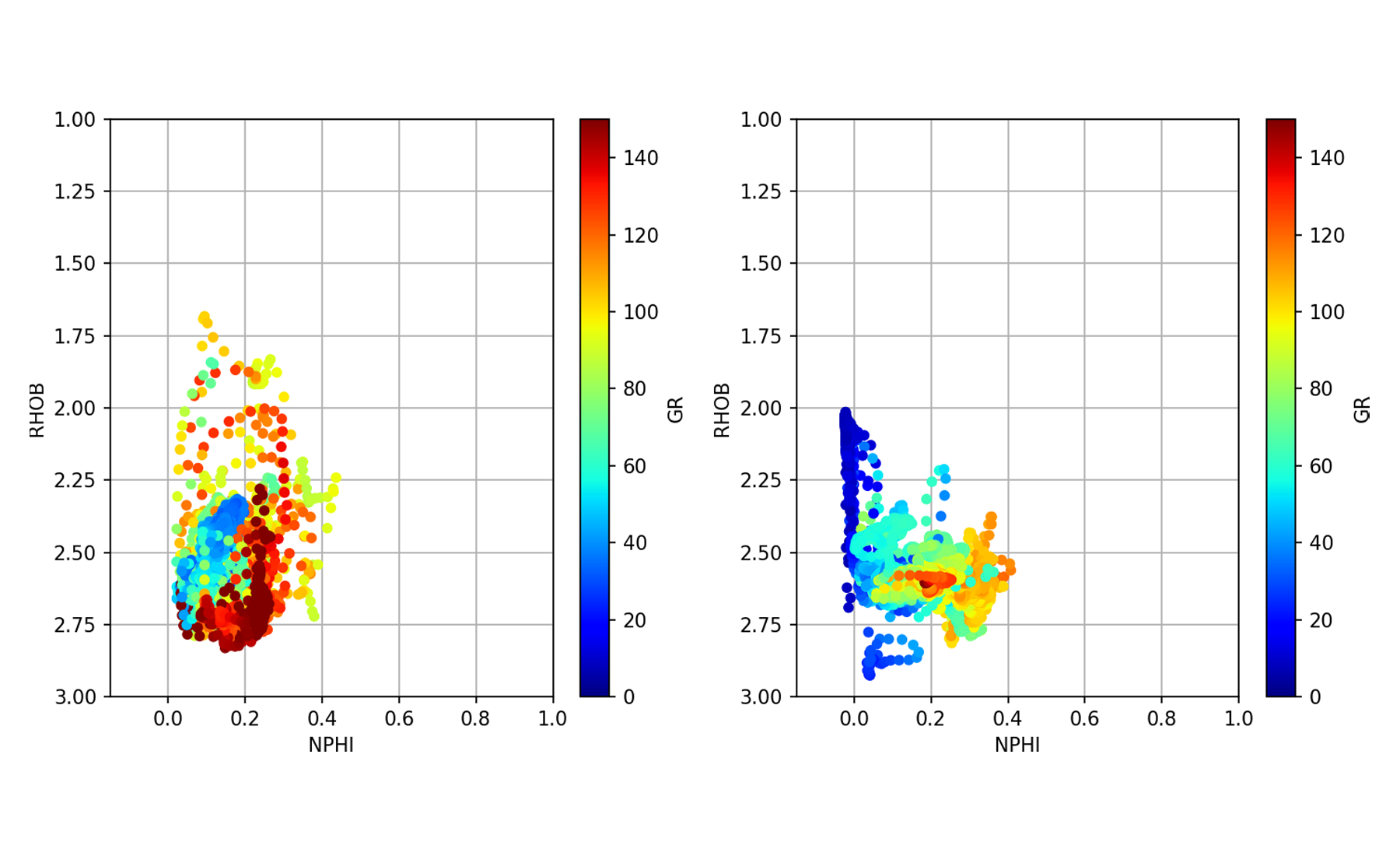
교차 도표 (산점도라고도 함)는 한 변수를 다른 변수에 대해 도표화하는 데 사용됩니다.이 예에서는 중성자 다공성 대 벌크 밀도 교차 플롯을 사용합니다. 이것은 페트로 피학에서 사용되는 매우 일반적인 플롯입니다.
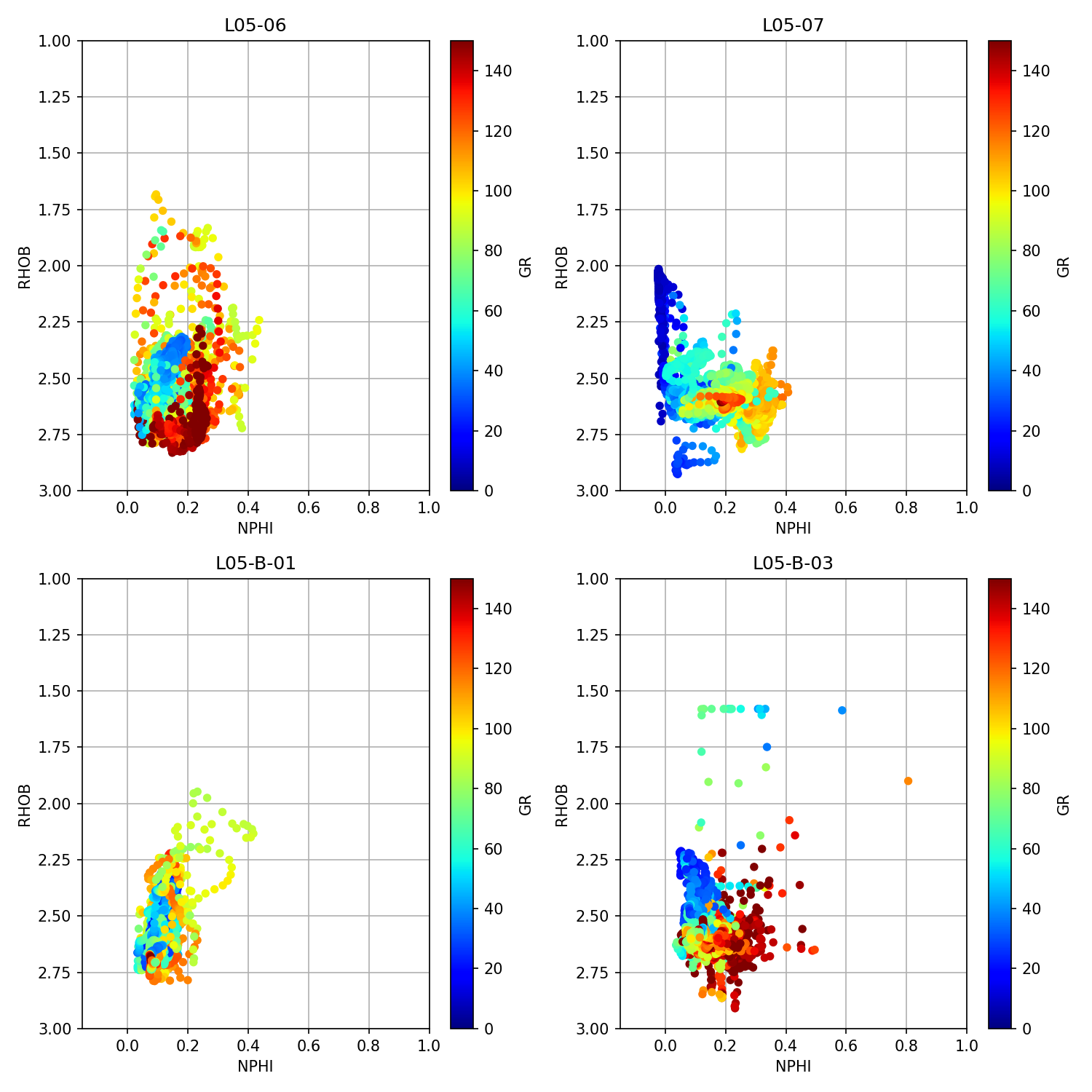
앞서 언급 한 유사한 코드를 사용하여웰 로그 데이터를 사용한 탐색 데이터 분석기사에서는 데이터 프레임의 각 그룹을 반복하고 중성자 다공성 (NPHI) 대 벌크 밀도 (RHOB)의 교차 플롯 (분산도)을 생성 할 수 있습니다.
이렇게하면 4 개의 서브 플롯이있는 다음 이미지가 생성됩니다.
웰당 감마선의 상자 그림
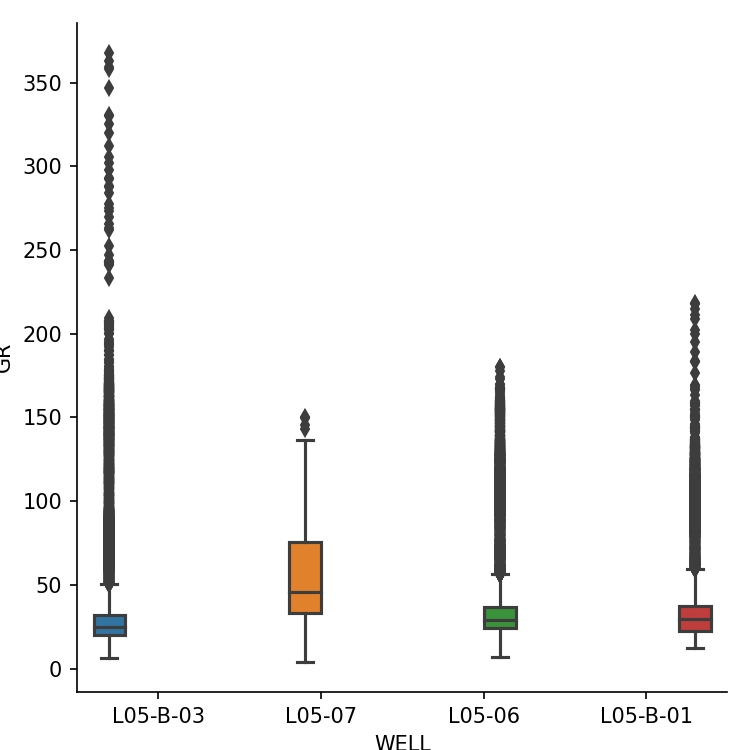
다음으로 모든 우물에서 나온 감마선 큐브의 상자 그림을 표시합니다.박스 플롯은 데이터의 범위 (최소에서 최대까지), 사 분위수 및 데이터의 중앙값을 보여줍니다.
이것은 seaborn 라이브러리에서 한 줄의 코드를 사용하여 달성 할 수 있습니다.인수에서 데이터에 대한 workingdf 데이터 프레임을 전달하고 색조에 대한 WELL 열을 전달할 수 있습니다.후자는 데이터를 각각 고유 한 색상을 가진 개별 상자로 분할합니다.
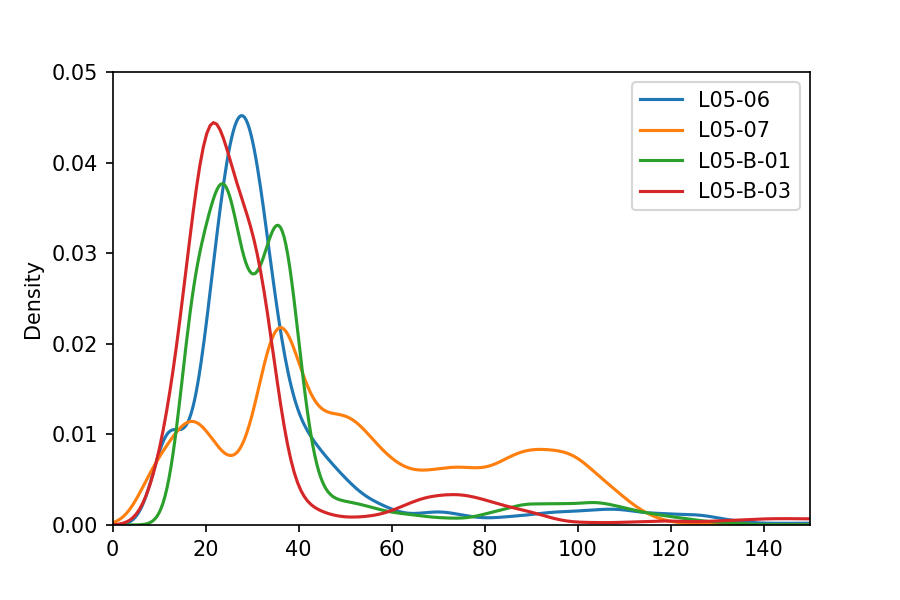
히스토그램 (커널 밀도 추정치)
마지막으로 히스토그램과 유사한 Kernel Density Estimate 플롯을 사용하여 데이터 프레임에서 곡선 값의 분포를 볼 수 있습니다.
다시 말하지만,이 예제는 groupby 함수를 적용하는 다른 방법을 보여줍니다.x 및 y 제한을 설정하기 위해 matplotlib 함수를 호출하여 플롯을 정리할 수 있습니다.
요약
이 기사에서는 디렉토리에서 .las 확장자를 가진 모든 파일을 검색하여 여러 LAS 파일을로드하고 단일 파일로 연결하는 방법에 대해 설명했습니다.팬더 데이터 프레임.데이터 프레임에이 데이터가 있으면 matplotlib 및 seaborn을 쉽게 호출하여 데이터 시각화를 빠르고 쉽게 이해할 수 있습니다.
읽어 주셔서 감사합니다!
이 기사가 유용하다고 생각되면 Python의 다양한 측면과 로그 데이터를 살펴 보는 다른 기사를 자유롭게 확인하십시오.이 기사 및 기타에서 사용 된 내 코드는GitHub.
연락하고 싶다면 나를 찾을 수 있습니다.LinkedIn 또는 내웹 사이트.
파이썬에 대해 더 많이 배우고 데이터 또는 페트로 피학을 잘 기록하고 싶으십니까?나를 따라와매질.