Python은 다재다능한 프로그래밍 언어입니다.파이썬은 라이브러리와 높은 수준의 언어로 인해 기계 학습 문제 해결에 가장 많이 사용되지만 다른 많은 언어보다 느린 것으로 알려져 있습니다.그 명성 때문에 많은 사람들이 언어를 버리고 프로그램 해결을 위해 C ++와 같은 다른 옵션을 고수하기로 결정했습니다.
이 기사에서는 파이썬이 C ++보다 얼마나 빠른지 보여줄 것입니다.
기본 속도 테스트
Python과 C ++의 정상적인 속도 차이를 테스트하기 위해소수의 생성연산.두 언어 모두에서 명확한 짧은 단계가있는 간단한 알고리즘입니다.
소수 생성 순서도
Python 구현
수입 수학 카운터 당 시간 가져 오기에서def is_prime (num) : 만약 num == 2 : 반환 True; num & lt; = 1이거나 num % 2가 아닌 경우 : False를 반환 range (3, int (math.sqrt (num) +1), 2)의 div의 경우 : num % div가 아닌 경우 : False를 반환 True 반환def 실행 프로그램 (N) : i 범위 (N) : is_prime (i)__name__ ==‘__main__’인 경우 : N = 10000000 시작 = perf_counter () 프로그램 실행 (N) 끝 = perf_counter () 인쇄 (끝-시작)
C++ Implementation
#include <iostream> #include <cmath> #include <time.h>using namespace std;bool isPrime(int num) { if (num == 2) return true; if (num <= 1 || num % 2 == 0) return false; double sqrt_num = sqrt(double(num)); for (int div = 3; div <= sqrt_num; div +=2){ if (num % div == 0) return false; } return true;}int main() { int N = 10000000; clock_t start,end; start = clock(); for (int i; i < N; i++) isPrime(i); end = clock(); cout << (end — start) / ((double) CLOCKS_PER_SEC); return 0;}
Results
Python: 80.137 seconds
C++ : 3.174 seconds
Comment
예상대로 C ++은 기본 테스트에서 Python보다 25 배 더 빠릅니다.따라서 평판은 사실이며 이것은 논리적입니다.
Python은 C ++와 달리 동적 언어입니다.
GIL (Python Global Interpreter)은 병렬 프로그래밍을 허용하지 않습니다.
이 속도 차이는 파이썬이 유연한 다목적 언어로 만들어 졌기 때문에 수정할 수 있습니다.속도 문제에 대한 최고의 솔루션 중 하나는Numba.
Numba
Numba는 Python 및 NumPy 코드의 하위 집합을 빠른 기계 코드로 변환하는 오픈 소스 JIT 컴파일러입니다.~위키 백과
간단히 말해서 Numba는 Python을 빠르게 만드는 라이브러리입니다.사용하기 매우 쉽고 코드 속도를 크게 변경합니다.Numba 사용을 시작하려면 콘솔 사용을 사용하여 설치하십시오.
pip 설치 numba
Python Implementation After Using Numba
import math from time import per_counter from numba import njit, prange@njit(fastmath=True, cache=True) def is_prime(num): if num == 2: return True; if num <= 1 or not num % 2: return False for div in range(3,int(math.sqrt(num)+1),2): if not num % div: return False return True@njit(fastmath=True, cache=True,parallel=True) def run program(N): for i in prange(N): is_prime(i)if __name__ == ‘__main__’: N = 10000000 start = perf_counter() run_program(N) end = perf_counter() print (end — start)
결과
파이썬: 1.401 초 C ++: 3.174 초
따라서 Python은 C ++보다 빠릅니다.따라서 Python에서 알고리즘의 속도를 C ++보다 빠르게 할 수 있습니다.
Python is a great versatile programming language. Even though python is used most for machine learning problem solving because of its library and high-level language, it is known to be slower than many other languages. Because of its reputation, many would decide to leave the language behind and stick with other options like C++ for program solving.
In this article, I will show you how Python is faster than C++.
Basic Speed Testing
To test the normal speed difference between Python and C++, I will test the execution time of the Generation of primes algorithm. It is a simple algorithm with clear short steps in both languages.
Generation of primes flowchart
Python Implementation
import math from time import per_counter def is_prime(num): if num == 2: return True; if num <= 1 or not num % 2: return False for div in range(3,int(math.sqrt(num)+1),2): if not num % div: return False return Truedef run program(N): for i in range(N): is_prime(i)if __name__ == ‘__main__’: N = 10000000 start = perf_counter() run_program(N) end = perf_counter() print (end — start)
C++ Implementation
#include <iostream> #include <cmath> #include <time.h>using namespace std;bool isPrime(int num) { if (num == 2) return true; if (num <= 1 || num % 2 == 0) return false; double sqrt_num = sqrt(double(num)); for (int div = 3; div <= sqrt_num; div +=2){ if (num % div == 0) return false; } return true;}int main() { int N = 10000000; clock_t start,end; start = clock(); for (int i; i < N; i++) isPrime(i); end = clock(); cout << (end — start) / ((double) CLOCKS_PER_SEC); return 0;}
Results
Python: 80.137 seconds
C++ : 3.174 seconds
Comment
As expected, C++ was 25 times faster than Python in our basic test. So the reputation is true, and this is logical as
Python is a dynamic language, unlike C++.
GIL (Python Global Interpreter) doesn’t allow parallel programming.
This speed difference can be fixed as python was created to be a flexible versatile language. One of the top solutions for the speed problem is using Numba.
Numba
Numba is an open source JIT compiler that translates a subset of Python and NumPy code into fast machine code. ~ Wikipedia
Briefly, Numba is a library that makes Python fast. It is very easy to use and dramatically change how fast your code. To start using Numba, just install it using the console use
pip install numba
Python Implementation After Using Numba
import math from time import per_counter from numba import njit, prange@njit(fastmath=True, cache=True) def is_prime(num): if num == 2: return True; if num <= 1 or not num % 2: return False for div in range(3,int(math.sqrt(num)+1),2): if not num % div: return False return True@njit(fastmath=True, cache=True,parallel=True) def run program(N): for i in prange(N): is_prime(i)if __name__ == ‘__main__’: N = 10000000 start = perf_counter() run_program(N) end = perf_counter() print (end — start)
Results
Python: 1.401 seconds C++ : 3.174 seconds
So Python is faster than C++. So it is possible to speed up your algorithms in Python to be faster than C++.
경기도 용인시 기흥구 탑실로 152, 215동 2층202호 (공세동,탑실마을대주피오레2단지) [집합건물 철근콘크리트구조 120.8200㎡]
항목
값
경매번호
2020타경9656
경매날짜
2021.02.18
법원
수원지방법원
담당
경매7계
감정평가금액
370,000,000
경매가
370,000,000(100%)
유찰여부
신건
1. 재매각임(매수신청보증금 30%)
<최근 1년 실거래가 정보> – 총 거래 수: 0건 – 동일 평수 거래 수: 0건
경기도 용인시 기흥구 동백죽전대로527번길 67, 205동 21층2101호 (중동,어정마을롯데캐슬에코2단지) [집합건물 철근콘크리트조 113.76㎡]
항목
값
경매번호
2020타경6039
경매날짜
2021.02.16
법원
수원지방법원
담당
경매2계
감정평가금액
544,000,000
경매가
544,000,000(100%)
유찰여부
신건
<최근 1년 실거래가 정보> – 총 거래 수: 0건 – 동일 평수 거래 수: 0건
경기도 용인시 기흥구 언남로 17-1, 상가동 지하1층지하101-1호 (언남동,하마비마을동일하이빌2차아파트) [집합건물 철근콘크리트벽식조 53.605㎡], 경기도 용인시 기흥구 언남로 17-1, 상가동 지하1층지하102호 (언남동,하마비마을동일하이빌2차아파트) [집합건물 철근콘크리트벽식조 76.500㎡], 경기도 용인시 기흥구 언남로 17-1, 상가동 지하1층지하103호 (언남동,하마비마을동일하이빌2차아파트) [집합건물 철근콘크리트벽식조 76.500㎡], 경기도 용인시 기흥구 언남로 17-1, 상가동 지하1층지하104호 (언남동,하마비마을동일하이빌2차아파트) [집합건물 철근콘크리트벽식조 39.780㎡]
항목
값
경매번호
2020타경2167
경매날짜
2021.02.17
법원
수원지방법원
담당
경매5계
감정평가금액
436,000,000
경매가
213,640,000(49%)
유찰여부
유찰\t2회
1. 일괄매각, 목록1내지4는 벽체 구분 없이 1개호로 세탁업소로 이용중임. 지하층 도면상 복도 일부를 벽체로 막아 본건 경매물건이 아닌 B101-2호를 사용하고 있음 2. 이 사건 부동산의 점유자인 이세인으로부터 2020.3.4.에 유치권신고서 및 2020.5.29.에 유치권권리변경신고서가 접수됨(이 사건 부동산에 대한 매매계약금 반환청구권 및 지연손해금 81,192,657원, 매매계약 해제로 인하여 신고인이 당연히 취할 수 있었던 이행이익에 관한 손해배상채권146,000,000원, 47개월간 점유하면서 발생한 비용상환청구채권 101,996,580원 총329,189,237원)
<최근 1년 실거래가 정보> – 총 거래 수: 0건 – 동일 평수 거래 수: 0건
경기도 용인시 처인구 고림동 184-1 7동 402호 [집합건물 철근콘크리트조 135.074㎡]
항목
값
경매번호
2019타경515971
경매날짜
2021.02.17
법원
수원지방법원
담당
경매5계
감정평가금액
56,000,000
경매가
56,000,000(100%)
유찰여부
신건
1. 건축법상 사용승인 받지 않은 건물임, 대지권 없음, 미완공상태임
<최근 1년 실거래가 정보> – 총 거래 수: 0건 – 동일 평수 거래 수: 0건
경기도 용인시 처인구 고림동 186-12 8층 801호 [집합건물 철근콘크리트조 141.22㎡]
항목
값
경매번호
2019타경515971
경매날짜
2021.02.17
법원
수원지방법원
담당
경매5계
감정평가금액
60,000,000
경매가
60,000,000(100%)
유찰여부
신건
1. 건축법상 사용승인 받지 않은 건물임, 대지권 없음, 미완공상태임
<최근 1년 실거래가 정보> – 총 거래 수: 0건 – 동일 평수 거래 수: 0건
경기도 용인시 기흥구 언남로 15, 208동 11층1101호 (언남동,하마비마을동일하이빌2차아파트) [집합건물 철근콘크리트벽식조 161.549㎡]
Dask분석을위한 고급 병렬 처리를 제공하여 좋아하는 도구에 대한 대규모 성능을 지원합니다.여기에는 numpy, pandas 및 sklearn이 포함됩니다.오픈 소스이며 자유롭게 사용할 수 있습니다.기존 Python API 및 데이터 구조를 사용하여 Dask로 구동되는 등가물간에 쉽게 전환 할 수 있습니다.
VaexLazy Out-of-Core DataFrames (Pandas와 유사)를위한 고성능 Python 라이브러리로, 큰 테이블 형식 데이터 세트를 시각화하고 탐색합니다.초당 10 억 개 이상의 행에 대한 기본 통계를 계산할 수 있습니다.빅 데이터의 대화 형 탐색을 허용하는 여러 시각화를 지원합니다.
Dask 및 Vaex 데이터 프레임은 Pandas 데이터 프레임과 완전히 호환되지 않지만 가장 일반적인 “데이터 랭 글링”작업은 두 도구에서 모두 지원됩니다.Dask는 클러스터를 계산하기 위해 코드를 확장하는 데 더 중점을 두는 반면 Vaex는 단일 컴퓨터에서 대규모 데이터 세트로 작업하기가 더 쉽습니다.
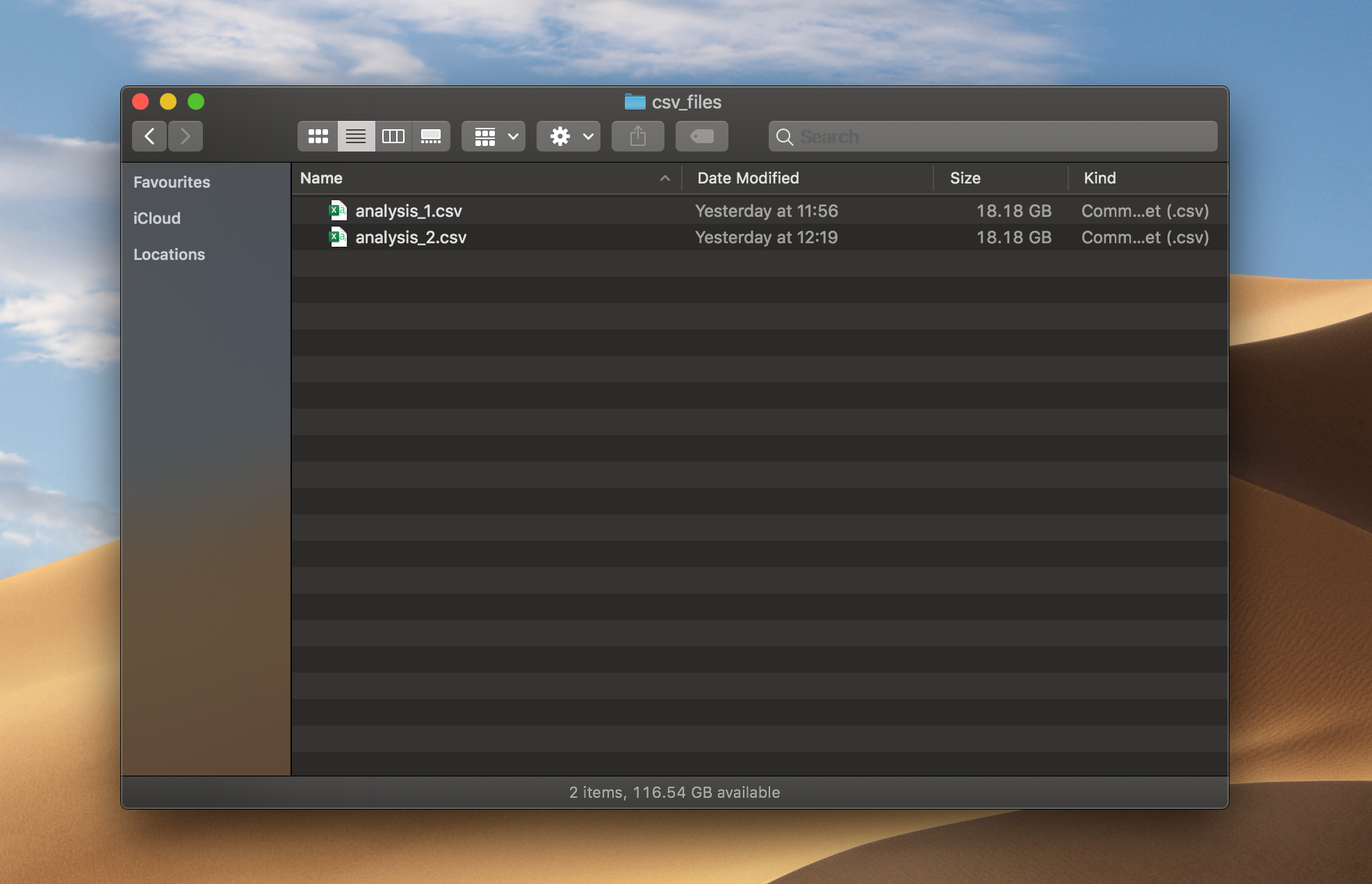
1 백만 개의 행과 1000 개의 열이있는 두 개의 CSV 파일을 생성했습니다.파일 크기는 18.18GB로 합쳐서 36.36GB입니다.파일에는 0과 100 사이의 균일 분포에서 난수가 있습니다.
임의 데이터가있는 두 개의 CSV 파일.저자가 만든 사진
팬더를 pd로 가져 오기 numpy를 np로 가져 오기OS 가져 오기 경로에서n_rows = 1_000_000 n_cols = 1000범위 (1, 3)에있는 i의 경우 : 파일 이름 = 'analysis_ % d.csv'% i file_path = path.join ( 'csv_files', 파일 이름) df = pd.DataFrame (np.random.uniform (0, 100, size = (n_rows, n_cols)), columns = [ 'col % d'% i for i in range (n_cols)]) print ( '저장', 파일 _ 경로) df.to_csv (file_path, index = False)df.head ()
Head of a file. Photo made by the author
이 실험은 32GB의 메인 메모리를 갖춘 MacBook Pro에서 실행되었습니다.pandas Dataframe의 한계를 테스트 할 때 놀랍게도 그러한 컴퓨터에서 메모리 오류에 도달하는 것이 상당히 어렵다는 것을 알았습니다!
macOS는 메모리가 용량에 가까워지면 메인 메모리에서 SSD로 데이터를 덤프하기 시작합니다.Pandas Dataframe의 상한은 머신의 100GB 여유 디스크 공간이었습니다.
WMac에 메모리가 필요한 경우 현재 사용되지 않는 항목을 임시 저장을 위해 스왑 파일로 푸시합니다.다시 액세스해야 할 때 스왑 파일에서 데이터를 읽어 메모리에 다시 넣습니다.
실험이 공정 해지려면이 문제를 어떻게 해결해야할지 고민했습니다.내 마음에 떠오른 첫 번째 아이디어는 각 라이브러리가 주 메모리 만 사용할 수 있도록 스와핑을 비활성화하는 것이 었습니다. macOS에서 행운을 빕니다.몇 시간을 보낸 후 스와핑을 비활성화 할 수 없었습니다.
두 번째 아이디어는 무차별 대입 방식을 사용하는 것이 었습니다.기기에 여유 공간이 없어 운영 체제에서 스왑을 사용할 수 없도록 SSD를 전체 용량으로 채웠습니다.
실험 중 디스크가 거의 꽉 찼습니다.저자가 만든 사진
이것은 효과가 있었다!Pandas는 두 개의 18GB 파일을 읽을 수 없었고 Jupyter Kernel이 다운되었습니다.
이 실험을 다시 수행하면 메모리가 더 적은 가상 머신을 만들 것입니다.이렇게하면 이러한 도구의 한계를 더 쉽게 보여줄 수 있습니다.
Dask 또는 Vaex가 이러한 대용량 파일을 처리하는 데 도움을 줄 수 있습니까?어느 것이 더 빠릅니까?알아 보자.
실험을 설계 할 때 데이터 분석을 수행 할 때 데이터 그룹화, 필터링 및 시각화와 같은 기본 작업을 생각했습니다.다음 작업을 생각해 냈습니다.
열의 10 번째 분위수 계산,
새 열 추가,
열로 필터링,
열별로 그룹화 및 집계,
열 시각화.
위의 모든 작업은 단일 열을 사용하여 계산을 수행합니다. 예 :
# 단일 열로 필터링 df [df.col2 & gt;10]
그래서 모든 데이터를 처리해야하는 작업을 시도하고 싶었습니다.
모든 열의 합계를 계산합니다.
이것은 계산을 더 작은 청크로 분할하여 달성 할 수 있습니다.예 :각 열을 개별적으로 읽고 합계를 계산하고 마지막 단계에서 전체 합계를 계산합니다.이러한 유형의 계산 문제는 다음과 같이 알려져 있습니다.난처하게 평행— 문제를 별도의 작업으로 분리하기 위해 노력할 필요가 없습니다.
Vaex부터 시작하겠습니다.실험은 각 도구에 대한 모범 사례를 따르는 방식으로 설계되었습니다. 이것은 Vaex 용 바이너리 형식 HDF5를 사용하는 것입니다.따라서 CSV 파일을 HDF5 형식 (The Hierarchical Data Format 버전 5)으로 변환해야합니다.
glob 가져 오기 수입 vaexcsv_files = glob.glob ( 'csv_files / *. csv')i의 경우 enumerate (csv_files, 1)의 csv_file : j의 경우 enumerate (vaex.from_csv (csv_file, chunk_size = 5_000_000), 1)의 dv : print ( '% d % s을 (를) hdf5 부분 % d'로 내보내는 중 '% (i, csv_file, j)) dv.export_hdf5 (f'hdf5_files / analysis_ {i : 02} _ {j : 02} .hdf5 ')
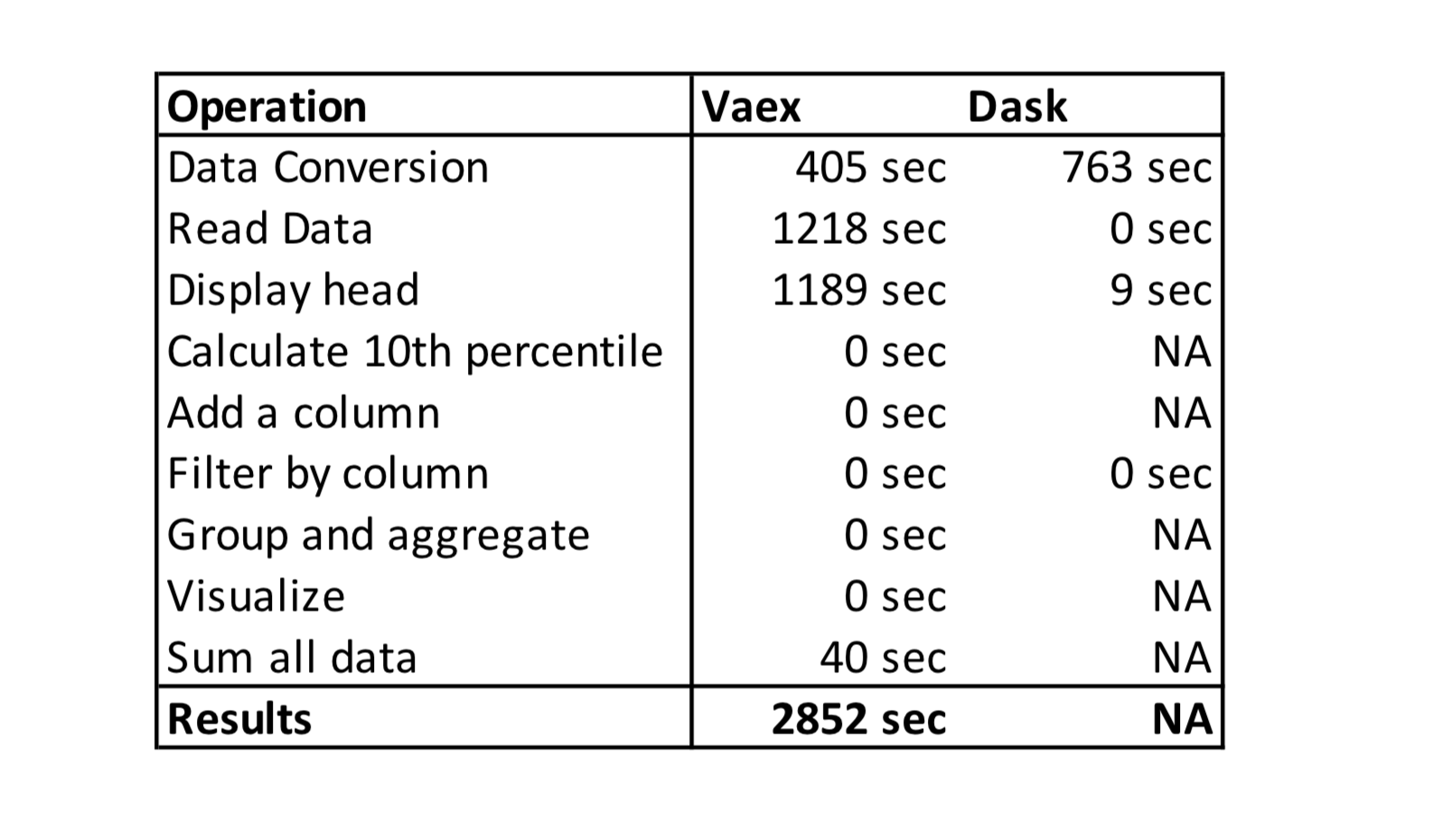
Vaex는 2 개의 CSV 파일 (36.36GB)을 16GB가 결합 된 2 개의 HDF5 파일로 변환하는 데 405 초가 필요했습니다.텍스트에서 이진 형식으로 변환하면 파일 크기가 줄어 들었습니다.
Vaex로 HDF5 데이터 세트 열기 :
dv = vaex.open('hdf5_files/*.hdf5')
Vaex는 HDF5 파일을 읽는 데 1218 초가 필요했습니다.Vaex가 바이너리 형식의 파일을 거의 즉시 열 수 있다고 주장하므로 더 빠를 것으로 예상했습니다.
I recently wrote two introductory articles about processing Big Data with Dask and Vaex — libraries for processing bigger than memory datasets. While writing, a question popped up in my mind:
Can these libraries really process bigger than memory datasets or is it all just a sales slogan?
This intrigued meto make a practical experiment with Dask and Vaex and try to process a bigger than memory dataset. The dataset was so big that you cannot even open it with pandas.
Big Data is a loosely defined term,which has as many definitions as there are hits on Google. In this article, I use the term to describe a dataset that is so big that we need specialized software to process it. With Big, I am referring to “bigger than the main memory on a single machine”.
Definition from Wikipedia:
Big data is a field that treats ways to analyze, systematically extract information from, or otherwise, deal with data sets that are too large or complex to be dealt with by traditional data-processing application software.
Dask provides advanced parallelism for analytics, enabling performance at scale for the tools you love. This includes numpy, pandas and sklearn. It is open-source and freely available. It uses existing Python APIs and data structures to make it easy to switch between Dask-powered equivalents.
Vaex is a high-performance Python library for lazy Out-of-Core DataFrames (similar to Pandas), to visualize and explore big tabular datasets. It can calculate basic statistics for more than a billion rows per second. It supports multiple visualizations allowing interactive exploration of big data.
Dask and Vaex Dataframes are not fully compatible with Pandas Dataframes but some most common “data wrangling” operations are supported by both tools. Dask is more focused on scaling the code to compute clusters, while Vaex makes it easier to work with large datasets on a single machine.
In case you’ve missed my articles about the Dask and Vaex:
I’ve generated two CSV files with 1 million rows and 1000 columns. The size of a file was 18.18 GB, which is 36.36 GB combined. Files have random numbers from a Uniform distribution between 0 and 100.
Two CSV files with random data. Photo made by the author
import pandas as pd import numpy as npfrom os import pathn_rows = 1_000_000 n_cols = 1000for i in range(1, 3): filename = 'analysis_%d.csv' % i file_path = path.join('csv_files', filename) df = pd.DataFrame(np.random.uniform(0, 100, size=(n_rows, n_cols)), columns=['col%d' % i for i in range(n_cols)]) print('Saving', file_path) df.to_csv(file_path, index=False)df.head()
Head of a file. Photo made by the author
The experiment was run on a MacBook Pro with 32 GB of main memory — quite a beast. When testing the limits of a pandas Dataframe, I surprisingly found out that reaching a Memory Error on such a machine is quite a challenge!
macOS starts dumping data from the main memory to SSD when the memory is running near its capacity. The upper limit for pandas Dataframe was 100 GB of free disk space on the machine.
When your Mac needs memory it will push something that isn’t currently being used into a swapfile for temporary storage. When it needs access again, it will read the data from the swap file and back into memory.
I’ve spent some time thinking about how should I address this issue so that the experiment would be fair. The first idea that came to my mind was to disable swapping so that each library would have only the main memory available — good luck with that on macOS. After spending a few hours I wasn’t able to disable swapping.
The second idea was to use a brute force approach. I’ve filled the SSD to its full capacity so that the operating system couldn’t use swap as there was no free space left on the device.
Your disk is almost full notification during the experiment. Photo made by the author
This worked! pandas couldn’t read two 18 GB files and Jupyter Kernel crashed.
If I would perform this experiment again I would create a virtual machine with less memory. That way it would be easier to show the limits of these tools.
Can Dask or Vaex help us and process these large files? Which one is faster? Let’s find out.
When designing the experiment, I thought about basic operations when performing Data Analysis, like grouping, filtering and visualizing data. I came up with the following operations:
calculating 10th quantile of a column,
adding a new column,
filtering by column,
grouping by column and aggregating,
visualizing a column.
All of the above operations perform a calculation using a single column, eg:
# filtering with a single column df[df.col2 > 10]
So I was intrigued to try an operation, which requires all data to be processed:
calculate the sum of all of the columns.
This can be achieved by breaking down the calculation to smaller chunks. Eg. reading each column separately and calculating the sum and in the last step calculating the overall sum. These types of computational problems are known as Embarrassingly parallel — no effort is required to separate the problem into separate tasks.
Let’s start with Vaex. The experiment was designed in a way that follows best practices for each tool — this is using binary format HDF5 for Vaex. So we need to convert CSV files to HDF5 format (The Hierarchical Data Format version 5).
import glob import vaexcsv_files = glob.glob('csv_files/*.csv')for i, csv_file in enumerate(csv_files, 1): for j, dv in enumerate(vaex.from_csv(csv_file, chunk_size=5_000_000), 1): print('Exporting %d %s to hdf5 part %d' % (i, csv_file, j)) dv.export_hdf5(f'hdf5_files/analysis_{i:02}_{j:02}.hdf5')
Vaex needed 405 seconds to covert two CSV files (36.36 GB) to two HDF5 files, which have 16 GB combined. Conversion from text to binary format reduced the file size.
Open HDF5 dataset with Vaex:
dv = vaex.open('hdf5_files/*.hdf5')
Vaex needed 1218 seconds to read the HDF5 files. I expected it to be faster as Vaex claims near-instant opening of files in binary format.
Opening such data is instantenous regardless of the file size on disk: Vaex will just memory-map the data instead of reading it in memory. This is the optimal way of working with large datasets that are larger than available RAM.
Display head with Vaex:
dv.head()
Vaex needed 1189 seconds to display head. I am not sure why displaying the first 5 rows of each column took so long.
Calculate 10th quantile with Vaex:
Note, Vaex has percentile_approx function which calculates an approximation of quantile.
quantile = dv.percentile_approx('col1', 10)
Vaex needed 0 seconds to calculate the approximation of the 10th quantile for the col1 column.
Vaex has a concept of virtual columns, which stores an expression as a column. It does not take up any memory and is computed on the fly when needed. A virtual column is treated just like a normal column. As expected Vaex needed 0 seconds to execute the command above.
Filter data with Vaex:
Vaex has a concept of selections, which I didn’t use as Dask doesn’t support selections, which would make the experiment unfair. The filter below is similar to filtering with pandas, except that Vaex does not copy the data.
dv = dv[dv.col2 > 10]
Vaex needed 0 seconds to execute the filter above.
Grouping and aggregating data with Vaex:
The command below is slightly different from pandas as it combines grouping and aggregation. The command groups the data by col1_binary and calculate the mean for col3:
Calculating mean with Vaex. Photo made by the author
Vaex needed 0 seconds to execute the command above.
Visualize the histogram:
Visualization with bigger datasets is problematic as traditional tools for data analysis are not optimized to handle them. Let’s try if we can make a histogram of col3 with Vaex.
Now, let’s repeat the operations above but with Dask. The Jupyter Kernel was restarted before running Dask commands.
Instead of reading CSV files directly with Dask’s read_csv function, we convert the CSV files to HDF5 to make the experiment fair.
import dask.dataframe as ddds = dd.read_csv('csv_files/*.csv') ds.to_hdf('hdf5_files_dask/analysis_01_01.hdf5', key='table')
Dask needed 763 seconds for conversion. Let me know in the comments if there is a faster way to convert the data with Dask. I tried to read the HDF5 files that were converted with Vaex with no luck.
Vaex requires conversion of CSV to HDF5 format, which doesn’t bother me as you can go to lunch, come back and the data will be converted. I also understand that in harsh conditions (like in the experiment) with little or no main memory reading data will take longer.
What I don’t understand is the time that Vaex needed to display the head of the file (1189 seconds for the first 5 rows!). Other operations in Vaex are heavily optimized, which enables us to do interactive data analysis on bigger than main memory datasets.
I kinda expected the problems with Dask as it is more optimized for compute clusters instead of a single machine. Dask is built on top of pandas, which means that operations that are slow in pandas, stay slow in Dask.
The winner of the experiment is clear. Vaex was able to process bigger than the main memory file on a laptop while Dask couldn’t. This experiment is specific as I am testing performance on a single machine, not a compute cluster.
Some of the links above are affiliate links and if you go through them to make a purchase I’ll earn a commission. Keep in mind that I link courses because of their quality and not because of the commission I receive from your purchases.
Follow me on Twitter, where I regularly tweet about Data Science and Machine Learning.