
2021 년에도 여전히 Pandas를 사용하여 빅 데이터를 처리하고 있습니까?
Pandas는 빅 데이터를 잘 처리하지 못합니다.이 두 라이브러리는 그렇습니다!어느 것이 더 낫습니까?더 빨리?
나는최근에 빅 데이터를 처리하는 방법에 대한 두 개의 소개 기사를 작성했습니다.Dask과Vaex— 메모리 데이터 세트보다 큰 처리를위한 라이브러리.글을 쓰는 동안 내 마음에 질문이 떠올랐다.
이러한 라이브러리가 실제로 메모리 데이터 세트보다 더 큰 데이터를 처리 할 수 있습니까? 아니면 모두 판매 슬로건입니까?
이것은 나를 흥미롭게했다 Dask와 Vaex로 실용적인 실험을하고 메모리보다 큰 데이터 셋을 처리하려고합니다.데이터 세트가 너무 커서 팬더로 열 수도 없습니다.
빅 데이터 란 무엇을 의미합니까?
빅 데이터는 느슨하게 정의 된 용어입니다. Google의 조회수만큼 많은 정의가 있습니다.이 기사에서는이 용어를 사용하여 데이터를 처리하기 위해 특수 소프트웨어가 필요한 너무 큰 데이터 세트를 설명합니다.Big에서는 “단일 시스템의 주 메모리보다 더 크다”는 의미입니다.
Wikipedia의 정의 :
빅 데이터는 기존의 데이터 처리 응용 프로그램 소프트웨어로 처리하기에는 너무 크거나 복잡한 데이터 세트를 분석하거나, 체계적으로 정보를 추출하거나, 처리하는 방법을 다루는 분야입니다.
Dask와 Vaex는 무엇입니까?
Dask분석을위한 고급 병렬 처리를 제공하여 좋아하는 도구에 대한 대규모 성능을 지원합니다.여기에는 numpy, pandas 및 sklearn이 포함됩니다.오픈 소스이며 자유롭게 사용할 수 있습니다.기존 Python API 및 데이터 구조를 사용하여 Dask로 구동되는 등가물간에 쉽게 전환 할 수 있습니다.
VaexLazy Out-of-Core DataFrames (Pandas와 유사)를위한 고성능 Python 라이브러리로, 큰 테이블 형식 데이터 세트를 시각화하고 탐색합니다.초당 10 억 개 이상의 행에 대한 기본 통계를 계산할 수 있습니다.빅 데이터의 대화 형 탐색을 허용하는 여러 시각화를 지원합니다.
Dask 및 Vaex 데이터 프레임은 Pandas 데이터 프레임과 완전히 호환되지 않지만 가장 일반적인 “데이터 랭 글링”작업은 두 도구에서 모두 지원됩니다.Dask는 클러스터를 계산하기 위해 코드를 확장하는 데 더 중점을 두는 반면 Vaex는 단일 컴퓨터에서 대규모 데이터 세트로 작업하기가 더 쉽습니다.
Dask 및 Vaex에 대한 내 기사를 놓친 경우 :
실험
1 백만 개의 행과 1000 개의 열이있는 두 개의 CSV 파일을 생성했습니다.파일 크기는 18.18GB로 합쳐서 36.36GB입니다.파일에는 0과 100 사이의 균일 분포에서 난수가 있습니다.
팬더를 pd로 가져 오기
numpy를 np로 가져 오기OS 가져 오기 경로에서n_rows = 1_000_000
n_cols = 1000범위 (1, 3)에있는 i의 경우 :
파일 이름 = 'analysis_ % d.csv'% i
file_path = path.join ( 'csv_files', 파일 이름)
df = pd.DataFrame (np.random.uniform (0, 100, size = (n_rows, n_cols)), columns = [ 'col % d'% i for i in range (n_cols)])
print ( '저장', 파일 _ 경로)
df.to_csv (file_path, index = False)df.head ()

이 실험은 32GB의 메인 메모리를 갖춘 MacBook Pro에서 실행되었습니다.pandas Dataframe의 한계를 테스트 할 때 놀랍게도 그러한 컴퓨터에서 메모리 오류에 도달하는 것이 상당히 어렵다는 것을 알았습니다!
macOS는 메모리가 용량에 가까워지면 메인 메모리에서 SSD로 데이터를 덤프하기 시작합니다.Pandas Dataframe의 상한은 머신의 100GB 여유 디스크 공간이었습니다.
WMac에 메모리가 필요한 경우 현재 사용되지 않는 항목을 임시 저장을 위해 스왑 파일로 푸시합니다.다시 액세스해야 할 때 스왑 파일에서 데이터를 읽어 메모리에 다시 넣습니다.
실험이 공정 해지려면이 문제를 어떻게 해결해야할지 고민했습니다.내 마음에 떠오른 첫 번째 아이디어는 각 라이브러리가 주 메모리 만 사용할 수 있도록 스와핑을 비활성화하는 것이 었습니다. macOS에서 행운을 빕니다.몇 시간을 보낸 후 스와핑을 비활성화 할 수 없었습니다.
두 번째 아이디어는 무차별 대입 방식을 사용하는 것이 었습니다.기기에 여유 공간이 없어 운영 체제에서 스왑을 사용할 수 없도록 SSD를 전체 용량으로 채웠습니다.
이것은 효과가 있었다!Pandas는 두 개의 18GB 파일을 읽을 수 없었고 Jupyter Kernel이 다운되었습니다.
이 실험을 다시 수행하면 메모리가 더 적은 가상 머신을 만들 것입니다.이렇게하면 이러한 도구의 한계를 더 쉽게 보여줄 수 있습니다.
Dask 또는 Vaex가 이러한 대용량 파일을 처리하는 데 도움을 줄 수 있습니까?어느 것이 더 빠릅니까?알아 보자.
Vaex 대 Dask
실험을 설계 할 때 데이터 분석을 수행 할 때 데이터 그룹화, 필터링 및 시각화와 같은 기본 작업을 생각했습니다.다음 작업을 생각해 냈습니다.
- 열의 10 번째 분위수 계산,
- 새 열 추가,
- 열로 필터링,
- 열별로 그룹화 및 집계,
- 열 시각화.
위의 모든 작업은 단일 열을 사용하여 계산을 수행합니다. 예 :
# 단일 열로 필터링
df [df.col2 & gt;10]
그래서 모든 데이터를 처리해야하는 작업을 시도하고 싶었습니다.
- 모든 열의 합계를 계산합니다.
이것은 계산을 더 작은 청크로 분할하여 달성 할 수 있습니다.예 :각 열을 개별적으로 읽고 합계를 계산하고 마지막 단계에서 전체 합계를 계산합니다.이러한 유형의 계산 문제는 다음과 같이 알려져 있습니다.난처하게 평행— 문제를 별도의 작업으로 분리하기 위해 노력할 필요가 없습니다.
Vaex
Vaex부터 시작하겠습니다.실험은 각 도구에 대한 모범 사례를 따르는 방식으로 설계되었습니다. 이것은 Vaex 용 바이너리 형식 HDF5를 사용하는 것입니다.따라서 CSV 파일을 HDF5 형식 (The Hierarchical Data Format 버전 5)으로 변환해야합니다.
glob 가져 오기
수입 vaexcsv_files = glob.glob ( 'csv_files / *. csv')i의 경우 enumerate (csv_files, 1)의 csv_file :
j의 경우 enumerate (vaex.from_csv (csv_file, chunk_size = 5_000_000), 1)의 dv :
print ( '% d % s을 (를) hdf5 부분 % d'로 내보내는 중 '% (i, csv_file, j))
dv.export_hdf5 (f'hdf5_files / analysis_ {i : 02} _ {j : 02} .hdf5 ')
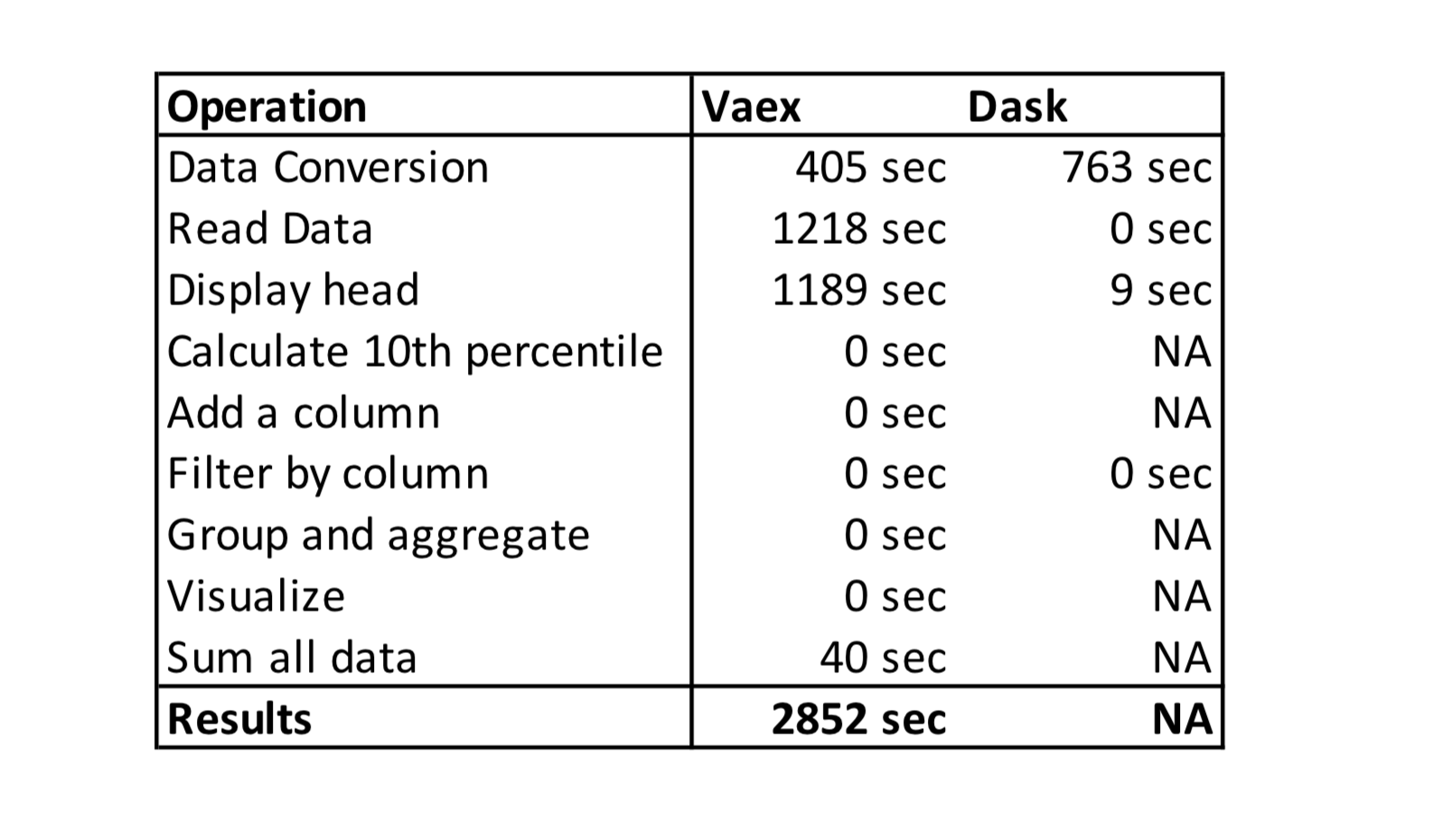
Vaex는 2 개의 CSV 파일 (36.36GB)을 16GB가 결합 된 2 개의 HDF5 파일로 변환하는 데 405 초가 필요했습니다.텍스트에서 이진 형식으로 변환하면 파일 크기가 줄어 들었습니다.
Vaex로 HDF5 데이터 세트 열기 :
dv = vaex.open('hdf5_files/*.hdf5')
Vaex는 HDF5 파일을 읽는 데 1218 초가 필요했습니다.Vaex가 바이너리 형식의 파일을 거의 즉시 열 수 있다고 주장하므로 더 빠를 것으로 예상했습니다.
이러한 데이터를 여는 것은 디스크의 파일 크기에 관계없이 즉시 이루어집니다. Vaex는 데이터를 메모리에서 읽는 대신 메모리 매핑 만합니다.이것은 사용 가능한 RAM보다 큰 대용량 데이터 세트로 작업하는 최적의 방법입니다.
Vaex가있는 디스플레이 헤드 :
dv.head()
Vaex는 머리를 표시하는 데 1189 초가 필요했습니다.각 열의 처음 5 개 행을 표시하는 데 왜 그렇게 오래 걸 렸는지 잘 모르겠습니다.
Vaex를 사용하여 10 번째 분위수 계산 :
Vaex에는 분위수의 근사치를 계산하는 percentile_approx 함수가 있습니다.
분위수 = dv.percentile_approx ( 'col1', 10)
Vaex는 col1 열에 대한 10 번째 분위수의 근사치를 계산하는 데 0 초가 필요했습니다.
Vaex로 새 열을 추가하십시오.
dv[‘col1_binary’] = dv.col1 > dv.percentile_approx(‘col1’, 10)
Vaex에는 식을 열로 저장하는 가상 열 개념이 있습니다.메모리를 차지하지 않으며 필요할 때 즉시 계산됩니다.가상 열은 일반 열처럼 처리됩니다.예상대로 Vaex는 위의 명령을 실행하는 데 0 초가 필요했습니다.
Vaex로 데이터 필터링 :
Vaex는선택, Dask는 선택을 지원하지 않아 실험이 불공평 해 지므로 사용하지 않았습니다.아래 필터는 Vaex가 데이터를 복사하지 않는다는 점을 제외하면 Pandas로 필터링하는 것과 유사합니다.
dv = dv [dv.col2 & gt;10]
Vaex는 위의 필터를 실행하는 데 0 초가 필요했습니다.
Vaex로 데이터 그룹화 및 집계 :
아래 명령은 그룹화 및 집계를 결합하므로 pandas와 약간 다릅니다.이 명령은 col1_binary로 데이터를 그룹화하고 col3의 평균을 계산합니다.
group_res = dv.groupby (by = dv.col1_binary, agg = { 'col3_mean': vaex.agg.mean ( 'col3')})

Vaex는 위의 명령을 실행하는 데 0 초가 필요했습니다.
히스토그램 시각화 :
더 큰 데이터 세트를 사용한 시각화는 기존의 데이터 분석 도구가이를 처리하도록 최적화되지 않았기 때문에 문제가됩니다.Vaex로 col3의 히스토그램을 만들 수 있는지 살펴 보겠습니다.
플롯 = dv.plot1d (dv.col3, what = 'count (*)', 제한 = [0, 100])

Vaex는 플롯을 표시하는 데 0 초가 필요했는데 놀랍도록 빨랐습니다.
모든 열의 합계 계산
한 번에 하나의 열을 처리 할 때 메모리는 문제가되지 않습니다.Vaex를 사용하여 데이터 세트에있는 모든 숫자의 합계를 계산해 보겠습니다.
suma = np.sum (dv.sum (dv.column_names))
Vaex는 모든 열의 합계를 계산하는 데 40 초가 필요했습니다.
Dask
이제 위의 작업을 반복하지만 Dask를 사용합니다.Dask 명령을 실행하기 전에 Jupyter 커널이 다시 시작되었습니다.
Dask의 read_csv 함수를 사용하여 CSV 파일을 직접 읽는 대신 CSV 파일을 HDF5로 변환하여 공정한 실험을 만듭니다.
dask.dataframe을 dd로 가져 오기ds = dd.read_csv ( 'csv_files / *. csv')
ds.to_hdf ( 'hdf5_files_dask / analysis_01_01.hdf5', key = 'table')
Dask는 변환에 763 초가 필요했습니다.Dask로 데이터를 변환하는 더 빠른 방법이 있으면 댓글로 알려주세요.운없이 Vaex로 변환 된 HDF5 파일을 읽으려고했습니다.
HDF5는 고성능이 필요한 Pandas 사용자에게 인기있는 선택입니다.Dask DataFrame 사용자는 대신 Parquet을 사용하여 데이터를 저장하고로드하는 것이 좋습니다.
Dask로 HDF5 데이터 세트 열기 :
import dask.dataframe as ddds = dd.read_csv('csv_files/*.csv')
Dask는 HDF5 파일을 여는 데 0 초가 필요했습니다.실제로 파일을 읽는 compute 명령을 명시 적으로 실행하지 않았기 때문입니다.
Dask가있는 디스플레이 헤드 :
ds.head()
Dask는 파일의 처음 5 개 행을 출력하는 데 9 초가 필요했습니다.
Dask를 사용하여 10 번째 분위수를 계산합니다.
Dask에는 근사치가 아닌 실제 분위수를 계산하는 분위수 함수가 있습니다.
Quantile = ds.col1.quantile (0.1) .compute ()
Dask는 Juptyter Kernel이 중단되어 분위수를 계산할 수 없었습니다.
Dask로 새 열을 정의합니다.
아래 함수는 분위수 함수를 사용하여 새 이진 열을 정의합니다.Dask는 분위수를 사용하기 때문에 계산할 수 없었습니다.
ds [ 'col1_binary'] = ds.col1 & gt;ds.col1.quantile (0.1)
Dask로 데이터 필터링 :
ds = ds[(ds.col2 > 10)]
위의 명령은 Dask가 지연된 실행 패러다임을 사용하므로 실행하는 데 0 초가 필요했습니다.
Dask로 데이터 그룹화 및 집계 :
group_res = ds.groupby('col1_binary').col3.mean().compute()
Dask는 데이터를 그룹화하고 집계 할 수 없었습니다.
col3의 히스토그램을 시각화합니다.
plot = ds.col3.compute().plot.hist(bins=64, ylim=(13900, 14400))
Dask는 데이터를 시각화 할 수 없었습니다.
모든 열의 합계를 계산합니다.
suma = ds.sum().sum().compute()
Dask는 모든 데이터를 합산 할 수 없었습니다.
결과
아래 표는 Vaex vs Dask 실험의 실행 시간을 보여줍니다.NA는 도구가 데이터를 처리 할 수없고 Jupyter Kernel이 다운되었음을 의미합니다.
결론
Vaex는 CSV를 HDF5 형식으로 변환해야하는데, 점심에 가서 돌아 오면 데이터가 변환 될 수 있기 때문에 신경 쓰지 않습니다.또한 주 메모리가 거의 또는 전혀없는 열악한 조건 (실험과 같이)에서는 데이터를 읽는 데 더 오래 걸릴 것임을 이해합니다.
내가 이해하지 못하는 것은 Vaex가 파일의 헤드를 표시하는 데 필요한 시간입니다 (처음 5 개 행에 대해 1189 초!).Vaex의 다른 작업은 크게 최적화되어 주 메모리 데이터 세트보다 더 큰 데이터를 대화식으로 분석 할 수 있습니다.
Dask는 단일 머신 대신 컴퓨팅 클러스터에 더 최적화되어 있기 때문에 다소 문제가있을 것으로 예상했습니다.Dask는 pandas 위에 구축되어 있습니다. 즉, pandas에서 느린 작업은 Dask에서 느리게 유지됩니다.
실험의 승자는 분명합니다.Vaex는 노트북의 메인 메모리 파일보다 더 큰 파일을 처리 할 수 있었지만 Dask는 처리 할 수 없었습니다.이 실험은 컴퓨팅 클러스터가 아닌 단일 머신에서 성능을 테스트하기 때문에 구체적입니다.
가기 전에
-교육 분야의 AI [동영상]-데이터 과학자를위한 무료 기술 테스트 & amp;기계 학습 엔지니어-비즈니스 리더를위한 데이터 과학[강좌]-PyTorch를 사용한 기계 학습 소개[강좌]-성장 제품 관리자되기[강좌]-대화 형 AI 및 분석을위한 라벨링 및 데이터 엔지니어링
위의 링크 중 일부는 제휴 링크이며 구매를 위해 통과하면 수수료를 받게됩니다.내가 코스를 링크하는 이유는 구매에 대한 수수료 때문이 아니라 품질 때문이라는 점을 명심하십시오.
나를 따라와트위터, 내가 정기적으로트위터데이터 과학 및 기계 학습에 대해.