
2021년 1월 23일 모바일 게임 매출 순위
| Rank | Game | Publisher |
|---|---|---|
| 1 | 리니지2M | NCSOFT |
| 2 | 리니지M | NCSOFT |
| 3 | 기적의 검 | 4399 KOREA |
| 4 | 세븐나이츠2 | Netmarble |
| 5 | 메이플스토리M | NEXON Company |
| 6 | Genshin Impact | miHoYo Limited |
| 7 | 라이즈 오브 킹덤즈 | LilithGames |
| 8 | V4 | NEXON Company |
| 9 | 뮤 아크엔젤 | Webzen Inc. |
| 10 | 블레이드&소울 레볼루션 | Netmarble |
| 11 | S.O.S:스테이트 오브 서바이벌 | KingsGroup Holdings |
| 12 | 바람의나라: 연 | NEXON Company |
| 13 | PUBG MOBILE | KRAFTON, Inc. |
| 14 | KartRider Rush+ | NEXON Company |
| 15 | R2M | Webzen Inc. |
| 16 | 미르4 | Wemade Co., Ltd |
| 17 | 리니지2 레볼루션 | Netmarble |
| 18 | 찐삼국 | ICEBIRD GAMES |
| 19 | 라그나로크 오리진 | GRAVITY Co., Ltd. |
| 20 | Cookie Run: Kingdom | Devsisters Corporation |
| 21 | Lords Mobile: Kingdom Wars | IGG.COM |
| 22 | A3: 스틸얼라이브 | Netmarble |
| 23 | 블리치: 만해의 길 | DAMO NETWORK LIMITED |
| 24 | Roblox | Roblox Corporation |
| 25 | Empires & Puzzles: Epic Match 3 | Small Giant Games |
| 26 | 명일방주 | Yostar Limited. |
| 27 | 그랑삼국 | YOUZU(SINGAPORE)PTE.LTD. |
| 28 | AFK 아레나 | LilithGames |
| 29 | FIFA ONLINE 4 M by EA SPORTS™ | NEXON Company |
| 30 | Pokémon GO | Niantic, Inc. |
| 31 | Epic Seven | Smilegate Megaport |
| 32 | Age of Z Origins | Camel Games Limited |
| 33 | 가디언 테일즈 | Kakao Games Corp. |
| 34 | Pmang Poker : Casino Royal | NEOWIZ corp |
| 35 | Cookie Run: OvenBreak – Endless Running Platformer | Devsisters Corporation |
| 36 | 검은사막 모바일 | PEARL ABYSS |
| 37 | Gardenscapes | Playrix |
| 38 | 한게임 포커 | NHN BIGFOOT |
| 39 | Brawl Stars | Supercell |
| 40 | Top War: Battle Game | Topwar Studio |
| 41 | Homescapes | Playrix |
| 42 | 아일랜드M | Gamepub |
| 43 | 컴투스프로야구2021 | Com2uS |
| 44 | FIFA Mobile | NEXON Company |
| 45 | Random Dice: PvP Defense | 111% |
| 46 | 랑그릿사 | ZlongGames |
| 47 | 카이로스 : 어둠을 밝히는 자 | Longtu Korea Inc. |
| 48 | 황제라 칭하라 | Clicktouch Co., Ltd. |
| 49 | Summoners War | Com2uS |
| 50 | Rise of Empires: Ice and Fire | Long Tech Network Limited |
A Zero-Maths Introduction to Bayesian Statistics -번역
베이지안 통계에 대한 제로 수학 소개
통계 세계의 십자군 해독 — 베이지안 대 빈도주의
이것은 많은 소개가 필요하지 않습니다.수천 개의 기사, 논문이 작성되었으며 베이지안 대 빈도주의에 대한 몇 가지 전쟁이 벌어졌습니다.내 경험상 대부분의 사람들은 일반적인 선형 회귀로 시작하여 더 복잡한 모델을 구축하기 위해 노력하고 소수만이 신성한 Bayes 풀에 발을 담그고 주제의 간결함과 함께 이러한 기회가 부족하여 구멍을 뚫습니다.이해에서 적어도 나에게는 그랬다.
나는되고 싶지 않다 너무 많은 수학적 방정식으로 인해 어려움을 겪고 베이지안 통계의 내용, 이유 및 위치를 직관적으로 이해하고자합니다.이것은 저의 겸손한 시도입니다.
베이지안 프로세스에 대한 직관 구축
베이지안 분석에 대한 직관을 구축해 보겠습니다.나는 한 번 또는 다른 당신이 Frequentism과 Bayesian 사이의 논쟁에 빠졌을 것이라고 믿습니다.통계적 추론의 두 가지 접근 방식의 차이점을 설명 할 수있는 많은 문헌이 있습니다.
요컨대빈도주의변수의 유의성을 측정하기 위해 p- 값을 사용하여 데이터에서 학습하는 일반적인 접근 방식입니다.빈도주의 접근법은 포인트 추정에 관한 것입니다.내 선형 방정식이 다음과 같으면
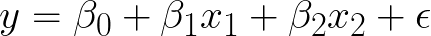
y는 반응 변수, x₁, x₂는 종속 변수입니다.β₁ 및 β₂는 추정해야하는 계수입니다.β₀은 절편 항입니다.x₁이 1 단위 씩 변하면 y는 β₁ 단위의 영향을받습니다.x₁이 1이고 β₁이 2이면 y는 2 단위의 영향을받습니다.일반적인 선형 물건.여기서 주목해야 할 점은 회귀 방정식이 다양한 β의 값을 추정한다는 것입니다.이 값은 제곱 오차 (최적 적합 선)의 합을 최소화하여 현재 데이터를 가장 잘 설명하며 추정 된 값은 단일 점입니다.β₀에 대한 값, β₁에 대한 값, β₂에 대한 값 등.β의 추정값은최대 가능성 추정입력 값 x와 출력값 y를 고려할 때 가장 가능성이 높은 값이기 때문입니다.
베이지안 데이터와는 별도로 데이터에 대한 사전 지식을 고려한다는 점에서 빈도주의 접근 방식과 다릅니다.여기에서 두 그룹 사이에 쇠고기가 놓여 있습니다.빈도 주의자들은 데이터를 복음으로 받아들이는 반면 베이지안 사람들은 우리가 시스템에 대해 항상 알고있는 것이 있고 매개 변수 추정에 그것을 사용하지 않는 이유가 있다고 생각합니다.
사전 지식과 함께 데이터는 사후라고 알려진 것을 추정하기 위해 함께 취해지며 단일 값이 아니라 분포입니다.베이지안 방법은 빈도주의 접근법의 경우와 같이 단일 최상의 값이 아닌 모델 매개 변수의 사후 분포를 추정합니다.
모델 매개 변수에 대해 선택한 사전은 단일 값이 아니지만 분포이기도합니다. 정규, 코시, 이항, 베타 또는 추측에 따라 적합하다고 간주되는 다른 분포 일 수 있습니다.
베이 즈 정리의 토착어와 대본을 알고 계시길 바랍니다.
(베이 즈 정리를 이미 이해하고 있다면이 섹션을 건너 뛰어도됩니다.)
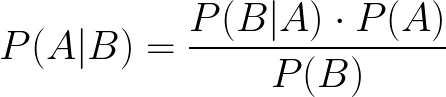
비록 그것은 매우 자명하지만 아주 기본적인 예의 도움으로 설명하겠습니다.
P (A | B)는 B가 이미 발생한 경우 A의 확률을 나타냅니다.예 :52 장의 카드 더미에서 무작위 카드를 가져옵니다.킹 GIVEN이 하트 카드를 뽑았을 확률은 얼마입니까??
A = 카드는 왕, B = 카드는 하트 스위트에서 가져온 것입니다.
P (A = 왕 | B = 하트)
P (A) = P (왕) = 4/52 = 1/13
P (B) = P (하트) = 13/52 = 1/4
P (B | A) = P (하트 | 킹) = 하트 카드를받을 확률 주어진 킹 = 1/4 (52 개 세트에는 4 개의 킹이 있으며 그중 하나의4 왕)
종합하면 P (A | B) = (1/4).(1/13) / (1/4) =1/13, 그래서 13 분의 1의 기회는 그것이 하트라면 왕을 얻을 수 있습니다.
저는이 간단한 예를 선택했습니다. 왜냐하면 베이 즈의 규칙을 풀 때 실제로 필요하지 않기 때문에 초보자도 직관적으로 생각할 수 있습니다.하트 카드라면 왕이 될 확률은 13 점 만점에 1 점입니다.
베이지안 접근 방식에는 사전 정보가 어떻게 포함됩니까?
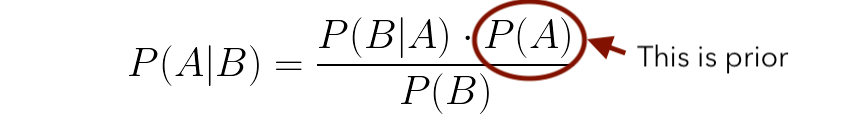
P (A)는 근사치 또는 데이터가있는 값입니다.위의 예에서 P (A)는 스위트에 관계없이 킹을 얻을 확률입니다.우리는 왕을 얻을 확률이 1/4이라는 것을 알고 있으므로 깨끗한 슬레이트로 시작하는 대신 시스템에 0.25의 값을 제공합니다.
그건 그렇고, Thomas Bayes는 Laplace가 한 위의 방정식을 생각해 내지 못했습니다.Bayes는“기회 교리의 문제 해결에 대한 에세이”그의 생각 실험에.Bayes가 사망 한 후 그의 친구 Richard Price가이 논문을 발견하고 몇 번의 판본을 읽은 후 런던 왕립 학회에서이 논문을 읽었습니다.
베이지안 추론의 경우 :
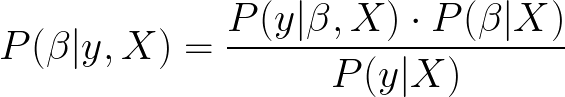
P (β | y, X)는 데이터 X와 y가 주어지면 모델 매개 변수 β의 사후 분포라고합니다. 여기서 X는 입력이고 y는 출력입니다.
P (y | β, X)는 데이터가 다음과 같이 곱해질 가능성입니다.사전 확률매개 변수의 P (β | X)를 정규화 상수라고하는 P (y | X)로 나눕니다.이 정규화 매개 변수는 P (β | y, X) 값의 합이 1이되도록하는 데 필요합니다.
간단히 말해서, 모델 매개 변수에 대한 이전 정보와 사후를 추정하기 위해 데이터를 사용하고 있습니다.
여기까지왔다면 등을 가볍게 두 드리십시오!:)
베이지안의 많은 사상가들은 Enigma의 해결책을 Alan Turing에 기인합니다.네, 그는 실제로 확률 모델을 만들었지 만 폴란드 수학자들이 그를 도왔습니다.전쟁이 있기 오래 전 폴란드의 수학자들은 영국인들이 여전히 언어 학적으로 그것을 풀려고 할 때 수학적 접근법을 사용하여 수수께끼를 풀었습니다.빗발마리안 레유 스키!
Moment of truth through an example
우리의 직관을 구축하기위한 몇 가지 간단한 예를 통해 위에서 배운 것을 이해할 수 있는지 봅시다.
동전을 20 번 던집니다. 1은 앞면, 0은 뒷면입니다.동전 던지기의 결과는 다음과 같습니다.
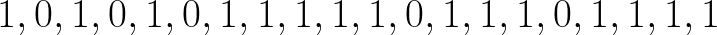
이 데이터의 평균은 0.75입니다.즉, 꼬리 (0)를 얻는 것보다 앞면 (1)을 얻을 확률이 75 %입니다.
그건 그렇고, 정규적으로 두 개의 결과 0 또는 1 만있는 모든 프로세스를베르누이 프로세스.
빈도 주의적 접근 방식을 취하면 동전이 편향된 것 같습니다.
하지만 대부분의 코인은 편향되지 않으며 1 또는 0을 얻을 확률은 50 % 여야합니다.중앙 극한 정리에 따르면 동전을 무한히 던졌다면 확률은 앞면과 뒷면 모두 0.5가 될 것입니다.실생활은 정리와는 상당히 다르며, 아무도 동전을 무한대로 던지지 않을 것입니다.우리가 사용할 수있는 데이터에 대해 결정을 내려야합니다.
바로 베이지안 접근 방식이 도움이됩니다.그것은 우리에게 사전 (우리의 초기 신념)을 포함 할 수있는 자유를 제공하며 이것이 우리가 동전 던지기 데이터에 할 일입니다.사전에 대한 정보가없는 경우 완전히 정보가없는 균일 분포를 사용할 수 있습니다. 실제로 균일 분포의 결과는 각 가능성이 동일 할 가능성이 있음을 모델에 알리기 때문에 빈도주의 접근 방식과 동일합니다.
Non-Bayesian (Frequentist) = 균일 사전이있는 베이지안
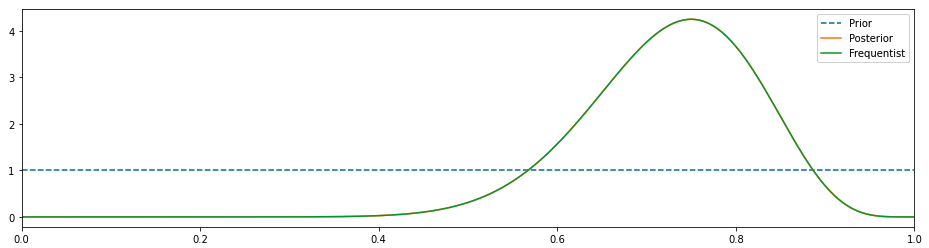
위의 차트에서 사후 및 빈도주의 결과는 일치하며 약 0.75에서 정점에 이릅니다 (빈도주의 접근 방식과 동일).Prior는 균등 분포를 가정했기 때문에 직선입니다.이 경우 녹색 분포는 실제로 가능성입니다.
나는 우리가 그것보다 더 잘할 수 있다고 믿습니다.더 많은 정보, 아마도 베타 배포판으로 이전을 변경하고 결과를 관찰합시다.
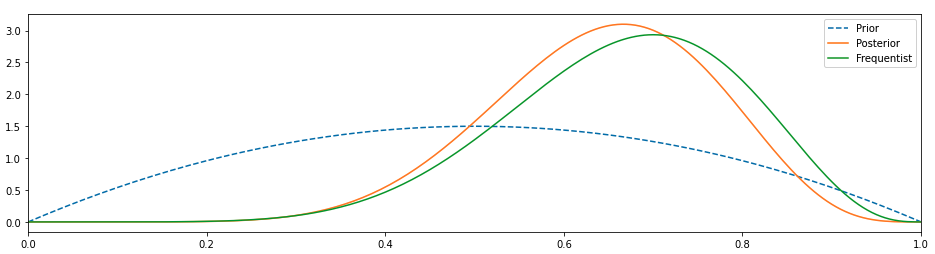
이것은 더 좋아 보인다.우리의 사전이 변경되었고 사후가 왼쪽으로 이동했기 때문에 0.5 값에 가깝지는 않지만 적어도 0.75에서 빈도 주의자와 일치하지는 않습니다.
우리는 이전 배포판의 몇 가지 매개 변수를 조정하여 더 많은 의견을 제시함으로써 더 개선 할 수 있습니다.
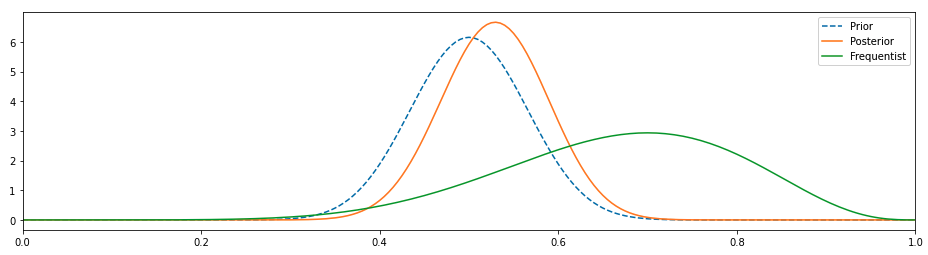
이것은 훨씬 더 좋아 보이며, 우리가 이전을 변경함에 따라 사후가 바뀌었고, 편향되지 않은 동전이 시간의 50 %를 차지하고 나머지 시간 동안 이야기를 할 것이라는 사실과 훨씬 더 일치합니다.
코인에 대한 우리의 기존 지식은 결과에 큰 영향을 미쳤으며 이는 의미가 있습니다.그것은 우리가 동전에 대해 아는 것이없고이 20 가지 관찰이 복음이라고 가정하는 빈도 주의적 접근과 정반대입니다.
Conclusion
따라서 데이터가 부족함에도 불구하고 베이지안을 통해 모델에 초기 신념을 포함했을 때 거의 올바른 결론에 도달 할 수 있었던 방법을 알 수 있습니다.Bayes의 규칙은 Bayesian 통계의 직관 뒤에 있으며 (이러한 명백한 진술) 빈도주의에 대한 대안을 제공합니다.
- 베이지안 접근 방식은 사전 정보를 통합하며 데이터가 제한적일 때 견고한 도구가 될 수 있습니다.
2. 접근 방식은 직관적 인 것 같습니다. 솔루션이 무엇인지 추정하고 더 많은 데이터를 수집할수록 해당 추정치를 개선합니다.
베이지안이 모든 데이터 과학 문제를 해결하기위한 최선의 접근 방식이라는 의미는 아닙니다.이는 접근 방식 중 하나 일 뿐이며 이러한 사고 학파 간의 십자군 전쟁에 맞서기보다는 베이지안과 빈도주의 방법을 모두 배우는 것이 유익 할 것입니다.
W큰 힘에는 큰 책임이 따른다.모든 것을 소금 한 알로 가져 가십시오.베이지안 방법의 명백한 이점이 있지만 고도로 편향된 결과를 생성하는 것이 훨씬 쉽습니다.전체 결과를 바꿀 수있는 사전을 선택할 수 있습니다.예를 들어, 제약 업계에서 안전하고 효과적인 약물을 연구하고 개발하는 데 수백만 달러를 투자하는 것보다 먼저 ‘올바른’것을 선택하는 것이 훨씬 쉽고 저렴합니다.수십억 달러에 달하는 경우 약탈적인 저널에 평범한 연구를 게시하고이를 이전 연구로 사용하는 것이 더 쉽습니다.
추가 읽기 :
Johnson, S. (2002).출현 : 개미, 뇌, 도시 및 소프트웨어의 연결된 삶.사이먼과 슈스터.
즐거운 독서 & amp;호기심을 가지세요!
A Zero-Maths Introduction to Bayesian Statistics
A Zero-Maths Introduction to Bayesian Statistics
Decoding the crusades of the statistics world — Bayesian vs Frequentism
This one doesn’t need much introduction. Thousands of articles, papers have been written and a few wars have been fought on Bayesian vs Frequentism. In my experience, most folks start with usual linear regression and work their way up to build more complex models and only a few get to dip their feet in the holy pool of Bayes and this lack of opportunity along with the terseness of the topic punches holes in the understanding, at least for me it did.
I don’t want to be bogged down by too many mathematical equations and want to have an intuitive understanding of what, why, and where of the Bayesian statistics. This is my humble attempt to do so.
Building intuition for Bayesian processes
Let’s build an intuition for Bayesian analysis. I believe one time or the other you might have been sucked in the debate between Frequentism vs Bayesian. There is a lot of literature out there that can explain the difference between the two approaches of statistical inference.
In short, Frequentism is the usual approach of learning from the data, using p-values to measure the significance of variables. The frequentist approach is about point estimates. If my linear equation is:
y is the response variable, x₁, x₂ are the dependent variables. β₁ and β₂ are the coefficients that need to be estimated. β₀ is the intercept term; If x₁ changes by 1 unit then y is affected by β₁ units e.g. if x₁ is 1 and β₁ is 2 then y will be affected by 2 units. Usual linear stuff. The thing to note here is that the regression equation estimates values of various β, that best explain the data at hand, based on minimising the sum of squared errors(line of best fit) and the estimated values are singular point i.e. there will be one value for β₀, one for β₁, and one for β₂, and so on. The estimated values of β are known as the maximum likelihood estimate of β because it is the value that is the most probable given the inputs, x, and output, y.
Bayesian differs from the frequentist approach in the fact that apart from the data, it takes the prior knowledge of the data into account. That’s where the beef lies between the two groups. Frequentists take data as the gospel while Bayesians think there is always something that we know about the system and why not use it in the estimation of the parameters.
The data along with the prior knowledge are taken together to estimate what’s known as the posterior and it is not a single value but a distribution. Bayesian methods estimate a posterior distribution of the model parameters, not a single best value as is the case in the frequentist approach.
The priors that we choose for the model parameters are not single values but they are distributions as well, they could be Normal, Cauchy, Binomial, Beta or any other distribution deemed fit according to our guess.
I hope you are aware of the vernacular and script of Bayes’ theorem
(Feel free to skip this section if you already understand Bayes’s Theorem)
Although, it is quite self-explanatory but let me just explain with the help of a very basic example.
P(A|B) refers to the probability of A given B has already happened. e.g. A random card is drawn from a deck of 52 cards, what is the probability that it is King GIVEN we drew a hearts card?
A = Card is King, B = Card is from Hearts suite.
P(A= King|B = Hearts)
P(A) = P(King) = 4/52 = 1/13
P(B) = P(Hearts) = 13/52 = 1/4
P(B|A) = P(Hearts| King) = Probability of getting a Hearts card GIVEN it is King = 1/4 (There are 4 kings in a set of 52 and you can select only one king of hearts out of those 4 kings)
Putting it all together, P(A|B) = (1/4). (1/13) / (1/4) = 1/13, so there are 1 in 13 chances to get a king given it is hearts.
I chose this simple example because it doesn’t really need Bayes’ rule to solve so even the beginners can think about it intuitively; Given it is a hearts’ card, the probability of getting a king is 1 out of 13.
How does the Bayesian approach include prior information?
P(A) is the value that we have approximated or what we have data on. In the above example, P(A) is the probability of getting a king irrespective of the suite. We know that the probability of getting a king is 1/4, so instead of starting with a clean slate, we are providing a value of 0.25 to the system.
By the way, Thomas Bayes didn’t come up with the above equation Laplace did. Bayes wrote a paper “An Essay towards solving a Problem in the Doctrine of Chances” on his thought experiments. After Bayes’ death, his friend Richard Price found the paper and after a few editions by him, the paper was read at the Royal Society of London.
For the Bayesian inference:
P(β|y, X) is the called the posterior distribution of the model parameters, β, given the data X and y, where X is input and y is output.
P(y|β, X) is the likelihood of the data which is multiplied by the prior probability of the parameters, P(β|X), and divided by P(y|X) which is known as a normalization constant. This normalisation parameter is required to make the sum of values in P(β|y, X) equals 1.
In nutshell, we are using our prior information about the model parameters and the data to estimate posterior.
Give yourself a pat on the back if you have made it this far! 🙂
A lot of Bayesian aligned thinkers attribute the solution of Enigma to Alan Turing. Well, yes, he did indeed build the probabilistic model but Polish Mathematicians helped him. Long before the war, Polish mathematicians had solved the enigma using Mathematical approach when Britishers were still trying to solve it linguistically. Hail Marian Rejewski!
Moment of truth through an example
Let’s see if we can understand what we learned above with some simple example to build our intuition.
Let’s toss a coin 20 times, 1 is heads and 0 is tails. Here are the outcomes of the coin throws:
The mean of this data is 0.75; in other words, there are 75% chances of getting heads i.e. 1 rather than getting a tail i.e. 0
By the way, any process that has canonically only two outcomes 0 or 1is referred to as Bernoulli process.
Taking a frequentist approach, it seems the coin is biased i.e. if we toss it one more time then according to frequentist estimates, it is more likely (75% of the times)that the coin will turn up heads i.e.1.
Although, most coins aren’t biased and the probability of getting a 1 or a 0 should be 50%. According to the central limit theorem, if we had tossed the coin infinite times then the probabilities would have lined up to be 0.5 for both head and tails. Real-life is quite different from theorems, no one is going to toss a coin infinite times; we have to make decisions on whatever data is available to us.
That’s where the Bayesian approach is helpful. It gives us the freedom to include the priors(our initial beliefs) and that’s what we will do to the coin flip data. If we don’t have any information about the priors then we can use a completely uninformative uniform distribution — in practice, the results of the uniform distribution will be same as the frequentist approach because we are telling our model that each possibility is equally likely.
Non-Bayesian(Frequentist) = Bayesian with a uniform prior
In the chart above, posterior and frequentist results coincide and it peaks at around 0.75( just like the frequentist approach). Prior is a straight line because we assumed that a uniform distribution. In this case, the green distribution is actually a likelihood.
I believe we can do better than that. Let’s change our prior to something more informed, maybe a beta distribution and observe the results.
This seems better. Our prior has changed and because of that the posterior has moved towards the left, it isn’t near the 0.5 value but it isn’t at least coincidental with the frequentist at 0.75.
We can improve it further by tweaking a few params of our prior distribution so that it becomes more opinionated.
This seems much better, the posterior has shifted as we have changed our prior and is much more in line with the fact that an unbiased coin will yield heads 50% of the time and tales rest of the time.
Our existing knowledge about the coin had a major impact on the results and that makes sense. It is the polar opposite to the frequentist approach in which we assume that we know NOTHING about the coin and these 20 observations are the gospel.
Conclusion
So you see how through Bayesian, despite having a paucity of data, we were able to reach the approximately right conclusion when we included our initial beliefs in the model. Bayes’ rule is behind the intuition of Bayesian statistics(such an obvious statement to make) and it provides an alternative to frequentism.
- The Bayesian approach incorporates prior information and that can be a solid tool when we have limited data.
2. The approach seems intuitive — estimate what your solution would be and improve that estimate as you gather more data.
Please understand that it doesn’t mean that Bayesian is the best approach for solving all data science problems; It is only one of the approaches and it would be fruitful to learn both Bayesian and Frequentist methods rather than fighting the crusades between these schools of thoughts.
With great power comes great responsibility. Take everything with a grain of salt. Although there are apparent advantages of Bayesian methods, it is much easier to produce highly biased results. One can choose a prior that can shift the entire results. As an example, it is much easier and cheaper to choose the ‘right’ prior than invest millions of dollars in research and development of safer and effective drugs in the pharmaceutical world. When billions of dollars are on the line, it’s easier to publish mediocre studies in predatory journals and use them as your prior.
Further reading:
Johnson, S. (2002). Emergence: The connected lives of ants, brains, cities, and software. Simon and Schuster.
Happy reading & stay curious!
2021년 1월 22일 모바일 게임 매출 순위
| Rank | Game | Publisher |
|---|---|---|
| 1 | 리니지2M | NCSOFT |
| 2 | 리니지M | NCSOFT |
| 3 | 세븐나이츠2 | Netmarble |
| 4 | 기적의 검 | 4399 KOREA |
| 5 | 메이플스토리M | NEXON Company |
| 6 | Genshin Impact | miHoYo Limited |
| 7 | 블레이드&소울 레볼루션 | Netmarble |
| 8 | R2M | Webzen Inc. |
| 9 | 라이즈 오브 킹덤즈 | LilithGames |
| 10 | V4 | NEXON Company |
| 11 | 뮤 아크엔젤 | Webzen Inc. |
| 12 | 바람의나라: 연 | NEXON Company |
| 13 | S.O.S:스테이트 오브 서바이벌 | KingsGroup Holdings |
| 14 | PUBG MOBILE | KRAFTON, Inc. |
| 15 | KartRider Rush+ | NEXON Company |
| 16 | 미르4 | Wemade Co., Ltd |
| 17 | 찐삼국 | ICEBIRD GAMES |
| 18 | 라그나로크 오리진 | GRAVITY Co., Ltd. |
| 19 | Lords Mobile: Kingdom Wars | IGG.COM |
| 20 | A3: 스틸얼라이브 | Netmarble |
| 21 | Roblox | Roblox Corporation |
| 22 | 리니지2 레볼루션 | Netmarble |
| 23 | 가디언 테일즈 | Kakao Games Corp. |
| 24 | 그랑삼국 | YOUZU(SINGAPORE)PTE.LTD. |
| 25 | AFK 아레나 | LilithGames |
| 26 | 블리치: 만해의 길 | DAMO NETWORK LIMITED |
| 27 | Empires & Puzzles: Epic Match 3 | Small Giant Games |
| 28 | FIFA ONLINE 4 M by EA SPORTS™ | NEXON Company |
| 29 | Age of Z Origins | Camel Games Limited |
| 30 | Pmang Poker : Casino Royal | NEOWIZ corp |
| 31 | Cookie Run: OvenBreak – Endless Running Platformer | Devsisters Corporation |
| 32 | 검은사막 모바일 | PEARL ABYSS |
| 33 | Pokémon GO | Niantic, Inc. |
| 34 | 한게임 포커 | NHN BIGFOOT |
| 35 | Gardenscapes | Playrix |
| 36 | 아일랜드M | Gamepub |
| 37 | Brawl Stars | Supercell |
| 38 | Top War: Battle Game | Topwar Studio |
| 39 | Epic Seven | Smilegate Megaport |
| 40 | Homescapes | Playrix |
| 41 | 명일방주 | Yostar Limited. |
| 42 | 컴투스프로야구2021 | Com2uS |
| 43 | Random Dice: PvP Defense | 111% |
| 44 | FIFA Mobile | NEXON Company |
| 45 | 사신키우기 온라인 : 경이로운 사신 ep1 | DAERISOFT |
| 46 | 황제라 칭하라 | Clicktouch Co., Ltd. |
| 47 | 카이로스 : 어둠을 밝히는 자 | Longtu Korea Inc. |
| 48 | 랑그릿사 | ZlongGames |
| 49 | Summoners War | Com2uS |
| 50 | Rise of Empires: Ice and Fire | Long Tech Network Limited |