
 hyungseok
hyungseok
2021년 4월 25일 모바일 게임 매출 순위
| Rank | Game | Publisher |
|---|---|---|
| 1 | 리니지2M | NCSOFT |
| 2 | 리니지M | NCSOFT |
| 3 | Cookie Run: Kingdom – Kingdom Builder & Battle RPG | Devsisters Corporation |
| 4 | 기적의 검 | 4399 KOREA |
| 5 | 세븐나이츠2 | Netmarble |
| 6 | 라이즈 오브 킹덤즈 | LilithGames |
| 7 | 데카론M | THUMBAGE |
| 8 | V4 | NEXON Company |
| 9 | 블레이드&소울 레볼루션 | Netmarble |
| 10 | 삼국지 전략판 | Qookka Games |
| 11 | 원펀맨: 최강의 남자 | GAMENOW TECHNOLOGY |
| 12 | 바람의나라: 연 | NEXON Company |
| 13 | R2M | Webzen Inc. |
| 14 | 그랑사가 | NPIXEL |
| 15 | 리니지2 레볼루션 | Netmarble |
| 16 | PUBG MOBILE | KRAFTON, Inc. |
| 17 | S.O.S: 스테이트 오브 서바이벌 x 더 워킹 데드 | KingsGroup Holdings |
| 18 | Roblox | Roblox Corporation |
| 19 | A3: 스틸얼라이브 | Netmarble |
| 20 | 뮤 아크엔젤 | Webzen Inc. |
| 21 | Brawl Stars | Supercell |
| 22 | DK모바일: 영웅의귀환 | NTRANCE Corp |
| 23 | 가디언 테일즈 | Kakao Games Corp. |
| 24 | 삼국지혼 | YOUZU(SINGAPORE)PTE.LTD. |
| 25 | Summoners War | Com2uS |
| 26 | 미르4 | Wemade Co., Ltd |
| 27 | FIFA Mobile | NEXON Company |
| 28 | Clash of Clans | Supercell |
| 29 | 이카루스 이터널 | LINE Games |
| 30 | 메이플스토리M | NEXON Company |
| 31 | Gardenscapes | Playrix |
| 32 | 컴투스프로야구2021 | Com2uS |
| 33 | 프로야구 H3 | NCSOFT |
| 34 | Genshin Impact | miHoYo Limited |
| 35 | Lords Mobile: Kingdom Wars | IGG.COM |
| 36 | FIFA ONLINE 4 M by EA SPORTS™ | NEXON Company |
| 37 | AFK 아레나 | LilithGames |
| 38 | 검은강호2: 이터널 소울 | 9SplayDeveloper |
| 39 | Empires & Puzzles: Epic Match 3 | Small Giant Games |
| 40 | Top War: Battle Game | Topwar Studio |
| 41 | Cookie Run: OvenBreak – Endless Running Platformer | Devsisters Corporation |
| 42 | Age of Z Origins | Camel Games Limited |
| 43 | Pmang Poker : Casino Royal | NEOWIZ corp |
| 44 | KartRider Rush+ | NEXON Company |
| 45 | Epic Seven | Smilegate Megaport |
| 46 | 한게임 포커 | NHN BIGFOOT |
| 47 | 갑부: 장사의 시대 | BLANCOZONE NETWORK KOREA |
| 48 | Homescapes | Playrix |
| 49 | Nonstop Game: Cyber Raid | SevenPirates |
| 50 | 검은사막 모바일 | PEARL ABYSS |
How to process a DataFrame with millions of rows in seconds -번역
수백만 행이 초 단위로 데이터 프레임을 처리하는 방법
그러나 당신이 알아야 할 데이터 분석을위한 또 다른 파이썬 라이브러리 – 그리고 아니, 나는 불꽃이나 마시에 대해 이야기하지 않습니다.
비파이썬의 IG 데이터 분석은 르네상스를 갖고 있습니다.그것은 모두이 기사에서 제시하고있는 도구 뒤에있는 빌딩 블록 중 하나 인 숫자 인 NUMPY로 시작되었습니다.
2006 년에 큰 데이터는 특히 Hadoop의 출시로 천천히 견인력을 얻은 주제였습니다.팬더는 데이터 프레임으로 곧 뒤를이었습니다.2014 년은 큰 자료가 주류가되었을 때의 해였으며, Apache Spark는 그 해에 해당되었습니다.2018 년에는 파이썬의 데이터 분석을 위해 Dask와 다른 라이브러리가있었습니다.
매월 나는 지느러미디내가 배우기를 열망하는 새로운 데이터 분석 도구.장기적으로 많은 시간을 절약 할 수 있으므로 시간 또는 2 시간을 보낼 수있는 가치있는 투자입니다.또한 최신 기술을 계속 연락하는 것도 중요합니다.
이 기사가 마스크에 관한 것이라고 기대하는 동안 당신은 잘못되었습니다.나는 당신이 알아야 할 데이터 분석을 위해 또 다른 파이썬 라이브러리를 발견했습니다.
파이썬처럼 SQL에 능숙 해지는 것이 똑같이 중요합니다.당신이 그것에 익숙하지 않은 경우, 당신은 여분의 돈이 있고,이 과정을 확인하십시오 :Master SQL, 빅 데이터 분석을위한 핵심 언어…에
파이썬의 큰 데이터 분석은 르네상스를 가지고 있습니다
다른 데이터 분석 도구에 대해 내 기사를 놓친 경우 :
VAEX를 만나십시오
VAEX는 게으른 핵심 데이터 프레임 (PandaS와 유사)을위한 고성능 Python 라이브러리로 큰 표 형식 데이터 집합을 시각화하고 탐색합니다.
초당 10 억 줄 이상의 행에 대한 기본 통계를 계산할 수 있습니다.큰 데이터의 대화식 탐색을 허용하는 여러 시각화를 지원합니다.
VAEX와 DASK의 차이점은 무엇입니까?
VAEX는 DASK와 유사하지 않지만 상단 팬더 데이터 프레임을 기반으로하는 DASK 데이터 프레임과 유사합니다.이것은 그 마술사를 의미합니다팬더 문제를 상속받습니다, 높은 메모리 사용량과 같습니다.이것은 VAEX의 경우가 아닙니다.
VAEX는 메인 메모리가 적은 시스템에서 더 큰 데이터 프레임을 처리 할 수 있도록 데이터 프레임을 복사하지 않습니다.
VAEX와 DASK는 모두 게으른 가공을 사용합니다.유일한 차이점은 VAEX가 필요할 때 필드를 계산하는 것입니다. Compute 함수를 명시 적으로 사용해야하는 Dask.
데이터는 HDF5 또는 Apache 화살표 형식이어야합니다. VAEX를 최대한 활용해야합니다.
VAEX를 설치하는 방법?
VAEX를 설치하려면 다른 Python 패키지를 설치하는 것만 큼 간단합니다.
PIP 설치 VAEX
Let’s take Vaex to a test drive
큰 데이터 파일을 만들려면 100 만 개의 행과 1000 개의 열이있는 팬더 데이터 프레임을 만들어 봅시다.
VAEX 가져 오기
PANDAS를 PD로 가져 오십시오
numpy를 np로 가져 오기n_rows = 1000000.
n_cols = 1000.
df = pd.dataFrame (np.random.randint (0, 100, size = (n_rows, n_cols)), columns = [ 'col % d'% i 범위 (n_cols)]df.head ()

이 데이터 프레임은 얼마나 많은 메모리를 사용합니까?
df.info (memory_usage = '깊이')

우리가 vaex로 나중에 읽을 수 있도록 디스크에 저장합시다.
file_path = 'big_file.csv'
df.to_csv (file_path, index = false)
우리는 속도가 팬더와 유사하므로 전체 CSV를 VAEX로 직접 읽는 것으로 많은 것을 얻지 못할 것입니다.둘 다 내 랩톱에서 약 85 초를 필요로합니다.
우리는 CSV를 HDF5 (계층 적 데이터 형식 버전 5)로 변환하여 VAEX의 이점을 확인해야합니다.VAEX에는 소규모 덩어리를 변환하여 주 메모리보다 큰 파일을 지원하는 변환 기능이 있습니다.
Pandas로 큰 파일을 열 수없는 경우 메모리 제약 조건으로 인해 HDF5로 덮어 VAEX로 처리 할 수 있습니다.
dv = vaex.from_csv (file_path, convert = true, chunk_size = 5_000_000)
이 함수는 HDF5 파일을 만들고 디스크에 지속됩니다.
DV의 데이터 유형은 무엇입니까?
유형 (DV)# 출력
vaex.hdf5.dataset.hdf5MemoryMapped.
이제 VAEX로 7.5GB 데이터 집합을 읽으려고합니다. 이미 DV 변수에 이미 있으므로 다시 읽을 필요가 없습니다.이것은 단지 속도를 테스트하는 것입니다.
dv = vaex.open ( 'big_file.csv.hdf5')
VAEX는 위의 명령을 실행하기 위해 1 초 미만이 필요했습니다.그러나 지연 로딩 때문에 VAEX가 실제로 파일을 읽지 않았습니다.
COL1의 합계를 계산하여 읽을 것을 강요합시다.
suma = dv.col1.sum ()
수마# 출력
# 배열 (49486599)
나는 이것을 정말로 놀랐다.VAEX는 합계를 계산하기 위해 1 초 미만이 필요했습니다.어떻게 가능합니까?
이러한 데이터를 열면 디스크의 파일 크기에 관계없이 순간적입니다.VaEx는 메모리에서 읽는 대신 데이터를 메모리 맵핑합니다.이것은 사용 가능한 RAM보다 큰 대형 데이터 세트를 사용하는 최적의 방법입니다.
플로팅
데이터를 플로팅 할 때 VAEX도 빠릅니다.특수 플로팅 기능 PLOT1D, PLOT2D 및 PLOT2D_CONTOUR가 있습니다.
dv.plot1d (dv.col2, figsize = (14, 7))
Virtual columns
VAEX는 새 열을 추가 할 때 가상 열을 만듭니다.
dv [ 'col1_plus_col2'] = dv.col1 + dv.col2
DV [ 'COL1_PLUS_COL2']]

Efficient filtering
VAEX는 훨씬 더 많은 메모리 효율 인 데이터를 필터링 할 때 데이터 프레임 복사본을 만들지 않습니다.
DVV = DV [dv.col1 & gt;90]
Aggregations
집계는 팬더보다 약간 다르게 작동하지만 더 중요한 것은 뻔뻔스럽게 빨리됩니다.
col1 ≥ 50 이진 가상 가상 열을 추가합시다.
DV [ 'COL1_50'] = DV.COL1 & gt; = 50
VAEX는 그룹별로 단일 명령으로 집계를 결합합니다.아래 명령은 “COL1_50″열에 의해 데이터를 그룹화하고 COL3 열의 합계를 계산합니다.
dv_group = dv.groupby (dv [ 'col1_50'], agg = vaex.agg.sum (dv [ 'col3']))
dv_group.

Joins
VAEX는 메모리 복사본을 저장하지 않고 데이터를 조인하여 주 메모리를 저장합니다.Pandas 사용자는 조인 기능에 익숙합니다.
dv_join = dv.join (dv_group, on = 'col1_50')
Conclusion
결국, 당신은 다음과 같이 묻습니다 : 우리는 팬더에서 VAEX로 전환해야합니까?대답은 큰 아니오입니다.
Pandas는 여전히 파이썬에서 데이터 분석을위한 최고의 도구입니다.가장 일반적인 데이터 분석 작업을위한 잘 지원되는 기능이 있습니다.
더 큰 파일에 관해서, 팬더는 가장 빠른 도구가 아닐 수도 있습니다.이것은 VAEX가 뛰어 내리는 훌륭한 장소입니다.
VAEX는 데이터 분석 도구 상자에 추가 해야하는 도구입니다.
팬더가 너무 느리거나 간단히 충돌하는 분석 작업에서 작업 할 때 VAEX를 도구 상자에서 가져오고 가장 중요한 항목을 필터링하고 팬더로 분석을 계속하십시오.
가기 전에
-SQL에서 날짜 시리즈를 만드는 방법[조]-데이터 과학자 및 amp에 대한 무료 기술 테스트;기계 학습 엔지니어-사이버 보안 (60 % OFF)에서 경력을 향상시킵니다 [코스]-Microsoft Azure [코스]를 사용하는 클라우드 개발자가 되십시오.-빅 데이터 분석의 핵심 언어 인 마스터 SQL [코스]
위의 링크 중 일부는 제휴 링크이며 구입을 위해 구입을 위해 그들을 통과하면위원회를 벌 수 있습니다.나는 당신의 구매로부터받는위원회로 인해 품질로 인해 과정을 링크한다는 것을 명심하십시오.
나를 따라 가라트위터, 내가 정기적으로 여기서트위터데이터 과학 및 기계 학습에 대해서.
How to process a DataFrame with millions of rows in seconds
How to process a DataFrame with millions of rows in seconds
Yet another Python library for Data Analysis that You Should Know About — and no, I am not talking about Spark or Dask
Big Data Analysis in Python is having its renaissance. It all started with NumPy, which is also one of the building blocks behind the tool I am presenting in this article.
In 2006, Big Data was a topic that was slowly gaining traction, especially with the release of Hadoop. Pandas followed soon after with its DataFrames. 2014 was the year when Big Data became mainstream, also Apache Spark was released that year. In 2018 came Dask and other libraries for data analytics in Python.
Each month I find a new Data Analytics tool, which I am eager to learn. It is a worthy investment of spending an hour or two on tutorials as it can save you a lot of time in the long run. It’s also important to keep in touch with the latest tech.
While you might expect that this article will be about Dask you are wrong. I found another Python library for data analysis that you should know about.
Like Python, it is equally important that you become proficient in SQL. In case you aren’t familiar with it, and you have some money to spare, check out this course: Master SQL, the core language for Big Data analysis.
Big Data Analysis in Python is having its renaissance
In case you’ve missed my article about another Data Analytics tool:
Meet Vaex
Vaex is a high-performance Python library for lazy Out-of-Core DataFrames (similar to Pandas), to visualize and explore big tabular datasets.
It can calculate basic statistics for more than a billion rows per second. It supports multiple visualizations allowing interactive exploration of big data.
What’s the difference between Vaex and Dask?
Vaex is not similar to Dask but is similar to Dask DataFrames, which are built on top pandas DataFrames. This means that Dask inherits pandas issues, like high memory usage. This is not the case Vaex.
Vaex doesn’t make DataFrame copies so it can process bigger DataFrame on machines with less main memory.
Both Vaex and Dask use lazy processing. The only difference is that Vaex calculates the field when needed, wherewith Dask we need to explicitly use the compute function.
Data needs to be in HDF5 or Apache Arrow format to take full advantage of Vaex.
How to install Vaex?
To install Vaex is as simple as installing any other Python package:
pip install vaex
Let’s take Vaex to a test drive
Let’s create a pandas DataFrame with 1 million rows and 1000 columns to create a big data file.
import vaex
import pandas as pd
import numpy as npn_rows = 1000000
n_cols = 1000
df = pd.DataFrame(np.random.randint(0, 100, size=(n_rows, n_cols)), columns=['col%d' % i for i in range(n_cols)])df.head()
How much main memory does this DataFrame use?
df.info(memory_usage='deep')
Let’s save it to disk so that we can read it later with Vaex.
file_path = 'big_file.csv'
df.to_csv(file_path, index=False)
We wouldn’t gain much by reading the whole CSV directly with Vaex as the speed would be similar to pandas. Both need approximately 85 seconds on my laptop.
We need to convert the CSV to HDF5 (the Hierarchical Data Format version 5) to see the benefit with Vaex. Vaex has a function for conversion, which even supports files bigger than the main memory by converting smaller chunks.
If you cannot open a big file with pandas, because of memory constraints, you can covert it to HDF5 and process it with Vaex.
dv = vaex.from_csv(file_path, convert=True, chunk_size=5_000_000)
This function creates an HDF5 file and persists it to disk.
What’s the datatype of dv?
type(dv)# output
vaex.hdf5.dataset.Hdf5MemoryMapped
Now, let’s read the 7.5 GB dataset with Vaex — We wouldn’t need to read it again as we already have it in dv variable. This is just to test the speed.
dv = vaex.open('big_file.csv.hdf5')
Vaex needed less than 1 second to execute the command above. But Vaex didn’t actually read the file, because of lazy loading, right?
Let’s force to read it by calculating a sum of col1.
suma = dv.col1.sum()
suma# Output
# array(49486599)
I was really surprised by this one. Vaex needed less than 1 second to calculate the sum. How is that possible?
Opening such data is instantaneous regardless of the file size on disk. Vaex will just memory-map the data instead of reading it in memory. This is the optimal way of working with large datasets that are larger than available RAM.
Plotting
Vaex is also fast when plotting data. It has special plotting functions plot1d, plot2d and plot2d_contour.
dv.plot1d(dv.col2, figsize=(14, 7))
Virtual columns
Vaex creates a virtual column when adding a new column, — a column that doesn’t take the main memory as it is computed on the fly.
dv['col1_plus_col2'] = dv.col1 + dv.col2
dv['col1_plus_col2']
Efficient filtering
Vaex won’t create DataFrame copies when filtering data, which is much more memory efficient.
dvv = dv[dv.col1 > 90]
Aggregations
Aggregations work slightly differently than in pandas, but more importantly, they are blazingly fast.
Let’s add a binary virtual column where col1 ≥ 50.
dv['col1_50'] = dv.col1 >= 50
Vaex combines group by and aggregation in a single command. The command below groups data by the “col1_50” column and calculates the sum of the col3 column.
dv_group = dv.groupby(dv['col1_50'], agg=vaex.agg.sum(dv['col3']))
dv_group
Joins
Vaex joins data without making memory copies, which saves the main memory. Pandas users will be familiar with the join function:
dv_join = dv.join(dv_group, on=’col1_50')
Conclusion
In the end, you might ask: Should we simply switch from pandas to Vaex? The answer is a big NO.
Pandas is still the best tool for data analysis in Python. It has well-supported functions for the most common data analysis tasks.
When it comes to bigger files, pandas might not be the fastest tool. This is a great place for Vaex to jump in.
Vaex is a tool you should add to your Data Analytics toolbox.
When working on an analysis task where pandas is too slow or simply crashes, pull Vaex out of your toolbox, filter out the most important entries and continue the analysis with pandas.
Before you go
- How To Create Date Series in SQL [Article]- Free skill tests for Data Scientists & Machine Learning Engineers- Advance your Career in Cybersecurity (60% off) [Course]- Become a Cloud Developer using Microsoft Azure [Course]- Master SQL, the core language for Big Data analysis [Course]
Some of the links above are affiliate links and if you go through them to make a purchase I’ll earn a commission. Keep in mind that I link courses because of their quality and not because of the commission I receive from your purchases.
Follow me on Twitter, where I regularly tweet about Data Science and Machine Learning.
2021년 4월 24일 모바일 게임 매출 순위
| Rank | Game | Publisher |
|---|---|---|
| 1 | 리니지2M | NCSOFT |
| 2 | 리니지M | NCSOFT |
| 3 | 기적의 검 | 4399 KOREA |
| 4 | Cookie Run: Kingdom – Kingdom Builder & Battle RPG | Devsisters Corporation |
| 5 | 세븐나이츠2 | Netmarble |
| 6 | 데카론M | THUMBAGE |
| 7 | 라이즈 오브 킹덤즈 | LilithGames |
| 8 | V4 | NEXON Company |
| 9 | 원펀맨: 최강의 남자 | GAMENOW TECHNOLOGY |
| 10 | 삼국지 전략판 | Qookka Games |
| 11 | R2M | Webzen Inc. |
| 12 | 바람의나라: 연 | NEXON Company |
| 13 | 리니지2 레볼루션 | Netmarble |
| 14 | 블레이드&소울 레볼루션 | Netmarble |
| 15 | 그랑사가 | NPIXEL |
| 16 | 뮤 아크엔젤 | Webzen Inc. |
| 17 | A3: 스틸얼라이브 | Netmarble |
| 18 | S.O.S: 스테이트 오브 서바이벌 x 더 워킹 데드 | KingsGroup Holdings |
| 19 | PUBG MOBILE | KRAFTON, Inc. |
| 20 | Roblox | Roblox Corporation |
| 21 | Brawl Stars | Supercell |
| 22 | DK모바일: 영웅의귀환 | NTRANCE Corp |
| 23 | 삼국지혼 | YOUZU(SINGAPORE)PTE.LTD. |
| 24 | FIFA Mobile | NEXON Company |
| 25 | Clash of Clans | Supercell |
| 26 | Summoners War | Com2uS |
| 27 | 미르4 | Wemade Co., Ltd |
| 28 | Epic Seven | Smilegate Megaport |
| 29 | FIFA ONLINE 4 M by EA SPORTS™ | NEXON Company |
| 30 | 메이플스토리M | NEXON Company |
| 31 | 프로야구 H3 | NCSOFT |
| 32 | 이카루스 이터널 | LINE Games |
| 33 | Gardenscapes | Playrix |
| 34 | 컴투스프로야구2021 | Com2uS |
| 35 | Genshin Impact | miHoYo Limited |
| 36 | Lords Mobile: Kingdom Wars | IGG.COM |
| 37 | Cookie Run: OvenBreak – Endless Running Platformer | Devsisters Corporation |
| 38 | 검은강호2: 이터널 소울 | 9SplayDeveloper |
| 39 | Top War: Battle Game | Topwar Studio |
| 40 | AFK 아레나 | LilithGames |
| 41 | Pmang Poker : Casino Royal | NEOWIZ corp |
| 42 | Age of Z Origins | Camel Games Limited |
| 43 | KartRider Rush+ | NEXON Company |
| 44 | 달빛조각사 | Kakao Games Corp. |
| 45 | Empires & Puzzles: Epic Match 3 | Small Giant Games |
| 46 | 한게임 포커 | NHN BIGFOOT |
| 47 | Homescapes | Playrix |
| 48 | 검은사막 모바일 | PEARL ABYSS |
| 49 | Gunship Battle Total Warfare | JOYCITY Corp. |
| 50 | Nonstop Game: Cyber Raid | SevenPirates |
Build and Run a Docker Container for your Machine Learning Model -번역
기계 학습 모델을위한 Docker 컨테이너 구축 및 실행
간단한 기계 학습 모델이있는 Docker 컨테이너의 빠르고 쉬운 빌드

이 기사의 아이디어는 간단한 기계 학습 모델을 사용하여 도커 컨테이너를 빠르고 쉽게 빌드하는 것입니다.이 기사를 읽기 전에 주저하지 말고 읽지 마십시오.왜 기계 학습을 위해 Docker를 사용하십시오과빠른 설치 및 먼저 Docker를 사용하십시오…에
기계 학습 모델을위한 Docker 컨테이너 구축을 시작하려면 세 가지 파일을 고려해 보겠습니다.DockerFile, Train.py, Inference.py.
모든 파일을 찾을 수 있습니다github.…에
그만큼train.py파이썬입니다 CSV 파일 (Train.csv)에서 EEG 데이터를 섭취하고 정규화하고 두 모델을 훈련시키는 스크립트 (Scikit-Learn 사용) 데이터를 분류합니다.스크립트는 선형 판별 분석 (CLF_LDA) 및 신경 네트워크 다층 PercePtron (CLF_NN)을 저장합니다.
그만큼inference.py이전에 생성 된 두 모델을로드하여 배치 추론을 수행하도록 호출됩니다.응용 프로그램은 CSV 파일 (test.csv)에서 오는 새로운 EEG 데이터를 정규화하고 데이터 집합에서 추론을 수행하고 분류 정확도와 예측을 인쇄합니다.
간단하게 만들어 봅시다DockerFile.와 더불어jupyter / scipy-notebook.이미지로서의 이미지로서의 이미지.우리는 설치해야합니다joblib.숙련 된 모델의 직렬화와 탈 수성을 허용합니다.우리는 train.csv, test.csv, train.py 및 inference.py 파일을 이미지에 복사합니다.그런 다음, 우리는 달리고 있습니다train.py기계 학습 모델에 맞는 이미지 빌드 프로세스의 일부로 기계 학습 모델을 적합하고 직렬화 할 것입니다. 프로세스 시작시 디버그 할 수있는 기능과 같은 몇 가지 장점을 제공하는 경우 도커 이미지 ID를 추적하거나 다른 버전을 사용할 수 있습니다.
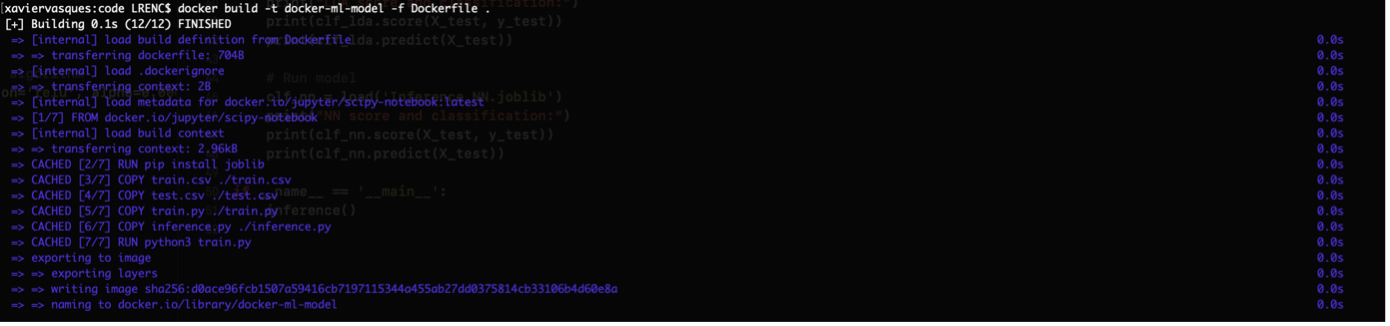
이미지를 빌드하려면 터미널에서 다음 명령을 실행합니다.
Docker Build -t Docker-ML 모델 -F Dockerfile.
출력은 다음과 같습니다.
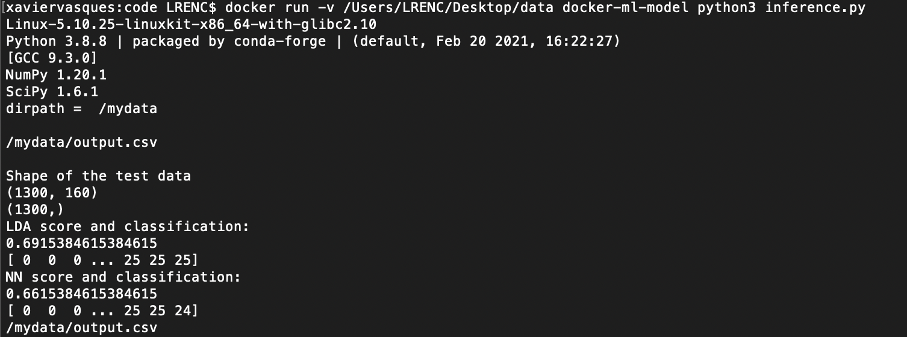
새 데이터 (test.csv)에서 추론을 수행 할 시간입니다.
Docker는 Docker-ML-Model Python3 Inference.py를 실행합니다
출력은 다음과 같습니다.

우리는 우리의 컨테이너 경험을 향상시킬 수있는 몇 가지 일을 할 수 있습니다.우리는 예를 들어 DockerFile에서 WorkDir을 사용하여 컨테이너의 호스트 디렉토리를 바인딩 할 수 있습니다.
에inference.py, 우리는 예를 들면 AN을 구하기로 결정할 수 있습니다Output.csv.파일과 함께 파일x_test.데이터의 데이터 :
당신이 그것을 빌드하고 그것을 실행하면 당신은 그것을 볼 수 있어야합니다.Output.csv.파일의 파일/ mydata.:
우리는 또한 추가 할 수 있습니다음량DockerFile의 명령으로 새 마운트 지점을 만드는 이미지가 생성됩니다.
우리가 지정한 이름으로,음량명령어는 우리가 처리하고자하는 데이터를 찾는 기본 호스트 또는 다른 컨테이너에서 외부 마운트 된 볼륨을 보유하는 것으로 태그가있는 마운트 포인트를 만듭니다.
개발의 미래를 위해 훈련 된 모델을 유지하기 위해 빌드 시간에 한 번만 환경 변수를 설정해야하며 특정 위치에 추가 데이터 또는 메타 데이터를 추가 할 수 있습니다.환경 변수 설정의 장점은 코드 전체에 필요한 경로의 하드 코드를 방지하고 합의 된 디렉토리 구조에서 다른 사람들과 작업을보다 잘 공유하는 것입니다.
새로운 DockerFile을 사용하여 다른 예제를 살펴 보겠습니다.
우리는 환경 변수를 추가해야합니다train.py:
과inference.py:
무엇 향후 계획 ?
목표는 간단한 기계 학습 모델로 Docker 컨테이너를 구축하기위한 빠르고 쉬운 단계를 생성하는 것이 었습니다.건물은 A를하는 것만 큼 간단합니다Docker Build -t My-Docker-Image.…에
이 단계에서 우리는 훨씬 더 간단 해지고 기계 학습 모델을 게시하고 확장하기 위해 두려움을 제거하는 모델의 배포를 시작할 수 있습니다.다음 단계는 Jenkins와 같은 CI / CD 공구 (연속 통합 / 연속 배송)가있는 워크 플로우를 생성하는 것입니다.이 접근 방식 덕분에 Docker Container를 구축하고 봉사하고 REST API를 노출하여 외부 이해 관계자가 소비 할 수 있도록 가능합니다.높은 계산 요구가 필요한 깊은 학습 모델을 교육하는 경우 컨테이너를 고성능 컴퓨팅 서버 또는 구내, 개인 또는 공용 클라우드와 같은 원하는 플랫폼으로 이동할 수 있습니다.이 아이디어는 모델을 확장 할 수 있지만 지역 / 가용성 영역에서 컨테이너를 확장 할 수 있으므로 탄력적 인 배포를 만듭니다.
나는 당신이 큰 단순함과 유연성 컨테이너가 제공하기를 바랍니다.기계 / 깊은 학습 응용 프로그램을 컨테이너로하여 세계에서 볼 수 있습니다.다음 단계는 클라우드에 배포하고 노출하는 것입니다.특정 시점에서는 Red Hat Openshift, kubernetes 배포와 같은 기술의 도움을 받아 수백만 명의 사용자에게 제공하도록 컨테이너를 조정, 모니터링 및 확장해야합니다.
소스
https://docs.docker.com/engine/reference/builder/
Build and Run a Docker Container for your Machine Learning Model
Build and Run a Docker Container for your Machine Learning Model
A quick and easy build of a Docker container with a simple machine learning model
The idea of this article is to do a quick and easy build of a Docker container with a simple machine learning model and run it. Before reading this article, do not hesitate to read Why use Docker for Machine Learning and Quick Install and First Use of Docker.
In order to start building a Docker container for a machine learning model, let’s consider three files: Dockerfile, train.py, inference.py.
You can find all files on GitHub.
The train.py is a python script that ingest and normalize EEG data in a csv file (train.csv) and train two models to classify the data (using scikit-learn). The script saves two models: Linear Discriminant Analysis (clf_lda) and Neural Networks multi-layer perceptron (clf_NN).
The inference.py will be called to perform batch inference by loading the two models that has been previously created. The application will normalize new EEG data coming from a csv file (test.csv), perform inference on the dataset and print the classification accuracy and predictions.
Let’s create a simple Dockerfile with the jupyter/scipy-notebook image as our base image. We need to install joblib to allow serialization and deserialization of our trained model. We copy the train.csv, test.csv, train.py and inference.py files into the image. Then, we run train.py which will fit and serialize the machine learning models as part of our image build process which provide several advantages such as the ability to debug at the beginning of the process, use Docker Image ID for keeping track or use different versions.
In order to build the image, we run the following command in our terminal:
docker build -t docker-ml-model -f Dockerfile .
The output is the following:
It’s time to perform the inference on new data (test.csv):
docker run docker-ml-model python3 inference.py
The output is the following:
We can do a few things that can improve our containerization experience. We can for example bind a host directory in the container using WORKDIR in the Dockerfile:
In inference.py, we can decide for example to save an output.csv file with the X_test data in it:
When you build it and run it you should be able to see the output.csv file in /mydata :
We can also add the VOLUME instruction in the Dockerfile resulting in an image that will create a new mount point:
With the name that we specify, the VOLUME instruction creates a mount point which is tagged as holding externally mounted volume from native host or other containers where we find the data we want to process.
For the future of your developments, it can be necessary to set environment variables from the beginning, just once at the build time, for persisting the trained model and maybe add additional data or metadata to a specific location. The advantage of setting environment variables is to avoid the hard code of the necessary paths all over your code and to better share your work with others on an agreed directory structure.
Let’s take another example, with a new Dockerfile:
We need to add the environment variables to train.py:
and inference.py:
What’s Next ?
The goal was to produce quick and easy steps to build a Docker container with a simple machine learning model. Building is as simple as doing a docker build -t my-docker-image ..
From this step, we can start the deployment of our models which will be much simpler and removing the fear to publish and scale your machine learning model. The next step is to produce a workflow with a CI/CD tool (Continuous Integration/Continuous Delivery) such as Jenkins. Thanks to this approach, it will be possible to build and serve anywhere a docker container and expose a REST API so that external stakeholders can consume it. If you are training a deep learning model that needs high computational needs, you can move your containers to high performance computing servers or any platform of your choice such as on premises, private or public cloud. The idea is that you can scale your model but also create resilient deployment as you can scale the container across regions/availability zones.
I hope you can see the great simplicity and flexibility containers provide. By containerizing your machine/deep learning application, you can make it visible to the world. The next step is to deploy it in the cloud and expose it. At certain points in time, you will need to orchestrate, monitor and scale your containers to serve millions of users with the help of technologies such as Red Hat OpenShift, a Kubernetes distribution.
Sources
https://docs.docker.com/engine/reference/builder/