
Pandas Groupby 기능을 최대한 활용하기위한 4 가지 팁
탐색 적 데이터 분석 프로세스 향상

Pandas는 매우 인기있는 데이터 분석 및 조작 라이브러리입니다.효율적인 데이터 분석을 수행 할 수있는 다양한 기능을 제공합니다.또한 구문이 간단하고 이해하기 쉽습니다.
이 기사에서는 Pandas의 특정 기능인 groupby에 초점을 맞 춥니 다.열의 범주 또는 고유 값을 기반으로 데이터 포인트 (즉, 행)를 그룹화하는 데 사용됩니다.그런 다음 통계를 계산하거나 그룹화 된 범주와 관련하여 숫자 열에 함수를 적용 할 수 있습니다.
예제를 살펴보면 프로세스가 명확해질 것입니다.라이브러리 가져 오기부터 시작하겠습니다.
numpy를 np로 가져 오기
팬더를 pd로 가져 오기
우리는엘따라서 예제에 대한 데이터 세트가 필요합니다.멜버른 주택의 작은 샘플을 사용합니다.데이터 세트Kaggle에서 사용할 수 있습니다.
df = pd.read_csv ( "/ content / melb_data.csv", usecols = [ 'Price', 'Landsize', 'Distance', 'Type', 'Regionname'])df = df [(df. 가격 & lt; 3_000_000) & amp;(df.Landsize & lt; 1200)]. sample (n = 1000) .reset_index (drop = True)df.head ()
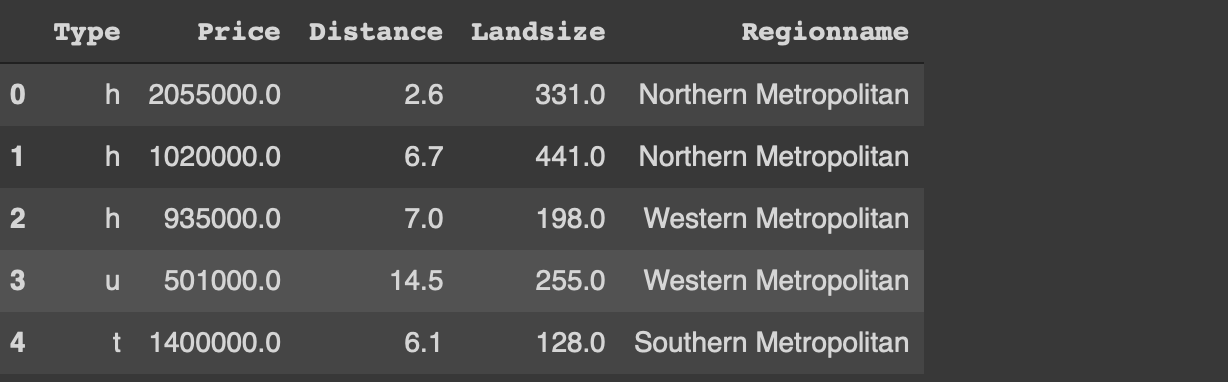
원본의 일부만 읽었습니다.데이터 세트.read_csv 함수의 usecols 매개 변수를 사용하면 csv 파일의 지정된 열만 읽을 수 있습니다.또한 가격 및 토지 크기와 관련하여 이상 값을 필터링했습니다.마지막으로 sample 함수를 사용하여 1000 개의 관측치 (즉, 행)의 무작위 표본을 선택합니다.
팁을 시작하기 전에 유형 열의 각 범주에 대한 평균 거리를 수행하는 간단한 groupby 함수를 구현해 보겠습니다.
df [[ 'Type', 'Distance']]. groupby ( 'Type'). mean ()

주택 (h)은 평균적으로 다른 두 유형보다 중앙 비즈니스 지구에서 더 멀리 떨어져 있습니다.
이제 groupby 기능을보다 효과적으로 사용하기위한 팁부터 시작할 수 있습니다.
1. 열 이름 사용자 지정
groupby 함수는 열 이름을 변경하거나 사용자 지정하지 않으므로 집계 된 값이 무엇을 나타내는 지 실제로 알 수 없습니다.예를 들어, 이전 예에서는 열 이름을 “distance”에서 “avg_distance”로 변경하는 것이 더 유익합니다.
이를 수행하는 한 가지 방법은 mean 함수 대신 agg 함수를 사용하는 것입니다.
df [[ 'Type', 'Distance']]. groupby ( 'Type'). agg (
avg_distance = ( '거리', '평균')
)

나중에 언제든지 열 이름을 변경할 수 있지만이 방법이 더 실용적입니다.
여러 열을 집계하거나 하나의 열에 다른 함수를 적용하는 경우 열 이름을 사용자 지정하는 것이 더 중요해집니다.agg 함수는 여러 집계를 허용합니다.열 이름과 함수를 지정하기 만하면됩니다.
예를 들어 다음과 같이 유형 열의 각 범주에 대한 평균 및 중앙 거리 값을 계산할 수 있습니다.
df [[ 'Type', 'Distance']]. groupby ( 'Type'). agg (
avg_distance = ( '거리', '평균'),
median_distance = ( 'Distance', 'median')
)

2. Lambda expressions
Lambda 표현식은 Python의 특수한 형태의 함수입니다.일반적으로 람다 표현식은 이름없이 사용되므로 일반 함수와 같이 def 키워드로 정의하지 않습니다.
람다 식의 주된 동기는 단순성과 실용성입니다.그들은 한 줄이며 일반적으로 한 번만 사용됩니다.
agg 함수는 람다 식을받습니다.따라서 groupby 함수와 함께 더 복잡한 계산 및 변환을 수행 할 수 있습니다.
예를 들어, 각 유형의 평균 가격을 계산하고 하나의 람다 표현식을 사용하여 수백만으로 변환 할 수 있습니다.
df [[ 'Type', 'Price']]. groupby ( 'Type'). agg (
avg_price_million = ( '가격', 람다 x : x.mean () / 1_000_000)
) .round (2)

3. As_index parameter
groupby 함수는 반환 된 데이터 프레임의 인덱스에 그룹을 할당합니다.중첩 된 그룹의 경우보기 좋지 않습니다.
df [[ '유형', '지역 이름', '거리']] \
.groupby ([ 'Type', 'Regionname']). mean (). head ()
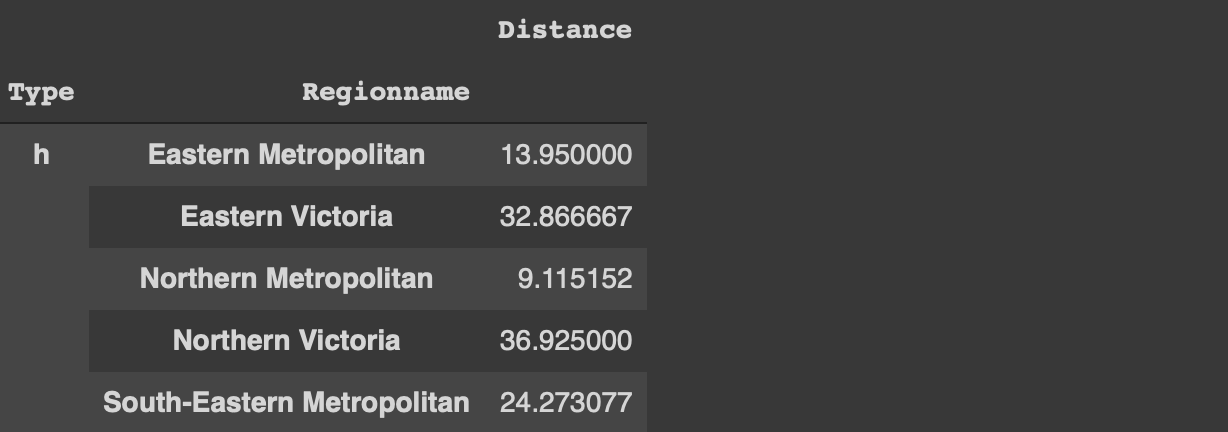
나중에이 데이터 프레임에 대한 분석을 수행하려는 경우 유형 및 지역 이름 열을 인덱스로 사용하는 것은 실용적이지 않습니다.우리는 항상 reset_index 함수를 사용할 수 있지만 더 최적의 방법이 있습니다.
groupby 함수의 as_index 매개 변수가 false로 설정된 경우 그룹화 된 열은 색인 대신 열로 표시됩니다.
df [[ '유형', '지역 이름', '거리']] \
.groupby ([ 'Type', 'Regionname'], as_index = False) .mean (). head ()
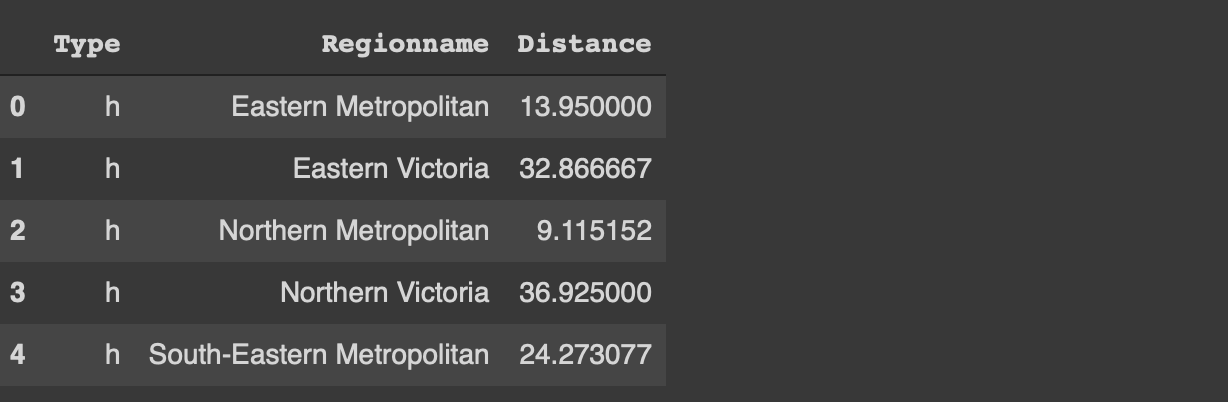
4. Missing values
groupby 함수는 기본적으로 누락 된 값을 무시합니다.먼저 유형 열의 일부 값을 누락 된 것으로 업데이트하겠습니다.
df.iloc [100 : 150, 0] = np.nan
iloc 함수는 인덱스를 사용하여 행-열 조합을 선택합니다.위의 코드는 첫 번째 열 (0 인덱스)의 100에서 150 사이의 행을 누락 된 값 (np.nan)으로 업데이트합니다.
유형 열의 각 범주에 대한 평균 거리를 계산하려고하면 누락 된 값에 대한 정보를 얻지 못합니다.
df [[ 'Type', 'Distance']]. groupby ( 'Type'). mean ()

어떤 경우에는 결 측값에 대한 개요도 얻어야합니다.그것은 우리가 그것들을 다루는 방법에 영향을 미칠 수 있습니다.groupby 함수의 dropna 매개 변수는 결 측값에 대한 집계도 계산하는 데 사용됩니다.
df [[ 'Type', 'Distance']]. groupby ( 'Type', dropna = False) .mean ()

Conclusion
groupby 함수는 탐색 적 데이터 분석 프로세스에서 가장 자주 사용되는 함수 중 하나입니다.변수 간의 관계에 대한 귀중한 통찰력을 제공합니다.
Pandas로 데이터 분석 프로세스를 강화하려면 groupby 함수를 효율적으로 사용하는 것이 중요합니다.이 기사에서 다룬 4 가지 팁은 groupby 기능을 최대한 활용하는 데 도움이 될 것입니다.
읽어 주셔서 감사합니다.의견이 있으면 알려주세요.