
8 Exciting Case Studies of Machine Learning Applications in Life Sciences and Biotechnology
An industry as thrilling and successful as the tech industry

COVID-19 made us focus and hope on the life sciences and biotechnology industry.
Health is our most precious asset, and we avoid no costs to stay healthy. So, the life sciences and biotechnology industry is gigantic and very diverse with many subsectors. The most known fields are drug discovery and manufacturing, therapeutics, diagnostics, therapeutics, genomics and proteomics, veterinary life sciences, but also cosmetics, medical technology, and distribution.
An enormous amount of data is inherent to this industry. Data are available from clinical trials, drugs, therapies, diagnostics, genomics, health care providers, and with the rise of all the wearables, all the personal fitness data.
Life sciences and biotechnology is in many fields a big data industry.
On the other hand, the costs for developing new therapies, drugs, or vaccines start from almost one billion U.S. dollars and two-digit billion U.S. dollars for rare diseases. For comparison, BioNTech and Moderna, each company received nearly $1 billion of external funding for the vaccine development. The total development costs are not public but are assumed a multiple of that.
These are tremendous sums of investments, and the industry makes all efforts to decrease the costs and expenses and make treatments and therapies faster available. So, the industry becomes as data-driven as the technology industry.
So, the life sciences and biotechnology industry is a paradise for data scientists. The players have large amounts of data, and a data scientist works daily in the big data area.
Many data scientists are not familiar with this industry. One entry barrier is the very specialized knowledge needed to understand the topics and work in the corresponding fields.
Second, causality and precision are of the highest importance and require a lot of deep mathematical and (bio)statistical background. If an algorithm leads to a wrong ad displayed to a user of the services of one of the large tech companies, nothing happens. If an algorithm leads to a wrong decision in drug development, it can lead to a massive loss on investment or even a dead person.
I worked for many years as a data science consultant in the life sciences and biotechnology industry. And I loved it because there I always had the most complex and exciting problems to solve.
To bring insights into this exciting industry, I present 8 real-world data science use cases. This gives you an impression of the applications and familiarizes you with essential business knowledge of that field.
There is a lack of data scientists in pharma, life sciences, and biotechnology. Eventually, I can motivate you to move into this exciting industry, with a salary level as high as the tech industry but even more recession-proof.
1. Development of microbiome therapeutics
We have a vast number of micro-organisms, so-called microbiota like bacteria, fungi, viruses, and other single-celled organisms in our body. All the genes of the microbiota are known as the microbiome. The number of these genes is trillions, and, e.g., the bacteria in the human body have more than 100 times more unique genes than humans.
The microbiota has a massive influence on human health, and imbalances are causing many disorders like Parkinson’s disease or inflammatory bowel disease. There is also the presumption that such imbalances cause several autoimmune diseases. So, microbiome research is a very trendy research area.
To influence the microbiota and develop microbiome therapeutics to reverse diseases, one needs to understand the microbiota’s genes and influence on our body. With all the gene sequencing possibilities today, terabytes of data are available but not yet probed.
To develop microbiome-targeted treatments and predict microbiome-drug interactions, one needs first to know such interdependencies. And this is where machine learning comes in.
The first step is to find patterns. One example is the imbalance of gut microbiota that causes motor neuron diseases, i.e., disorders that destroy cells for skeletal muscle activities, i.e., the muscles cannot be controlled anymore. Usually, more than 1000 people’s individual parameters are included. Supervised ML and reinforcement learning are the main algorithms in that step.
One must consider several hundreds of factors like dosage form, drug solubility, drug stability, and drug administration and manufacturing to design a therapy. E.g., random forest is often used in questions around drug stability.
The last step is the personalization of therapies. For that, one needs to predict the responses and interactions of the microbiome and the drug. Principle component analysis followed by supervised learning algorithms are standard techniques. The biggest challenge in this step is still the lack of large databases to train the models.
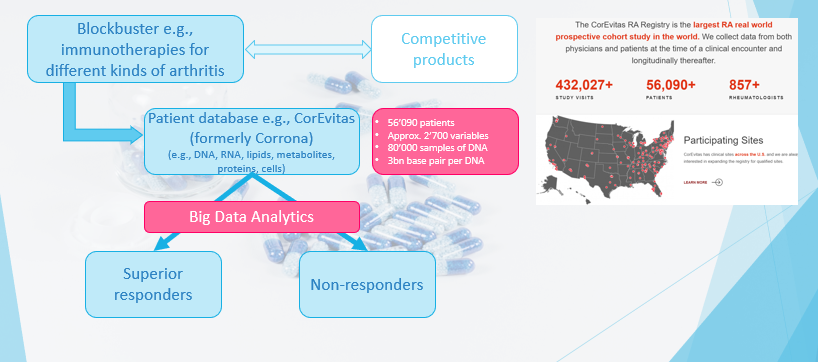
2. Precision medicine for a rheumatoid arthritis blockbuster
A blockbuster is a tremendously popular drug that generates at least annual revenues of more than $1 billion. Blockbusters address common diseases like diabetes, high blood pressure, common cancer types, or asthma. There are usually many competing products in the market.
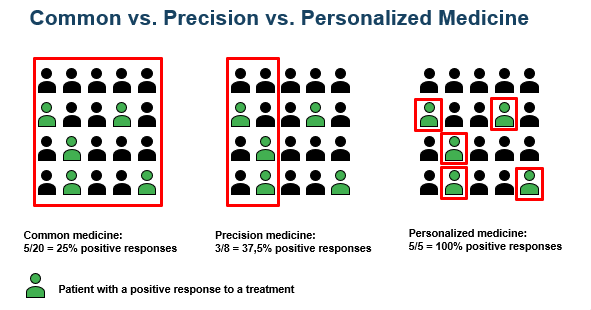
“Precision medicine” means that it is a treatment for groups of individuals who share certain characteristics that are responsive to that specific therapy (see graphic below).
For a better, i.e., a differentiation to other drugs, and for more specific targeting and marketing of the product, the patient groups that respond superior regarding its disease suppression are determined. The goal is the same as in every marketing analytics project. Data used are so-called real-world data (RWD), i.e., data of treated patients and not from clinical trials.
The main methods are supervised learning methods because we have a desired output value. Besides the common methods of regression / logistic regression, support vector machines, and random forest, today, with larger amounts of data, deep learning algorithms like convolutional neural networks (CNN) are applied. CNN often outperforms the other methods.
3. Predicting heart failure in mobile health
Heart failure typically leads to emergency or hospital admission. And with an aging population, the percentage of heart failure in the population is expected to increase.
People that suffer heart failure usually have pre-existing illnesses. So, it is not uncommon that telemedicine systems are used to monitor and consult a patient, and mobile health data like blood pressure, body weight, or heart rate are collected and transmitted.
Most prediction and prevention systems are based on fixed rules, e.g., when specific measurements are beyond a pre-defined threshold, the patient is alerted. It is self-explanatory that such a predictive system has a high number of false alerts, i.e., false positives.
Because an alert leads mostly to hospital admission, too many false alerts lead to increased health costs and deteriorate the patient’s confidence in the prediction. Eventually, she or he will stop following the recommendation for medical help.
So, based on baseline data of the patient like age, gender, smoker or not, pacemaker or not but also measurements of sodium, potassium or hemoglobin concentrations in the blood, and monitored characteristics like heart rate, body weight, (systolic and diastolic) blood pressure, or questionnaire answers about the well-being, or physical activities, a classifier based on Naïve Bayes has been finally developed.
The false alerts decreased by 73%, with an AUC (“area under the curve”) of about 70%.
4. Mental illness prediction, diagnosis, and treatment
It is estimated that at least 10% of the global population has a mental disorder. Economic losses caused by mental illness sum up to nearly $10 trillion. Mental disorders include, amongst others, anxiety, depression, substance use disorder, e.g., opioid, bipolar disorder, schizophrenia, or eating disorders.
So, the detection of mental disorders and intervention as early as possible is critical. There are two main approaches: apps for consumers that detect diseases and tools for psychiatrists to support diagnostics.
The apps for consumers are typically conversational chatbots enhanced with machine learning algorithms. The app analyzes the spoken language of the consumer, and recommendations for help are given. As the recommendations must be based on scientific evidence, the interaction and response of proposals and the individual language pattern must be predicted as accurately as possible.
The methods applied vary. The first step is almost always sentiment analysis. In simpler models, random forest and Naïve Bayes are used. These models are outperformed tremendously by neural networks with up to three hidden layers.
5. Research publication and database scanning for biomarkers of stroke
Stroke is one of the main reasons for disability and death. The lifetime risk of an adult person is about 25% of having once a stroke. But stroke is a very heterogeneous disorder. So, having individualized pre-stroke and post-stroke care is crucial for the success of a cure.
To determine this individualized care, the person’s phenotype, i.e., observable characteristics of a person should be chosen. And this is usually achieved by biomarkers. A so-called biomarker is a measurable data point such that the patients can be stratified. Examples are disease severity scores, lifestyle characteristics, or genomic properties.
There are many known biomarkers already published or in databases. Also, there are daily many hundreds of scientific publications about the detection of biomarkers for all the different diseases.
Research is enormously expensive and time-critical to prevent a disorder. So, biotech companies need to understand the most effective and efficient corresponding biomarkers for a particular disease. The amount of information is so gigantic that this cannot be done manually.
Data science helps in the development of sophisticated NLP algorithms to find relevant biomarkers in databases and publications. Besides understanding the content if such a biomarker is relevant for a particular type of stroke, a judgment of the published results’ quality must be achieved. This is a highly complex task overall.
6. 3D Bioprinting
Bioprinting is another hot topic in the biotechnology field. Based on a digital blueprint, the printer uses cells and natural or synthetic biomaterials — also called bioinks — to print layer-by-layer living tissues like skin, organs, blood vessels, or bones.
Instead of depending on organ donations, they can be produced in printers more ethically and cost-effectively. Also, drug tests are performed on the synthetic build tissue than with animal or human testing. The whole technology is still in early maturity due to its high complexity. One of the most essential parts to cope with this complexity of printing is data science.
The printing process and quality depend on numerous factors like the properties of the bioinks, which have inherent variabilities, or the various printing parameters. For example, to increase the success of getting usable output and thus, optimize the printing process, Bayesian optimization is applied.
The printing speed is a key component in the process. Siamese network models are deployed to determine the optimized speed. To detect material, i.e., tissue defects, convolutional neural networks are applied to images from the layer-by-layer tissue.
There are many more applications during the pre-production, production, and post-production process, but these three examples already show the complexity and advanced models needed. In my opinion, this field is one of the most exciting ones in biotechnology for data scientists.
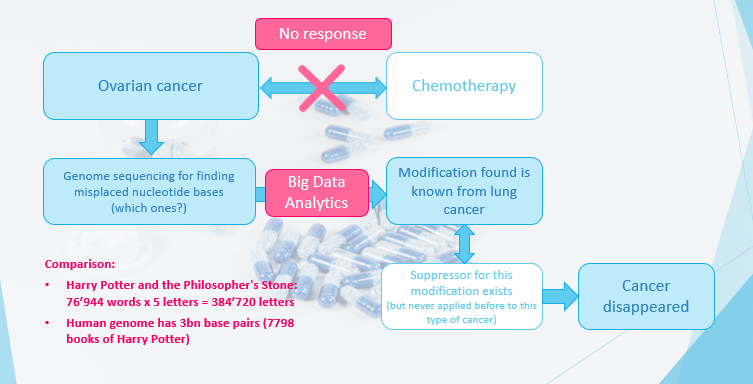
7. Personalized therapy in ovarian cancer treatment
“Personalized” means that a treatment matched with the needs of one single individual is applied (see graphic above). Medical treatments are more and more based on the individualized characteristics of a patient.
These properties are disease subtypes, personal patient risks, health prognosis, and molecular and behavioral biomarkers. We have seen above that a biomarker is any measurable data point such that the patients can be stratified. Based on that data, the best individualized treatment for a single patient is determined.
For one patient with ovarian cancer, the usual chemotherapy was not effective. So, one decided to perform genome sequencing to find the misplaced nucleotide bases that cause this cancer. With big data analytics, one found the modification amongst the 3 billion base pairs of a human, which corresponds to the number of words of 7798 books of Harry Potter’s “The Philosopher’s Stone.”
Methods applied are usually so-called covariance models, often combined with a classifier like random forest. Interestingly, this modification was known from lung cancer, where a drug exists but not from ovarian cancer. So, the treatment for lung cancer was applied, and the patient recovered.
8. Supply chain optimization
The production of drugs needs time, especially today’s high-tech cures based on specific substances and production methods. Also, the whole processes are broken down into many different steps, and several of them are outsourced to specialist providers.
We see this currently with the COVID-19 vaccine production. The vaccine inventors deliver the blueprint, and the production is in plants of companies specialized in sterile production. The vaccine is delivered in tanks to companies that do the filling in small doses under clinical conditions, and finally, another company makes the supply.
Further, drugs can be stored only for a limited time and often under special storage conditions, e.g., in a cold storage room.
The whole planning, from having the right input substances available at the right time, having the adequate production capacity, and finally, the proper amount of drugs stored for serving the demand, is a highly complex system. And this must be managed for hundreds and thousands of therapies, each with its specific conditions.
Computational methods are essential for managing this complexity. For example, the selection of the optimal partner companies in the production process is done by supervised learning like support vector machines.
Dynamic demand forecasting often relies on so-called support vector regression, and the production optimization itself deploy neural networks.
Conclusion
It is highly fascinating what modern technology and science can achieve today. It unfolds the most considerable value in combination with data science.
Method-wise, we see that supervised learning methods — random forest, Naïve Bayes, and support vector machines are often used, reinforcement learning, NLP, and deep learning are dominating.
Further, computational methods to cope with high dimensional data and search like principal component analysis and covariance models are needed.
Working on the frontier of innovation requires knowledge in particular topics like Bayesian optimization, convolutional neural networks, or Siamese networks.
The most significant entry barrier to this field is the topic-specific knowledge, thus understanding the (raw) data. The fastest path becoming familiar with is reading scientific publications and each expression that is not known, diligently to look up. When working in that field, you need to speak in the words of the experts.
Only then you can have an enormous impact as a data scientist. But this is also the most rewarding aspect.
I could never have more impact with my work than in the life sciences and biotechnology industry.
Do you like my story? Here you can find more.