Data Science Learning Roadmap for 2021
Building your own learning track to master the art of applying data science

Although nothing really changes except for the date, a new year fills everyone with the hope of starting things afresh. Adding a bit of planning, well-envisioned goals and a learning roadmap makes for a great recipe for a year full of growth.
This post intends to strengthen your plan by providing you with a learning framework, resources, and project ideas to build a solid portfolio of work showcasing expertise in data science.
Disclaimer:
The roadmap defined is prepared based on my little experience in data science. This is not the be-all and end-all learning plan. The roadmap may change to better suit any specific domain/field of study. Also, this is created keeping python in mind as I personally prefer to use python.
What is a learning roadmap?
In my humble opinion, a learning roadmap is an extension of a curriculum that charts out multi-level skills map with details on what skills you want to hone, how you will measure the outcome at each level, and techniques to further master each skill.
My roadmap assigns weights to each level based on the complexity and commonality of application in the real-world. I have also added an estimated time for a beginner to complete each level with exercises/projects.
Here is a pyramid that depicts the high-level skills in order of their complexity and application in the industry.
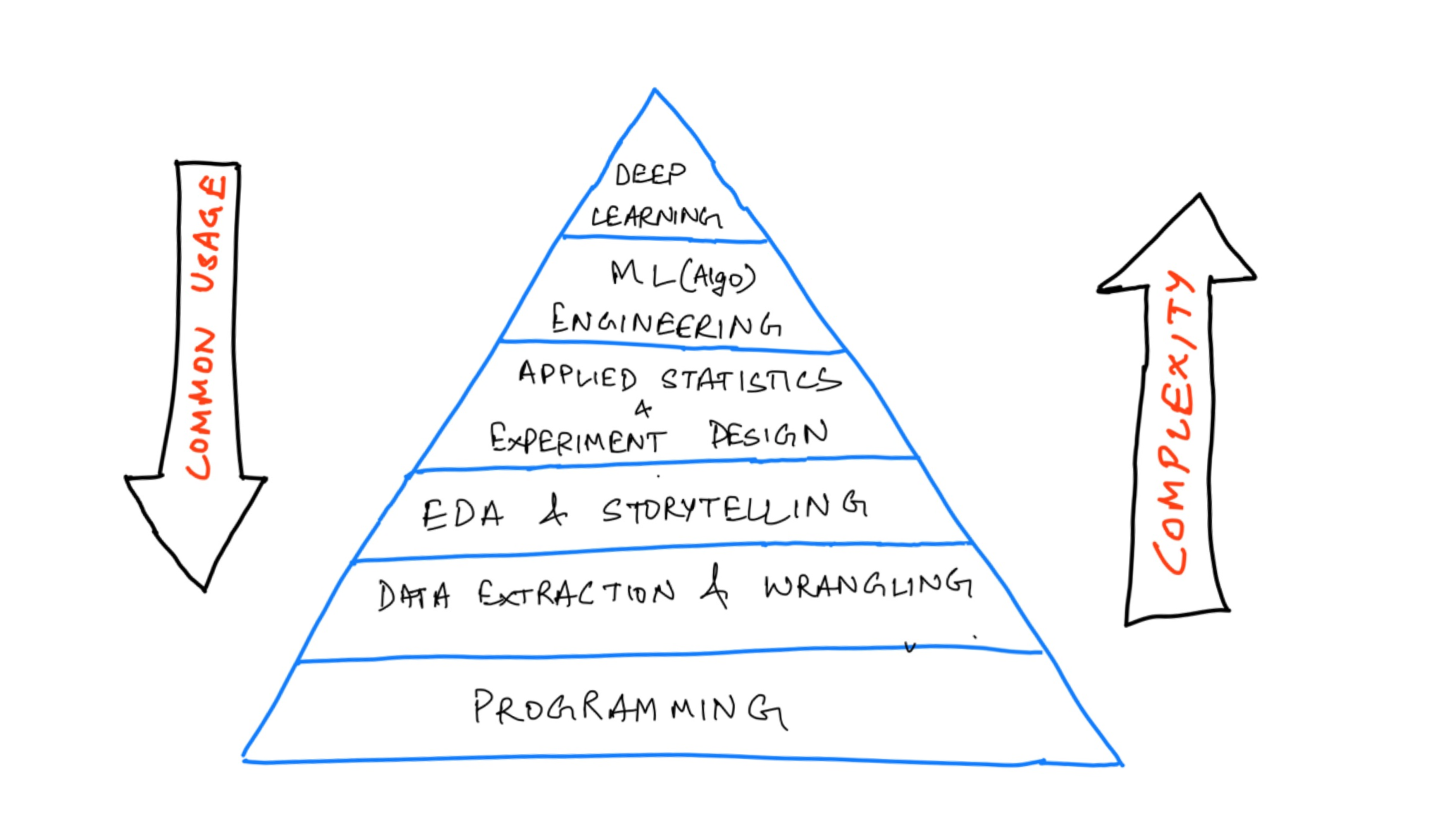
This would mark the base of our framework, we’ll now have to deep dive into each of these strata to complete our framework with more specific, and measurable details.
Specificity comes from enlisting the critical topics in each stratum and resources to refer to master those topics.
We’d be able to measure it by applying the learned topics to a number of real-world projects. I’ve added a few project ideas, portals, and platforms that you can use to measure your proficiency.
Imp NOTE: Take it one day at a time, one video/blog/chapter a day. It is a wide spectrum to cover. Don’t overwhelm yourself!
Let’s deep dive into each of these strata, starting from the bottom.
1. Programming or Software Engineering
(Estimated time: 2-3 months)
Firstly, make sure you have sound programming skills. Every data science job description would ask for programming expertise in at least one of the languages.
Specific topics include:
- Common data structures(data types, lists, dictionaries, sets, tuples), writing functions, logic, control flow, searching and sorting algorithms, object-oriented programming, and working with external libraries.
- SQL scripting: Querying databases using joins, aggregations, and subqueries
- Comfortable with using the Terminal, version control in Git, and using GitHub
Resources for python:
- learnpython.org [free]— a free resource for beginners. It covers all the basic programming topics from scratch. You get an interactive shell to practice those topics side-by-side.
- Kaggle [free]— a free and interactive guide to learning python. It is a short tutorial covering all the important topics for data science.
- Python Course by freecodecamp on YouTube[free] — This is a 5-hour course that you can follow to practice the basic concepts.
- Intermediate python [free]— Another free course by Patrick featured on freecodecamp.org.
- Coursera Python for Everybody Specialization[fee] — this is a specialization encompassing beginner-level concepts, python data structures, data collection from the web, and using databases with python.
Git
- Guide for Git and GitHub[free]: complete these tutorials and labs to develop a firm grip over version control. It will help you further in contributing to open-source projects.
SQL
- Intro to SQL and Advanced SQL on Kaggle.
- Datacamp also offers many courses on SQL.
Measure your expertise by solving a lot of problems and building at least 2 projects:
- Solve a lot of problems here: HackerRank(beginner-friendly), LeetCode(solve easy or medium-level questions)
- Data Extraction from a website/API endpoints — try to write python scripts from extracting data from webpages that allow scraping like soundcloud.com. Store the extracted data into a CSV file or a SQL database.
- Games like rock-paper-scissor, spin a yarn, hangman, dice rolling simulator, tic-tac-toe, etc.
- Simple web apps like youtube video downloader, website blocker, music player, plagiarism checker, etc.
Deploy these projects on GitHub pages or simply host the code on GitHub so that you learn to use Git.
2. Data collection and Wrangling(Cleaning)
(Estimated time: 2 months)
A significant part of the data science work is centered around finding apt data that can help you solve your problem. You can collect data from different legitimate sources — scraping(if the website allows), APIs, Databases, publicly available repositories.
Once you have data in hand, an analyst will often find herself cleaning dataframes, working with multi-dimensional arrays, using descriptive/scientific computations, manipulating dataframes to aggregate data.
Data is rarely clean and formatted for use in the “real world”. Pandas and NumPy are the two libraries that are at your disposal to go from dirty data to ready-to-analyze data.
As you start feeling comfortable writing python programs, feel free to start taking up lessons on using libraries like pandas and numpy.
Resources:
- Data Manipulation using pandas[fee] —an interactive course from datacamp that can quickly get you started with manipulating data using pandas. Learn to add transformations, aggregations, subsetting, and indexing dataframes.
- Kaggle pandas tutorial[free] — A short and concise hands-on tutorial that will walk you through commonly used data manipulation skills.
- Data Cleaning course by Kaggle.
- freecodecamp course on learning Numpy, pandas, matplotlib, and seaborn[free].
- Coursera course on Introduction to Data Science in Python[fee] — This is the first course in the Applied Data Science with Python Specialization.
Project Ideas:
- Collect data from a website/API(open for public consumption) of your choice, collect the data, and transform the data to store data from different sources into an aggregated file or table(DB). Example APIs include TMDB, quandl, Twitter API, etc.
- Pick any publicly available dataset; define a few set of questions that you’d want to pursue after looking at the dataset and the domain. Wrangle the data to find out answers to those questions using pandas and NumPy.
3. EDA, Business acumen and Storytelling
(Estimated time: 2–3 months)
The next stratum to master is data analysis and storytelling. Drawing insights from the data and then communicating the same to the management in simple terms and visualizations is the core responsibility of a Data Analyst.
The storytelling part requires you to be proficient with data visualization along with excellent communication skills.
Specific topics:
- Exploratory data analysis — defining questions, handling missing values, outliers, formatting, filtering, univariate and multivariate analysis.
- Data visualization — plotting data using libraries like matplotlib, seaborn, and plotly. Knowledge to choose the right chart to communicate the findings from the data.
- Developing dashboards — a good percent of analysts only use Excel or a specialized tool like Power BI and Tableau to build dashboards that summarise/aggregate data to help the management in making decisions.
- Business acumen: Work on asking the right questions to answer, ones that actually target the business metrics. Practice writing clear and concise reports, blogs, and presentations.
Resources:
- Career track on Data Analysis — by datacamp. A good list of interactive courses that you can refer to along with real-world case studies that they use while teaching. But do work on your own projects after going through the specialization.
- Data Analysis with Python — by IBM on Coursera. The course covers wrangling, exploratory analysis, and simple model development using python.
- Data Visualization — by Kaggle. Another interactive course that lets you practice all the commonly used plots.
- Data Visualization in Spreadsheets, Excel, Tableau, Power BI — pick anyone.
- Build product sense and business acumen with these books: Measure what matters, Decode and conquer, Cracking the PM interview.
Project Ideas
- Exploratory analysis on movies dataset to find the formula to create profitable movies(use it as inspiration), use datasets from healthcare, finance, WHO, past census, Ecommerce, etc.
- Build dashboards(jupyter notebooks, excel, tableau) using the resources provided above.
4. Data Engineering
(Estimated time: 4–5 months)
Data engineering underpins the R&D teams by making clean data accessible to research engineers and scientists at big data-driven firms. It is a field in itself and you may decide to skip this part if you want to focus on just the statistical algorithm side of the problems.
Responsibilities of a data engineer comprise building an efficient data architecture, streamlining data processing, and maintaining large-scale data systems.
Engineers use Shell(CLI), SQL, and python/Scala, to create ETL pipelines, automate file system tasks, and optimize the database operations to make it high-performance. Another crucial skill is implementing these data architectures which demand proficiency in cloud service providers like AWS, Google Cloud Platform, Microsoft Azure, etc.
Resources:
- [Book]Machine Learning Engineering by Andriy Burkov — this is a book that captures the real scenario of deploying/monitoring a model in a production environment.
- Data Engineering Nanodegree by Udacity — as far as a compiled list of resources is concerned, I have not come across a better-structured course on data engineering that would cover all the major concepts from scratch.
- Introduction to Data Engineering — By datacamp. A good resource to get started with building ETL pipelines with a host of tools.
- Data Engineering, Big Data, and Machine Learning on GCP Specialization — You can complete this specialization offered by Google on Coursera that walks you through all the major APIs and services offered by GCP to build a complete data solution.
Project Ideas/Certifications to prepare for:
- AWS Certified Machine Learning(300 USD) — A proctored exam offered by AWS, adds some weight to your profile(doesn’t guarantee anything though), requires a decent understanding of AWS services and ML.
- Professional Data Engineer — Certification offered by GCP. This is also a proctored exam and assesses your abilities to design data processing systems, deploying machine learning models in a production environment, ensure solutions quality and automation.
5. Applied statistics and mathematics
(Estimated time: 4–5 months)
Statistical methods are a central part of data science. Almost all the data science interviews predominantly focus on descriptive and inferential statistics.
People start coding machine learning algorithms without a clear understanding of underlying statistical and mathematical methods that explain the working of those algorithms.
Topics you should focus on:
- Descriptive Statistics — to be able to summarise the data is powerful but not always. Learn about estimates of location(mean, median, mode, weighted statistics, trimmed statistics), and variability to describe the data.
- Inferential statistics — designing hypothesis tests, A/B tests, defining business metrics, analyzing the collected data and experiment results using confidence interval, p-value, and alpha values.
- Linear Algebra, Single and multi-variate calculus to understand loss functions, gradient, and optimizers in machine learning.
Resources:
- [Book]Practical statistics for data science(highly recommend) — A thorough guide on all the important statistical methods along with clean and concise applications/examples.
- [Book]Naked Statistics — a non-technical but detailed guide to understanding the impact of statistics on our routine events, sports, recommendation systems, and many more instances.
- Statistical thinking in Python — a foundation course to help you start thinking statistically. There is a second part to this course as well.
- Intro to Descriptive Statistics— offered by Udacity. Consists of video lectures explaining widely used measures of location and variability(standard deviation, variance, median absolute deviation).
- Inferential Statistics, Udacity — the course consists of video lectures that educate you on drawing conclusions from data that might not be immediately obvious. It focuses on developing hypotheses and use common tests such as t-tests, ANOVA, and regression.
Project Ideas:
- Solve the exercises provided in the courses above and then try to go through a number of public datasets where you can apply these statistical concepts. Ask questions like “Is there sufficient evidence to conclude the mean age of mothers giving birth in Boston is over 25 years of age at the 0.05 level of significance.”
- Try to design and run small experiments with your peers/groups/classes by asking them to interact with an app or answer a question. Run statistical methods on the collected data once you have a good amount of data after a period of time. This might be very hard to pull off but should be very interesting.
- Analyze stock prices, cryptocurrencies, and design hypothesis around the average return or any other metric. Determine if you can reject the null hypothesis or fail to do so using critical values.
6. Machine Learning / AI
(Estimated time: 4–5 months)
After grilling yourself through all the major aforementioned concepts, you should now be ready to get started with the fancy ML algorithms.
There are three major types of learning:
- Supervised Learning — includes regression and classification problems. Study simple linear regression, multiple regression, polynomial regression, naive Bayes, logistic regression, KNNs, tree models, ensemble models. Learn about evaluation metrics.
- Unsupervised Learning — Clustering and dimensionality reduction are the two widely used applications of unsupervised learning. Dive deep into PCA, K-means clustering, hierarchical clustering, and gaussian mixtures.
- Reinforcement learning(can skip*) — helps you build self-rewarding systems. Learn to optimize rewards, using the TF-Agents library, creating Deep Q-networks, etc.
The majority of the ML projects need you to master a number of tasks that I’ve explained in this blog.
Resources:
- [book]Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition — one of my all-time favorite books on machine learning. Doesn’t only cover the theoretical mathematical derivations but also showcases the implementation of algorithms through examples. You should solve the exercises given at the end of each chapter.
- Machine Learning Course by Andrew Ng — the go-to course for anyone trying to learn machine learning. Hands down!
- Introduction to Machine Learning — Interactive course by Kaggle.
- Intro to Game AI and Reinforcement Learning — another interactive course on Kaggle on reinforcement learning.
- Supervised learning with Python — datacamp offers a multitude of courses on machine learning that one can follow. All of them are 4 hours long and can help you get a decent understanding of the application of ML.
Deep Learning Specialization by deeplearning.ai
For those of you who are interested in further diving into deep learning can start off by completing this specialization offered by deeplearning.ai and the Hands-ON book. This is not as important from a data science perspective unless you are planning to solve a computer vision or NLP problem.
Deep learning deserves a dedicated roadmap of its own. I’ll create that with all the fundamental concepts and
Track your learning progress
I’ve also created a learning tracker for you on Notion. You can customize it to your needs and use it to track your progress, have easy access to all the resources and your projects.
Find the video version of this blog below!
Data Science with Harshit
This is just a high-level overview of the wide spectrum of data science and you might want to deep dive into each of these topics and create a low-level concept-based plan for each of the categories.
Feel free to respond to this blog or comment on the video if you want me to add a new topic or rename anything. Also, let me know which category would you like me to do project tutorials on.