
Facebook의 PyGraph는 큰 그래프로 지식을 캡처하기위한 오픈 소스 프레임 워크입니다.
새로운 프레임 워크는 큰 그래프 구조에서 그래프 임베딩을 학습 할 수 있습니다.
저는 최근에 AI 교육에 관한 새로운 뉴스 레터를 시작했습니다.TheSequence는 읽는 데 5 분이 소요되는 비 BS (과장, 뉴스 없음 등) AI 중심 뉴스 레터입니다.목표는 기계 학습 프로젝트, 연구 논문 및 개념에 대한 최신 정보를 유지하는 것입니다.아래에서 구독하여 사용해보세요.
그래프는 기계 학습 애플리케이션의 기본 데이터 구조 중 하나입니다.특히 그래프 임베딩 방법은 기본 그래프 구조를 사용하여 노드 표현을 학습한다는 점에서 비지도 학습의 한 형태입니다.소셜 미디어 예측, 사물 인터넷 (IOT) 패턴 탐지 또는 약물 시퀀스 모델링과 같은 주류 시나리오의 훈련 데이터는 그래프 구조를 사용하여 자연스럽게 표현됩니다.이러한 시나리오 중 하나는 수십억 개의 상호 연결된 노드가있는 그래프를 쉽게 생성 할 수 있습니다.그래프 구조의 풍부함과 고유 한 탐색 기능은 기계 학습 모델을위한 훌륭한 놀이터이지만 그 복잡성은 엄청난 확장 성 문제를 안고 있습니다.당연히 최신 딥 러닝 프레임 워크에서 대규모 그래프 데이터 구조에 대한 지원은 여전히 상당히 제한적입니다.최근에 페이스 북은PyTorch BigGraph, PyTorch 모델에서 매우 큰 그래프에 대한 그래프 임베딩을 훨씬 빠르고 쉽게 생성 할 수있는 새로운 프레임 워크입니다.
어느 정도까지는 노드 간의 연결을 사용하여 특정 관계를 추론 할 수 있으므로 그래프 구조는 레이블이 지정된 학습 데이터 세트의 대안으로 볼 수 있습니다.이것은 노드 사이에 에지가있는 노드 쌍에 대한 임베딩이 공유 에지가없는 노드 쌍보다 서로 더 가깝다는 목표를 최적화하여 그래프에서 각 노드의 벡터 표현을 학습하는 비지도 그래프 임베딩 방법에 따른 접근 방식입니다.이것은 word2vec과 같은 단어 임베딩이 텍스트에서 학습되는 방식과 유사합니다.
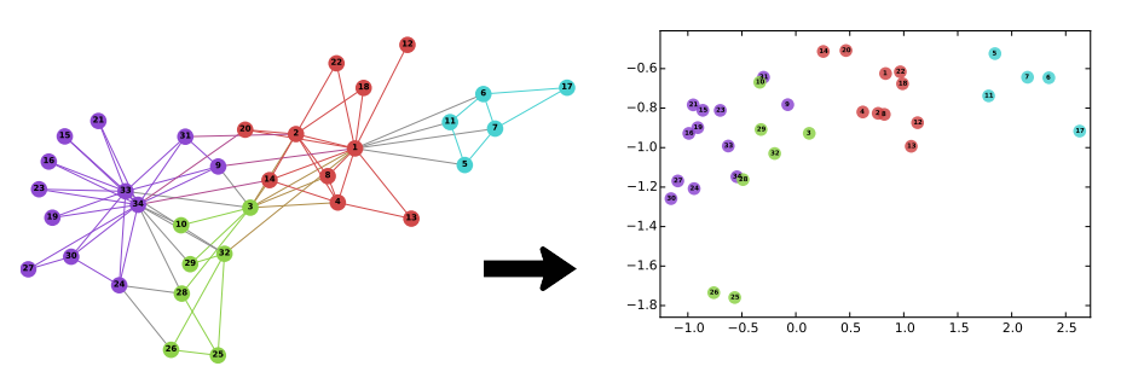
대부분의 그래프 임베딩 방법은 큰 그래프 구조에 적용될 때 상당히 제한적입니다.예를 들어, 노드 당 20 억 개의 노드와 100 개의 임베딩 매개 변수가있는 모델 (부동으로 표시됨)은 매개 변수를 저장하는 데 800GB의 메모리가 필요하므로 많은 표준 방법이 일반적인 상용 서버의 메모리 용량을 초과합니다.딥 러닝 모델의 주요 과제를 나타내는 것은 Facebook의 BigGraph 프레임 워크의 기원입니다.
PyTorch BigGraph
PyTorch BigGraph (PBG)의 목표는 그래프 임베딩 모델을 수십억 개의 노드와 수조 개의 에지가있는 그래프로 확장 할 수 있도록하는 것입니다.PBG는 다음과 같은 네 가지 기본 구성 요소를 활성화하여이를 달성합니다.
- 그래프 분할, 모델을 메모리에 완전히로드 할 필요가 없습니다.
- 다중 스레드 계산각 컴퓨터에서
- 분산 실행여러 컴퓨터 (선택 사항)에서 모두 동시에 그래프의 분리 된 부분에서 작동
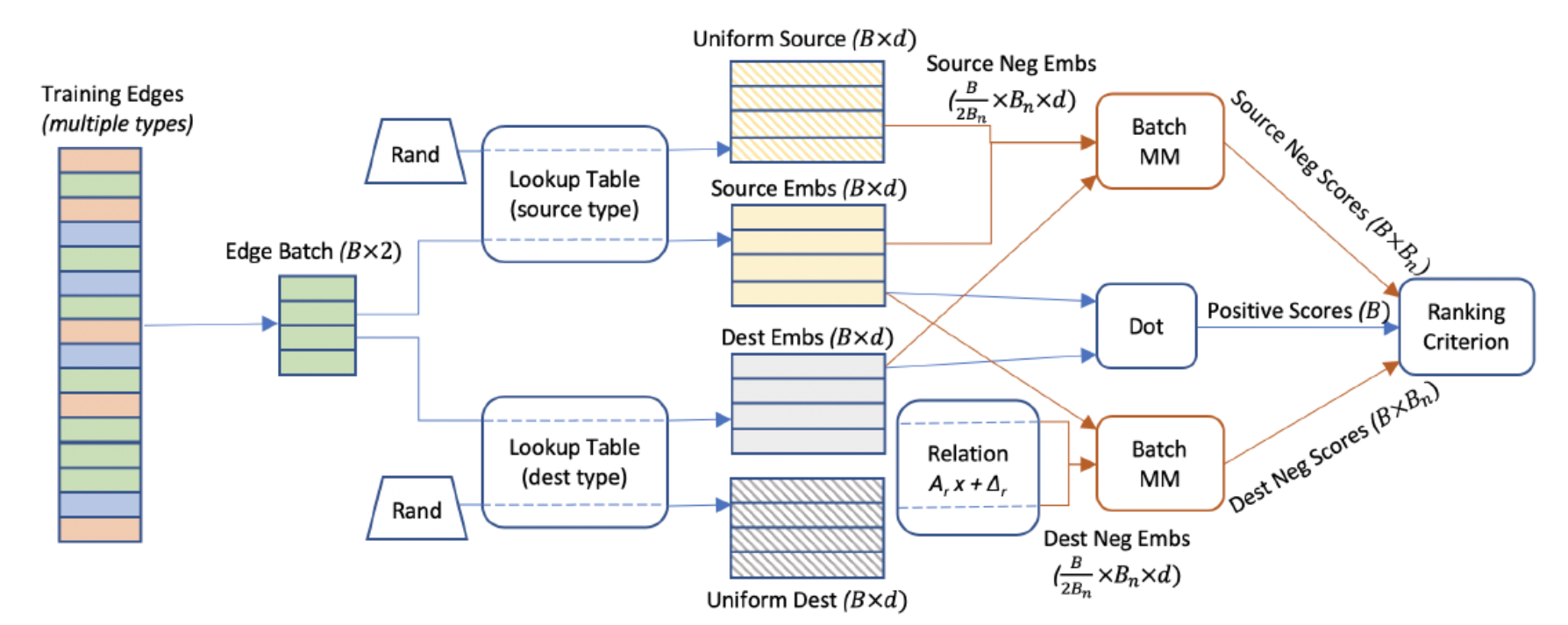
- 일괄 네거티브 샘플링, 에지 당 100 만 개의 네거티브를 사용하여 기계 당 초당 100 만 개의 에지를 처리 할 수 있습니다.
PBG는 두 개의 파티션이 메모리에 들어갈 수 있도록 크기가 조정 된 P 파티션으로 그래프 구조를 무작위로 분할하여 기존 그래프 임베딩 방법의 일부 단점을 해결합니다.예를 들어 에지의 소스가 파티션 p1에 있고 대상이 파티션 p2에있는 경우 버킷 (p1, p2)에 배치됩니다.동일한 모델에서 그래프 에지는 소스 및 대상 노드를 기반으로 P2 버킷으로 나뉩니다.노드와 에지가 분할되면 한 번에 하나의 버킷에서 훈련을 수행 할 수 있습니다.버킷 (p1, p2) 훈련에는 파티션 p1 및 p2에 대한 임베딩 만 메모리에 저장되어야합니다.PBG 구조는 버킷에 이전에 훈련 된 임베딩 파티션이 하나 이상 있음을 보장합니다.
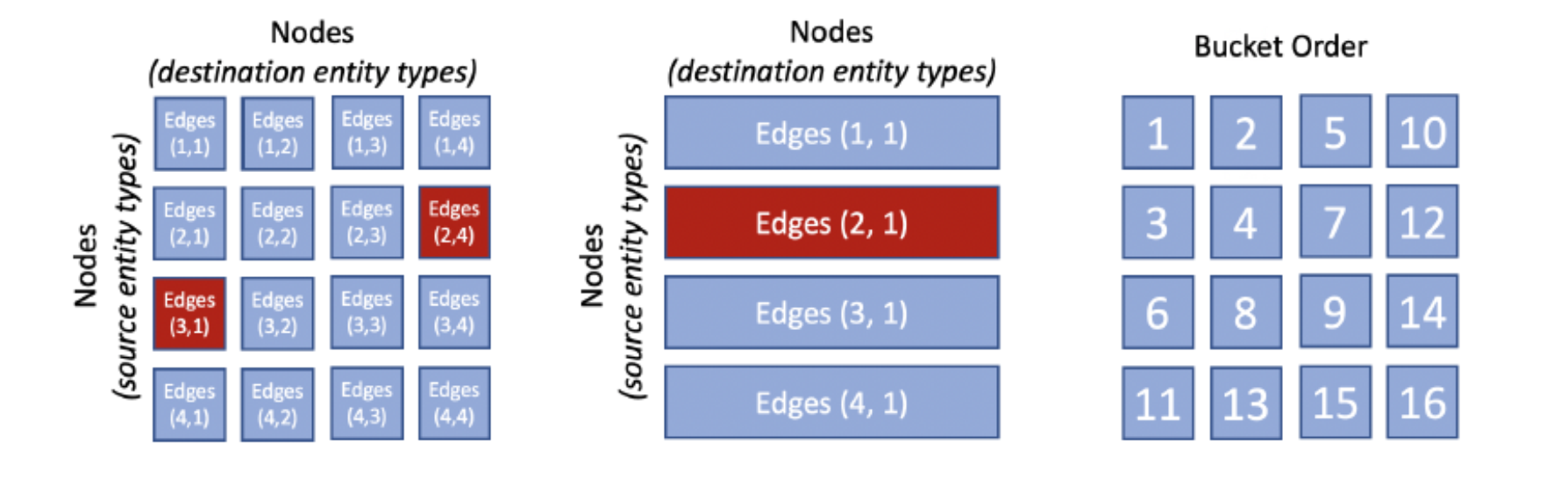
PBG가 진정으로 혁신하는 또 다른 영역은 훈련 메커니즘의 병렬화 및 배포입니다.PBG는 PyTorch를 사용합니다.병렬화 프리미티브앞에서 설명한 블록 파티션 구조를 활용하는 분산 학습 모델을 구현합니다.이 모델에서 개별 기계는 서로 다른 기계 간의 통신을 최소화하기 위해 작업자에게 버킷을 분할하는 잠금 서버를 사용하여 분리 된 버킷에서 훈련하도록 조정합니다.각 머신은 서로 다른 버킷을 사용하여 모델을 병렬로 학습시킬 수 있습니다.
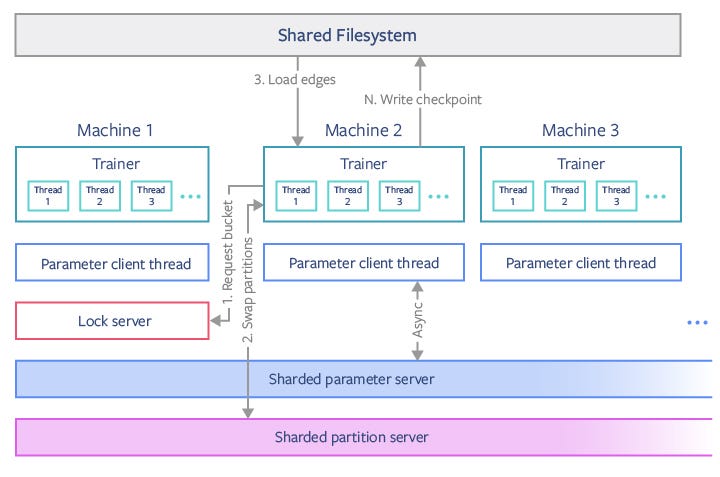
이전 그림에서 머신 2의 Trainer 모듈은 머신 1의 잠금 서버에서 버킷을 요청하여 해당 버킷의 파티션을 잠급니다.그런 다음 트레이너는 더 이상 사용하지 않는 파티션을 저장하고 샤드 된 파티션 서버에서 필요한 새 파티션을로드합니다. 이때 이전 파티션을 잠금 서버에서 해제 할 수 있습니다.그런 다음 공유 파일 시스템에서 에지를로드하고 스레드 간 동기화없이 여러 스레드에서 학습을 수행합니다.별도의 스레드에서 소수의 공유 매개 변수가 분할 된 매개 변수 서버와 지속적으로 동기화됩니다.모델 체크 포인트는 때때로 트레이너가 공유 파일 시스템에 작성합니다.이 모델을 사용하면 최대 P / 2 머신을 사용하여 P 버킷 세트를 병렬화 할 수 있습니다.
PBG의 간접적 인 혁신 중 하나는 일괄 네거티브 샘플링 기술을 사용하는 것입니다.기존의 그래프 임베딩 모델은 임의의 “거짓”에지를 참 양성 에지와 함께 음성 학습 예제로 구성합니다.이렇게하면 새 샘플마다 적은 비율의 가중치 만 업데이트해야하므로 훈련 속도가 크게 빨라집니다.그러나 네거티브 샘플은 결국 그래프 처리에 성능 오버 헤드를 유발하고 결국 임의의 소스 또는 대상 노드로 실제 에지를 “손상”시킵니다.PBG는 N 개의 임의 노드의 단일 배치를 재사용하여 N 개의 훈련 에지에 대해 손상된 음수 샘플을 생성하는 방법을 도입했습니다.다른 임베딩 방법과 비교하여이 기술을 사용하면 적은 계산 비용으로 실제 에지 당 많은 네거티브 예제를 학습 할 수 있습니다.
큰 그래프에서 메모리 효율성과 계산 리소스를 높이기 위해 PBG는 Bn 샘플링 된 소스 또는 대상 노드의 단일 배치를 활용하여 여러 개의 네거티브 예제를 구성합니다. 일반적인 설정에서 PBG는 훈련 세트에서 B = 1000 포지티브 에지의 배치를 가져옵니다.50 개의 가장자리 조각으로 나눕니다.각 청크의 대상 (동등하게, 소스) 임베딩은 꼬리 항목 유형에서 균일하게 샘플링 된 50 개의 임베딩과 연결됩니다.200 개의 샘플링 된 노드와 50 개의 긍정의 외적은 9900 개의 부정적인 예와 같습니다.
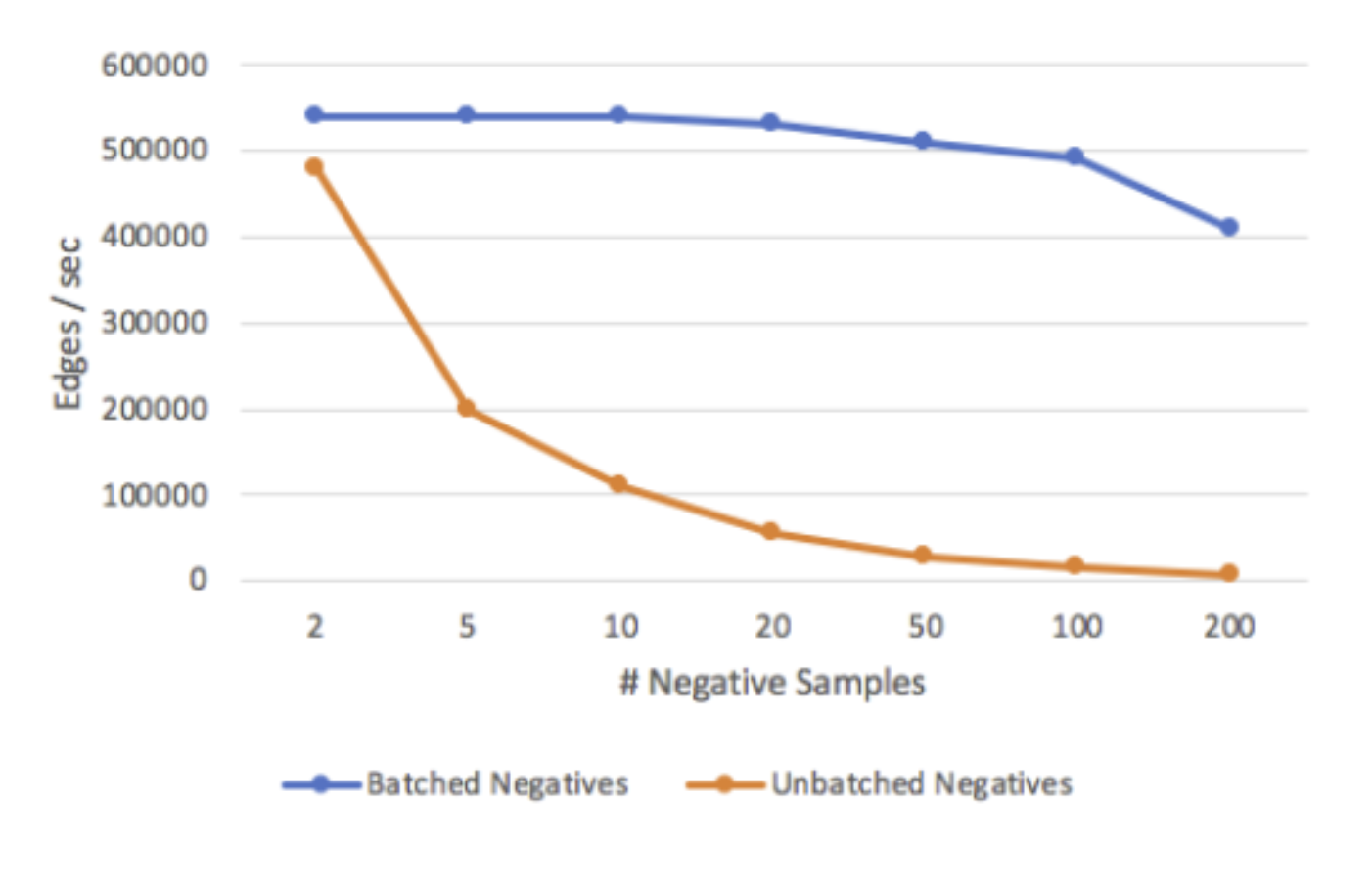
일괄 음수 샘플링 접근 방식은 모델 학습 속도에 직접적인 영향을 미칩니다.일괄 처리를 사용하지 않으면 학습 속도가 음수 샘플 수에 반비례합니다.일괄 훈련은 해당 방정식을 개선하여 일정한 훈련 속도를 달성합니다.
Facebook은 LiveJournal, Twitter 데이터 및 YouTube 사용자 상호 작용 데이터와 같은 다양한 그래프 데이터 세트를 사용하여 PGB를 평가했습니다.또한 PBG는 15,000 개의 노드와 600,000 개의 에지를 포함하고 일반적으로 사용되는 FB15k로 알려진 Freebase 그래프의 더 작은 하위 집합뿐 아니라 1 억 2 천만 개 이상의 노드와 27 억 개의 에지를 포함하는 Freebase 지식 그래프를 사용하여 벤치마킹되었습니다.다중 관계 임베딩 방법에 대한 벤치 마크.FB15k 실험은 PBG가 최신 그래프 임베딩 모델과 유사한 성능을 보이는 것으로 나타났습니다.그러나 전체 Freebase 데이터 세트에 대해 평가했을 때 PBG는 메모리 소비가 88 % 이상 향상되었음을 보여줍니다.

PBG는 수십억 개의 노드와 수조 개의 에지가있는 구조로 그래프 데이터를 확장하고 학습 및 처리 할 수있는 최초의 방법 중 하나입니다.PBG의 첫 번째 구현GitHub에서 오픈 소스되었습니다.그리고 우리는 가까운 장래에 흥미로운 기여를 기대해야합니다.